序言
本章的关键词是 SnapShot, FileSnap 实现, 以及实现日志 TxnLog和SnapShot接口的 FileTxnSnapLog ,通过 这几个接口的进行持久化和加载持久化到内存的一些操作。
其间涉及 关键数据结构,zk的树形存储结构的设计 DataTree 和节点 DataNode,ACL等结构的解说
正文
zk 里面持久化有两种方式,一种是全量 持久化,一种是增量持久化, 这两种持久化的方式,在其他组件的设计方案里面也有见到,因为全量持久化解决的是持久化到序列化到内存的效率问题,而增量持久化是保持数据同步到磁盘数据比较同步的一种方式。 像redis, rdb持久化和aof持久化. 这一节我们来看看 zk里面如何做 snapshot 持久化,也就是所谓的快照持久化,这个词意味着就是在某一个时机,要把内存中的全部数据落盘。
我们关注snapshot持久化的时候,要关注我们最关注的问题:
- 什么时机进行 snapshot持久化?
- 怎么进行持久化?怎么反序列化到内存?
- 持久化的文件是怎么管理的,还有就是zk最核心的存储数据结构的窥探
跟着如上问题,我们来慢慢解析,zk snapshot持久化的过程
首先我们先来看 SnapShot 接口的定义
可以看到整体接口还是相当简洁的,从名字就能知道接口是干嘛的。清晰,在此笔者不表。
可以看到序列化和反序列化的核心数据结构是DataTree这个数据结构,这个其实就算是zk 在内存中的数据结构的体现,我们常说好的程序,其实就是由好的数据结构和算法组成的,从zk设计者中设计出的DataTree,我们能看出怎样的结构化设计思想。
我们先来看看这个DataTree的类文件头的注释,作者写得清清楚楚,它的存在的含义和功能边界
/**
* This class maintains the tree data structure. It doesn't have any networking
* or client connection code in it so that it can be tested in a stand alone
* way.
* <p>
* The tree maintains two parallel data structures: a hashtable that maps from
* full paths to DataNodes and a tree of DataNodes. All accesses to a path is
* through the hashtable. The tree is traversed only when serializing to disk.
*/
public class DataTree {
} |
接着我们还是来简单了解下 ,DataTree这个东西的组成,众所周知,我们想要了解一个事物的路径都是差不多一致的。我们要先知道东西的功用,才能深入了解到这东西是如何实现这个功用的。我们在这里简单复习下
zk的核心功能,这对我们看DataTree 有一定的借鉴作用。
zk的核心功能:
- 以树形结构(类似于文件系统的树形结构)存储父子关系,路径唯一,节点上能带一些payload 信息
- 有acl 权限控制,简单的基于角色验证的权限控制
- 有监听节点单次触发的watch机制,有临时节点,临时有序节点的高级特性
- 最核心的当然是保证 分布式情况下的,事务有序性,这里谈的比较抽象,事务有序性指的是,写操作能够有序地被执行,这样分布式情况下数据高度统一,有完善的failover机制,选举机制,心跳机制
好,知道这些以后,我们先来看看基本的树形的存储结构的实现
这里比较清楚的说明了,NodeHashMap就是这个存储结构,继续查看
看下这个NodeHashMap的接口
可以看到对外暴露的是常规的增删查改操作,还有一个比较不同普通容器的接口的就是这个 Digest (摘要),这个摘要的存在是为了什么的。我们直入主题,看下这个Digest的实现
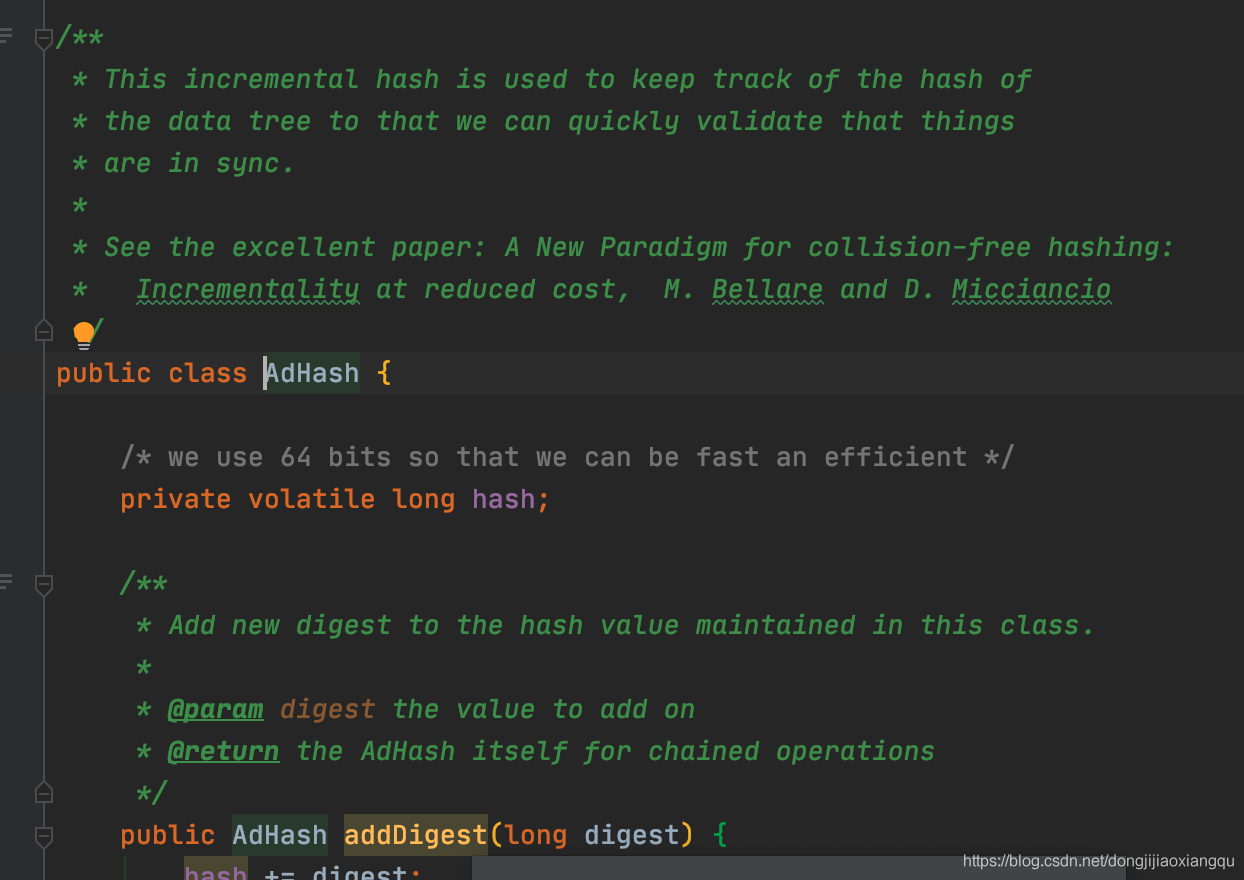
可以文件头注释,可以看到这个digest的解释是,保存整体NodeHashMap的每个节点的hash值并进行累加或者删减的操作,通过这种方式能够track 整体HashMap里面的值有没有数据变更,里面还特意提到sync的时候,估计是 从节点需要同步主节点数据时候,不能让主节点的数据被篡改的一种摘要校验。这种保证全局数据有没有被改动而进行的hash 累加的方式,也是值得学习的。这让我想起了,有些组件的其他判断数据有无变更的方式,是通过version累加的方式来进行的,通过cas判断来查看是否有数据变更。
然后继续查看这个NodeHashMap实现,主体的实现还是比较清晰简单
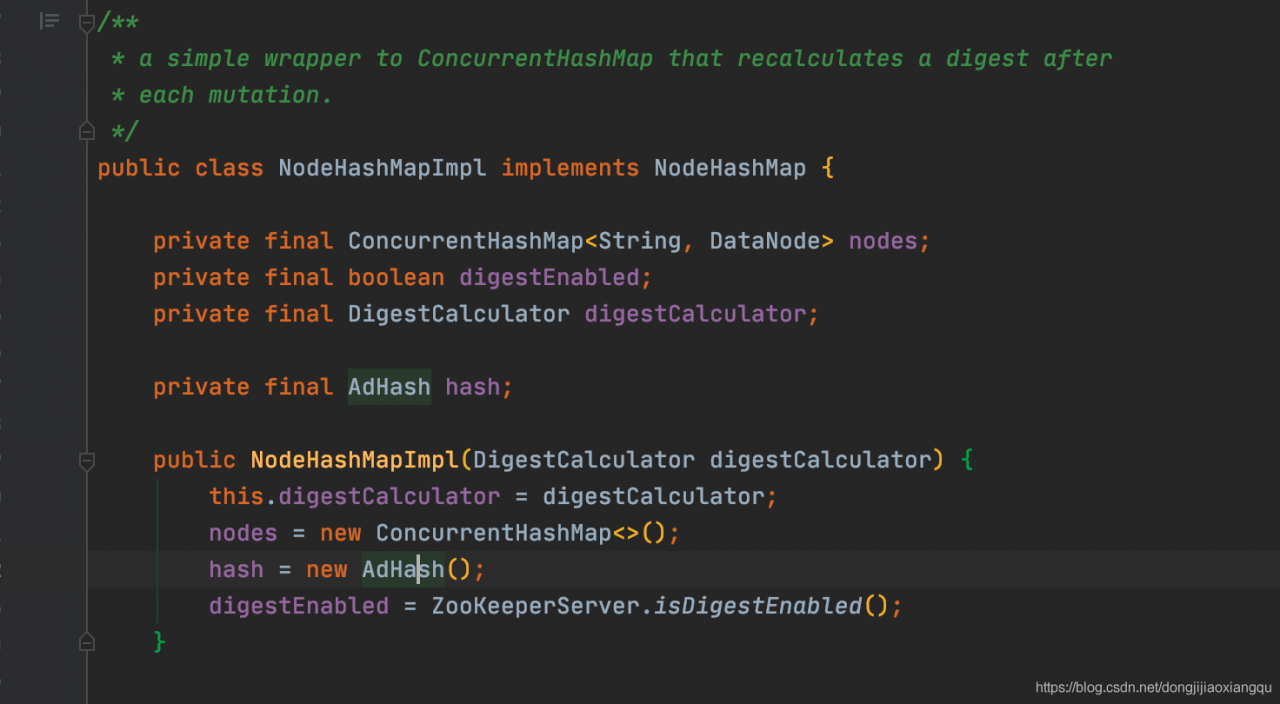
通过包装ConcurrentHashMap来存节点信息,然后看下DataNode的实现结构
在这里笔者直接截取重点了,其他一些支路信息,笔者有意跳过,包括一些元数据信息,包括持久化信息,node节点相关信息

这里看到父子关系的存储,是父节点存储子节点列表,这个其实是说明了一些信息的。这样说明了,查找子节点只能从父类往下遍历查找,当然由于是树形路径结构,子节点通过解析路径信息,也能找到父节点。
在此我们就简单看完了整个NodeHashMap的实现。再回过头来看下,这个DataTree其他的一些包含信息
由于这个DataTree是zk里面的核心数据结构,后面肯定会频繁涉及到其中一些细致的信息,在此,笔者就简单提及一些基本介绍。
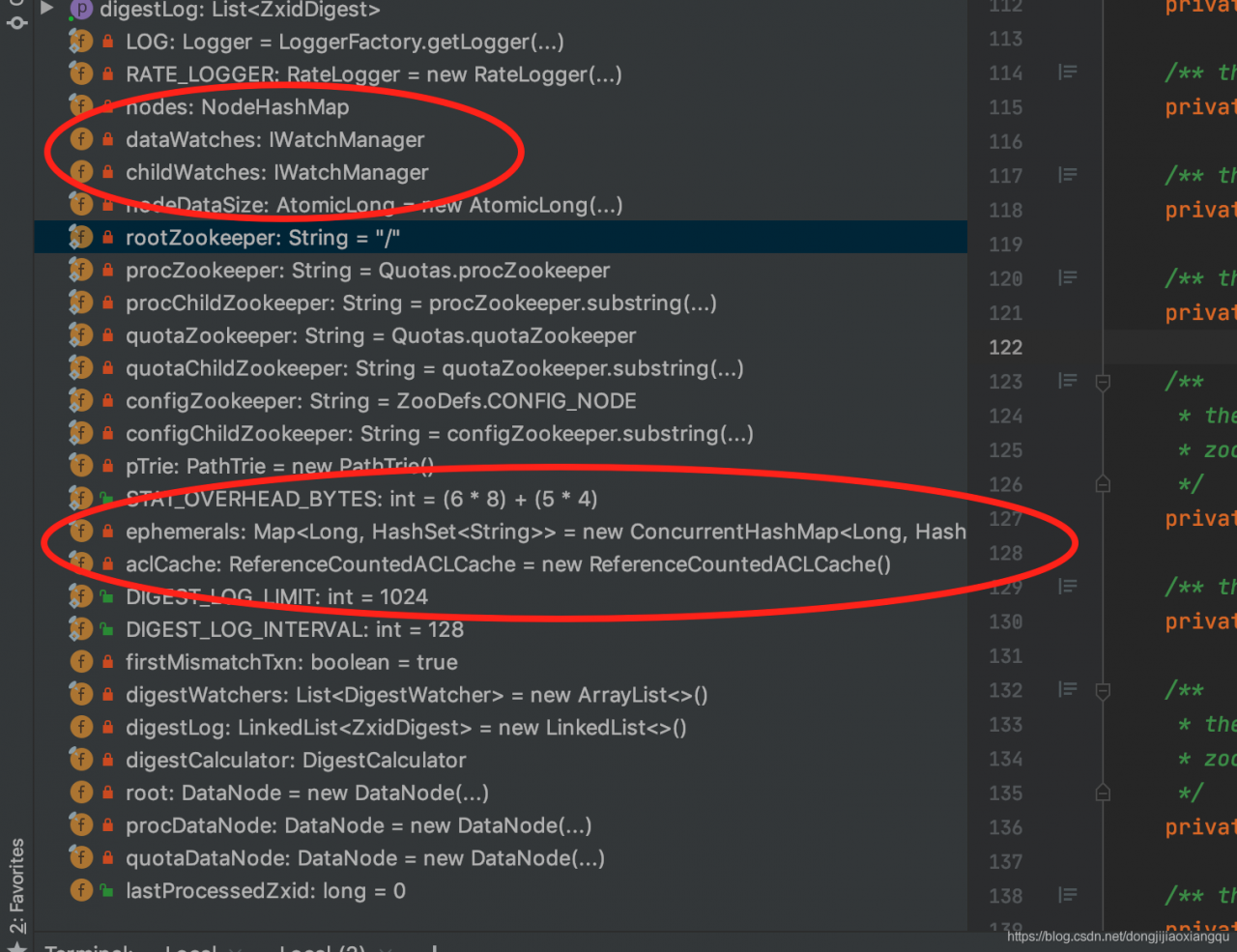
这里需要注意的是dataWatches, childWatches ,这两个看名字可以看出一个是数据变动时候通知观察者,另一个是子节点变动时候通知观察者的,观察列表。还有就是ephemerals 临时节点列表,其他的一些数据变量包括一些 zk的 config 节点和quotas 节点的一些元数据信息。
这里反思一下,读代码的方式有点像深度优先遍历,遇到一个不了解地就会继续往下深入,但是深入的越多也会沉溺于细节不能自拔了。我们回溯到SnapLog这里看下 序列化和反序列化的操作实现。
先看下序列化的实现
/**
* serialize the datatree and session into the file snapshot
* @param dt the datatree to be serialized
* @param sessions the sessions to be serialized
* @param snapShot the file to store snapshot into
* @param fsync sync the file immediately after write
*/
public synchronized void serialize(
DataTree dt,
Map<Long, Integer> sessions,
File snapShot,
boolean fsync) throws IOException {
if (!close) {
try (CheckedOutputStream snapOS = SnapStream.getOutputStream(snapShot, fsync)) {
OutputArchive oa = BinaryOutputArchive.getArchive(snapOS);
FileHeader header = new FileHeader(SNAP_MAGIC, VERSION, dbId);
serialize(dt, sessions, oa, header);
SnapStream.sealStream(snapOS, oa);
// Digest feature was added after the CRC to make it backward
// compatible, the older code cal still read snapshots which
// includes digest.
//
// To check the intact, after adding digest we added another
// CRC check.
if (dt.serializeZxidDigest(oa)) {
SnapStream.sealStream(snapOS, oa);
}
lastSnapshotInfo = new SnapshotInfo(
Util.getZxidFromName(snapShot.getName(), SNAPSHOT_FILE_PREFIX),
snapShot.lastModified() / 1000);
}
} else {
throw new IOException("FileSnap has already been closed");
}
} |
可以看到传进来的是DataTree,和 sessions , snapShot文件是外面通过特定的文件名生成的File, 看下序列化过程,先生成FileHeader, 然后看看序列化函数
/**
* serialize the datatree and sessions
* @param dt the datatree to be serialized
* @param sessions the sessions to be serialized
* @param oa the output archive to serialize into
* @param header the header of this snapshot
* @throws IOException
*/
protected void serialize(
DataTree dt,
Map<Long, Integer> sessions,
OutputArchive oa,
FileHeader header) throws IOException {
// this is really a programmatic error and not something that can
// happen at runtime
if (header == null) {
throw new IllegalStateException("Snapshot's not open for writing: uninitialized header");
}
header.serialize(oa, "fileheader");
SerializeUtils.serializeSnapshot(dt, oa, sessions);
}
|
这个没啥好说,先把header 序列化完以后,再序列化snapshots, 直接看SerializeUtils 里面的实现
public static void serializeSnapshot(DataTree dt, OutputArchive oa, Map<Long, Integer> sessions) throws IOException {
HashMap<Long, Integer> sessSnap = new HashMap<Long, Integer>(sessions);
oa.writeInt(sessSnap.size(), "count");
for (Entry<Long, Integer> entry : sessSnap.entrySet()) {
oa.writeLong(entry.getKey().longValue(), "id");
oa.writeInt(entry.getValue().intValue(), "timeout");
}
dt.serialize(oa, "tree");
} |
看到其先把sessions 序列化完以后,再序列化DataTree,DataTree的序列化和反序列化可以简单查看下
public void serialize(OutputArchive oa, String tag) throws IOException {
serializeAcls(oa);
serializeNodes(oa);
} |
这里就比较清晰了,DataTree的序列化,分为两步,第一步是序列化Acls, 第二步是序列化 Nodes, 其具体实现,在此笔者想不先展开了。观察到Nodes其实是树形结构,通过递归的方式应该能以一种较为简洁的方式来实现。
回到上文内容,
FileSnap序列化完DataTree以后,还做了什么操作
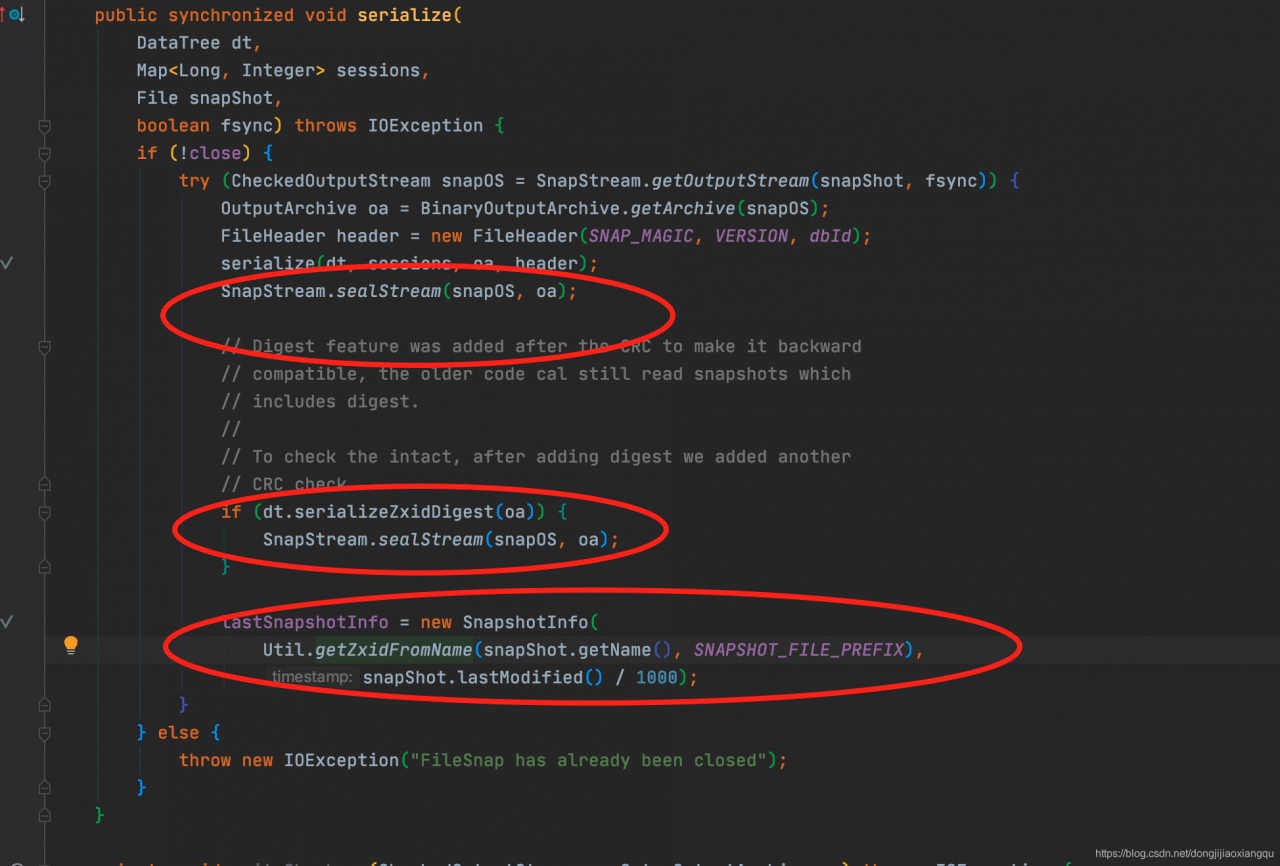
看到红圈处,分别简单介绍这几个方法的作用,第一个是输出checkSum的 sum值序列化后做校验,第二种是序列化摘要,第三个是解析file,返回返回值。
到此Serialize操作就基本完成了。
然后接下去看看,序列化的时机
简单而言就是,在SyncRequestProcessor, 中有个判断,这个Processor 请求链的机制,后面再说
private boolean shouldSnapshot() {
int logCount = zks.getZKDatabase().getTxnCount();
long logSize = zks.getZKDatabase().getTxnSize();
return (logCount > (snapCount / 2 + randRoll))
|| (snapSizeInBytes > 0 && logSize > (snapSizeInBytes / 2 + randSize));
} |
可以看到,判断条件, 查看logCount,和 logSize 是否大于一定的限制。
会新起一个线程就进行序列化操作。
SyncRequestProcessor 中的代码
// track the number of records written to the log
if (!si.isThrottled() && zks.getZKDatabase().append(si)) {
if (shouldSnapshot()) {
resetSnapshotStats();
// roll the log
zks.getZKDatabase().rollLog();
// take a snapshot
if (!snapThreadMutex.tryAcquire()) {
LOG.warn("Too busy to snap, skipping");
} else {
new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
snapThreadMutex.release();
}
}
}.start();
}
}
} else |
可以看到判断可以进行序列化后,会重置需要序列化的状态,然后起后台线程进行序列化操作。
再看下,SnapLog的反序列操作,这次采取简述的方式来描述这个过程了。
/**
* deserialize a data tree from the most recent snapshot
* @return the zxid of the snapshot
*/
public long deserialize(DataTree dt, Map<Long, Integer> sessions) throws IOException {
// we run through 100 snapshots (not all of them)
// if we cannot get it running within 100 snapshots
// we should give up
List<File> snapList = findNValidSnapshots(100);
if (snapList.size() == 0) {
return -1L;
}
File snap = null;
long snapZxid = -1;
boolean foundValid = false;
for (int i = 0, snapListSize = snapList.size(); i < snapListSize; i++) {
snap = snapList.get(i);
LOG.info("Reading snapshot {}", snap);
snapZxid = Util.getZxidFromName(snap.getName(), SNAPSHOT_FILE_PREFIX);
try (CheckedInputStream snapIS = SnapStream.getInputStream(snap)) {
InputArchive ia = BinaryInputArchive.getArchive(snapIS);
deserialize(dt, sessions, ia);
SnapStream.checkSealIntegrity(snapIS, ia);
// Digest feature was added after the CRC to make it backward
// compatible, the older code can still read snapshots which
// includes digest.
//
// To check the intact, after adding digest we added another
// CRC check.
if (dt.deserializeZxidDigest(ia, snapZxid)) {
SnapStream.checkSealIntegrity(snapIS, ia);
}
foundValid = true;
break;
} catch (IOException e) {
LOG.warn("problem reading snap file {}", snap, e);
}
}
if (!foundValid) {
throw new IOException("Not able to find valid snapshots in " + snapDir);
}
dt.lastProcessedZxid = snapZxid;
lastSnapshotInfo = new SnapshotInfo(dt.lastProcessedZxid, snap.lastModified() / 1000);
// compare the digest if this is not a fuzzy snapshot, we want to compare
// and find inconsistent asap.
if (dt.getDigestFromLoadedSnapshot() != null) {
dt.compareSnapshotDigests(dt.lastProcessedZxid);
}
return dt.lastProcessedZxid;
} |
基本逻辑和Serialize 函数基本是相反的,会找最近100个序列化文件,找到一个有效就不继续下去,然后主体内容deSerialize 后,checkSum 会校验。 然后会记录最近反序列化的zxid和相关snapInfo 。
我们看看反序列时机是怎样的,其实可以猜到,一般都是程序起来的时候,进行加载序列化内容。
直接看时机,一个是在ZookeeperServer , loadData() 这里进行,这里是程序起来的时候加载硬盘数据。另一个地方是, QuorumPeer 的loadDataBase() 这个时机,这个应该和分布式机器状态有关,这个后面再讲,基本是程序起来的时候进行数据加载。
至此,我们的FileSnapLog基本就算讲完,主要的功能讲完,我们看下FileTxnSnapLog 这个东西的实现,这个功能其实就是结合前面的 TxnLog 和SnapLog的封装类,就是snapshot 日志和 txnLog 日志持久化相关操作的
封装类。
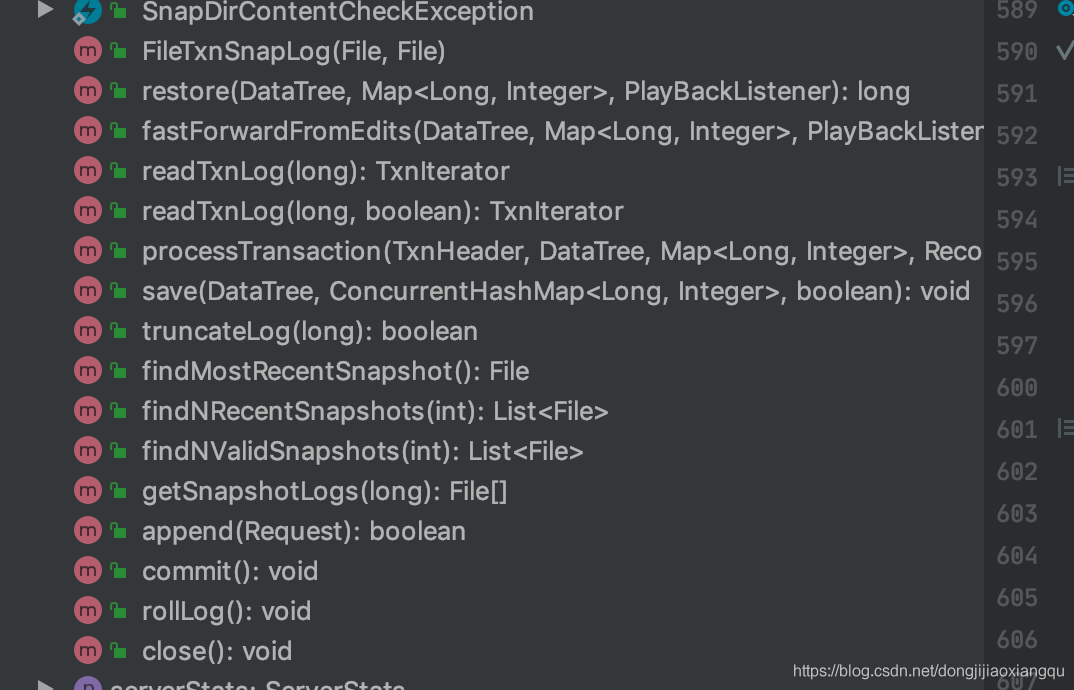
可以看到方法基本是 这两个接口的调用,也可以说是代理模式的实现。
其中有个方法是值得注意的,就是restore 方法,这个方法的主要流程有,首先通过snapLog 先恢复快照日志,然后找到这个SnapLog对应的zxid,从TxnLog中找到比这个zxid大的日志,再继续进行日志反序列化加载,这样就把全量日志,和增量日志都反序列完了。
总结
本文阐述了 SnapLog和FileTxnSnapLog的一些序列化反序列操作,也讲了它们进行序列化和反序列的时机。