1、什么是缓存穿透
缓存穿透是指查询一个根本不存在的数据, 缓存和DB都不会命中,通常出于容错的考虑, 如果从存储层查不到数据则不写入缓存层。 缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。
造成缓存穿透的基本原因有两个:
- 自身业务代码或者数据出现问题。
- 一些恶意攻击、 爬虫等造成大量空命中。
解决办法:布隆过滤器(Bloom Filter)
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。布隆过滤器使用多个hash函数将key映射到不同的位上,可以减少hash冲突带来的影响。
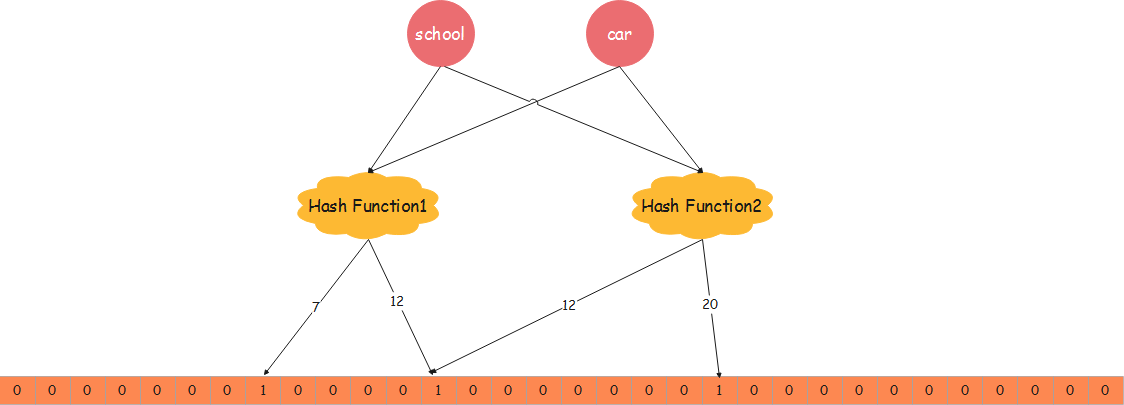
布隆过滤器优势:相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash 函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器缺点:但是布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。另外,一般情况下不能从布隆过滤器中删除元素,必须要重新构建布隆过滤器。下图说明为什么不能从布隆过滤器中删除元素。
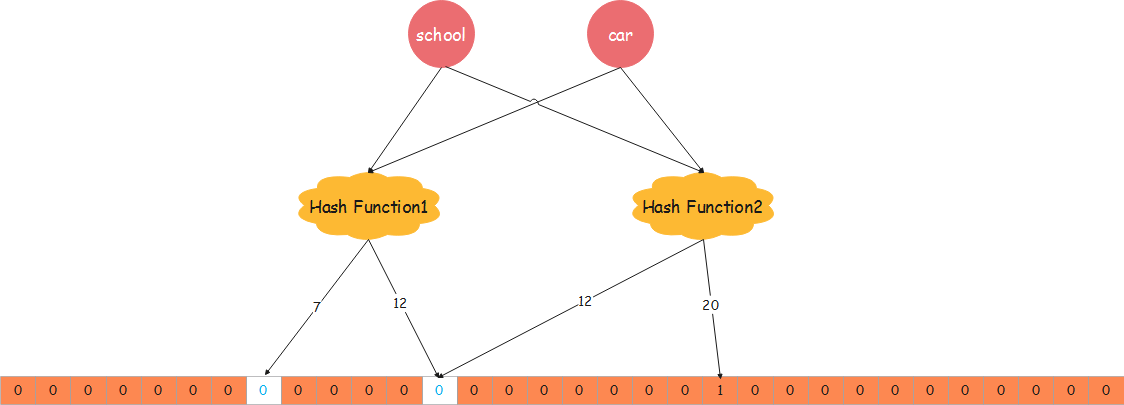
假设我们要删除school这个key,就需要把第7位和第12位置0,当我们查car这个key是否存在时,这个布隆过滤器会说car不存在。这就导致了误判。引入Counting Bloom Filter 可以解决原生布隆过滤器不支持删除的问题。
Counting Bloom Filter:Counting Bloom Filter 的出现,解决了上述问题,它将标准 Bloom Filter 位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的 k (k 为哈希函数个数)个 Counter 的值分别加 1,删除元素时给对应的 k 个 Counter 的值分别减 1。Counting Bloom Filter 通过多占用几倍的存储空间的代价, 给 Bloom Filter 增加了删除操作。基本原理是不是很简单?看下图就能明白它和 Bloom Filter 的区别在哪。
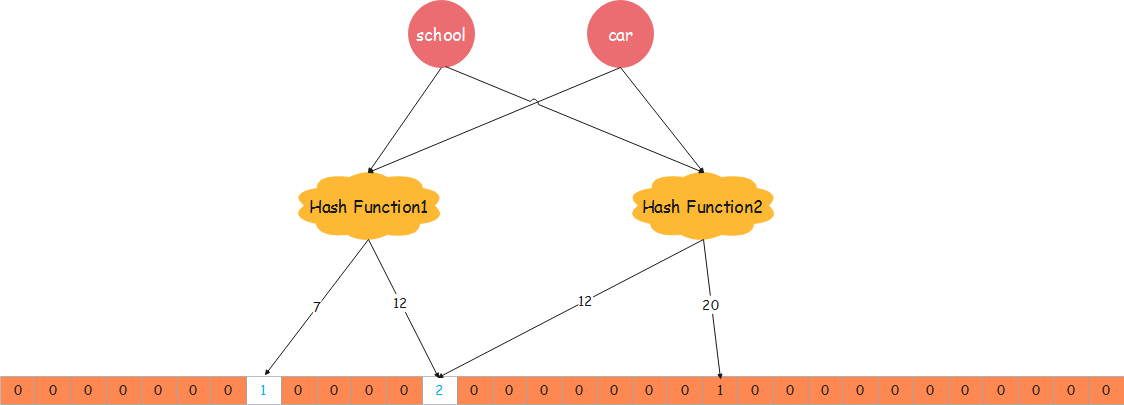
用Counter取代原生布隆过滤器中的一位,那么counter选取为多大合适呢?参考这里。
import mmh3
class CountingBloomFilter:
def __init__(self, size, hash_num):
self.size = size
self.hash_num = hash_num
self.byte_array = bytearray(size)
def add(self, s):
for seed in range(self.hash_num):
result = mmh3.hash(s, seed) % self.size
if self.bit_array[result] < 256:
self.bit_array[result] += 1
def lookup(self, s):
for seed in range(self.hash_num):
result = mmh3.hash(s, seed) % self.size
if self.bit_array[result] == 0:
return "Nope"
return "Probably"
def remove(self, s):
for seed in range(self.hash_num):
result = mmh3.hash(s, seed) % self.size
if self.bit_array[result] > 0:
self.bit_array[result] -= 1
cbf = CountingBloomFilter(500000, 7)
cbf.add("dantezhao")
cbf.add("yyj")
cbf.remove("dantezhao")
print (cbf.lookup("dantezhao"))
print (cbf.lookup("yyj"))2、什么是缓存击穿?
缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增。
分析:
关键在于某个热点的key失效了,导致大并发集中打在数据库上。所以要从两个方面解决,第一是否可以考虑热点key不设置过期时间,第二是否可以考虑降低打在数据库上的请求数量。
解决方案:
1、上面说过了,如果业务允许的话,对于热点的key可以设置永不过期的key。
2、使用互斥锁(分布式锁)。如果缓存失效的情况,只有拿到锁才可以查询数据库,降低了在同一时刻打在数据库上的请求,防止数据库打死。当然这样会导致系统的性能变差。
String get(String key) {
// 从Redis中获取数据
String value = redis.get(key);
// 如果value为空, 则开始重构缓存
if (value == null) {
// 只允许一个线程重建缓存, 使用nx, 并设置过期时间ex
String mutexKey = "mutext:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 从数据源获取数据
value = db.get(key);
// 回写Redis, 并设置过期时间
redis.setex(key, timeout, value);
// 删除key_mutex
redis.delete(mutexKey);
}
// 其他线程休息50毫秒后重试
else {
Thread.sleep(50);
get(key);
}
}
return value;
}3、缓存雪崩
当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
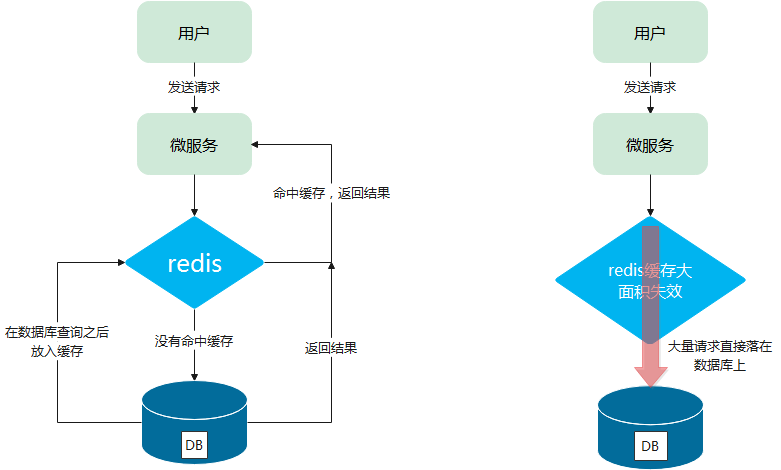
分析:
造成缓存雪崩的关键在于在同一时间大规模的key失效。为什么会出现这个问题呢,有几种可能,第一种可能是Redis宕机,第二种可能是采用了相同的过期时间。搞清楚原因之后,那么有什么解决方案呢?
解决方案:
1、在原有的失效时间上加上一个随机值,比如1-5分钟随机。这样就避免了因为采用相同的过期时间导致的缓存雪崩。
String get(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
//设置一个过期时间(300到600之间的一个随机数)
int expireTime = new Random().nextInt(300) + 300;
if (storageValue == null) {
cache.expire(key, expireTime);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}如果真的发生了缓存雪崩,有没有什么兜底的措施?
2、使用熔断机制比如使用Hystrix限流降级组件。当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
3、提高数据库的容灾能力,可以使用分库分表,读写分离的策略。
4、为了防止Redis宕机导致缓存雪崩的问题,可以搭建Redis集群,提高Redis的容灾性。
5、模拟预演。项目上线前, 演练缓存层宕掉后, 应用以及后端的负载情况以及可能出现的问题, 在此基础上做一些预案设定。
4、开发规范与性能优化
4.1 key名设计(1)
(1)【建议】: 可读性和可管理性
以业务名(或数据库名)为前缀(防止key冲突),用冒号分隔,比如 业务名:表名:id
trade:order:1
(2)【建议】:简洁性
保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视,例如:
user:{uid}:friends:messages:{mid} 简化为 u:{uid}:fr:m:{mid}
(3)【强制】:不要包含特殊字符
反例:包含空格、换行、单双引号以及其他转义字符
4.2 value设计
(1)【强制】:拒绝bigkey(防止网卡流量、慢查询)
在Redis中,一个字符串最大512MB,一个二级数据结构(例如hash、list、set、zset)可以存储大约40亿个(2^32-1)个元素,但实际中如果下面两种情况,我就会认为它是bigkey。
1. 字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
2. 非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。
一般来说,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
反例:一个包含200万个元素的list。
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞)。
bigkey的危害:
1.导致redis阻塞
2.网络拥塞:bigkey也就意味着每次获取要产生的网络流量较大,假设一个bigkey为
1MB,客户端每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾,而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey可能会对其他实例也造成影响,其后果不堪设想。
3. 过期删除:有个bigkey,它安分守己(只执行简单的命令,例如hget、lpop、zscore等),但它设置了过期时间,当它过期后,会被删除,如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。bigkey的产生:一般来说,bigkey的产生都是由于程序设计不当,或者对于数据规模预料不清楚造成的,来看几个例子:
(1) 社交类:粉丝列表,如果某些明星或者大v不精心设计下,必是bigkey。
(2) 统计类:如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey。
(3) 缓存类:将数据从数据库load出来序列化放到Redis里,这个方式非常常用,但有两个地方需要注意,第一,是不是有必要把所有字段都缓存;第二,有没有相关关联的数据,有的同学为了图方便把相关数据都存一个key下,产生bigkey。
如何优化bigkey
1. 将bigkey拆成一个个小key
big list: list1、list2、...listN
big hash:可以讲数据分段存储,比如一个大的key,假设存了1百万的用户数据,可以拆分成200个key,每个key下面存放5000个用户数据
2. 如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要
hmget,而不是hgetall),删除也是一样,尽量使用优雅的方式来处理。
【推荐】:选择适合的数据类型。
例如:实体类型(要合理控制和使用数据结构,但也要注意节省内存和性能之间的平衡)
反例:
set user:1:name tom
set user:1:age 19
set user:1:favor football
正例:
hmset user:1 name tom age 19 favor football
【推荐】:控制key的生命周期,redis不是垃圾桶。
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期)。
4.3 命令使用
1.【推荐】 O(N)命令关注N的数量例如hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替。
2.【推荐】:禁用命令
禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
3.【推荐】合理使用select
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处理,会有干扰。
4.【推荐】使用批量操作提高效率
1 原生命令:例如mget、mset。
2 非原生命令:可以使用pipeline提高效率。
但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。
注意两者不同:
1. 原生是原子操作,pipeline是非原子操作。
2. pipeline可以打包不同的命令,原生做不到
3. pipeline需要客户端和服务端同时支持。
5.【建议】Redis事务功能较弱,不建议过多使用,可以用lua替代
5、redis连接池参数设置
1)maxTotal:最大连接数,早期的版本叫maxActive实际上这个是一个很难回答的问题,考虑的因素比较多:
- 业务希望Redis并发量
- 客户端执行命令时间
- Redis资源:例如 nodes(例如应用个数) * maxTotal 是不能超过redis的最大连接数
maxclients。
- 资源开销:例如虽然希望控制空闲连接(连接池此刻可马上使用的连接),但是不希望因为连接池的频繁释放创建连接造成不必靠开销。
以一个例子说明,假设:
一次命令时间(borrow|return resource + Jedis执行命令(含网络) )的平均耗时约为1ms,一个连接的QPS大约是1000,业务期望的QPS是50000,那么理论上需要的资源池大小是50000 / 1000 = 50个。但事实上这是个理论值,还要考虑到要比理论值预留一些资源,通常来讲maxTotal可以比理论值大一些。但这个值不是越大越好,一方面连接太多占用客户端和服务端资源,另一方面对于Redis这种高QPS的服务器,一个大命令的阻塞即使设置再大资源池仍然会无济于事。
2)maxIdle、minIdle
maxIdle实际上才是业务需要的最大连接数,maxTotal是为了给出余量,所以maxIdle不要设置过小,否则会有new Jedis(新连接)开销。连接池的最佳性能是maxTotal = maxIdle,这样就避免连接池伸缩带来的性能干扰。但是如果并发量不大或者maxTotal设置过高,会导致不必要的连接资源浪费。一般推荐maxIdle可以设置为按上面的业务期望QPS计算出来的理论连接数,maxTotal可以再放大一倍。minIdle(最小空闲连接数),与其说是最小空闲连接数,不如说是"至少需要保持的空闲连接数",在使用连接的过程中,如果连接数超过了minIdle,那么继续建立连接,如果超过了maxIdle,当超过的连接执行完业务后会慢慢被移出连接池释放掉。如果系统启动完马上就会有很多的请求过来,那么可以给redis连接池做预热,比如快速的创建一些redis连接,执行简单命令,类似ping(),快速的将连接池里的空闲连接提升到minIdle的数量。