前言
在实际业务之中,我们经常会遇见双表查询的问题。如何更加优雅,以及更加快的拿到我们所想要的数据。这便是我们经常所会遇见的问题。
最简单解决问题的方式,便是我们要得到一份详细的数据,来知道MYSQL对于这条SQL是如何解析的,每一句扫描了多少行,返回了多少数据。但是MYSQL似乎并没有给出这个问题的答案。因此想要知道如何,就只能依靠工程师们自己的经验。
下面,我们就根据一个实际并且简单的也无需求来谈论这个问题。
知道LEFT JOIN 在不同的查询条件下执行步骤
基础问题
假设我们在做一个简单的快递项目。当前我们有一个需求:
便是在我们后台项目之中,增加一个查询页面,查询出当前所有快递(express)的信息,以及快递的发件人(user)的姓名。
解决这个问题的SQL很简单:
SELECT * FROM express e LEFT JOIN user u ON e.user_id = u.user_id LIMIT 10;
现在我们查看其执行计划
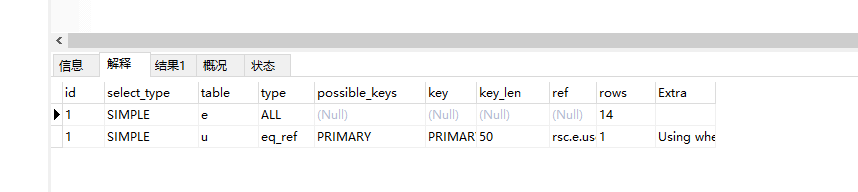
我们可以简单的解析出SQL的执行步骤:
1.先查询 express , 预计扫描条数 14 条,由于我们LIMIT 10 ,因此MYSQL只会查询前十条数据。
2.根据这十条数据的user_id 来得到对应user信息。
这应该是大家对于 LEFT JOIN的第一印象。
整体SQL作为主导的是在于LEFT JOIN 左边的表,LEFT JOIN 右边的表根据得到对应的信息进行整合数据
增加名称查询条件
增加用户名称作为查询条件
SQL也将修改,变成了
SELECT * FROM express e LEFT JOIN user u ON e.user_id = u.user_id
WHERE u.`name` = '王婆子' LIMIT 10;
这时候我们再看解释后的语句

这时候我们查看SQL运行计划,似乎发生了变化。express 用上了索引,查询条数,扫描次数只剩下了3条。
因此,我们能推导出来,MYSQL查询逻辑似乎出现了编号。
1.MYSQL先根据 name ,查询出USER之中符合的条数
2.之后使用user_id查询出express符合的条数。
3.之后再将两张表的结果进行组合。
在这方面上我们似乎知道了另一个事实,LEFT JOIN 并不是只有一个查询逻辑,在1之中的查询逻辑,只是MYSQL一种甚至主要使用的一种查询逻辑。
LEFT JOIN 逻辑会根据对应的查询条件以及表索引。自主的选择“最好”的查询方案。
总结
这上文之中,我们不难得出结论。
- LEFT JOIN 甚至说 整个 JOIN 体系(甚至可以引申到所有在查询条件内可以写入两张表的查询语句),他的查询逻辑并不是单一的。
- 由于查询逻辑并不单一,因此他的如果 LEFT JOIN SQL越是复杂,那么他的查询逻辑越是难以捉摸,可能会出现由于参数的不同,出现不同的查询逻辑。因此最好 SQL 之中的 LEFT JOIN 不能太多。