paper—《Bag of Tricks for Image Classification with Convolutional Neural Networks》中提到
“Using large batch size, however, may slow down the training progress. For convex problems, convergence rate decreases as batch size increases. Similar empirical results have been reported for neural networks [25]. In other words, for the same number of epochs, training with a large batch size results in a model with degraded validation accuracy compared to the ones trained with smaller batch sizes”
针对这句话,有个问题:
从理论上来讲,batch size increases能够使得训练中数据的方差更小,即更加不易受小样本更新时噪声的影响,其训练速度会更快,那为什么最后会导致泛化性能下降?
带着这个问题,找到了这篇paper—《ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA》,其中提到两点来解释这个现象,并给出了实验来支撑:
(1)LB(large-batch) methods lack the explorative properties of SB(small-batch) methods and tend to zoom-in on the minimizer closest to the initial point;(翻译:相比SB,LB缺乏探索能力,导致其更接近损失函数的初始点)
(2) SB and LB methods converge to qualitatively different minimizers with differing generalization properties.(翻译:SB和LB收敛到不同位置,导致其泛化能力有差异)
然后,作者利用如下曲线来说明了SB能够收敛到flat minimizers,LB收敛到sharp-minimizers。
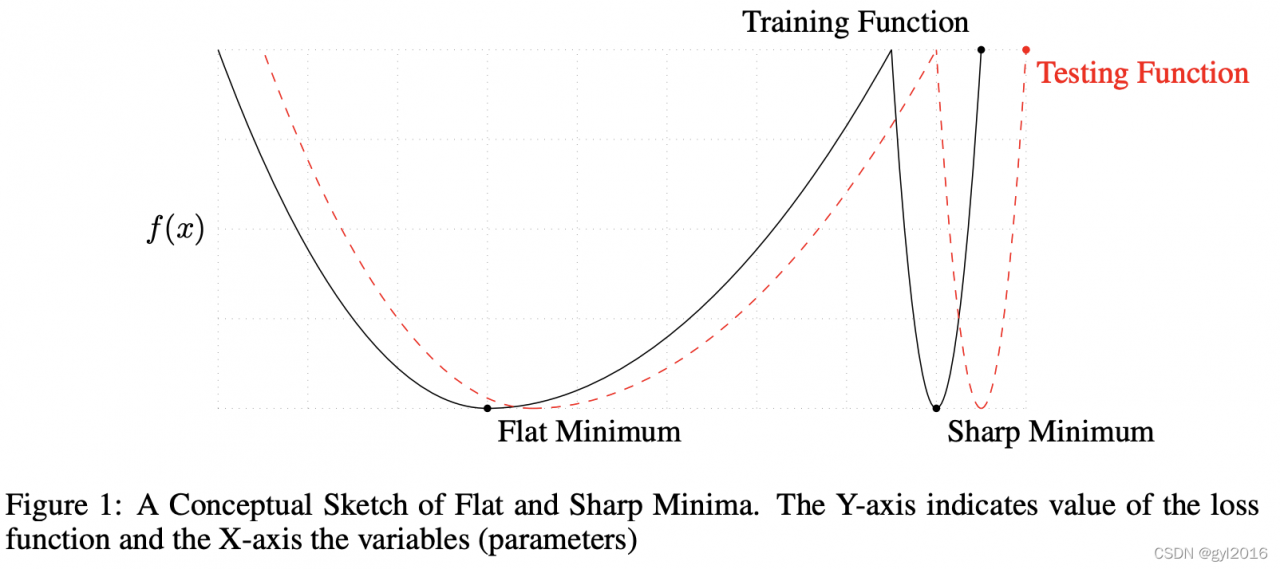
那就有个问题:为什么flat-minimizers要比sharp-minimizers的泛化性能更好?
sharp minimizers:the function increases rapidly in a small neighborhood
flat minimizers:the function varies slowly in a relatively large neighborhood
答:从上面的曲线可以看出一些端倪,flat-minimizers曲线更平缓,而sharp-minimizers曲线更剧烈,所以对于参数的微小抖动,flat-minimizers更不敏感,泛化性能更好。(补充一点,flat minimizers和sharp-minimizers其实都是一个局部最优解——参考1)
那为什么LB会收敛到sharp-minimizers?
答:对于LB,它不会改变随机梯度的期望,但是会改变梯度的方差,使得梯度的方差减少(减少了噪声的影响——参考2),使得估计的梯度包含的噪声不足以跳出sharp型的局部最优,导致模型收敛到sharp minimizers——即上述现象1:LB缺乏探索能力。
那如何缓解这个问题呢?
答:(1)certain number of epochs of warm-start;(2)data augmentation;(3)conservative training;(4)adversarial training;(5)更大的学习率——影响收敛,前期一般配合warm-start更好(见参考5: for large minibatches (e.g., 8k) the linear scaling rule breaks down when the network is changing rapidly, which commonly occurs in early stages of training);
对于warm-start和更大的学习率:
(1)CLR,在一个固定的区间内周期的调整学习率;——参考3
(2)SGDR,周期的重启学习率;——参考4
(3)Gradual warmup strategy 和 Linear scaling learning rate;——参考5
另外还有一篇文章也进行了相关探索——DON’T DECAY THE LEARNING RATE, INCREASE THE BATCH SIZE。
附:
参考文献5:
(1)Linear scaling learning rate:When the mini-batch size is multiplied by K,multiply the learning-rate by K.
(2)start from a learning rate of η and increment it by a constant amount at each iteration such that it reaches ηˆ = kη after 5 epochs。
(3)分布式并行gpu上训练时,当batch-size小于等于8192时,能维持原有泛化性能;当batch-size大于等于8192时,largest mini-batches的泛化性能会随着batch-size增大下降;
参考
2、Bag of Tricks for Image Classification with Convolutional Neural Networks
3、cyclical learning rates for training neural networks
4、sgdr: stochastic gradient descent with restarts
5、Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour