导语:本文是模型评估指标系列的第一篇,将详细地介绍分类模型中基于混淆矩阵衍生出来的各个指标的计算公式,如准确率,精确率,召回率,FPR,TPR,ROC曲线的绘制逻辑,AUC的计算公式等。本文首发在个人知乎和微信公众号:一直学习一直爽
文章目录
在
Evaluating Learning Algorithms: A Classification Perspective书中有一幅模型评估指标的全局图,如下: 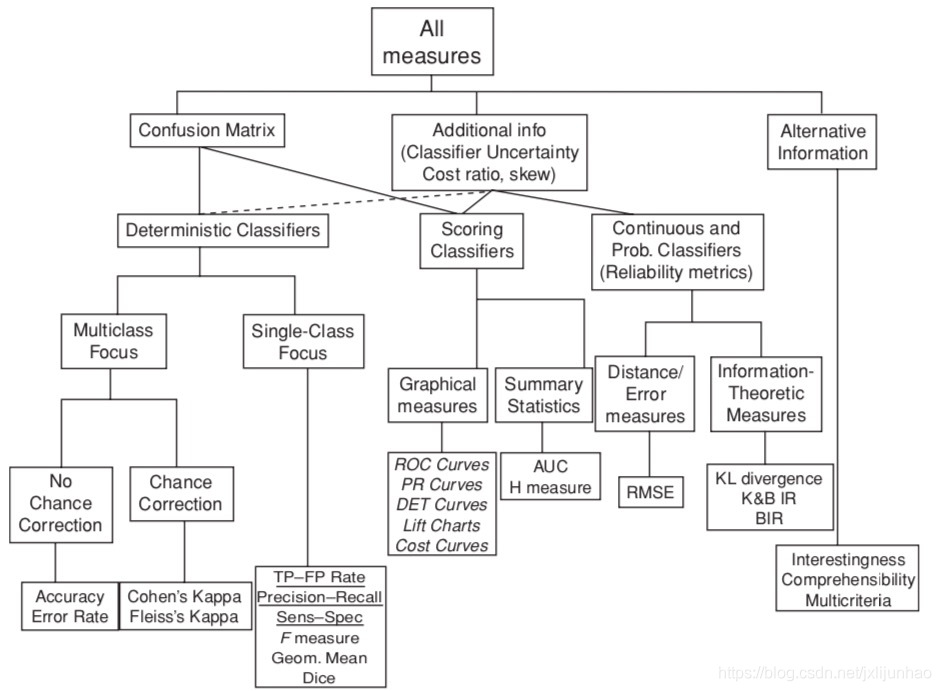
该图基本包含了日常我们常用的各种指标,如果不想看那么详细,可以看以下总结: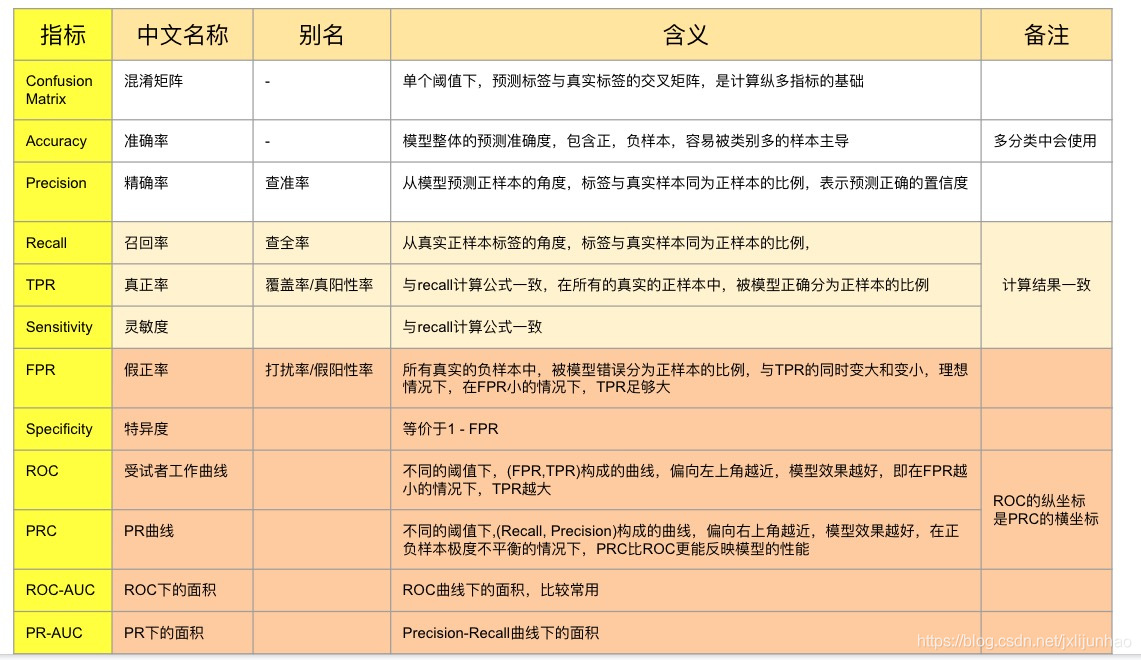
混淆矩阵-Confusion Matrix
在分类模型中,假如给定的类别个数为N NN,那么混淆矩阵的大小为N × N N \times NN×N,默认地,会把列作为真实的类别,行作为预测的类别,如下图举例所示: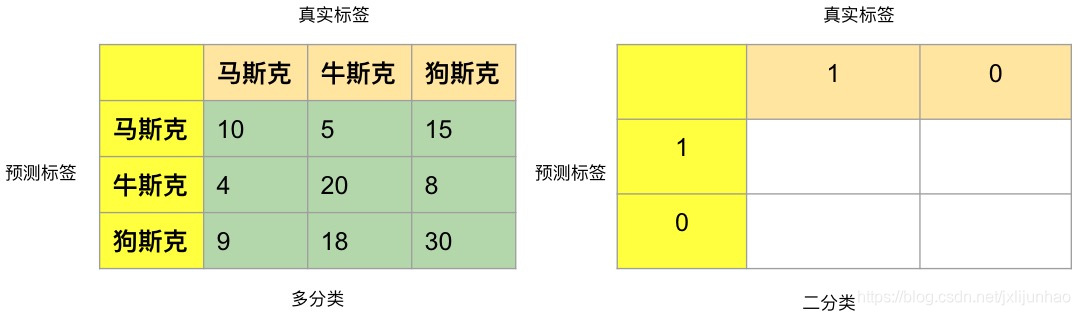
由是我们常见的分类任务基本上为二分类,如预测商品否被点击,是否被购买,借款人是否发生逾期等,下面的计算过程就以二分类混淆矩阵来进行举例,另外,很多模型输出的预测值p pp在[0,1]之间,并不是离散取值{0,1},为了构建混淆矩阵,需要确定一个阈值t tt,使得预测值p > t p > tp>t的样本预测为1,否则为0。
由于ROC这样的曲线来源于雷达,后面又应用到医学领域,因此常常把正样本称为阳性(Positive,P,标签为1), 负样本称为阴性(Negative, N,标签为0),而机器学习领域习惯用正负样本来表示,当初学二分类中的混淆矩阵时,很多同学会被TP,FP,FN,TN等缩写搞混,下面对其做一些方便记忆的说明: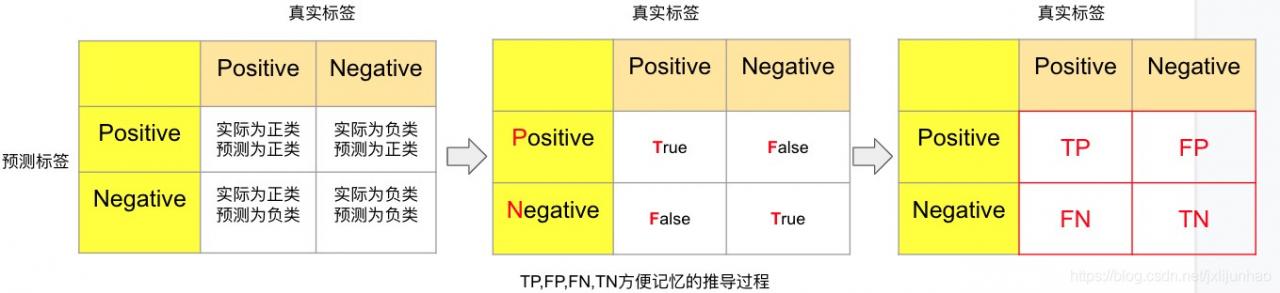
从上图的最左边的表格,可以很清楚地显示4个区域内样本的含义,沿着正对角线,可知,样本的预测标签和实际标签都是一致的,因此在第二个表格中将其标记为True,负对角线上预测标签和真实标签不一致,标记为False,在第三个表格中,结合预测标签的类别(Positive,Negative)和各个区域的True,False标记,得到了经常被搞混的4个缩写(不需要去记忆,记住上述推演过程即可):
TP:实际为正类,预测也为正类TN:实际为负类,预测也为负类FP:实际为负类,预测为正类FN:实际为正类,预测为负类
有了上述混淆矩阵和各个区域的标识,就可以开始计算各个指标了;
准确率-Accuracy
显然,准确率为混淆矩阵中正对角线上被分类正确样本之和:正样本,模型预测也为正样本(TP) ,负样本,模型预测也为负样本(TN).
A c c u r a c y = T P + T N T P + F P + F N + T N \begin{aligned} Accuracy = \frac{TP + TN}{TP + FP + FN + TN} \end{aligned}Accuracy=TP+FP+FN+TNTP+TN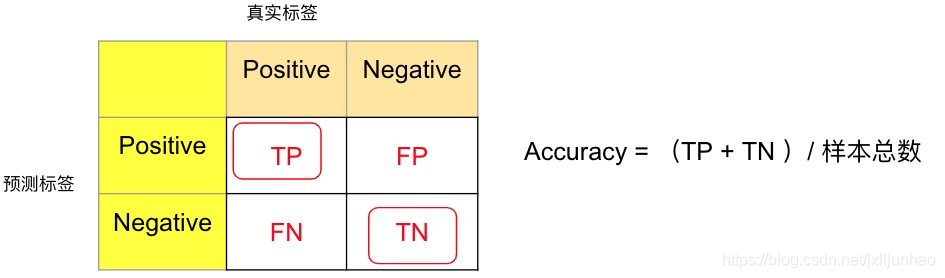
精确率-Precision
- 别名:查准率
精确率Precision的计算如下图所示,表示的含义为,从模型预测的角度来看,在所有预测为正样本中,标签与真实样本同为正样本的比例, 表示模型对于预测正确的置信度:
P r e c i s i o n = T P T P + F P \begin{aligned} Precision = \frac{TP}{TP + FP} \end{aligned}Precision=TP+FPTP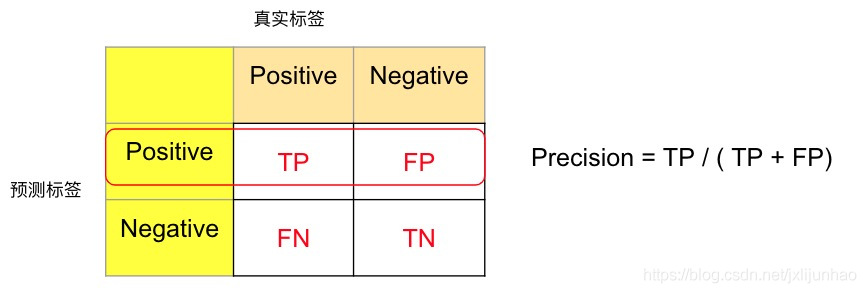
召回率-Recall
- 别名:查全率
召回率Recall计算如下图所示,表示的含义为,从真实标签的角度来看,在所有的真实正样本中,被模型正确地预测为正样本所占的比例:
R e c a l l = T P T P + F N \begin{aligned} Recall = \frac{TP}{TP + FN} \end{aligned}Recall=TP+FNTP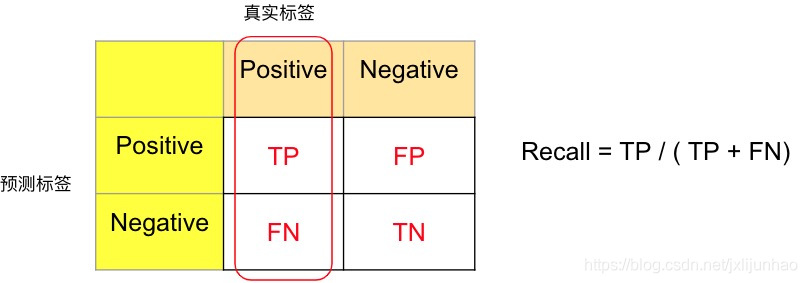
F1-调和精确率与召回率
从上述Precision,Recall的计算过程可以发现(分子是相同的),其计算都是围绕着正样本(实际类别和预测类别)来计算的,同时Precision,Recall天然存在着矛盾,如下图所示:
- 当把所有样本全部预测为正样本时(模型过分贪婪,模型分> = 0 >=0>=0即为正样本),显然召回率可以达到最大,取值为1,但是精确率将显著下降
- 当设定很大的阈值(模型过分保守,模型分> = 0.9 >=0.9>=0.9才是正样本),刚好仅有一个样本预测正确,那么精确率取值为1,但召回率将很低
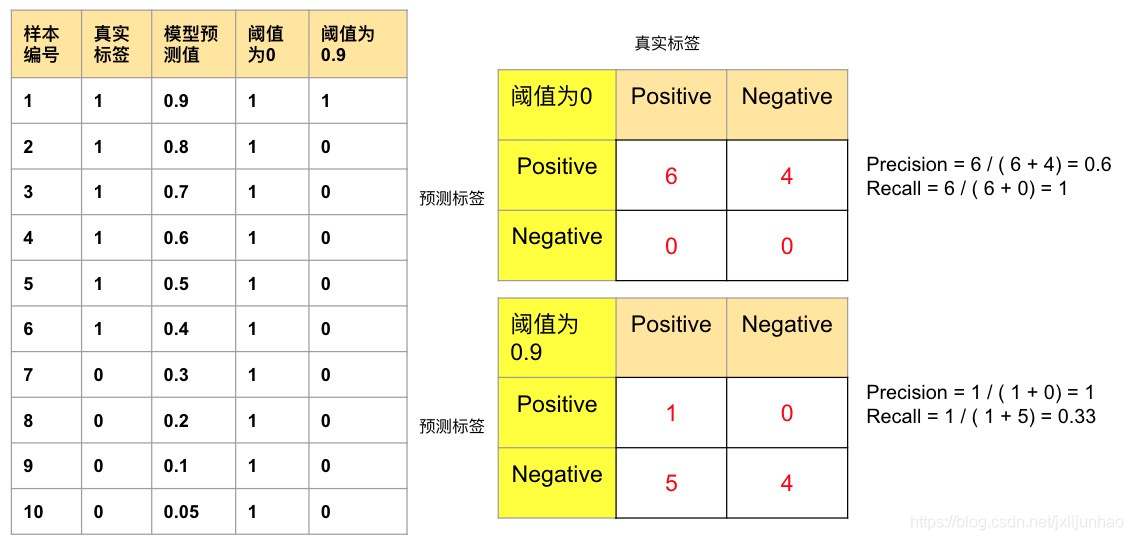
因此,为了调和两者之间的矛盾,将引入F1指标来综合反映模型的性能:
2 F 1 = 1 P + 1 R \begin{aligned} \frac{2}{F1} = \frac{1}{P} + \frac{1}{R} \end{aligned}F12=P1+R1
另外,还有一个更通用的计算F α F_{\alpha}Fα值的公式,当α = 1 \alpha=1α=1即为F1:
F α = 1 + α 2 α 2 ∗ P + R P R \begin{aligned} F_{\alpha} = \frac{1 + \alpha^2}{\alpha^2 * P + R} PR \end{aligned}Fα=α2∗P+R1+α2PR
真正率-TPR
- 别名:真阳性率
TPR(True Positive Rate)预测正确的正类占实际正类的比例(给定数据集标签后,统计出正样本个数即可作为分母):
T P R = T P T P + F N \begin{aligned} TPR = \frac{TP}{TP + FN} \end{aligned}TPR=TP+FNTP
可以发现,TPR=Recall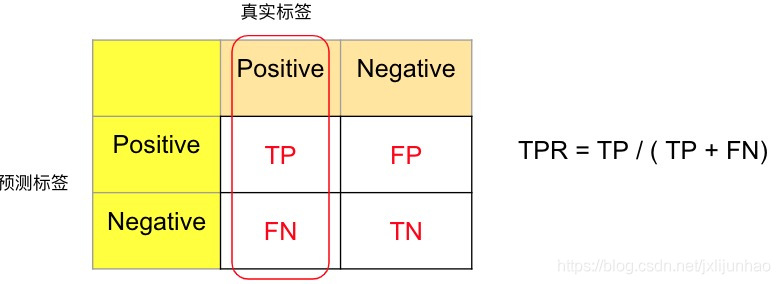
假正率-FPR
- 别名:假阳性率
FPR(False Positive Rate)预测错误的正类占实际负类的比例(给定数据集标签后,统计出负样本个数即可作为分母):
F P R = F P F P + T N \begin{aligned} FPR = \frac{FP}{FP + TN} \end{aligned}FPR=FP+TNFP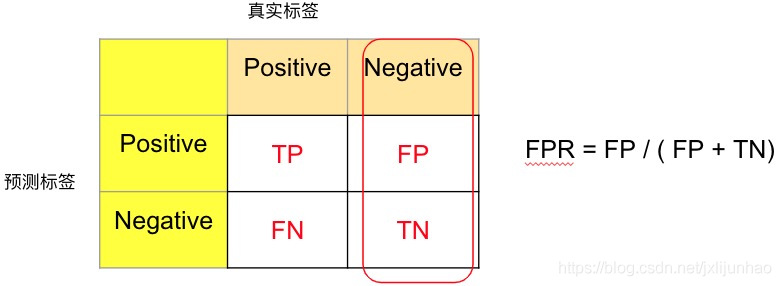
对比TPR和FPR的计算公式,我们发现其分母要么是全部的真实正类,或者全部的真实的负类,增加真实正类样本的个数,不会影响FPR的计算,反之亦然,互不干扰,因此我们常说TPR和FPR对于样本不平衡不敏感。
KS
KS(Kolmogorov-Smirnov)值,计算公式如下, KS能够反映出模型最优的区分效果,以及对应的阈值:
K S = max ( T P R − F P R ) \begin{aligned} KS = \max(TPR - FPR) \end{aligned}KS=max(TPR−FPR)
灵敏度-Sensitivity
- 计算结果与TPR,Recall相同
特异度-Specificity
特异度的计算如下图所示:
特 异 度 = T N F P + T N \begin{aligned} 特异度 = \frac{TN}{FP + TN} \end{aligned}特异度=FP+TNTN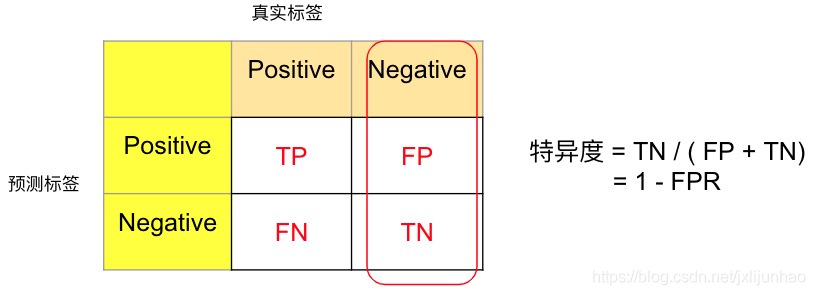
从点到线-ROC曲线
由于混淆矩阵是在确定的了一个阈值后生成的,因此,利用不同的阈值就可以得到多组(FPR,TPR)点,将这些点依次连接起来,就构成了ROC曲线(没有必要先遍历阈值,如从0~1之间,将阈值切分1000等分, 可以直接根据样本预测值从大到小排序,依次遍历样本即可,得到数据中的阈值),受试者工作特征曲线ROC曲线的横坐标是FPR,纵坐标是TPR。
下面通过一个论文中的一个例子来说明ROC是怎么画出来的,数据如下,一共20个样本,正样本10个,负样本10个,每个样本具有不同的模型分,根据模型分从大到小进行排序;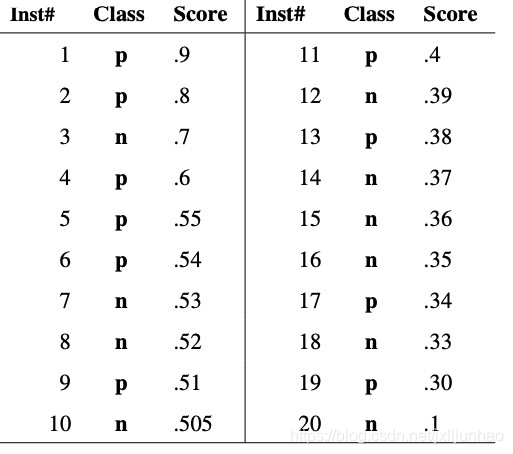
ROC曲线流程:假定L LL为带标签和模型分的数据集,其中正样本个数为P PP,负样本个数为N NN,样本i ii的模型分记为f ( i ) f(i)f(i), 用R RR存放(FPR,TPR)点:
- 根据模型分对数据集L LL进行从大到小排序,得到L s o r t e d L_{sorted}Lsorted,第一个样本记为i = 1 i=1i=1,由于TPR和FPR的分母已知,故只需要初始化分子TP,FP为0,模型分的阈值初始化为f p r e = ∞ f_{pre} = \inftyfpre=∞;
- 依次对L s o r t e d L_{sorted}Lsorted的样本进行遍历:
2.1)如果满足 $f(i) \neq f_{pre} $ (相邻样本模型分取值不相同),则 R RR.append(F P N , T P P \frac{FP}{N}, \frac{TP}{P}NFP,PTP), 更新f p r e = f ( i ) f_{pre} = f(i)fpre=f(i);
2.2)如果L s o r t e d [ i ] L_{sorted}[i]Lsorted[i] 的真实标签和预测标签都为正样本,那么 T P = T P + 1 TP = TP + 1TP=TP+1,否则F P = F P + 1 FP = FP + 1FP=FP+1
更新样本下标i = i + 1 i = i + 1i=i+1- 将最后一个点加入到R . a p p e n d ( ( 1 , 1 ) ) R.append((1, 1))R.append((1,1))
有了上述的计算流程,对于上述数据,前几个点的FPR,TPR取值如下:
- 当阈值为∞ \infty∞, 显然 TP=0,FP=0, (0, 0),具体解释见下段内容
Tips;- 遍历第一个样本,阈值设置为0.9,将样本预测值标签设为正,和真实标签相同都为正样本,因此T P R = 1 10 = 0.1 , F P R = 0 TPR=\frac{1}{10}=0.1,FPR=0TPR=101=0.1,FPR=0, (0, 0.1);
- 遍历到第二个样本,阈值设置为0.8, T P R = 2 10 , F P R = 0 TPR=\frac{2}{10}, FPR=0TPR=102,FPR=0, (0, 0.2);
- 遍历到第三个样本, 阈值设置为0.7,将样本预测值标签设为正,和真实标签不同,FP=1, T P R = 2 10 , F P R = 1 10 TPR=\frac{2}{10}, FPR=\frac{1}{10}TPR=102,FPR=101, (0.1, 0.2);
- …
最终整个ROC曲线如下图所示: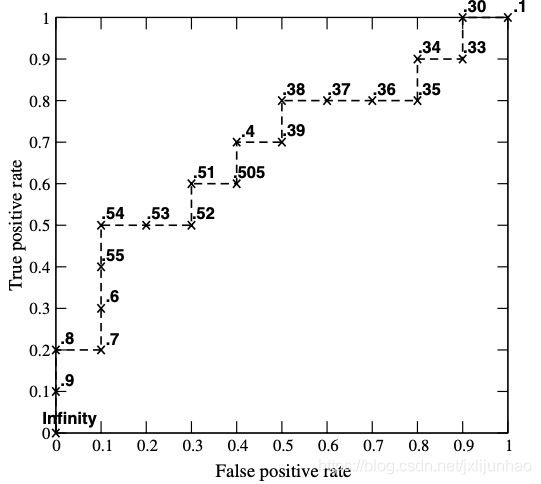
由于样本个数有限,可以发现ROC曲线其实是一个个阶跃形状,了解到这一点,有助于我们来计算ROC曲线下的面积(AUC)。
Tips:
- 如果FPR和TPR处处相等,那么ROC会是一条直线(理解为,模型会将一半的正样本,负样本预测错误,相当于随机猜测了);
- 对于点( 1 , 1 ) (1, 1)(1,1),阈值为− ∞ - \infty−∞,由于样本模型分在[0,1]之间,那么所有样本被预测为正样本(混淆矩阵第二行全为0),TP=P(正样本个数), FP=N(负样本个数);
- 对于点( 0 , 0 ) (0, 0)(0,0), 阈值为∞ \infty∞, 所有样本被预测为负样本(混淆矩阵第一行全为0),TP=0,FP=0;
- 阈值越小时,召回率/TPR就越高,FPR也越高
从点到线-PRC曲线
Precision-Recall曲线,简称PRC,其横坐标为Recall,纵坐标为Precision, 曲线的绘制方式与ROC类似,这里不做过多展开。
- PRC的横坐标是ROC的纵坐标(Recall VS TPR)
ROC-AUC(ROC曲线下的面积)
计算方式1
AUC是ROC曲线下的面积,直接根据这个定义,对ROC计算流程进行简单改进,就可以得到AUC的计算流程:
- 根据模型分对数据集L LL进行排序,得到L s o r t e d L_{sorted}Lsorted,第一个样本记为i = 1 i=1i=1,由于TPR和FPR的分母已知,故只需要初始化分子T P TPTP,F P FPFP为0,由于是不断积分的过程(计算梯形面积的过程),还需要记录上一次T P p r e v TP_{prev}TPprev, F P p r e v FP_{prev}FPprev的值, 模型分的阈值初始化为f p r e = ∞ f_{pre} = \inftyfpre=∞, 面积A AA;
- 依次对L s o r t e d L_{sorted}Lsorted的样本进行遍历:
2.1) 如果满足 $f(i) \neq f_{pre} $ (相邻样本模型分取值不相同),则 A = A + T R A P E Z O I D ( F P , F P p r e v , T P , T P p r e v ) A = A + TRAPEZOID(FP, FP_{prev}, TP, TP_{prev})A=A+TRAPEZOID(FP,FPprev,TP,TPprev), 更新
f p r e = f ( i ) f_{pre} = f(i)fpre=f(i); F P p r e v = F P , T P p r e v = T P FP_{prev}=FP, TP_{prev}=TPFPprev=FP,TPprev=TP;
2.2) 如果L s o r t e d [ i ] L_{sorted}[i]Lsorted[i] 的真实标签和预测标签都为正样本,那么 T P = T P + 1 TP = TP + 1TP=TP+1,否则F P = F P + 1 FP = FP + 1FP=FP+1
更新样本下标i = i + 1 i = i + 1i=i+1- A = A + T R A P E Z O I D ( N , F P p r e v , N , T P p r e v ) A = A + TRAPEZOID(N, FP_{prev}, N, TP_{prev})A=A+TRAPEZOID(N,FPprev,N,TPprev)
- 缩放回去:A = A P × N A = \frac{A}{P \times N}A=P×NA
其中上述T R A P E Z O I D ( X 1 , X 2 , Y 1 , Y 2 ) TRAPEZOID(X_1, X_2, Y_1, Y_2)TRAPEZOID(X1,X2,Y1,Y2)是计算梯形面积的过程:
b a s e = ∣ X 1 − X 2 ∣ h e i g h t = Y 1 + Y 2 2 a r e a = b a s e × h e i g h t \begin{aligned} base &= | X_1 - X_2| \\ height &= \frac{Y_1 + Y_2}{2} \\ area & = base \times height \\ \end{aligned}baseheightarea=∣X1−X2∣=2Y1+Y2=base×height
计算方式2
AUC实际上是模型将正样本排在负样本前面的概率,随机从正负样本中分别选出一个样本,构成样本对,样本对中正样本的模型分大于负样本模型分的占比,即为AUC
sklearn计算的接口
| 接口 | 说明 |
|---|---|
| confusion_matrix | 算混淆矩阵来评估分类的准确性 |
| accuracy_score | 模型准确度(Accuracy) |
| f1_score | 计算F1得分 |
| precision_recall_curve | 针对不同的概率阈值计算精度(precision),召回率对 |
| precision_score | 计算精确度 |
| recall_score | 计算召回 |
| roc_auc_score | 计算特征曲线(ROC AUC)下预测分数的计算区域 |
| roc_curve | 计算ROC |
总结
- 判断一个指标是否受正负样本量的影响,看这个指标在混淆矩阵中是否只利用单独某列上的数据,如果是,对正负样本采样本,不影响模型的指标;
- 在正负样本极不平衡的情况下,PR曲线比ROC曲线更能反映模型的性能(这个在下一篇进行说明)

