你是否经常使用观测数据或非实验数据?你是否在面对数据带来的自选择偏误时束手无策?今天,商小研就要给大家介绍一种可以用来缓解自选择偏误的计量方法——倾向得分匹配法!
01 倾向得分匹配法是什么
倾向得分匹配法(Propensity Score Matching)一般简称为“PSM”,是当前经济学界用来处理自选择偏误的一大热门利器,它经常和之前我们介绍过的双重差分法(DID)进行组合使用(PSM-DID),这种方法最早由Paul Rosenbaum和Donald Rubin在1983年提出。
02 倾向得分匹配法的逻辑和原理
我们举个简单常用的例子来说明PSM的原理。我们现在想要研究“接受某种职业技能培训会对个人收入有怎么样的影响”这一课题,我们收集到的是观测数据,将其简单分为处理组(接受培训)和控制组(未接受培训)。如果由此直接计算接受培训带来的处理效应(treatment effect),那显然得到的结果是不可信的。
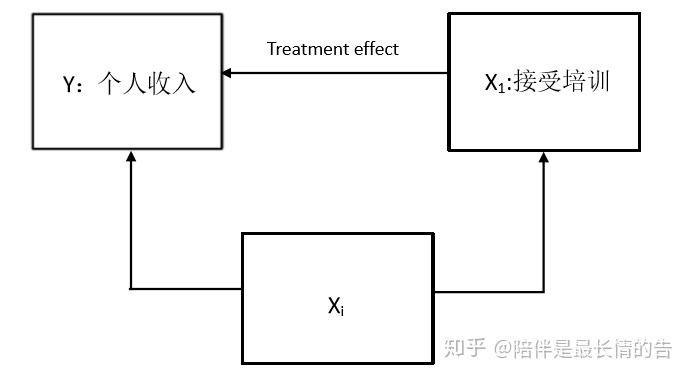
显然,存在着这样一个协变量集Xi,Xi中的变量均会对Y和X1产生影响。比如个人的能力,个人能力强的人可能就不会选择接受技能培训,但是能力强的人又能取得比较高的收入,这可能会对处理效应产生一个偏导性的影响。除了个人能力外,个人家境和学历等等因素都具有这种双面影响性。
为了解决上述的问题,我们可以利用匹配的思想,将控制组的个体按照各特性(协变量集中的变量)“距离”相近的方法与处理组中的个体进行匹配,这就使得匹配过后的个体除是否接受处理外并无显著差异,所以就在一定程度上缓解了自选择偏误。这就是PSM中的匹配法思想。
但是,在匹配之前我们需要考虑一个问题。个体的协变量集是多维度的,我们需要考虑如何将个体按照现有的多维度协变量集进行适当的匹配,这就是引入倾向得分值的缘由了。倾向得分值便是按照现有的协变量集计算个体进入处理组的概率(一般是利用probit或logit模型来进行的),这就使得多维协变量集被降到一维变量的层面,之后我们便可通过特定的匹配法则来将我们定义中的倾向得分值接近的个体进行匹配,这便重构了我们的控制组和处理组。接着,在完成了平衡性检验后,我们便可以开始计算处理效应了。
到了这里,想必大家对倾向得分匹配(PSM)的基本逻辑有了一定的认识了吧!
03 倾向得分匹配法的操作步骤
1.选择合适的协变量集
协变量集中的协变量一般来说应该对被解释变量和解释变量都有影响。
2.确定选择性的存在
确定我们的解释变量不是随机的。关于选择性存在确认的方法和理论比较多,而且不是本文的关键问题(本文重点在于处理已知存在的自选择偏误),故在此不过多展开。
3.计算倾向值
基于选定的协变量集,通过“probit”或“logit”模型来计算个体进入处理组的概率(倾向值)。
4.进行匹配
可用的匹配方法有许多,我们在这仅仅介绍几种最常见的匹配方法:
·最邻近匹配(nearest neighbor matching)
将控制组中与处理组倾向得分差异最小的个体进行匹配。虽然处理组所有个体都能匹配成功,但是不放弃任一处理组个体可能影响匹配质量,降低处理效应的精确度。
·半径匹配(radius matching)
提前设定卡尺,按照半径范围寻找控制个体进行匹配,卡尺越小匹配严格程度越高。
·核匹配(kernel matching)
将处理组样本与由控制组所有样本计算出的一个估计效果进行配对,其中估计效果由处理组个体得分值与控制组所有样本得分值加权平均获得,而权数则由核函数计算得出。
5.平衡性检验
检验匹配过后的处理组和控制组是否存在显著差异,判断匹配的效果如何。
6.计算处理效应
04 倾向得分匹配法的局限性
1.倾向得分匹配法通常需要较大的样本容量来实现高质量匹配。因此有时不适用于小样本容量的研究;
2. PSM要求立足于控制组的倾向得分有较大的共同取值范围;否则会丢失较多的观测值,导致剩下的样本不具有代表性。
参考文献:
1. 陈强. 高级计量经济学及Stata应用[M]. 北京: 高等教育出版社, 2014.