文章目录
一、分析写代码的思路
1.作者url+headers 2.看作者所在的url是否是静态网页 3.解析网页,获取作者的每个作品的url,及作者名字 4.根据每个作品url继续访问,然后数据分析 5.提取html文本字符串,标题 6.创建文件夹 7.保存html文本 8.转换pdf文本
二、代码步骤
1.导入需要的库
代码如下(示例):
import requests,parsel,os,pdfkit
from lxml import etree2.分析某个博客的主页
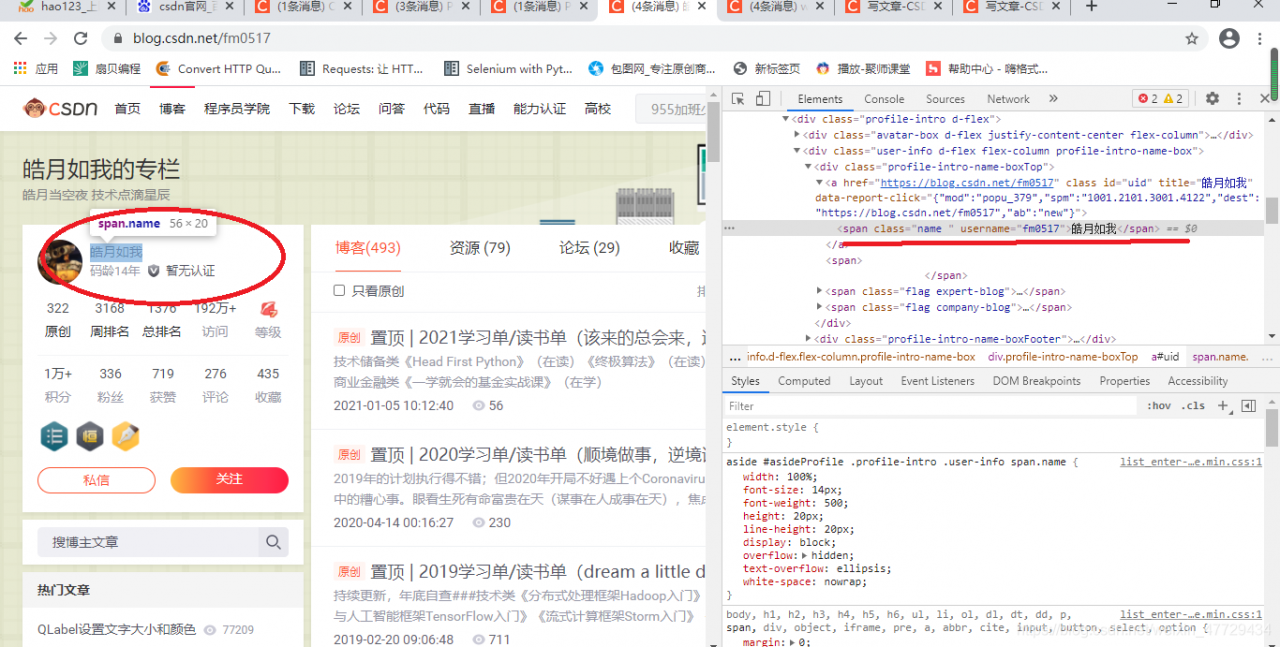
2.1.任意点进某个博主的网页,例如:“w要变强”的博主
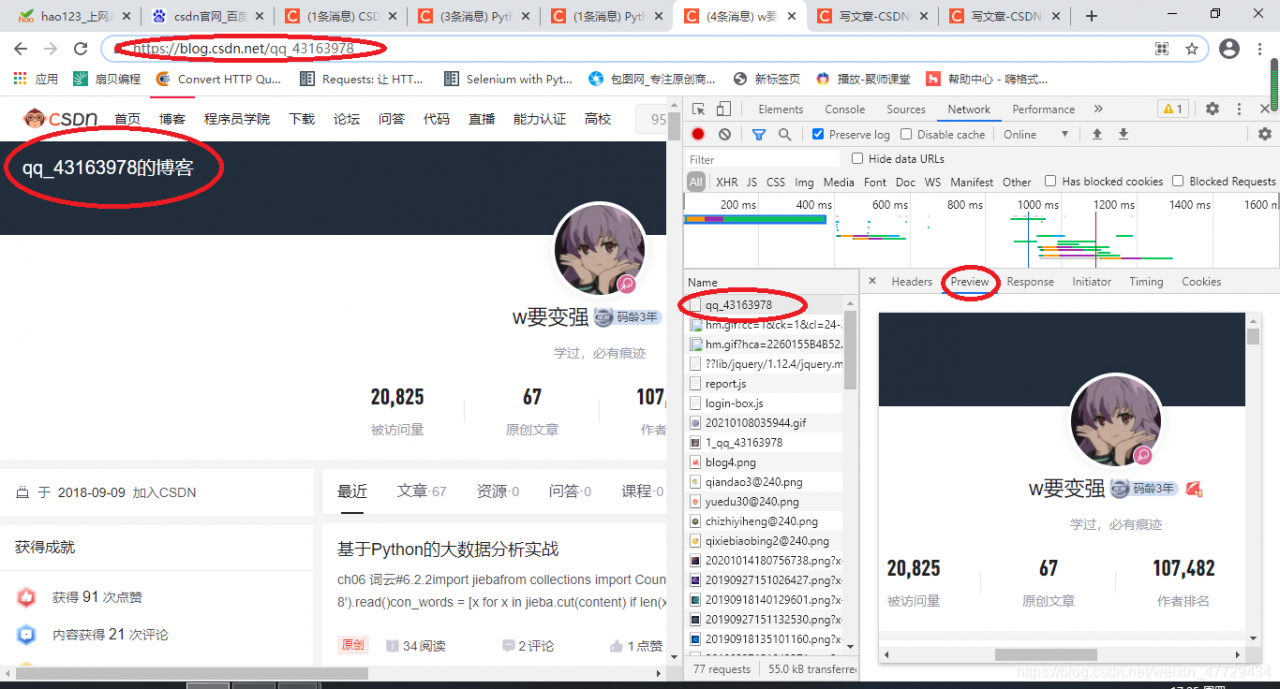
2.2 点击开发者工具,刷新加载出博主主页的网址
2.3 右键点击查看网页源代码,发现博主主页为静态网页,这里我选择了xpath解析网页,当然还可以用css选择器,beautifulsoup等其他解析器
代码如下:
#1.author_url+headers author_url=input('请输入csdn博主的url:') headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/87.0.4280.88 Safari/537.36'} response = requests.get(author_url,headers=headers).text # 2.作者所在的url是静态网页,xpath解析每个作品url html_xpath = etree.HTML(response)
3.提取需要的数据
3.1提取博客的名字和所有作品的url
代码如下:
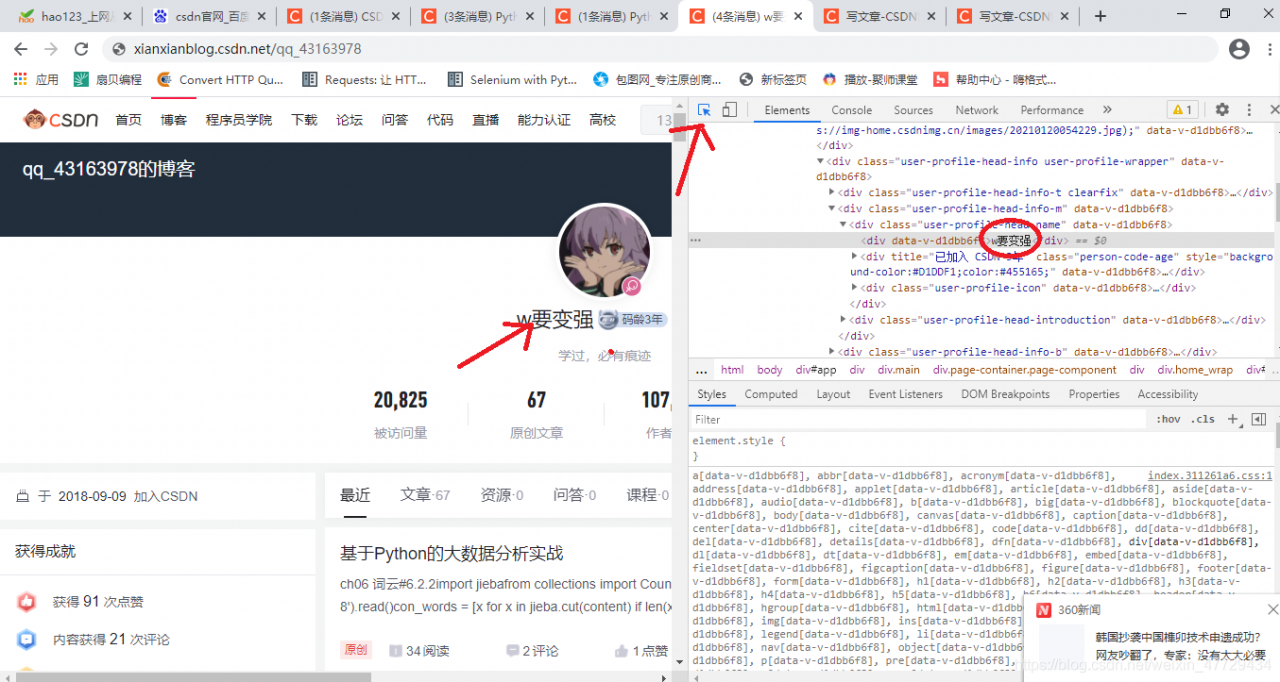
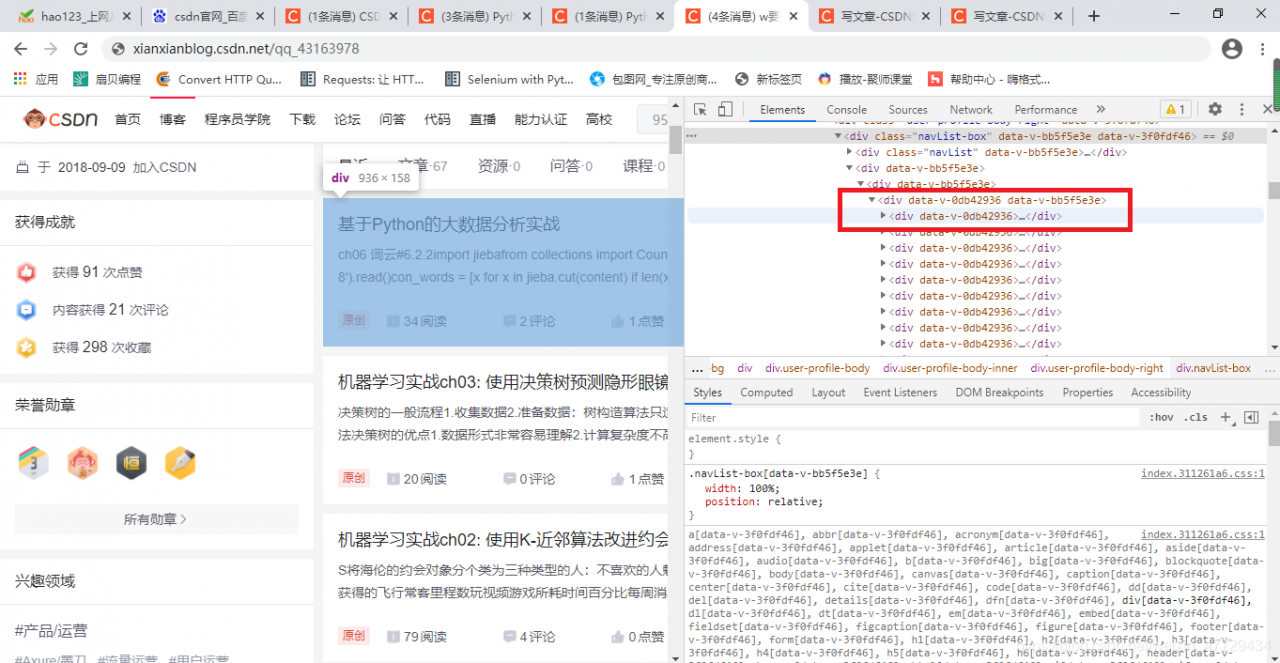
try: author_name = html_xpath.xpath(r'//*[@class="user-profile-head-name"]/div/text()')[0] # print(author_name) author_book_urls = html_xpath.xpath(r'//*[@class="blog-list-box"]/a/@href') # pprint(author_book_urls) except Exception as e: author_name = html_xpath.xpath(r'//*[@id="uid"]/span/text()')[0] author_book_urls = html_xpath.xpath(r'//*[@class="article-list"]/div/h4/a/@href')元素的xpath路径可以直接copy的,对于这里用的异常处理我稍微解释下:其实还有少部分博主的主页是不同的,例如:
分析方法都一样,只是元素xpath路径不同而已,因此无论是哪种形式通过异常处理都能提取出作品urls及名字。
4.遍历博主的每个文章的网址
4.1 每个作品网页也为静态网页,发送请求,获取响应并解析
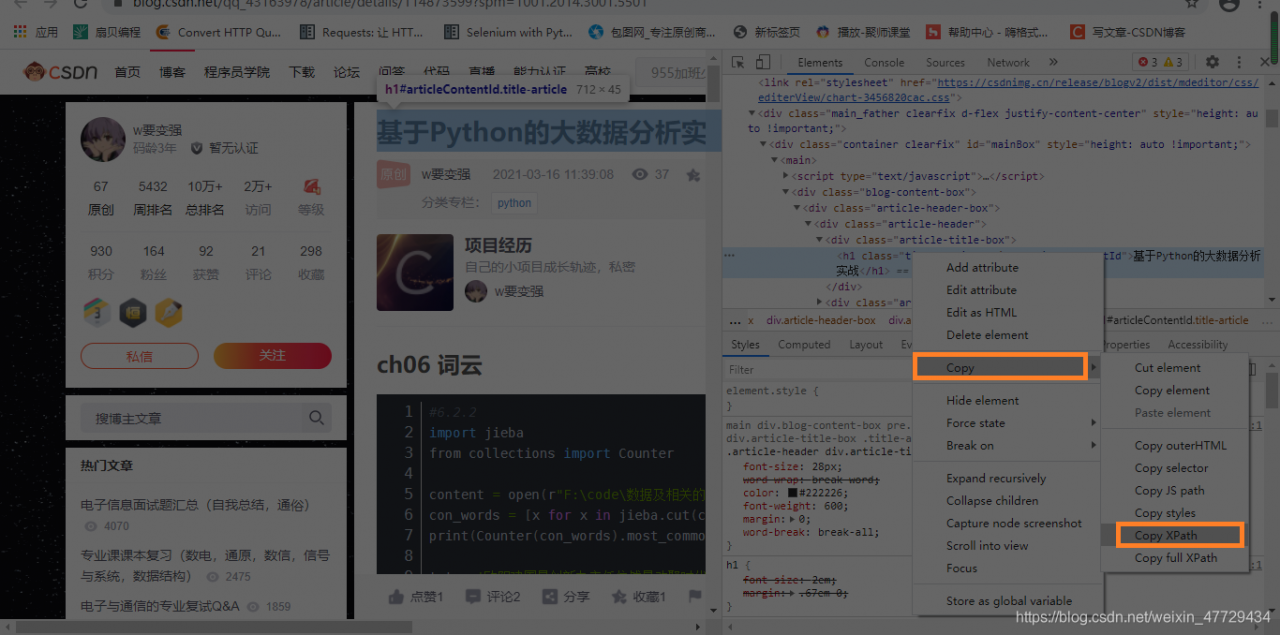
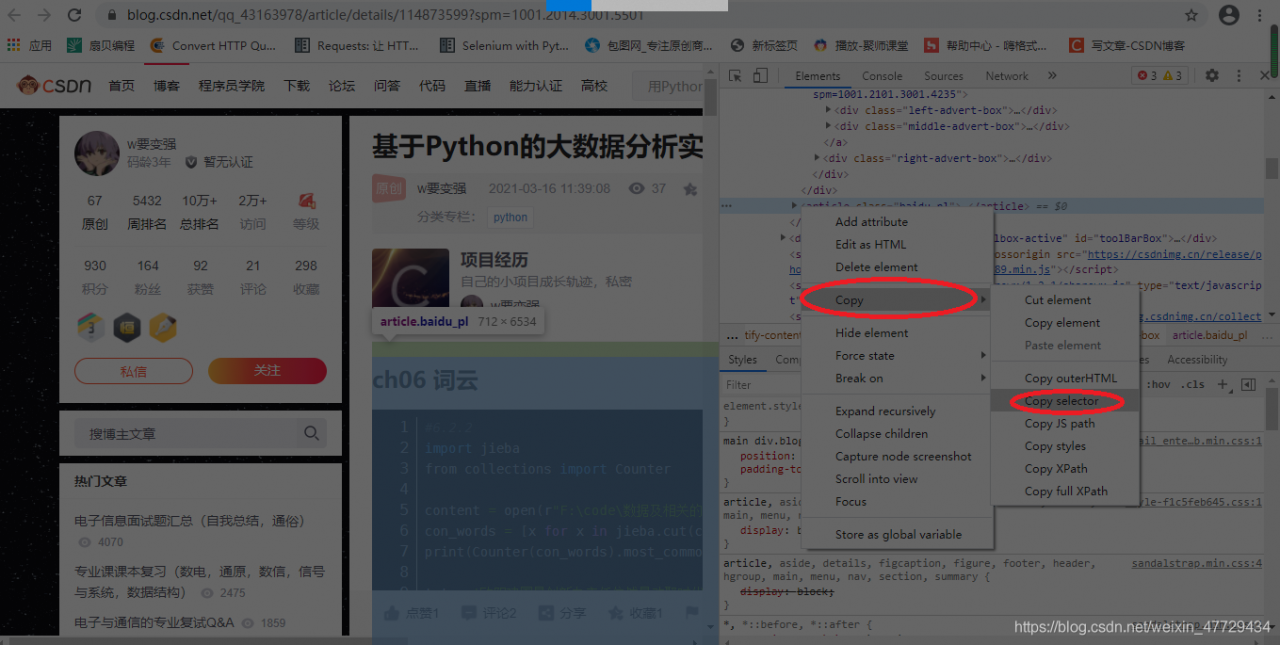
代码如下:for author_book_url in author_book_urls: book_res = requests.get(author_book_url,headers = headers).text #4.将响应分别用xpath,css选择器解析 html_book_xpath = etree.HTML(book_res) html_book_css = parsel.Selector(book_res)4.2 css选择器提取文章的html文本,xpath提取文章标题
代码如下:
book_title = html_book_xpath.xpath(r'//*[@id="articleContentId"]/text()')[0] html_book_content = html_book_css.css('#mainBox > main > div.blog-content-box').get()
5.构造html网页
#5.拼接构造网页框架,加入文章html内容
html =\
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>
'''.format(html_book_content)
6.创建文件夹
#6.创建博主文件夹
if not os.path.exists(r'./{}'.format(author_name)):
os.mkdir(r'./{}'.format(author_name))7.保存html文件
#6.保存html文本
try:
with open(r'./{}/{}.html'.format(author_name,book_title),'w',encoding='utf-8') as f:
f.write(html)
print('***{}.html文件下载成功****'.format(book_title))
except Exception as e:
continue8.将html文件转换成pdf文件
转换文件物理条件:需要下载wkhtmltopdf.exe驱动文件喔!
#8.转换pdf文本,导入pdfkit包 try: config = pdfkit.configuration( wkhtmltopdf=r'D:\programs\wkhtmltopdf\bin\wkhtmltopdf.exe' ) pdfkit.from_file( r'./{}/{}.html'.format(author_name,book_title), './{}/{}.pdf'.format(author_name,book_title), configuration=config ) print(r'******{}.pdf文件保存成功******'.format(book_title)) except Exception as e: continue
三. 总代码及结果
# !/usr/bin/env python
# -*- coding: utf-8 -*-
'''
实现目标:爬某一博主的所有博客
1.作者url+headers
2.看作者所在的url是否是静态网页
3.解析网页,获取作者的每个作品的url,及作者名字
4.根据每个作品url继续访问,然后数据分析
5.提取html文本,标题
6.创建多级文件夹
7.保存html文本
8.转换pdf文本
'''
import requests,parsel,os,pdfkit
from lxml import etree
from pprint import pprint
def main():
#1.author_url+headers
author_url=input('请输入csdn博主的url:')
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36'}
response = requests.get(author_url,headers=headers).text
# 2.作者所在的url是静态网页,xpath解析每个文章url
html_xpath = etree.HTML(response)
try:
author_name = html_xpath.xpath(r'//*[@class="user-profile-head-name"]/div/text()')[0]
# print(author_name)
author_book_urls = html_xpath.xpath(r'//*[@class="blog-list-box"]/a/@href')
# print(author_book_urls)
except Exception as e:
author_name = html_xpath.xpath(r'//*[@id="uid"]/span/text()')[0]
author_book_urls = html_xpath.xpath(r'//*[@class="article-list"]/div/h4/a/@href')
# print(author_name,author_book_urls,sep='\n')
#3.遍历循环每个作品网址,请求网页
for author_book_url in author_book_urls:
book_res = requests.get(author_book_url,headers = headers).text
#4.将响应分别用xpath,css选择器解析
html_book_xpath = etree.HTML(book_res)
html_book_css = parsel.Selector(book_res)
book_title = html_book_xpath.xpath(r'//*[@id="articleContentId"]/text()')[0]
html_book_content = html_book_css.css('#mainBox > main > div.blog-content-box').get()
#5.拼接构造网页框架,加入文章html内容
html =\
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>
'''.format(html_book_content)
#6.创建博主文件夹
if not os.path.exists(r'./{}'.format(author_name)):
os.mkdir(r'./{}'.format(author_name))
#7.保存html文本
try:
with open(r'./{}/{}.html'.format(author_name,book_title),'w',encoding='utf-8') as f:
f.write(html)
print('***{}.html文件下载成功****'.format(book_title))
except Exception as e:
continue
#8.转换pdf文本,导转换包
try:
config = pdfkit.configuration(
wkhtmltopdf=r'D:\programs\wkhtmltopdf\bin\wkhtmltopdf.exe'
)
pdfkit.from_file(
r'./{}/{}.html'.format(author_name,book_title),
'./{}/{}.pdf'.format(author_name,book_title),
configuration=config
)
print(r'******{}.pdf文件保存成功******'.format(book_title))
except Exception as e:
continue
if __name__ == '__main__':
main()
总结
以上就是今天要讲的内容,本文介绍了如何下载csdn上博主的所有文章,并保存成pdf文件!如果本篇博客对您有一定的帮助,大家记得留言+点赞哦。
版权声明:本文为weixin_47729434原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。