Spark SQL 实现 group_concat
环境:Spark 2.0.1
以下貌似需要至少Spark 1.6支持,未实测(网友yanshichuan1反馈spark 1.5.1同样支持,感谢)
表结构及内容:
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
| Justin| 20|
| LI| 20|
+-------+---+Spark SQL 实现:
SELECT concat_ws(',',collect_set(name)) FROM A GROUP BY class parquetFile.registerTempTable("people")
sqlContext.sql("select concat_ws(',',collect_set(name)) as names from people group by age").show()
+---------+---+
| names|age|
+---------+---+
|LI,Justin| 20|
| Justin| 19|
| Michael| 29|
| Andy| 30|
+---------+---+Spark DataFrame 实现:
也可使用 collect_list() 替换 collect_set()
import org.apache.spark.sql.functions._
parquetFile.groupBy("age")
.agg(collect_set("name"))
.show()
+---+-----------------+
|age|collect_set(name)|
+---+-----------------+
| 20| [LI, Justin]|
| 19| [Justin]|
| 29| [Michael]|
| 30| [Andy]|
+---+-----------------+更好理解的一个例子:
使用以下sql语句实现如下的变换
SELECT concat_ws(',',collect_set(name)) FROM A GROUP BY class 原始表:
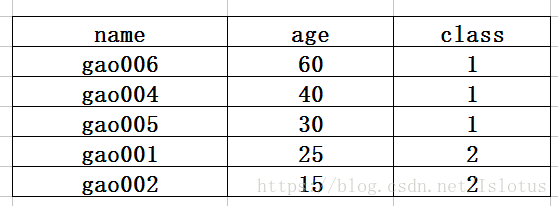
结果表:

参考:
2.Spark SQL 函数之 GROUP_CONCAT 实现
3.Spark CONCAT系列函数
版权声明:本文为Islotus原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。