最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解关于有关物体检测的相关网络,具体包括R-CNN,Fast R-CNN,Faster R-CNN和Mask R-CNN等。在此之前会先将常见的几个比较有效的CNN网络也作简单的介绍。
一、经典的CNN
1.LeNet
LeNet是最早提出的几个卷积神经网络之一,现在看起其结构比较简单,只有简单的卷积、池化和全连接层,没什么特别的Tricks(技巧)。其示意图如下:

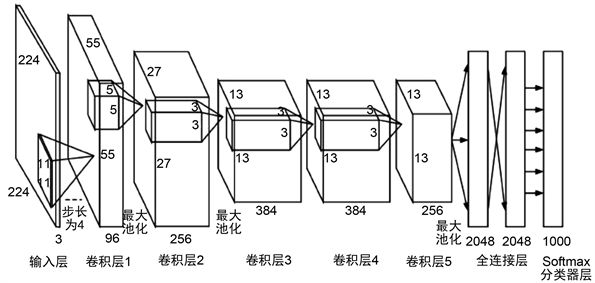
2. AlexNet
AlexNet使用了较多的Tricks,比如用ReLU作为激活函数、使用最大池化代替平均池化、Dropout、数据增强等方法。在该网络中还提出了一个名为Local Response Norm的层,但是后来证实该层的加入并没有什么明显的效果。其示意图如下:
3. GoogLeNet
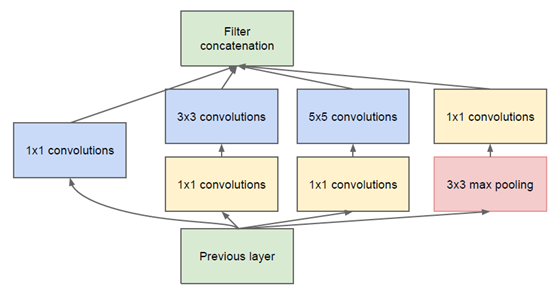
GoogLeNet设计了一个名为Inception的网络结构(如上图所示),该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。其中1x1卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)。GoogLeNet就是多个 Inception 结构串联而形成的。它的参数相对于同时期其他网络来说要少很多,这也保证了其训练速度比较快。
有趣的是GoogLeNet中的L是大写的,这是为了致敬LeNet。其示意图如下:
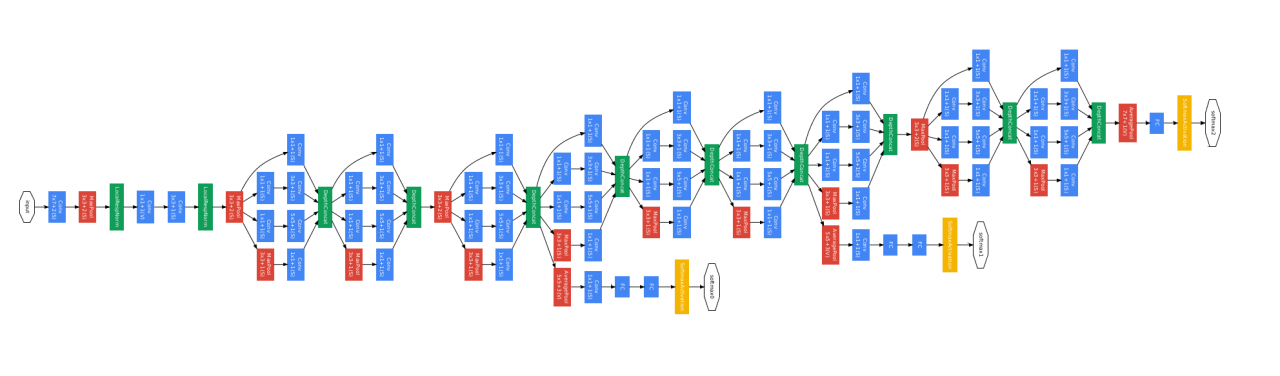
4. VGG Net
VGG Net是一种比较勤奋的网络,它试验了多种不同的卷积核大小的组合,最终挑出来了一个效果最好的版本——VGG 19。VGG 19放弃了较大的卷积核,而使用较小的卷积核,同时也增加了网络的深度,这导致网络的参数过多。不同的VGG版本所采用的结构如下:

5.ResNet
ResNet全称Residual Networks,可译作残差网络。所谓残差是指观察值与预测值之间的差。当一个神经网络的深度不断增加时,其训练误差会先减少后增大。为了克服该问题,残差网络引入了残差块的概念(如下图所示),残差网络就是由多个残差块组成的。
在下图中,x 是神经网络浅层的输出,x 会先经一个3 × 3 3\times33×3的卷积,再经 ReLU函数激活,再经一个3 × 3 3\times33×3的卷积,得到 F ( x ) F(x)F(x),然后将深层的输出 F(x) 加上浅层的输出 x,将 F ( x ) + x F(x)+xF(x)+x 作为训练的目标。当浅层网络的输出 x 训练的足够好时,只需要另 F(x) = 0 即可保留已经训练好的结果。也就是说浅层网络可以看作是深层网络的子网络,深层网络至少不会比浅层网络有更差的效果。

二、目标检测网络
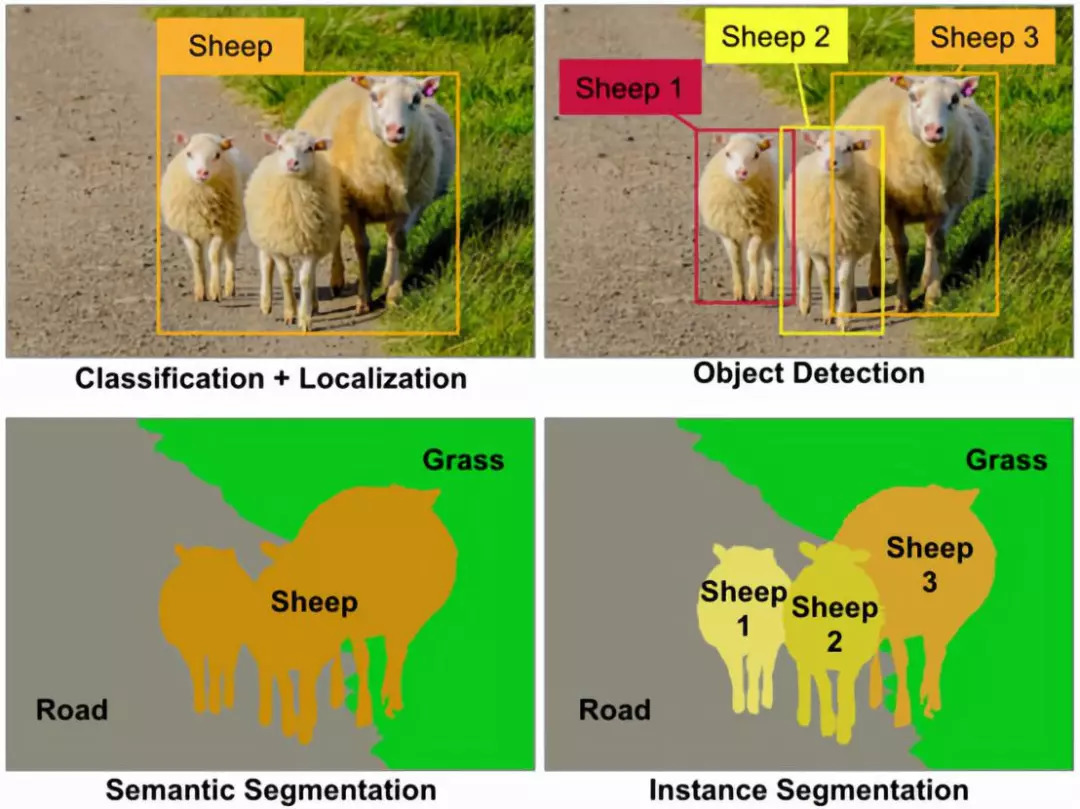
目标检测就是把图像中的物体用bounding box标注其所在的位置;语义分割是在像素级别上把前景和后景分割出来,同一类别的不同个前景为同一标注;实例分割会把同一类别的不同个前景标注为不同的标记。如上图所示,语义分割会把三只羊打上相同的标注,而实例分割会把三只羊打上不同的标注。
1. Overfeat
Overfeat把网络的1~5看作是特征提取层,不同的任务共享该特征提取层,这种做法减少了特征提取层参数的重复训练。
2. R-CNN
R-CNN(regions with CNN features)的算法流程如下:
(1) 输入图片;
(2) 使用selective search(选择性搜索)生成多个region proposal(建议区域/候选区域),并wrap到固定的尺寸;
(3) 将每个候选区域输入到 CNN 中,提取每个候选区域的特征;
(4) 使用SVM对特征进行分类,对每个特征都建立一个SVM分类器。并对每一个类别进行NMS(非极大值抑制),得到最终的 bounding box。
R-CNN算法最大的缺点就是对于每个 region proposal 都需要重新对其提取特征,而这些 region proposal 之间可能存在重叠,这就导致了大量重复的计算。
selective search
在 selective search 算法提出之前,对于候选框的搜索是用的是一种暴力搜索算法——滑动窗口算法。在该算法中,要使用一个小窗口遍历搜索整张图片,在每个位置上对滑窗内的图片做物体识别。不仅要搜索不同的位置,还要遍历不同的大小,所以非常耗时间。
而在选择性搜索算法中,由于不知道物体的尺寸如何,所以会先设法得到若干个小尺度的候选框,然后再根据小尺度候选框之间的相似性将其合并为尺寸较大的候选框。
非极大值抑制
顾名思义,所谓的非极大值抑制就是抑制不是极大值的元素。在进行目标检测时,对同一个物体可能存在多个候选框,当候选框互不重叠时会全部保留,而当候选框的重叠程度(IOU)超过某个阈值时就会只保留置信度最大的候选框。

3. Fast R-CNN
Fast R-CNN在R-CNN的基础上做了一定的改进,它会先对整个图片提取特征,然后再选取 region proposal,这就避免了重复的运算。其算法流程如下:
(1) 提前整张图片的特征,得到 feature map(特征图);
(2) 用 selective search 选取若干个 ROI(region of interet,感兴趣的区域),并找到每个 ROI 在特征图上的映射 path(一小块图像);
(3) 用 ROI pooling layer 将path统一到相同的尺寸(因全连接的输入大小是固定的);
(4) 经过两个全连接层,然后对特征分别进行分类和 bounding box 回归,分类就是确定每个bounding box中是什么物体,而 bounding box回归就是对 bounding box 的位置进行调整。分类时使用 softmax 代替SVM,回归时使用了 smooth 的 L1损失。
Fast R-CNN采用了联合训练的方式,即总损失函数=分类损失+回归损失。在测试时还加入了NMS处理,以提高目标检测的质量。
ROI pooling是 SPP-Net的一个精简版,其流程为:
(1) 将ROI映射到特征图的对应区域;
(2) 将映射后的区域根据输出的大小平均分为同等大小的区域。比如,如果输出大小是2$\times$3的,则应将映射后的区域平均分为2行3列个小格。如果不能平均分,则对小格的大小取整;
(3) 对每个小格进行最大池化。
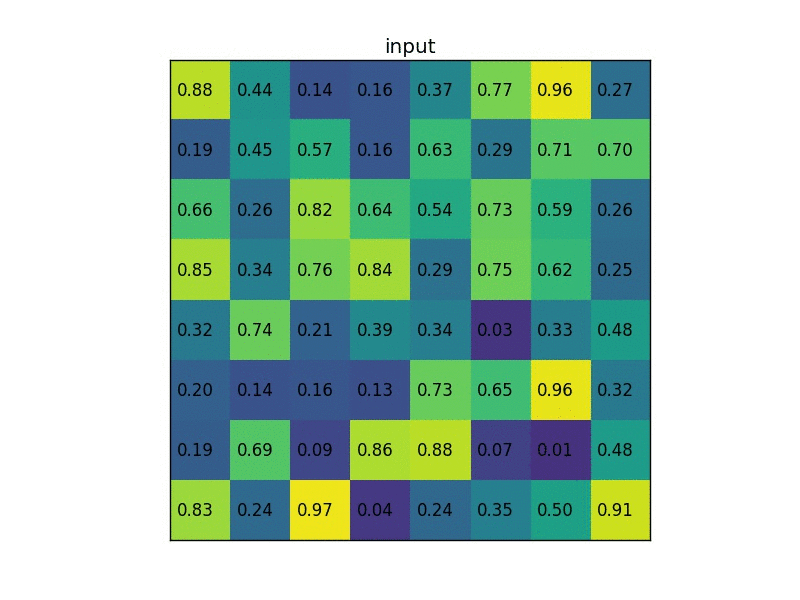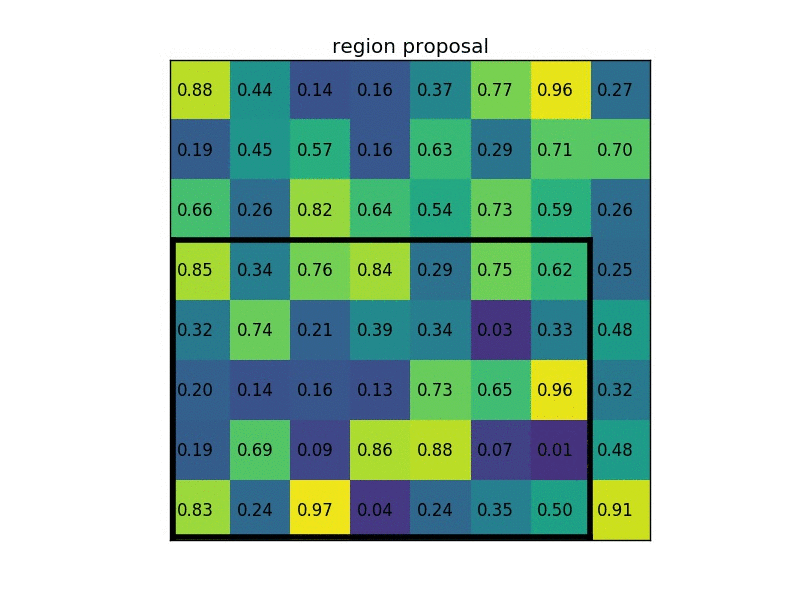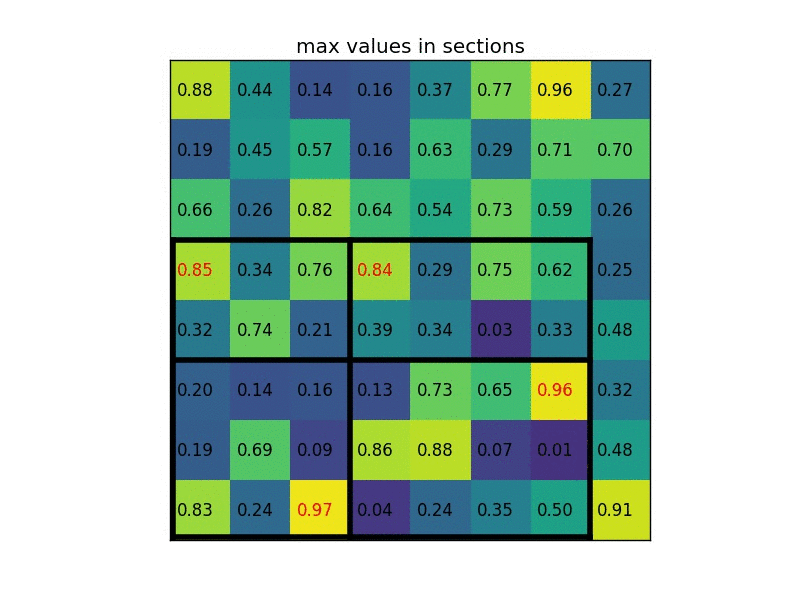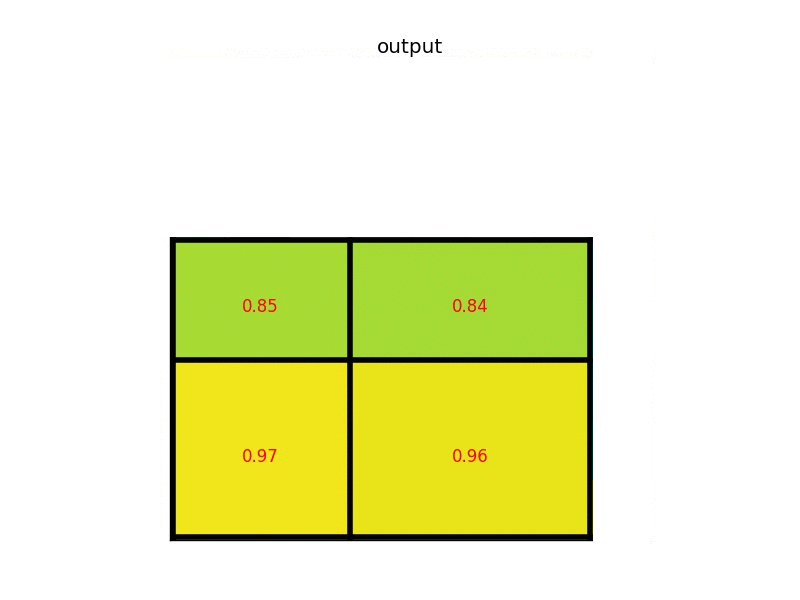
4. Faster R-CNN
Faster R-CNN将Fast R-CNN中的 selective search 方法替换为了 Region Proposal Networks(RPN)。RPN用来生成 region proposal,它通过softmax 分类判断 anchors 属于前景还是背景,再利用 bounding box 回归来修正 anchors ,以获得更精确的候选区域。
所谓的 anchors(锚点)就是三组大小不同的矩形框,每组矩形框又包含3个长宽比分别为 1:1,1:2,2:1的矩形框。因为如果对特征图的每个像素点都配备一组 anchors,则候选框会很多,所以实际中会在合适的 anchors 中随机选取 128个 postive anchors 和 128 个 negtive anchors来进行训练。
5. Mask R-CNN
Mask R-CNN使用 ResNet + 特征金字塔(Feature pyramid network, FPN)获取对应的特征图,并用 ROI Align 代替 ROI Pooling 来保证输出特征图大小固定。此外该网络还可以在标记出 bounding box的基础上,为前景增加 mask。
特征金字塔
特征金字塔是一种多尺度的检测方法,它先讲图片不断的做 2$\times$2 的pooling(下采样),形成多个尺寸由大到小的特征图,再对每一层特征图做 1 × 1 × n 1\times1\times n1×1×n (n为通道数)的卷积,形成多层只有一个通道的特征图。因为多层特征图呈现出金字塔的形状,所以称作特征金字塔。

ROI Align
ROI 映射到特征图后的区域的坐标往往是小数,ROI Pooling 所采取的办法是区域的大小直接取整,这样才能在特征图上截取对应的区域。

ROI Align 会在 ROI 的每个小格子中取 n 个采样点,并用双线性插值计算采样点的值,小格子的值就是采样点取最大值/平均值的结果。然后再对映射后的区域进行相应的池化操作。
Mask R-CNN由于使用了 ROI Align算法,所以在一定程度上提高了对小物体的检测精度。
以下是以上几个网络的对比图:

6. YOLO
YOLO(You Only Look Once)是一种 one-stage(单步)的端到端的目标检测算法,基本实现了对视频数据的实时处理。该算法一共有三个版本。
YOLO v1
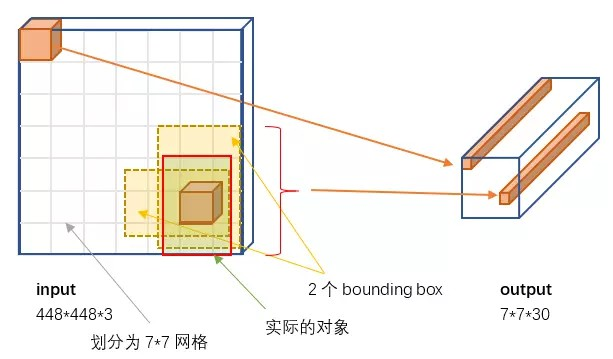
YOLO v1将图片平均划分为 7 × 7 = 49 7\times7=497×7=49 个网格(grid),每个网格只允许预测出 2 个边框(bounding box),它们很粗糙的覆盖了图片的整个区域。49 × 2 = 98 49\times2=9849×2=98 个边框再去除置信度较低的目标窗口,并由NMS去除冗余窗口,得到最终的结果。这种做法虽然降低了 mAP(平均精度均值),但是大幅提升了效率。
在该算法中总损失函数=bounding box 的位置误差 + bounding box 置信度误差 + 对象分类误差。该算法的缺点是容易产生定位错误,并且对小物体的检测效果不好。
YOLO v2
YOLO v2在前一版本的基础上主要做了以下改进:
(1) Batch Normalization
(2) High Resolution Classifier(高分辨率分类器): 先用小图训练,后用大图微调;
(3) Convolutional with Anchor Boxes: 不逐像素扫描,而是每个网格有给定个数个 anchor 来预测 bounding box;
(4) Dimension Cluster(维度聚类): 使用 K-means 算法训练 bounding box,以找到更好的边框宽高维度;
(5) Multi-Scale Training(多尺度训练): 每经过10次训练(10个epoch)就随机选择新的图片尺寸。
YOLO v3
YOLO v3 将输入图像平均分为 13 × 13 13\times1313×13 个网格,如果 ground truth 中某个物体的中心坐标落在某个网格中,则用该网格来预测该物体(因为每个网格所预测的 bounding box 的个数是有限的),所预测的 bounding box 中只有和 ground truth 的 IOU(交并比)最大的 bounding box 才用来预测该物体。
YOLO v3 还做了以下主要几点改进:
(1) 分类预测:用二元交叉熵损失来代替softmax损失进行类别预测;
(2) 跨尺度预测:提供了3种尺寸不一的边框,用相似的FPN提取这些尺寸的特征,以形成金字塔形网络;
(3) 特征提取器:用 DarkNet-53 来提取特征。
以下是YOLO不同版本的对比图:
