设多项式
将参数和训练数据都作为向量来处理,可以使计算变得更简单。
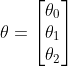
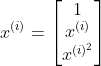
由于训练数据有很多,所以我们把1 行数据当作1 个训练数据,以矩阵的形式来处理会更好。
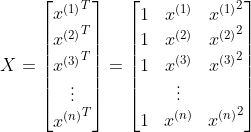
矩阵与参数向量θ 的积如下
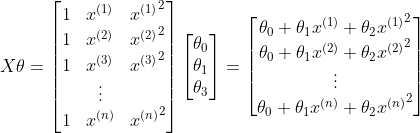
在Jupyter Notebook中表示
#初始化
theta = np.random.rand(3)#通过np.random.randn(d0,d1,d2……dn)函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
#创建训练数据的矩阵
def to_matrix(x):
return np.vstack([np.ones(x.shape[0]), x, x**2]).T#ones()返回一个全1的n维数组,同样也有三个参数:shape(用来指定返回数组的大小)、dtype(数组元素的类型),np.vstack():在竖直方向上堆叠
X = to_matrix(train_z)
#预测函数
def f(x):
return np.dot(x, theta)参数更新表达式,在我前面的博客里面,多重回归时有讲到推理过程
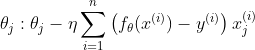
这里很容易让人想到用循环来实现,但其实如果好好利用训练数据的矩阵X,就能一下子全部计算出来。比如在j = 0 的时候,把更新表达式的Σ部分展开,就会变成这样子。
把表达式中和
的部分分别当作向量来处理
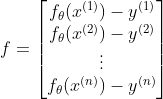
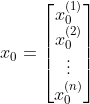
j=0时把f 转置之后与相乘,就与和的部分一样了。
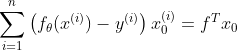
现在全部为1,
为
、
为
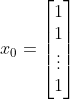 ,
, 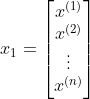 ,
, 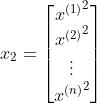
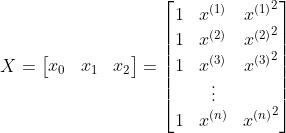
就能一次性地更新θ 了
#误差的差值
diff = 1
#重复学习
error = E(X,train_y)
while diff>1e-2:
#更新参数
theta = theta - ETA*np.dot(f(X)-train_y,X)
#计算与上一次误差的差值
current_error = E(X, train_y)
diff = error - current_error
error = current_error
x = np.linspace(-3, 3, 100)
plt.plot(train_z, train_y, 'o')
plt.plot(x, f(to_matrix(x)))
plt.show()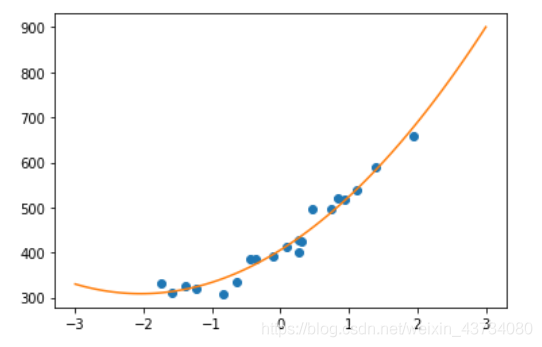
从上图可以发现,拟合了训练数据的曲线。以重复次数为横轴、均方误差为纵轴来绘图,来观察曲线不断下降的样子。
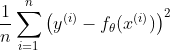
在停止重复的条件里可以用上均方误差
#均方误差
def MSE(x, y):
return (1 / x.shape[0])*np.sum((y-f(x))**2)#x.shape(0)指行数
#用随机值初始化参数
theta = np.random.rand(3)
#均方差的历史记录
errors = []
#误差的差值
diff = 1
#重复学习
errors.append(MSE(X, train_y))
while diff>1e-2:
theta = theta - ETA*np.dot(f(X) - train_y, X)
errors.append(MSE(X, train_y))
diff = errors[-2] - errors[-1]
#绘制误差变化图
x = np.arange(len(errors))
plt.plot(x, errors)
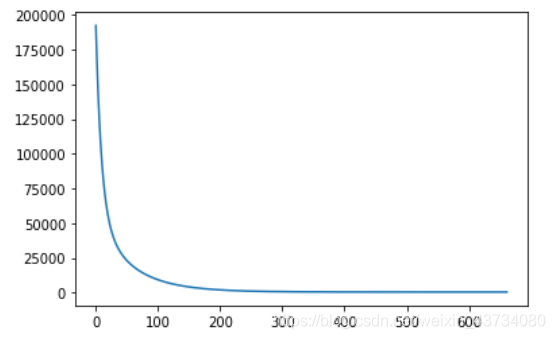
plt.show()结果如下图 ,我们不难发现误差在不断下降
版权声明:本文为weixin_43734080原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。