Hash类型有以下两种实现方式:
1、ziplist 编码的哈希对象使用压缩列表作为底层实现
2、hashtable 编码的哈希对象使用字典作为底层实现
1:ziplist 编码作为底层实现
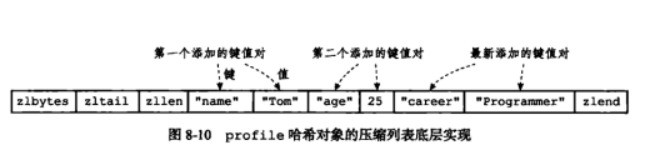
ziplist 编码的哈希对象使用压缩列表作为底层实现, 每当有新的键值对要加入到哈希对象时,程序会先将保存了键的压缩列表节点推入到压缩列表表尾, 然后再将保存了值的压缩列表节点推入到压缩列表表尾。
因此保存了同一键值对的两个节点总是紧挨在一起, 保存键的节点在前, 保存值的节点在后;先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。
例如, 我们执行以下 HSET 命令,
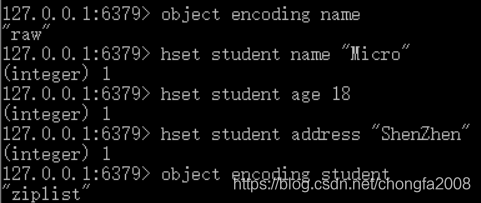
student 键的值对象使用的是 ziplist 编码
2:hashtable 编码作为底层实现
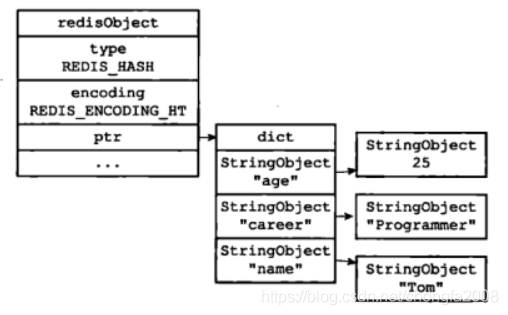
hashtable 编码的哈希对象使用字典作为底层实现, 哈希对象中的每个键值对都使用一个字典键值对来保存:
字典的每个键都是一个字符串对象, 对象中保存了键值对的键;
字典的每个值都是一个字符串对象, 对象中保存了键值对的值。

如果student 键创建的不是 ziplist 编码的哈希对象, 而是 hashtable 编码的哈希对象。
3:编码转换
当哈希对象可以同时满足以下两个条件时, 哈希对象使用 ziplist 编码:
哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节;
哈希对象保存的键值对数量小于 512 个;
不能满足这两个条件的哈希对象需要使用 hashtable 编码。
对于使用 ziplist 编码的列表对象来说, 当使用 ziplist 编码所需的两个条件的任意一个不能被满足时, 对象的编码转换操作就会被执行: 原本保存在压缩列表里的所有键值对都会被转移并保存到字典里面, 对象的编码也会从 ziplist 变为 hashtable 。
1.键的长度太大引起编码转换
2.值的长度太大引起编码转换
3.键值对数量过多引起编码转换
4:小结
1.Hash类型两种编码方式,ziplist 与 hashtable。
2.hashtable 编码的哈希对象使用字典作为底层实现。
3.ziplist 与 hashtable 编码方式之间存在转换。
4.压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。
5.既想节省Redis内存空间,又想存储对象数据,又想访问速度快,hash似乎是不二的选择。