好久没有更文了,写文章真的很费时间,也不是为了啥,主要就是想沉淀学习过程中的一些知识。
做了这么久的数据挖掘,主要还是ETL和算法,打算把这一部分知识好好的梳理一下。关于数据的分层就后面再聊了,最近主要还是说如何做ETL吧。本次内容主要就是介绍下Hive的数据类型、关系运算。下一篇就介绍SparkSQL/Hive的一些内置函数和开创函数以及自定义函数UDF吧。
数据类型是数据的一个基本属性,用于区分不同类型的数据,不同的数据类型所占的存储空间也是不相同的,在创建表之前我们就可以想清楚字段的类型,在存储方面也能节省一定的空间,定义好了数据类型,当我们在存储数据时也必须遵守该字段的数据类型,不然就会报错的哟 。
。
基础数据类型
| 数据类型 | 描述 | 存储大小 | 范围 |
| int | 整数型 | 4个字节 | |
| string | 字符串 | 看存入多大了 | |
| double | 双精度浮点型 | 4字节 | |
| decimal | 固定有效位数 | ||
| Boolean | 布尔类型 | true/false | |
| smallint | 有符号整数 | 16字节 | -32768-32768 |
| tinyint | 整数 | 16字节 | -128-127 |
| bigint | 整数 | 64字节 | 很大 |
| varchar | 可变长度字符 | ||
| binary | 二进制数 | 0/1 | |
| date | 日期 | ||
| timestamp | 时间戳 |
其他数据类型
| 数据类型 | 描述 |
| map | java类似,一组无序键值对 |
| array | 一段有序序列,对应Java arraylist |
| struct | 一组命名的字段,字段类型可以不同 |
map: 假设定义类型 map,字段的建为string类型,值为int型。在数据库中表现为{"k1":v1,"k2":v2},有点像json的感觉。
array: 常用就array,array类型,在数据库中表现形式类似于[1,2,3,4]之类的,用中括号的。
struct:感觉和map差不多吧,但是呢,他也可以单独查询里面的k,v列。用得不多。
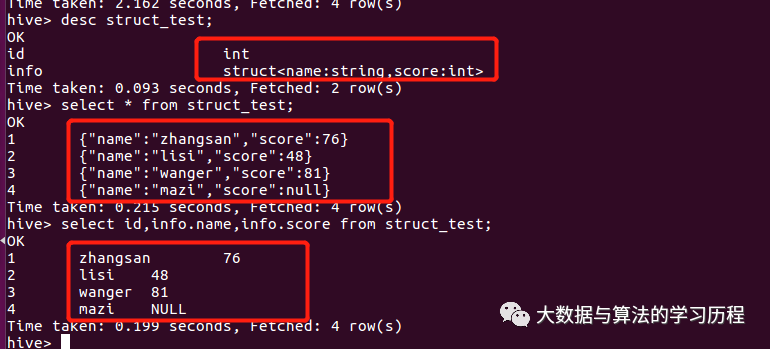
其他的都比较好理解,就不举例了,主要还是方便自己看 。
。
有类型肯定就有数据类型转换的操作瑟,数据类型转换就是相当的简单了。关键字cast。
比如说字符串转日期,YYYY-MM-dd这种,前提是能转哈,向‘a’这种转int肯定是不行的,比如说,cast(string as date) ;cast(string as int)。。。
运算符
关系运算符,都是些常用的,用于数据类型之间的比较,并且返回一个boolean,这里就简单描述下,做开发的sql也写得不少,这些简单的就稍微带过就好了。
| 运算符 | 描述 |
| = | 判断是否相等 |
| <> | 判断不相等 |
| != | 判断不相等,和<>差不多 |
| > | 判断小于/大于 |
| <=/>= | 小于等于/大于等于 |
| between and | 判断是否在区间 |
| is null | 判断是否为空 |
| is not null | 判断不为空 |
| like | 匹配,常与%一起使用,%代表任意匹配 |
| not like | 和like相反 |
| rlike | 是否包含子字符串匹配 |
算术运算符,常用的不外乎就是+、-、*、/、%(取余),这里就不介绍了。
逻辑运算符常用的也就是and 、or、not、in、not in这些。都是些比较简单的概念性的东西,一看就懂一看就明白。
后面逐渐会稍微难点了,主要分以下几个部分。内置函数以及开窗的使用和udf的开发,以及表操作和一些ETL常用的命令之类的,然后就是关于在spark上任务调优这些就差不多了,其他sql解决不了的也就只能依赖spark程序了。