4.1、使用索引的目的
- 使用索引是为了提高查询的效率,对于数据库表而言,使用索引查找类似于使用书的目录查找文章类似。
4.2、索引常见的模型类型
- 哈希表
- 键-值(key-value)存储数据的结构,使用不同的 key 经过哈希算法算出在哈希表中某个桶的位置,之后由于哈希冲突的原因,所查找的位置上可能有不同 key 算出的相同的哈希值,因此使用拉链法将这些发生冲突的 Entry 对象通过单链表的形式相连接,因此如果在查询的时候遇到需要在单链表中在查询的情况,需要一个个的遍历链表上的结点比较 key 值,使得最终查询的效率大大降低。
- 有序数组
- 有序数组在单个查找和区间查找的效率都非常地高效,在数据不会出现相同的情况,让数据使用递增递减地方式存储在有序数组中,需要查找某个数据使用二分法查找器查找的时间复杂度为 O(logn),即使是区间查找,只要使用二分查找查找到属于区间左边的的最小值的位置之后向递增的方向遍历寻找到大于区间右边的值的前一个数即可完成查找区间范围的值。
- 虽然有序数组在查询方面效率比较高,但是在增加或删除数据时,需要移动后面所有的数据,需要耗费大量的时间,因此有序数组只适用于静态表的查询。
- 搜索树
- 其中二叉搜索树满足左节点小于父节点,右节点大于父节点,因此使得在二叉搜索树中查询的时间复杂度只要 O(logn),但是为了查询的效率稳定在 O(logn) 的范围,因此需要保证这是个平衡二叉排序树,否则二叉搜索树慢慢变成链表结构。
- 排序中二叉排序树的查询效率是最高的,由于索引不只是要存储在内存中还要存储在磁盘中,然而在二叉树中一个父节点只能有两个结点导致最终生成的数据在树中存储的后,其树的高度会比较大,导致在查询读取某个数据的时候,磁盘要访问的数据块会比较多,从而拉低了查询的效率,为了减少读取数据块的次数,应该使用 N 叉排序树,让父结点中的 N 个子节点从左至右递增排序,至于这里 N 的值取决于数据块的大小。
- 由于 N 叉排序树高效率的读写,以及适配磁盘的访问模式,被广泛的应用于数据库引擎中。
4.3、InnoDB 的索引模型
- 由于索引模型是在引擎中实现的,因此索引模型并没有统一的标准,即不同的存储引擎的索引的工作方式并不一样,即使多个存储引擎支持同一种类型的索引,其底层的实现也是不尽相同的,而 InnoDB 是 Mysql 中使用最广泛的存储引擎。
- 在 InnoDB 引擎中,表是根据主键顺序以索引的形式存放的,这种存储方式的表称之为索引组织表。而 InnoDB 使用的是 B+树索引模型,因此这些数据都是存储在 B+树 中的。每一个索引在 InnoDB 里面对应着一颗 B+树。
- 假设有个表其中主键 ID,表中含有字段 k,k 上添加索引。表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6),两棵树的示例示意图:
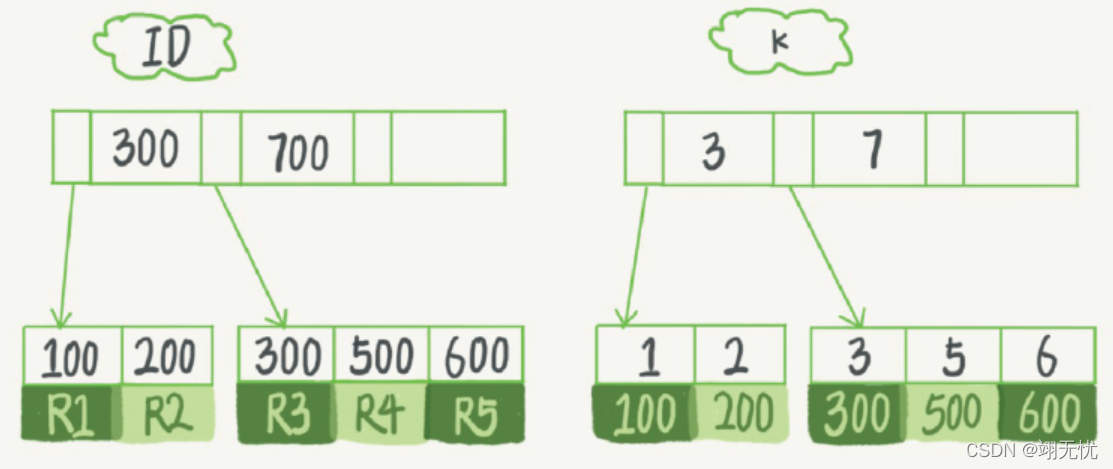
- 图中左边是主键索引,也称聚簇索引,其中叶子节点存储的是 R1~R5 整行数据的值,而右边的非主键索引,也称之为二级索引,其中叶子节点存储的主键的值。
- 使用主键查询和非主键查询的区别?
- 执行 select * from T where ID=500; 即使用主键 ID 进行查询,只需要在左边这个主键索引这颗 B+树 上进行搜索即可得到最终叶子节点中整行数据的值
- 执行 select * from T where k=5; 即使用普通索引查询的方式,则需要现在 k B+树上进行查询获取到其主键的值,再到主键 B+树 上进行二次搜索获取具体一行的值。
- 因此得出结论,使用主键查询只需要在主键 B+树上进行一次查询即可,然后使用普通索引则额外需要在对应的普通索引的 B+树 上进行一次搜索得到查询的主键的值。因此在查询中尽量使用主键查询,减少普通索引查找。
4.4、索引维护
- B+树为了维护索引的有序性,在插入新值的时候需要做必要的维护。以上图为例如果要插入新的一行记录中 ID 的值为 700,那么只需要在 B+树 中的 R5 后面添加即可,但是如果要添加的一行记录中的 ID 值为 400,那就比较麻烦,需要移动 R4 及其之后的结点,更糟糕的是如果此时 R5 所在的数据页已经满了,那么就需要申请新的一页数据页,然后使用挪动部分数据到新的数据页中,这个过程称之为分裂,这种情况下,性能自然会受到影响,并且还会降低数据页的利用率,原本一页数据使用两页数据页来进行存储。当然有分裂自然有合并,当相邻的两个数据页由于删除了数据,使得数据页的空间利用率很低,因此将数据页进行合并,合并的过程即为分裂过程的逆过程。
- 在某些建表规范中要求表中使用自增的主键(Not Null Primary Key Auto_Increment),这是由于如果使用带有业务逻辑的值作为主键,导致不能保证有序的添加数据造成写成本比较高,除此之外,即使使用具有唯一性的数据作为主键,例如身份证号作为主键,其数据类型使用的 biging 需要占用 8个字节,导致在二级索引树种其叶子节点所占的存储空间会相对于使用 int 数据类型占用 4 个字节所耗损的空间要大得多,因此使用自增主键既可以满足性能上以及存储空间上往往都是比较合理的选择。
- 在典型的 KV 场景中,就只能适用于使用具有业务逻辑的字段作为主键,只有一个索引,并且该索引必须是唯一的索引。
4.5、小结
- 分析了数据库中引擎中可用的数据结构,介绍了 InnoDB 采用 B+树 结构及其原因,B+树 具有高效率的读写能力以及很好的配合了磁盘的读写性,使得磁盘访问更少的数据块,减少单次查询中访问磁盘的次数从而提高查询效率。并且由于 InnoDB 使用的是索引组织表,因此推荐使用自增主键,这样非主键的二级索引 B+树 中的叶子结点占用的内存较少,并且减少写数据的成本,但是在 K-V 应用场景中还是只能使用带有业务逻辑的字段作为主键。
4.6、问题
- 重建索引 k

- 重建主键索引

- 首先为什么需要重建索引?
- 索引可能会因为数据的删除,或者因为插入数据的时候由于数据页已经满了,导致不得不申请新的数据页用于后移的数据的存储(也分裂),导致数据页出现空洞,从而使用重建索引的方式创建新的索引,把数据按顺序插入,填充数据页的空洞,提高数据页空间的利用率,节省空间。
- 这样做有什么不合适的?有什么更好的方式?
- 重建普通索引 k 的做法是合理的,可以达到节省空间的目的。但是重建主键的方式是不合理的,原因是无论是删除主键还是创建主键都会删除整个表进行整张表的重建,因此第一条 SQL 语句是多余的,可以选择执行 alter table T engine=InnoDB。
版权声明:本文为wmt0501原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。