点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
2022年6月11日,PhD Debate第十期,题为“自监督学习在推荐系统中的应用”的研讨活动,特别邀请了来自香港大学计算机学院助理教授黄超、新加坡国立大学博士后张震、清华大学博士生武楚涵和中国科学技术大学博士生吴剑灿作为嘉宾,与大家一起聊一聊自监督学习在推荐系统中的应用。
近年来,自监督学习在各个领域得到了广泛的应用。通过引入额外的监督信号,来解决数据稀疏性的问题。
Q1
针对于不同的推荐场景,如何更好地设计出基于预训练或协同训练的辅助任务,从而增强用户表征学习?
针对这个问题,武楚涵首先分享了他的看法,预训练和协同训练都可以基于自监督学习,但是二者在推荐系统的场景下存在很大的范数差距。
预训练其实是一个推荐系统的流派之一,其这些任务与下游任务进行解耦。比如,预训练可能是一些特定的自监督任务,下游任务把这些预训练过后的用户模型进行fine-tuning微调,之后我们就能将其应用于下游任务之中。
协同训练则是指与下游任务一起进行训练,可见基于预训练的方式与我们常见的BERT模型有所不同。基于预训练的方式更多是工业界偏好的方式,因为其在训练时依赖大量的一般用户行为。对于这些不受场景限制的行为,我们进行预训练之后就可以得到general purpose的用户模型。之后再将这些general purpose的用户模型在不同场景下进行fine-tuning,这样我们就可以用比较general的信息去增强下游任务的推荐结果。其实预训练的起步和NLP的起步速度差不多,并没有像NLP那样产生很大的影响力可能是因为预训练很多时候要求有共同的输入。NLP中的文本就是大家的共同语言,所以无论迁移到什么任务之中,只要文本还是共同语言,预训练模型就可以通用。
但是在推荐场景下用户行为的输入,并不是所有场景都是共同语言的。比如说,我们预训练是基于商品推荐用户行为进行的,假如想要迁移到新闻推荐上是会存在困难的,可见推荐之中的范式并不像NLP中一样统一。训练大体也分为几种,无论是“you to I”还是“you to u”的交互,这些不同的预训练使得我们可以在一些general purpose问题上进行较好的预训练,在下游任务中也有更好的效果。
关于协同训练,当前也有很多耳熟能详的工作。
黄超提到由于工业界中存在着大量的数据,这些可以在推荐系统中作为很好的监督信号。这个的难点在于如何通过噪声数据找到和下游任务相关的预训练任务。但是工业界中的大量数据可以很好的帮助到我们。
在协同过滤的问题上,张震补充到既然我们做研究无法获得同工业界那么多的信息,我们是否可以通过其他模态的数据来帮助我们做更好的预训练,如一些文本的描述或图片。这也是一个不错的出发点。
黄超提到,很多时候在推荐系统场景中并没有那么多的数据以供我们产生较好的预训练任务,但是我们有些时候可能会更偏好一些协同训练的模式来引入一些自监督的信号。不管是基于任务,还是特定的上下文或是寻找相关的监督信号,都是比较重要的维度。
吴剑灿对此分析,之前几位关于预训练的自监督模型的介绍都已经很详尽了,而对于协同训练和联合优化,主要补充以下两点。首先要理解对比学习和推荐系统之间的关联和区别,毕竟推荐系统一直采用的都是对比的思想;而对比学习中常用的优化目标infoNCE loss在本质上是和训练系统已有的采样方法是一样的。如果在这个角度来说,自监督的对比学习和传统的推荐系统在解决思路上是没有太大区别的。那么为什么这两年自监督学习在推荐系统中那么火爆?自监督学习给推荐系统带来的实在增益还是值得大家思考的。自监督对比学习的一大优势就是我们可以去利用这种未标记的数据空间,根据我们想要的评价指标如多样性和可解释性来生成各种数据增长策略,以达到更好的效果。
黄超总结到,对比学习作为自监督学习中的一个重要分支,可以有效的灵活构建想要做对比的试图,这在推荐系统中是很灵活的。正如吴剑灿所说,自监督可以有效地利用到大量的没有标注的数据。因为在推荐系统之中,数据的稀疏性是一个很有挑战的问题。仅依赖用户和商品之间的交互行为是远远不够的。
Q2
在不同的推荐场景中,自监督对比学习任务构建有什么不同的有效方式?
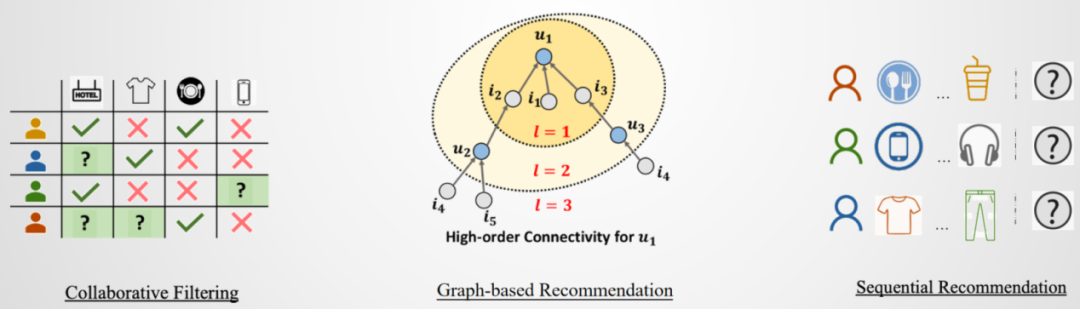
黄超提到,针对不同的推荐场景,我们需要把用户和商品的交互考虑成一个图的结构。我们在上面去做一些图学习的方法来生成用户和商品的embedding进行推荐,其特点在于我们首先考虑到用户对于商品的爱好是随着时间而变化的,这两方面都是值得我们去考虑的。
武楚涵对此表示,自监督对比学习的任务构建还是存在很大差异的,随着Transformer结构越来越有效,无论是工业界和还是学术界,Transformer都已经成为了核心的架构。但是我们发现,Transformer最擅长的是用户亲密行为之间的交互。我们发现用户之间存在各种异构的行为,每一种行为之间还有各自的meta data。
因此,我们可以通过Transformer这种强大的序列和交互能力,学习到丰富的用户行为之间的联系。sequential condition中的任务设计大部分还是以mask为基准的自监督任务设计方式,即便用户的兴趣会随着事件发生变化,但是也总会存在一些长期稳定的兴趣。对于负样本的选择,大部分方法要么是选择随机的负样本,要么是使用难负样本的采样。
黄超总结到,在sequential condition这个数据场景下,我们想要做数据增强的方法还是非常多且灵活的,取决于大家研究的侧重点,是时间维度上做增强还是基于数据稀疏性来做增强。
张震针对在图上做自监督对比学习提出了他的看法,在图上做自监督对比学习本质上是拉近相似的样本,在图这种数据上的核心问题就变成了如何构建正样本对和负样本对。当下最常见的做法是删除一些节点、边或子图等等。但是我们需要思考这样生成的是否是正样本对。以GNN为例,我们随便删除点和边会对节点的表征产生很大影响,所以当前用的很多方法并不能保证我们在做随机的增删点、边后能得到正样本。
吴剑灿提到,现有的基于图的自监督学习在做数据增强的时候其实是可以总结出三种类型的数据增强方式。一种是对图结构做出改变;一种是在表征层面做增强,比如对embedding做drop out,也可以对学出的表征做扰动,扰动后就有了不同的节点视图;一种是在model层面做数据增强。除了数据增强层面,还要优化目标层面。
黄超总结到,随机采样一些item作为负样本就很可能采集到比较popular的样本,这对模型也是一种损伤。对于sequential condition场景,我们可以从很多角度出发,只要能学到一个比较好的sequential pattern就行。对图而言,基于图的自监督或对比学习视图构建对无论是协同过滤还是推荐系统都起到了数据增强效果。
Q3
在不同的场景中自监督学习面临什么挑战?
黄超提到,刚刚大家都提到比较难的一点是如何选择正负样本。很多时候是存在难负样本的,无论是在sequential场景还是图场景。
武楚涵分享了他的看法,无论是推荐系统本身的训练还是自监督学习中都是非常常用的,但是对难负样本的选择也不能太难。如今大家也发现难负样本会使得模型很快陷入局部最优解,并不能得到特别好的结果,而且embedding的相似度也会出现问题。如今对难负样本的选择可能是偏向于子集中较难的,又或者是全集中比较难的,一方面样本足够难,模型可以收敛的更快;另一方面,足够的难度也会使得model变得confusing,对模型反而有害。因此对于负样本对选择,既要具有足够的代表性,而且要均匀。当下的选择大都是让随机样本与难负样本二者合并,这样既能保证样本的均匀,难度也会足够大。同时在推荐系统之中,我们发现负样本的数量也不是越多越好。由于推荐系统中的数据嘈杂,负样本无论是过多或过少,对整个样本质量都是不利的。保证适合数量的负样本,对于自监督学习也是一个挑战。
张震也表示他最近正在尝试通过强化学习的方式帮助人们自动选择一些倾向于是positive sample的view来帮助我们做自监督的对比学习。由于强化学习不是很稳定,训练过程还面临着各种各样的问题。
黄超提出图作为推荐系统中重要的方法,如何在图上进行结构学习来选择正负样本甚至学习到一些隐含的关系而不是直接观察,都是需要我们之后考虑的。他还提出了超图的概念,通过同时连接多个点的方式来建立一个可学习的超边和点之间的关系,也是学到一个基于全局的用户embedding,一定程度上也是可以和本身可观测到的local用户embedding起到数据增强的效果。鉴于推荐系统中大多数实际数据都存在很多的噪音,如何在有噪音的数据上设计一个鲁棒性的自监督方式来做推荐系统是需要我们考虑的。
武楚涵对这个问题做出了解答,真实的推荐系统中的噪声是巨大的,想降低噪声,还是要引入一些多类型的behaviour,比如点击行为的反馈是不够的,而且嘈杂行为远超我们想象。想要应对点击行为带来的噪声问题,引入其他的反馈是非常有效的。其他的反馈包含用户停留的时间、用户的分享都是可以给推荐系统提供的较强反馈。这也使得噪声的影响得到了很大程度的降低。但是又因为部分场景下数据的难以获取,所以要想减少推荐系统中自监督学习面临的噪声问题,我们需要一些更加鲁棒的模型。现在一些工作除了使用自编码器来减少噪声,还会在损失函数的设计上采取一些技巧。
黄超提到,接触额外的数据是一个很有用且能表示用户真实兴趣的一点。另外,如何通过不同对比学习view之间的关系来过滤掉一些不相关且有噪音的信息,来提取到更有用的自监督信号,这也可以在推荐系统中起到对抗噪音的效果。
武楚涵还针对这个问题做了补充,推荐系统和其他学科结合的十分紧密。他以新闻推荐为例,说明其与传媒学的联系很密切。新闻和商品存在区别,商品买不买都可以,但是我们浏览到的新闻却带有很强的社会属性,与社会学、心理学都有着关联。
Q4
多模态的数据引入到推荐系统中,如何更好地实现模态数据的融合?
针对多模态,黄超对其进行了简单介绍,如同超市中的商品不止有ID信息,还有文字介绍、图片和音频等各种各样模态的数据。如何在多模态信息存在的情况下做数据增强,即便是数据稀疏的小众商品,如何在如此多模态数据的基础上做数据增强或者实现有效自监督信号的产生,是我们目前普遍关心而且值得讨论的。
张震对此分享了他的看法,如我们在逛淘宝时看到的文字、图片和视频等信息,利用好这些多模态信息可以帮助我们解决商品的冷启动问题和提取商品的表征。做模型融合的话,目前最常用的方法是对文本进行建模或是对图片进行建模。对文本进行建模可能会用到如BERT等知名的语言模型,对图片进行建模可能会涉及深度卷积神经网络等等。在融合层面,无论是早期融合还是embedding阶段做后期融合,对于多个不同模态之间的直接融合,一个比较直观的想法就是用attention等一系列操作帮助我们融合多个模态之间的信息。如果转入到自监督场景下,我们可以将其当作一个样本的多个view之间进行的结构学习。把商品的文本表征和图片表征映射到同一个语义空间中,我们将其当作一个正样本做结构学习等等,并对多模态的表征进行大一统的融合。目前的问题在于如果将多个模块的数据同时融入进来,那么我们训练的推荐模型不仅可以在我们的推荐任务上取得很好的效果,还可以在一些下游任务上表现出色。
黄超也认为刚刚提到的不同模式下多模态数据务的引入对推荐任务进行增强是很有意义的。
武楚涵分享了他的看法,如今的视觉语义模型就是一种非常好的产生多模态embedding的方式,其对于item的增强是起到很大作用的。另一方面,多模态也可以在对比学习方面实现很好的对齐,比如商品的文本对文本,图像对图像。这样其实不仅有了模态内部的对比,还有了跨模态的对比。在推荐系统之中,多模态数据使得对比学习的任务构建更加丰富了。
吴剑灿针对多模态这种情况提出了“信息偏食”这一概念,字面意思上是说只吃一类食物而造成的营养不良,在推荐系统中指的是只推荐用户喜欢看的东西而带来的信息茧房。其中的核心就是捕捉推荐系统对用户的影响top-effect,无论是利用多模态还是跨模态数据。他还强调在做多模态的预训练时,可以考虑加入一些额外的信息如模板等作为一个中转来学到更好的表示。
黄超总结到,信息偏食这个问题引得我们思考如何在推荐的多元化上面调整用户偏食的习惯,来引导其尝试其他的推荐内容。同时,NLP中在做文本表征学习的时候加入一些上下文的信息,就可以起到一个文本信息表征学习增强的作用。结合到多模态的场景,我们可以在学习商品表征时告诉模型商品其图片是什么,是什么内容的数据。这样当我们将其输入模型的时候就可以起到一种上下文增强的作用。
提
醒
点击“阅读原文”,即可观看本场精彩回放
整理:林 则
审核:黄超、张震、武楚涵、吴剑灿
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了800多位海内外讲者,举办了逾350场活动,超300万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!