系列文章
R做面板数据分析:R语言 面板数据分析 plm包实现(一) ——LSDV和固定效应模型
如果想看随机效应模型怎么做,参见这篇文章
R语言 面板数据分析 plm包实现(二)——随机效应模型如果想看如何判断面板数据适用随机效应模型还是固定效应模型,参见这篇文章:
R语言 面板数据分析 plm包实现(三)——面板数据与面板模型的检验使用随机效应模型,且一些时间或个体存在数据缺失,应当使用Swamy Arora估计,如何用R语言来实现,参见这篇文章:
R语言 面板数据如何做Swamy Arora估计。
目录
我们知道,针对面板数据主要有四种模型,分别是:
- pool模型->对变量去整体均值后进行 OLS 估计
- 固定效应模型->对变量去个体均值后进行 OLS 估计
- 随机效应模型->对变量处理(减去个体均值的某个倍数)后进行 OLS 估计
- 可变系数模型(随机系数模型)->采用 GLS 估计
在《R语言 面板数据分析 plm包实现(固定效应模型和组内模型)》中对模型如何使用进行分析做演示,本文主要展示如何检验该使用何种模型。
下面依次介绍三种检验,在介绍前,特别强调:
- WLS(加权最小二乘回归)和FGLS都属于GLS回归。区别是前者方差矩阵可知,后者方差矩阵不知需估计。
- 判断选择固定效应模型和随机效应模型不能单凭传统的hausman检验(Hausman, 1978)。因为传统的hausman检验假设方差是同方差的,没有考虑异方差问题,须使用异方差稳健的豪斯曼检验。
有数据集:Ex1_1.dta
数据样式
点击下载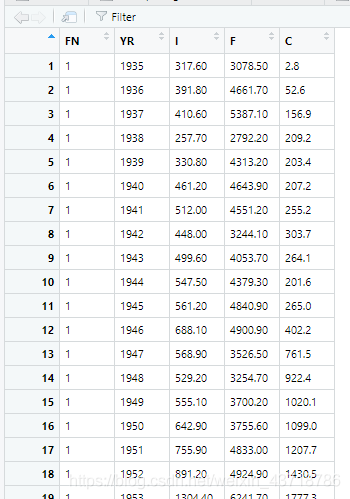
其中FN代表公司,总共有三家;YR代表年份;I是总投资;F是企业实际价值;C是企业实际资本存量。
更多解释:
数据导入
这个数据集是stata的数据集,因此在Rstudio中你可以选择文件–>导入数据集(import dataset)–>导入stata文件,即可完成导入工作
此外,我好像在其它地方也看见过此数据集,如果你无法下载,可以在其它地方寻找数据集(我印象里是在某个面板相关的R程序包里自带的数据集)。
很多童鞋反映数据集获取困难,我把这个数据集上传到github的一个项目里了(免费),注意,只有一个文件是数据集。如果有帮到你,请给文章点个赞哦~
数据检验
绘制相关系数矩阵和相关性t检验矩阵
rankData<-pdata.frame(Ex1_1 ,index=c("FN","YR"))
mydata = Ex1_1[ , c(3,4,5)]
# 相关系数矩阵
library(Hmisc) # 加载包
res <- cor(mydata)
# 输出相关系数矩阵,保留两位小数
round(res, 2)
# 相关性的显著性检验
res2 <- rcorr(as.matrix(mydata))
res2
# 结果都在p<0.01水平上显著(第二幅图的第二个矩阵)


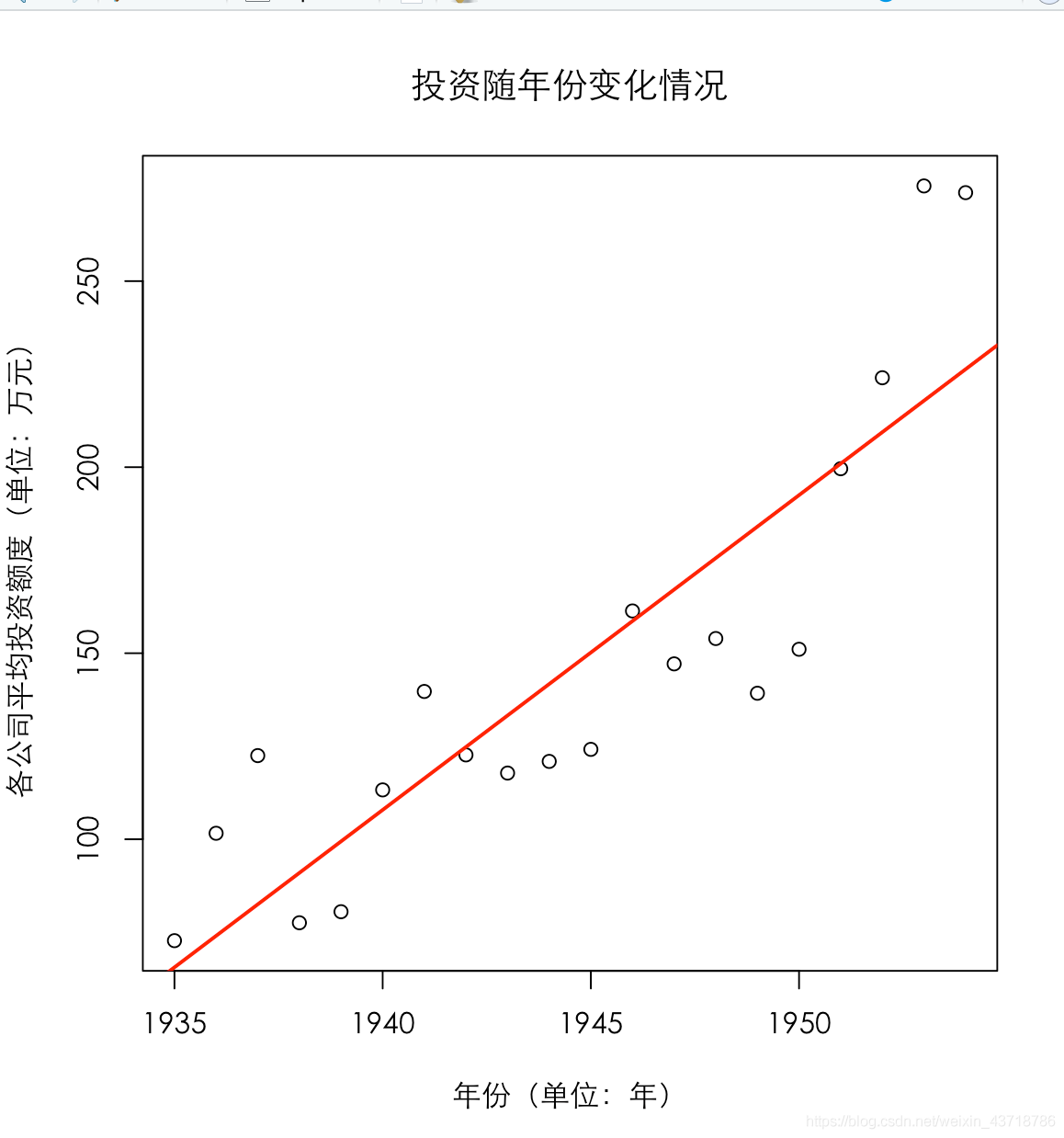
绘制企业投资平均水平随时间的变化
frame = aggregate(I~YR,data=Ex1_1,mean) # YR(年份)作横轴,I作纵轴
# 绘制散点图
plot(frame,main = "投资随年份变化情况",xlab = "年份(单位:年)",ylab = "各公司平均投资额度(单位:万元)", family='STXihei')
# 绘制拟合曲线(回归方法)
abline(lm(I~YR,data=Ex1_1),col = "red", lwd = 2 , lty = 1)
得到图像如下:
序列相关性检验
考察企业的投资额的序列相关性,通常是重要一步
# 导入plm包
library("plm")
# 模型的基本形式
form = I ~ F + C
# 序列相关性检验,默认参数effect = "individual",此处未写出
pwartest(form, data = rankData)

在个体固定效应模型情况下,拒绝原假设,认为存在序列相关性。可以根据此对模型进行修改,比如在自变量中添加滞后一期的因变量I作为解释变量。
下面进行模型检验。
模型检验
pool模型还是固定效应模型——F检验
pooltest()函数和pFtest()函数都可以做F检验,其原假设是能否认为所有时间或个体都具有相同的系数,这样的话应当采用pool模型,即传统的OLS回归。
pool模型具体可参见《R语言 面板数据分析 plm包实现(固定效应模型和组内模型)》。
# 如果拒绝零假设,采用individual维度的固定效应模型
pooltest(form, data = rankData, model = "within")
# 如果拒绝零假设,采用time维度的固定效应模型
pooltest(form, data = rankData,effect = "time", model = "within")
# 如果拒绝零假设,采用双维度的固定效应模型
pFtest(form, data = rankData,effect = "twoways", model = "within")
固定效应模型还是随机效应模型——Hausman检验
固定效应模型和随机效应模型的名字具有迷惑性,实际上二者都采用了随机估计量,我们可以用Hausman检验来判断哪一个适用(Hausman and Taylor 1981)。
拒绝零假设,采用固定效应模型;不拒绝,采用随机效应模型。
上文提到数据可能存在自相关和异方差问题,因此我们也可以采用稳健的(robust) Hausman检验,下面的代码展示了两种,即稳健的和非稳健的。
# 固定效应模型,注意参数是model = "within"
mf = plm(form, data = rankData,effect = "twoways", model = "within")
# 随机效应模型
mr = plm(form, data = rankData,effect = "twoways", model = "random")
# 传统 Hausman检验
phtest(mf,mr)
# 稳健的Hausman检验
phtest(form, data = rankData, method = "aux", vcov = vcovHC)
检验结果: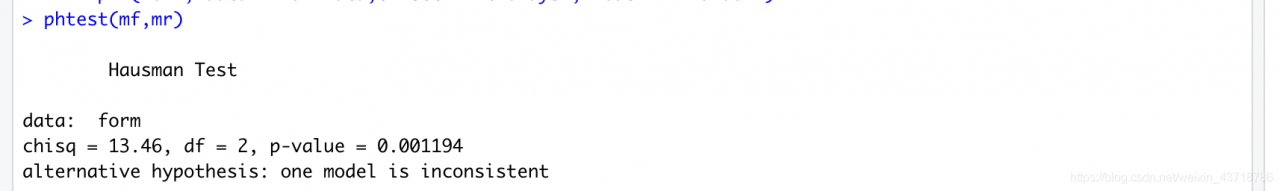

从两个结果看,都拒绝原假设,应当采用固定效应模型。
另外,如果没有序列相关性,则随机效应的最佳检验是Breusch和Godfrey的基于似然性的LM检验(Honda进行了改进)
LM检验
拒绝零假设,采用随机效应模型;不拒绝,可能是固定效应模型或 Pooled 模型。
# LM检验
pcdtest(form,data=rankData,model="within")

从结果来看,Hausman和LM检验都指出应当使用固定效应模型。
尾声
通常,检验部分结束,确定模型后,应当进入模型分析部分
如果检验结果是随机效应模型,且一些时间或个体存在数据缺失,应当使用Swamy Arora估计,如何用R语言来实现,参见这篇文章:
R语言 面板数据如何做Swamy Arora估计。
探究至此,文章中可能有错误,欢迎评论指出。