Java SE 集合及泛型
文章目录
前言
复习集合及泛型的概念,迭代器的使用,每个集合类型的特点及不同点,Comparator的使用及Comparable接口的实现来重写比较规则,Collections工具类。
集合中的继承结构图
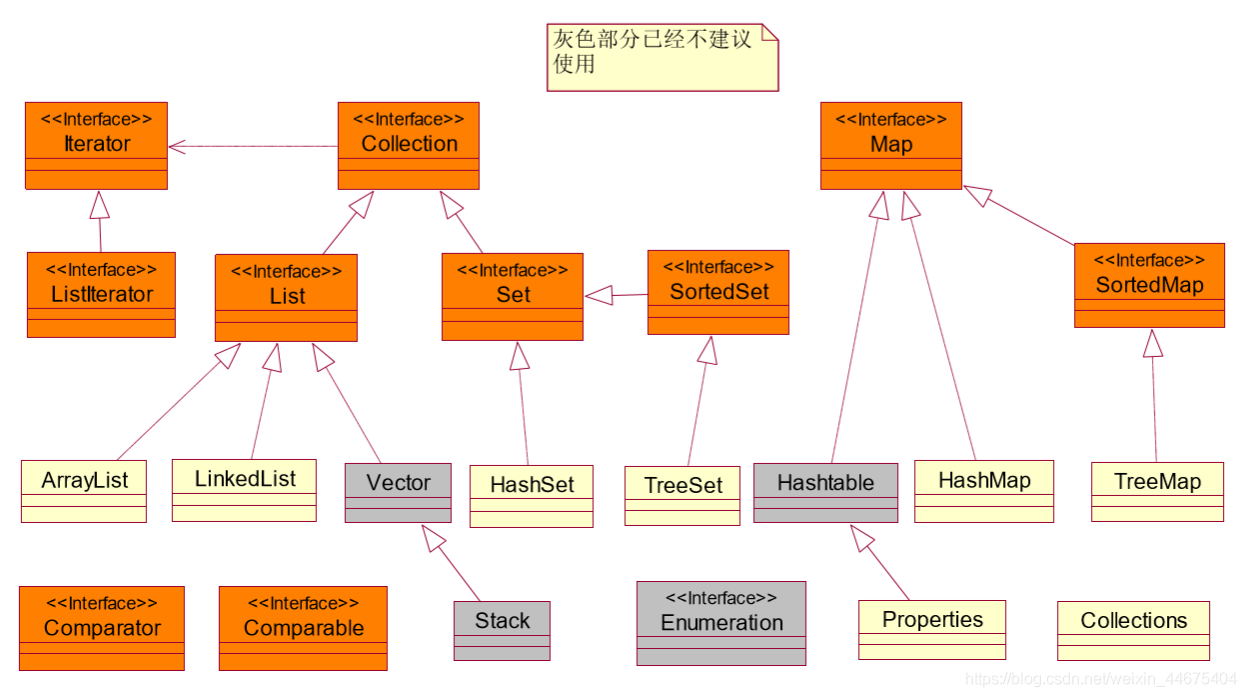 图片来源:www.bjpowernode.com
图片来源:www.bjpowernode.com
一、Collection
Java集合主要有 3 种重要的类型:
List:是一个有序集合,可以放重复的数据
Set:是一个无序集合,不允许放重复的数据
Map:是一个无序集合,集合中包含一个键对象,一个值对象,键对象不允许重复,值对象可以重复,属于和Collection同个层次的接口
1、Iterable和Iterator
Iterable属于java.lang包下的一个接口,是Collection的父类,其中提供了一个方法去获取迭代器对象:
Iterator iterator()
返回类型为 T元素的迭代器。
返回一个迭代器对象去遍历集合
而Iterator则属于java.util包下的一个接口,其中提供了三个方法让我们去遍历集合和删除集合中的元素
boolean hasNext()
如果迭代具有更多元素,则返回 true 。
E next()
返回迭代中的下一个元素。
default void remove()
从底层集合中删除此迭代器返回的最后一个元素(可选操作)。
Collection中实现的是Iterable接口而不是Iterator,Iterable中提供迭代器Iterator去迭代集合中的元素。
2、List 接口
List接口下面主要有两个实现类 ArrayList 和 LinkedList,他们都是有顺序的,也就是放进去是什么顺序,取出来还是什么顺序,基于线性存储,可以看作是一个可变数组
ArrayList(Java.util.ArrayList):查询数据比较快,添加和删除数据比较慢(基于可变数组)
LinkedList(Java.util.LinkedList):查询数据比较慢,添加和删除数据比较快(基于链表数据结构)
Vector:Vector 已经不建议使用,Vector 中的方法都是同步的,效率慢,已经被 ArrayList 取代
Stack是继承 Vector 实现了一个栈,栈结构是后进先出,目前已经被 LinkedList 取代。
import java.util.Iterator;
import java.util.LinkedList;
/*
ArrayList和LinkedList
1、每个集合对象的创建
2、向集合中添加元素
3、从集合中提取元素
4、遍历集合
*/
public class ArrayListTest {
public static void main(String[] args) {
// 创建集合对象
//ArrayList<String> list = new ArrayList<>();
LinkedList<String> list = new LinkedList<>();
// 添加元素
list.add("abc");
list.add("abe");
list.add("aba");
// 从集合中取出某个元素
// List集合有下标
String firstElt = list.get(0);
System.out.println(firstElt);
// 遍历(下标方式)
for(int i=0;i<list.size();i++){
String elt = list.get(i);
System.out.println(elt);
}
// 遍历(迭代器方式)
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String elt = iterator.next();
System.out.println(elt);
}
// 遍历(foreach方式)
for(String elt:list){
System.out.println(elt);
}
}
}
3、Set 接口
哈希表
哈希表是一种数据结构,哈希表能够提供快速存取操作。哈希表是基于数组的,所以也存 在缺点,数组一旦创建将不能扩展。 正常的数组,如果需要查询某个值,需要对数组进行遍历,只是一种线性查找,查找的速 度比较慢。如果数组中的元素值和下标能够存在明确的对应关系,那么通过数组元素的值就可 以换算出数据元素的下标,通过下标就可以快数定位数组元素,这样的数组就是哈希表。
hashcode和equals中的具体算法运行自行查找资料深究
HashSet
HashSet(Java.util.HashSet)中的数据是无序的不可重复的。HashSet 按照哈希算法存取数据的,具有非常好性能, 它的工作原理是这样的,当向 HashSet 中插入数据的时候,他会调用对象的 hashCode 得到该 对象的哈希码,然后根据哈希码计算出该对象插入到集合中的位置。 所以向 HashSet或 HashMap 中加入数据时必须同时覆盖 equals和 hashCode 方 法,应该养成一种习惯覆盖 equals的同时最好同时覆盖 hashCode
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Objects;
/*
HashSet
1、每个集合对象的创建
2、向集合中添加元素
3、从集合中提取元素
4、遍历集合
*/
public class HashSetTest {
public static void main(String[] args) {
// 创建集合
ArrayList<String> arrayList = new ArrayList<>();
// 使用构造方法把ArrayList转换为HashSet
HashSet<String> set = new HashSet<>(arrayList);
// 添加元素
set.add("abc");
set.add("def");
set.add("king");
// set集合没有下标,不能通过下标取元素
// 遍历集合(迭代器方式)
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()){
String elt = iterator.next();
System.out.println(elt);
}
// 遍历集合(foreach方式)
for(String elt:set){
System.out.println(elt);
}
// Set集合的特点:无序不可重复
set.add("king");
set.add("king");
System.out.println(set.size());
for(String elt:set){
System.out.println(elt);
}
// 创建学生集合
HashSet<Student> students = new HashSet<>();
students.add(new Student(1,"zhangsan"));
students.add(new Student(4,"lisi"));
students.add(new Student(1,"zhangsan"));
students.add(new Student(1,"wangwu"));
for (Student student:students
) {
System.out.println(student);
}
}
}
class Student{
int no;
String name;
Student(){}
public Student(int no, String name) {
this.no = no;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return no == student.no &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(no, name);
}
}
SortedSet 的实现类 TreeSet
TreeSet(Java.util.TreeSet)可以对 Set 集合进行排序,默认自然排序(即升序),但也可以做客户化的排序 。若是自定义客户类的话,那么将必须实现Comparable接口或者使用Comparator比较器进行比较。
Comparator 和 Comparable 的区别:
Comparable 是默认的比较接口,Comparable 和需要比较的对象紧密结合到一起,Comparator 可以分离比较规则,所以它更具灵活性
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
/*
TreeSet
1、每个集合对象的创建
2、向集合中添加元素
3、从集合中提取元素
4、遍历集合
5、TreeSet集合会自动排序不可重复
6、使用比较器Comparator进行降序比较(
为什么不能使用Comparable进行改正?
因为Integer已经被用fianl修饰符修饰,不能进行继承
自然无法重写Comparable中的compareTo方法
)
*/
public class TreeSetTest {
public static void main(String[] args) {
// 创建TreeSet集合
TreeSet<Integer> treeSet = new TreeSet<>(new Comparator<Integer>() {
@Override
// 编写比较器可以更改规则
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
// 添加元素
treeSet.add(100);
treeSet.add(10);
treeSet.add(10);
treeSet.add(300);
// 遍历集合(迭代器遍历)
Iterator<Integer> iterator = treeSet.iterator();
while(iterator.hasNext()){
Integer integer = iterator.next();
System.out.println(integer);
}
System.out.println();
// 遍历(foreach遍历)
for (Integer integer:treeSet
) {
System.out.println(integer);
}
System.out.println();
// 创建TreeSet集合
TreeSet<A> as = new TreeSet<>();
as.add(new A("Lisa"));
as.add(new A("Amy"));
as.add(new A("Sunny"));
for (A a:as
) {
System.out.println(a);
}
}
}
// 第一种方式:实现Comparable接口
class A implements Comparable<A>{
String string;
public A(){}
public A(String string) {
this.string = string;
}
@Override
public String toString() {
return "A{" +
"string =" + string +
'}';
}
@Override
public int compareTo(A o) {
return this.string.compareTo(o.string);
}
}
二、Map
Map 中可以放置键值对,也就是每一个元素都包含键对象和值对象,Map 实现较常用的为 HashMap,HashMap对键对象的存取和 HashSet 一样,仍然采用的是哈希算法,所以如果使用 自定类作为 Map的键对象,必须复写equals 和 hashCode 方法。
1、Hashtable 的实现类 Properties
Properties(Java.util.Properties),该类主要用于读取Java的配置文件,不同的编程语言有自己所支持的配置文件,配置文件中很多变量是经常改变的,为了方便用户的配置,能让用户够脱离程序本身去修改相关的变量设置。就像在Java中,其配置文件常为.properties文件,是以键值对的形式进行参数配置的。
import java.util.Properties;
/*
Properties
HashTable的一个子类
String getProperty(String key)
使用此属性列表中指定的键搜索属性。
String getProperty(String key, String defaultValue)
使用此属性列表中指定的键搜索属性。
*/
public class PropertiesTest {
public static void main(String[] args) {
// 创建集合
Properties properties = new Properties();
// 存
properties.setProperty("username","wangzuxian");
properties.setProperty("password","159596");
// 取
String username = properties.getProperty("username");
String password = properties.getProperty("password");
System.out.println(username);
System.out.println(password);
}
}
2、HashMap
HashMap (java.util.HashMap) 的底层实现采用的是哈希表,所以 Map 的 key 必须覆盖 hashcode 和 equals 方法
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
HashMap
1、每个集合对象的创建
2、向集合中添加元素
3、从集合中提取元素
4、遍历集合
*/
public class HashMapTest {
public static void main(String[] args) {
// 创建集合
HashMap<Integer,String> map = new HashMap<>();
// 添加元素
map.put(12,"zhangsan");
map.put(9,"lisi");
map.put(1,"smith");
map.put(1,"wangwu"); // key重复value会覆盖
// 获取元素个数
System.out.println(map.size()); //3
// 取key是9的元素
System.out.println(map.get(9));
// 遍历Map集合很重要,几种方式都要会
// 第一种方式,获取所有的key,通过key获取value
System.out.println();
Set<Integer> keys = map.keySet();
for (Integer key:keys
) {
System.out.println(key+" "+map.get(key));
}
System.out.println();
// 第二种方式:将Map集合转换为Set集合,Set中的每一个元素是一个Entry
// 这个Entry中含有key和value
Set<Map.Entry<Integer,String>> Entrys = map.entrySet();
for (Map.Entry<Integer,String> Entry:Entrys
) {
System.out.println(Entry);
}
}
}
/*
java.util.Map接口中常用的方法:
1、Map和Collection没有继承关系
2、Map集合以key和value的方式存储数据:键值对
key和value都是引用数据类型
key和value都是存储对象的内存地址
key起到主导的地位,value是key的一个附属品
3、Map接口中常用方法:
V put(K key, V value) 向集合中添加键值对
V get(Object key) 通过传入key值返回value的值
void clear() 清空Map集合
boolean containsKey(Object key) 判断集合中是否包含某个key
boolean containsValue(Object value) 判断集合中是否包含某个value
boolean isEmpty() 判断集合是否为空
Set<K> keySet() 获取集合中所有的key
Collection<V> values() 获取Map集合中所有的value,返回一个Collection
V remove(Object key) 通过key删除键值对
int size() 获取集合中键值对的个数
Set<Map.Entry<K,V>> entrySet() 将Map集合转换成Set集合
例如
--------------------------------------------
key value
1 zhangsan
2 lisi
3 wangwu
--------------------------------------------
Set set = map.entrySet();
set集合对象
1=zhangsan
2=lisi
3=wangwu
那么Set集合中的数据类型是什么?
Map集合中通过entrySet()方法转换成的这个Set集合的元素类型是Map.Entry<K,V>
*/
import java.util.Map;
import java.util.HashMap;
import java.util.Collection;
import java.util.Set;
public class MapTest01
{
public static void main(String[] args){
// 创建Map集合对象
Map<Integer,String> map = new HashMap<>();
// 添加键值对
map.put(1,"zhangsan");
map.put(2,"lisi");
map.put(4,"wangwu");
map.put(3,"zhaoliu");
// 输出map的键值对
// 通过传入key值返回value值
String s1 = map.get(2);
System.out.println(s1); //lisi
// 通过key删除键值对
map.remove(2);
// 获取集合中键值对的个数
System.out.println(map.size()); //3
// 这边的contains方法底层都是调用equals方法进行比较的,所以自定义类需要重写equals方法
// 判断集合中是否包含某个key
System.out.println(map.containsKey(3)); //true
// 判断集合中是否包含某个value
System.out.println(map.containsValue("lisi")); //false
// 获取集合中所有的key,返回一个Set集合
Set<Integer> set1 = map.keySet();
for(Integer i : set1){
System.out.println(i);
}
// 获取集合中的所有value,并返回一个Collection集合
Collection<String> c = map.values();
for(String s : c){
System.out.println(s);
}
// 将Map集合转换为Set集合
Set<Map.Entry<Integer,String>> set2 = map.entrySet();
for(Map.Entry<Integer,String> s:set2){
System.out.println(s);
}
// 清空map集合
map.clear();
// 判断map集合是否为空
System.out.println(map.isEmpty()); //true
}
}
/*
Map集合的遍历
第一种方法:通过Key和get()方法遍历整个Map集合
第二种方法:使用Set<Map.Entry<K,V>> entrySet() 将Map集合转换成Set集合
第三种方法:引用.forEach((key,value)->{
Sytem.out.println(key + " " + value);
});
*/
import java.util.*;
public class MapTest02
{
public static void main(String[] args){
// 创建Map集合
Map<Integer,String> map = new HashMap<>();
// 存入键值对
map.put(1,"zhangsan");
map.put(2,"lisi");
map.put(3,"wangwu");
map.put(4,"zhaoliu");
// 第一种方法:通过key遍历整个map
// Set<Integer> keys = map.keySet();
// 通过while循环遍历
/* Iterator<Integer> iterator = keys.iterator();
while(iterator.hasNext()){
Integer key = iterator.next();
System.out.println(key+" "+ map.get(key));
}
*/
// 通过foreach循环遍历
/* for(Integer key:keys){
System.out.println(key+" "+map.get(key));
}
*/
// 第二种方法:使用Set<Map.Entry<K,V>> entrySet()
/* Set<Map.Entry<Integer,String>> nodes = map.entrySet();
for(Map.Entry<Integer,String> node:nodes){
System.out.println(node);
}
*/
//第三种方法:直接调用Map中的forEach方法直接输出
map.forEach((key,value)->{
System.out.println(key+" "+value);
});
}
}
3、SortedMap 的实现类 TreeMap
同TreeSet
三、Collecions工具类
Collections 位于 java.util 包中,提供了一系列实用的方法,如:对集合排序,对集合中的内容 查找等
import java.util.*;
/*
java.util.Collections;工具类
常用方法
static <T> boolean addAll(Collection<? super T> c, T... elements)
将所有指定的元素添加到指定的集合。
static <T> void copy(List<? super T> dest, List<? extends T> src)
将所有元素从一个列表复制到另一个列表中。
public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
不是Collections的方法,属于System的一种方法
static <T> boolean replaceAll(List<T> list, T oldVal, T newVal)
将列表中一个指定值的所有出现替换为另一个。
static void reverse(List<?> list)
反转指定列表中元素的顺序。
static <T extends Comparable<? super T>>
void sort(List<T> list)
根据其元素的自然排序对指定的列表进行排序。
static <T> void sort(List<T> list, Comparator<? super T> c)
根据指定的比较器引起的顺序对指定的列表进行排序。
static <T> Collection<T> synchronizedCollection(Collection<T> c)
返回由指定集合支持的同步(线程安全)集合。
static <T extends Object & Comparable<? super T>>
T max(Collection<? extends T> coll)
根据其元素的 自然顺序返回给定集合的最大元素。
static <T> T max(Collection<? extends T> coll, Comparator<? super T> comp)
根据指定的比较器引发的顺序返回给定集合的最大元素。
static <T extends Object & Comparable<? super T>>
T min(Collection<? extends T> coll)
根据其元素的 自然顺序返回给定集合的最小元素。
static <T> T min(Collection<? extends T> coll, Comparator<? super T> comp)
根据指定的比较器引发的顺序返回给定集合的最小元素。
*/
public class CollectionsTest {
public static void main(String[] args) {
// 创建集合对象
ArrayList<Integer> arrayList01 = new ArrayList<>();
// static <T> boolean addAll(Collection<? super T> c, T... elements)
// 一次性添加元素
Collections.addAll(arrayList01,1,2,3,9,8,7,6,5,4);
// static <T> void copy(List<? super T> dest, List<? extends T> src)
// 将所有元素添加到别的集合中
List arrayList02 = Arrays.asList(new Integer[arrayList01.size()]);
Collections.copy(arrayList02,arrayList01);
// System.arraycopy(arrayList01,0,arrayList02,0,arrayList01.size());
// static <T> boolean replaceAll(List<T> list, T oldVal, T newVal)
// 将列表中一个指定值的所有出现替换为另一个。
Collections.replaceAll(arrayList02,1,0);
// static void reverse(List<?> list)
// 反转指定列表中元素的顺序。
Collections.reverse(arrayList02);
System.out.println(arrayList02);//[4, 5, 6, 7, 8, 9, 3, 2, 0]
// void sort(List<T> list)
// 根据其元素的自然排序对指定的列表进行排序。
Collections.sort(arrayList02);
System.out.println(arrayList02);//[0, 2, 3, 4, 5, 6, 7, 8, 9]
// static <T> void sort(List<T> list, Comparator<? super T> c)
// 根据指定的比较器引起的顺序对指定的列表进行排序。
Collections.sort(arrayList02, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
System.out.println(arrayList02);//[9, 8, 7, 6, 5, 4, 3, 2, 0]
//static <T> Collection<T> synchronizedCollection(Collection<T> c)
//返回由指定集合支持的同步(线程安全)集合。
Collections.synchronizedCollection(arrayList02);
//static <T extends Object & Comparable<? super T>>
//T max(Collection<? extends T> coll)
//根据其元素的 自然顺序返回给定集合的最大元素。
System.out.println(Collections.max(arrayList02));//9
System.out.println(Collections.min(arrayList02, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
}));//0
}
}
四、泛型
泛型能更早的发现错误,如类型转换错误,通常在运行期才会发现,如果使用泛型,那么在编 译期将会发现,通常错误发现的越早,越容易调试,越容易减少成本。
public class GenericTest02 {
public static void main(String[] args) {
custome<String> c = new custome<>();
c.doSome("原来如此");
}
}
class custome<标识符随便写>{
public 标识符随便写 doSome(String s) {
System.out.println(s);
return null;
}
}
class 标识符随便写{
}