官网:https://github.com/alibaba/DataX
一、DataX概述
日志数据:用户每天浏览的数据信息,一般都是用log进行保存,使用Flume进行采集
业务数据:用户比较关键的信息,也就是重要的信息,例如,用户购买的商品,支付的金钱,用户注册的各种信息,这样的数据都会保存到业务数据库(MySQL)
DataX就是可以将业务数据库的数据同步到数据仓库中(Hive)
二、框架设计
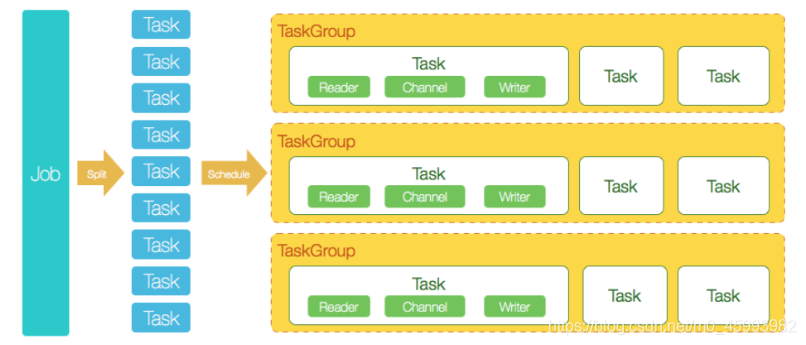
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
三、增量、全量
全量导入:没有限制性的导入,一般用于不经常变化更新的表(例如用户基本信息表)
增量导入:按照条件导入,一般用于更新变化频繁的表(例如流水表)
四、DataX调优
问题出现的位置
- 网络本身带宽和硬件因素
- DataX本身的参数
- 从数据源到任务机
- 任务机到目的端
解决
- 可使用从源端到目的端scp,python http,nethogs等观察实际网络及网卡速度;
- 结合监控观察任务运行时间段时,网络整体的繁忙情况,来判断是否应将任务避开网络高峰运行;
- 观察任务机的负载情况,尤其是网络和磁盘IO,观察其是否成为瓶颈,影响了速度;
- JVM调优
python datax.py --jvm="-Xms3G -Xmx3G" ../job/test.json -p "参数列表"
版权声明:本文为m0_45993982原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。