 本教程只供个人学习,禁止用于商业,谢谢支持
本教程只供个人学习,禁止用于商业,谢谢支持 礼拜六闲暇时刻在某站逛了一下,经常观看科技、游戏的我,发现了新大陆——
小姐姐 好,开干~~
1.分析地址
1.随便找个视频
(小姐姐对不起了,我要拿你做实验了~~其实这个小姐姐长的确实不错的)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E43hgiyq-1587555662980)(/home/mck/Desktop/截图录屏_选择区域_20200422181607.png)]](https://code84.com/wp-content/uploads/2020/04/20200422194129541.png)
因为这种网站规模很大,所以一般这些视频地址不会轻易的放在网页源代码里,所以直接pass掉分析源代码的过程。
2.后来我发现了!
我想到分享的原因是因为(之前b站也是这么一个套路,不过我最近去试了一下,好像不行了) 我们在分享里找到
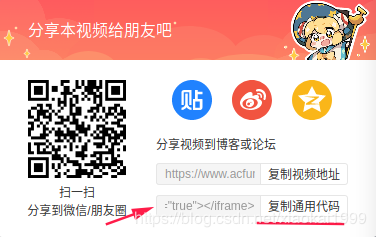
点击复制通用代码。(这是一段HTML代码,了解过HTML的同学知道iframe标签是干嘛的),分享的网站就在其中。 找到src后的网址,第一时间看到这个网址的时候我迟疑了,觉得好像和刚刚打开的网址一模一样,但是仔细一看其实不一样。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H1sPUOK7-1587555662997)(/home/mck/Desktop/截图录屏_选择区域_20200422183123.png)]](https://code84.com/wp-content/uploads/2020/04/20200422194154186.png)
https://www.acfun.cn/player/ac11692688
3.分析分享页面
这时候就得注意着网页源代码了。右键打开网页源代码。当看到源代码的时候,有些同学的内心肯定是崩溃的:啊~~怎么这么乱七八糟的。 哈哈,其实做爬虫最主要的还是
5分仔细+5分技术吧,当我在逛这个网页源代码的时候看到了
m3u8。
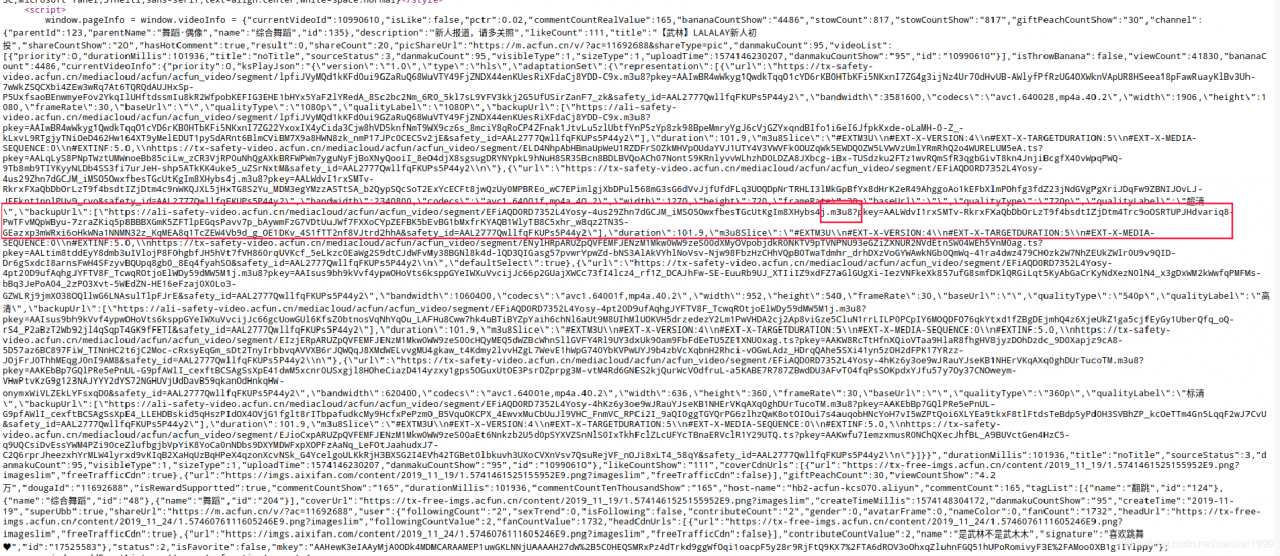
3.1 m3u8介绍
原理:将视频或音频流分片,并建立m3u8格式的索引,m3u8可以嵌套(最多支持一层嵌套)。可用于直播或者点播。 格式:m3u8是由独立行组成的文本文件,行分成三类:
- 以#EXT开头的表示是tag
- 仅有#表示是注释
- uri行表示嵌套的m3u8文件,或者真正的分片流。
一级索引和二级索引中,给出的地址可能是相对地址/绝对地址。相对地址根据一级索引的地址更改。 通常一级索引会给出不同带宽的下载链接,可以根据网速适配不同的下载链接,从而避免卡顿。 流格式可能是.ts .aac或者RFC支持的其他格式。 m3u8参数
- EXTINF:播放时间长度,单位s
- BANDWIDTH:带宽
- EXT-X-ENDLIST:有这个参数,说明是点播,是完整的一段音频或者视频;没有这个参数,说明是直播,需要不断从二级索引中去获取下一片段的链接
- EXT-X-MEDIA-SEQUENCE(可选): 播放列表的第一个音频的序号,如64.m3u8中,有3个音频,序号分别是12591742,12591743,12591744。如果不设置,默认为第一个音频链接序号为0。可以没有这个参数
- EXT-X-KEY:可能是加密的,具体见RFC
- EXT-X-TARGETDURATION:每片最大时长,单位s, #EXTINF应该小于这个值
例子
bipbopall.m3u8
#EXTM3U
#EXT-X-STREAM-INF:PROGRAM-ID=1, BANDWIDTH=200000
gear1/prog_index.m3u8
#EXT-X-STREAM-INF:PROGRAM-ID=1, BANDWIDTH=311111
gear2/prog_index.m3u8
#EXT-X-STREAM-INF:PROGRAM-ID=1, BANDWIDTH=484444
gear3/prog_index.m3u8
#EXT-X-STREAM-INF:PROGRAM-ID=1, BANDWIDTH=737777
gear4/prog_index.m3u8
prog_index.m3u8
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXT-X-MEDIA-SEQUENCE:0
#EXTINF:10, no desc
fileSequence0.ts
#EXTINF:10, no desc
fileSequence1.ts
#EXTINF:10, no desc
...
...
...
fileSequence178.ts
#EXTINF:10, no desc
fileSequence179.ts
#EXTINF:1, no desc
fileSequence180.ts
#EXT-X-ENDLIST
2.分析m3u8文件
就拿我们要获取的m3u8来做例子吧。我们吧那一长段复制下来,打开这个网页,会让我们下载.m3u8后缀的文件。点击下载。
https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/segment/xxx.m3u8?pkey=xxx&safety_id=xxx
我们
以文本打开#EXTM3U
#EXT-X-VERSION:4
#EXT-X-TARGETDURATION:5 #每片最大时长,单位s, #EXTINF应该小于这个值
#EXT-X-MEDIA-SEQUENCE:0 #播放列表的第一个音频的序号,如64.m3u8中,有3个音频,序号分别是12591742,12591743,12591744。如果不设置,默认为第一个音频链接序号为0。可以没有这个参数
#EXTINF:5.000000, #播放时间长度,单位s
xxx.ts?pkey=xxx&safety_id=xxx
其实.ts文件就是我们要下载的文件。(但是这个.ts和我们普通见到的不太一样,其实这里的ts需要加上pkey,safety_id两个参数才能下载到视频,相当于他们的加密方式吧) 这样看起来很累,我们可以把这段分成3行来看(
其实这里还缺访问的域名)
xxx.ts?
pkey=(xxx)
safety_id=(xxx)
1.找到.ts域名
按下ctrl+F12查看network里是否有可靠的信息。

https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/segment/
我们就添加到上面获取到的ts字符串前。(这个就是他其中的分段视频了)
3.ffmpeg 视频下载器介绍
1、libavformat:用于各种音视频封装格式的生成和解析,包括获取解码所需信息以生成解码上下文结构和读取音视频帧等功能,包含demuxers和muxer库; 2、libavcodec:用于各种类型声音/图像编解码; 3、libavutil:包含一些公共的工具函数; 4、libswscale:用于视频场景比例缩放、色彩映射转换; 5、libpostproc:用于后期效果处理; 6、ffmpeg:是一个命令行工具,用来对视频文件转换格式,也支持对电视卡实时编码; 7、ffsever:是一个HTTP多媒体实时广播流服务器,支持时光平移; 8、ffplay:是一个简单的播放器,使用ffmpeg 库解析和解码,通过SDL显示;
在这组成部分中,需要熟悉基础概念有 容器(Container) 容器就是一种文件格式,比如flv,mkv等。包含下面5种流以及文件头信息。 流(Stream) 是一种视频数据信息的传输方式,5种流:音频,视频,字幕,附件,数据。 帧(Frame) 帧代表一幅静止的图像,分为I帧,P帧,B帧。 编解码器(Codec) 是对视频进行压缩或者解压缩,CODEC =COde (编码) +DECode(解码) 复用/解复用(mux/demux) 把不同的流按照某种容器的规则放入容器,这种行为叫做复用(mux) 把不同的流从某种容器中解析出来,这种行为叫做解复用(demux) 具体可以去看https://www.jianshu.com/p/3c8c4a892f3c(这个大佬写的很详细)
4.上代码
1.网页源代码获取
def requests_get(ac_url):
r = requests.get(ac_url,headers=headers).text
print(r)
if "出错啦!" in r:
print("并没有找到你想要的信息!")
return 0
a = get_informations(r)
return a
2.分别获取m3u8下载地址
def get_informations(r):
informations=[]
filename=''
p1='';p2='';p3='';p4=''
urls = re.findall("[a-zA-z]+://[^\s]*",r)
for url in urls:
if "tx" in url:
informations = url.split("{")
for information in informations:
if '1080P' in information:
p1 = re.findall("[a-zA-z]+://[^\s]*",information)
p1 = "1080p地址:"+p1[0][0:p1[0].index("\\")]
elif '超清' in information:
p2 = re.findall("[a-zA-z]+://[^\s]*",information)
p2 = "超清地址:"+p2[0][0:p2[0].index("\\")]
elif "高清" in information:
p3 = re.findall("[a-zA-z]+://[^\s]*",information)
p3 = "高清地址:"+p3[0][0:p3[0].index("\\")]
elif "标清" in information:
p4 = re.findall("[a-zA-z]+://[^\s]*",information)
p4 = "标清地址:"+p4[0][0:p4[0].index("\\")]
return p1,p2,p3,p4
3.下载m3u8文件
def download_m3u8(ipt2):
print("正在下载m3u8")
download = ""
if ipt2 == '1':
download = a[0][5:]
elif ipt2=='2':
download = a[1][5:]
elif ipt2=='3':
download = a[2][5:]
elif ipt2=='4':
download = a[3][5:]
else:
print("输入错误!")
return 0
r = requests.get(download,headers=headers,stream=True).text
with open(path+"/2.txt","w+") as f:
f.write(r)
f.close()
print("完成")
return 1
4.下载ts文件
def download_ts():
with open(path+"/2.txt","r+") as f:
t = f.readlines()
f.close()
print("开始下载---")
if not os.path.exists(path+"/vedio"):
os.mkdir(path+"/vedio")
l=0
for i in t:
if i[0]!="#" and len(i)>8:
s1 = i.split("?")
s2 = s1[1].split("&")
s3 = s2[0].split("=")
s4 = s2[1].split("=")
params={
"pkey":s3[1],
"safety_id":s4[1][:-1]
}
download_url = "https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/segment/"+s1[0]
r = requests.get(download_url,headers=headers,params=params,stream=True)
with open(path+"/vedio/"+str(l)+".ts","wb") as f:
for chunk in r.iter_content(chunk_size=1024 * 1024):
if chunk:
f.write(chunk)
f.close()
print("正在下载{0}.ts".format(l))
l+=1
time.sleep(1)
print("下载完成---")
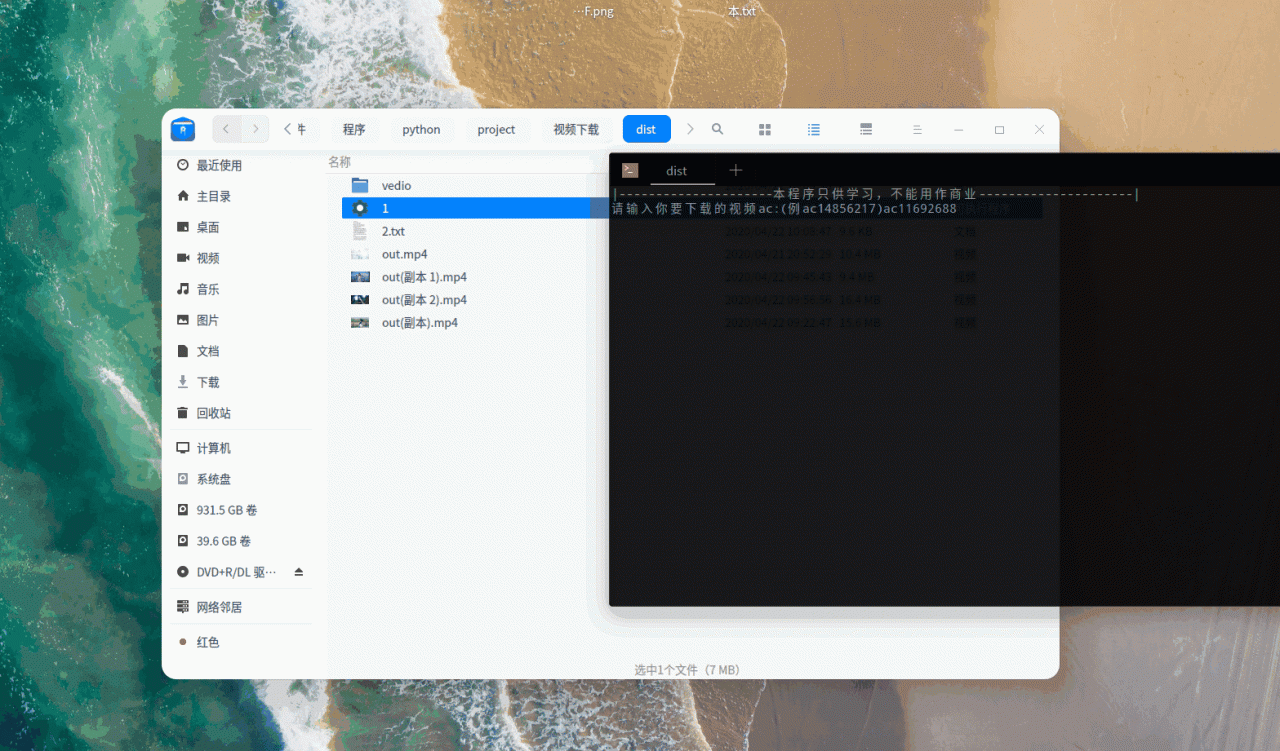
5.合并ts文件
def involve_ts():
print("合并视频")
ls = os.listdir(path+"/vedio/")
print(len(ls))
contect=""
for i in range(len(ls)):
contect += path+"/vedio/"+str(i)+".ts"
if i != len(ls)-1:
contect+="|"
print(contect)
cmd = "ffmpeg -i concat:\""+contect+"\" -acodec copy -vcodec copy -vbsf h264_mp4toannexb "+path+"/vedio/out.mp4"
os.system(cmd)
print("完成")
效果:
如要转载请说明出处:https://blog.csdn.net/xiaokai1999/article/details/105690965