
1.导入包
#导入numpy包
import numpy as np
#导入pandas包
import pandas as pd2.一维数据结构
Numpy
#定义numpy的数组
a = np.array([1,2,3,4,5])
#访问数组的3种方法
#1.查询元素
a[0] #输出:1
#2.切片访问
a[1:3] #输出:array[2,3]
#3.循环访问
for i in a:
print(i)
'''输出:
1
2
3
4
5
'''
#查看数据类型
a.dtype #输出:dtype('int32')
#统计计算
#平均值
a.mean() #输出:3.0
#标准差
a.std() #输出:1.4142135623730951
#numpy数组中的每个元素必须是同一类型Pandas
#定义:Pandas一维数据结构:Series
#存放6家公司某一天的股价(单位是美元)。其中腾讯427.4港元兑换成美元是54.74
stockS=pd.Series([54.74,190.9,173.14,1050.3,181.86,1139.49],
index=['腾讯',
'阿里巴巴',
'苹果',
'谷歌',
'Facebook',
'亚马逊'])
stockS
'''输出:
腾讯 54.74
阿里巴巴 190.90
苹果 173.14
谷歌 1050.30
Facebook 181.86
亚马逊 1139.49
dtype: float64
'''
#获取描述统计信息
stockS.describe()
'''输出:
count 6.000000
mean 465.071667
std 491.183757
min 54.740000
25% 175.320000
50% 186.380000
75% 835.450000
max 1139.490000
dtype: float64
'''
#iloc属性用于根据索引获取值
stockS.iloc[0] #输出:54.74
#loc属性用于根据索引获取值
stockS.loc['腾讯'] #输出:54.74
#向量化运算:向量相加
s1=pd.Series([1,2,3,4],index=['a','b','c','d'])
s2=pd.Series([10,20,30,40],index=['a','b','e','f'])
s3=s1+s2
s3
'''输出:
a 11.0
b 22.0
c NaN
d NaN
e NaN
f NaN
dtype: float64
'''
#方法1:删除缺失值
s3.dropna()
'''输出:
a 11.0
b 22.0
dtype: float64
'''
#方法2:将缺失值进行填充
s3=s1.add(s2,fill_value=0)
s3
'''输出:
a 11.0
b 22.0
c 3.0
d 4.0
e 30.0
f 40.0
dtype: float64
'''3.二维数据结构
Numpy
#定义二维数组
a=np.array([
[1,2,3,4],
[5,6,7,8],
[9,10,11,12]
])
#查询元素
a[0,2] #输出:3
#获取第1行
a[0,:] #输出:array([1, 2, 3, 4])
#获取第1列
a[:,0] #输出:array([1, 5, 9])
#Numpy数轴参数:axis
#如果没有指定数轴参数,会计算整个数组的平均值
a.mean() #输出:6.5
#按轴计算:axis=1计算每一行
a.mean(axis=1) #输出:array[2.5, 6.5, 10.5]
#按轴计算:axis=0计算每一列
a.mean(axis=0) #输出:array[5, 6, 7, 8]Pandas
'''
Pandas二维数组:数据框(DataFrame)
'''
#第1步:定义一个字典,映射列名与对应列的值
salesDict={
'购药时间':['2018-01-01 星期五','2018-01-02 星期六','2018-01-06 星期三'],
'社保卡号':['001616528','001616528','0012602828'],
'商品编码':[236701,236701,236701],
'商品名称':['强力VC银翘片','清热解毒口服液','感康'],
'销售数量':[6,1,2],
'应收金额':[82.8,28,16.8],
'实收金额':[69,24.64,15]
}
#导入有序字典
from collections import OrderedDict
#定义一个有序字典
salesOrderDict=OrderedDict(salesDict)
#定义数据框:传入字典,列名
salesDf=pd.DataFrame(salesOrderDict)
salesDf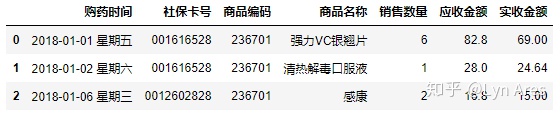
#平均值:是按每列来求平均值
salesDf.mean()
'''输出:
商品编码 236701.000000
销售数量 3.000000
应收金额 42.533333
实收金额 36.213333
dtype: float64
'''
'''
iloc属性用于根据位置获取值
'''
#查询第1行第3列的元素
salesDf.iloc[0,2] #输出:236701
#获取第1行,:代表所有列
salesDf.iloc[0,:]
'''输出:
购药时间 2018-01-01 星期五
社保卡号 001616528
商品编码 236701
商品名称 强力VC银翘片
销售数量 6
应收金额 82.8
实收金额 69
Name: 0, dtype: object
'''
#获取第1列,:代表所有行
salesDf.iloc[:,0]
'''输出:
0 2018-01-01 星期五
1 2018-01-02 星期六
2 2018-01-06 星期三
Name: 购药时间, dtype: object
'''
'''
loc属性用于根据索引获取值
'''
#查询第1行第1列的元素
salesDf.loc[0,'商品编码'] #输出:266701
#获取第1行
salesDf.loc[0,:]
'''输出:
购药时间 2018-01-01 星期五
社保卡号 001616528
商品编码 236701
商品名称 强力VC银翘片
销售数量 6
应收金额 82.8
实收金额 69
Name: 0, dtype: object
'''
#获取“商品名称”这一列
#salesDf.loc[:,'商品名称']
#简单方法:获取“商品名称”这一列
salesDf['商品名称']
'''输出:
0 强力VC银翘片
1 清热解毒口服液
2 感康
Name: 商品名称, dtype: object
'''数据框复杂查询:切片功能
#通过列表来选择某几列的数据
salesDf[['商品名称','销售数量']]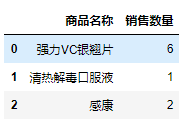
#通过切片功能,获取指定范围的列
salesDf.loc[:,'购药时间':'销售数量']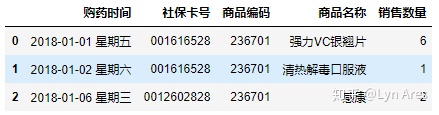
数据框复杂查询:条件判断
#通过条件判断筛选
#第1步:构建查询条件
querySer=salesDf.loc[:,'销售数量']>1
type(querySer) #输出:pandas.core.series.Series
querySer
'''输出:
0 True
1 False
2 True
Name: 销售数量, dtype: bool
'''
#第2步:应用查询条件
salesDf.loc[querySer,:]
查看数据集描述统计信息
#1.读取Ecxcel数据
fileNameStr='./朝阳医院2018年销售数据.xlsx'
xls = pd.ExcelFile(fileNameStr)
salesDf = xls.parse('Sheet1')
#2.打印出前5行
salesDf.head()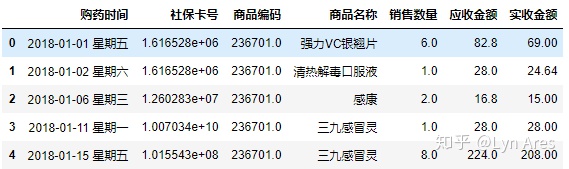
#3.查看某一列的数据类型
salesDf.loc[:,'销售数量'].dtype #输出:dtype('float64')
#4.有多少行,多少列
salesDf.shape #输出:(6578, 7)
#5.查看每一列的统计数值
salesDf.describe()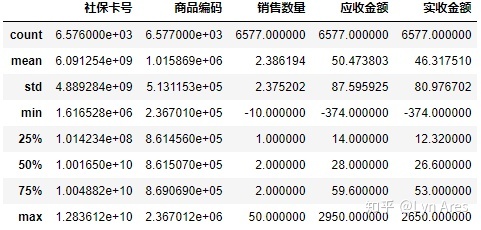
4.数据分析步骤
1)提出问题
从销售数据中分析出以下业务指标: 1)月均消费次数2)月均消费金额3)客单价4)消费趋势
2)理解数据
'''
路径中最好不要有中文,或者特殊符号啥的,不然路径会提示错误找不到。
最好将文件放到一个简单的英文路径下
'''
#excel文件路径,路径中的./表示在当前notebook所在的文件夹路径
fileNameStr='./朝阳医院2018年销售数据.xlsx'
'''
使用pandas的read_excel函数读取Ecxcel数据
参数sheet_name:数据在Excel里的哪个sheet下面,这块就写该sheet在excel里的名称
参数dtype=str 统一先按照字符串读入,之后再转换
pandas的read_excel函数官网地址:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html#pandas.read_excel
'''
salesDf = pd.read_excel(fileNameStr,sheet_name='Sheet1',dtype=str)
salesDf.head()
#打印前5行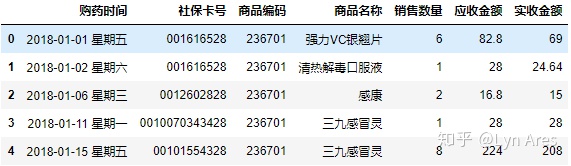
#有多少行,多少列
salesDf.shape #输出:(6578, 7)
#查看每一列的数据类型
salesDf.dtypes
'''输出:
购药时间 object
社保卡号 object
商品编码 object
商品名称 object
销售数量 object
应收金额 object
实收金额 object
dtype: object
'''3)数据清洗
①选择子集
选择需要使用到的列
#此处为举例,选择购药时间到销售数量列的0到4行数据
subSalesDf=salesDf.loc[0:4,'购药时间':'销售数量']②列名重命名
#字典:旧列名和新列名对应关系
colNameDict = {'购药时间':'销售时间'}
'''
inplace=False,数据框本身不会变,而会创建一个改动后新的数据框,
默认的inplace是False
inplace=True,数据框本身会改动
'''
salesDf.rename(columns = colNameDict,inplace=True)③缺失数据处理
python缺失值有3种:
1)Python内置的None值
2)在pandas中,将缺失值表示为NA,表示不可用not available。
3)对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。
后面出来数据,如果遇到错误:说什么foloat错误,那就是有缺失值,需要处理掉
所以,缺失值有3种:None,NA,NaN
dropna函数详细使用地址:
print('删除缺失值前大小',salesDf.shape)
#输出:删除缺失值前大小 (6578, 7)
#删除列(销售时间,社保卡号)中为空的行
#how='any' 在给定的任何一列中有缺失值就删除
salesDf=salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
print('删除缺失后大小',salesDf.shape)
#输出:删除缺失值前大小 (6575, 7)④数据类型转换
#字符串转换为数值(浮点型)
salesDf['销售数量'] = salesDf['销售数量'].astype('float')
salesDf['应收金额'] = salesDf['应收金额'].astype('float')
salesDf['实收金额'] = salesDf['实收金额'].astype('float')
print('转换后的数据类型:n',salesDf.dtypes)
'''输出
转换后的数据类型:
销售时间 object
社保卡号 object
商品编码 object
商品名称 object
销售数量 float64
应收金额 float64
实收金额 float64
dtype: object
'''
#字符串转换为日期数据类型
#测试:字符串分割
testList='2018-06-03 星期五'.split(' ')
testList #输出:['2018-06-03', '星期五']
testList[0] #输出:'2018-06-03'
'''
定义函数:分割销售日期,获取销售日期
输入:timeColSer 销售时间这一列,是个Series数据类型
输出:分割后的时间,返回也是个Series数据类型
'''
def splitSaletime(timeColSer):
timeList=[]
for value in timeColSer:
#例如2018-01-01 星期五,分割后为:2018-01-01
dateStr=value.split(' ')[0]
timeList.append(dateStr)
#将列表转行为一维数据Series类型
timeSer=pd.Series(timeList)
return timeSer
#获取“销售时间”这一列
timeSer=salesDf.loc[:,'销售时间']
#对字符串进行分割,获取销售日期
dateSer=splitSaletime(timeSer)
'''
注意:
如果运行后报错:AttributeError: 'float' object has no attribute 'split'
是因为Excel中的空的cell读入pandas中是空值(NaN),这个NaN是个浮点类型,一般当作空值处理。
所以要先去除NaN在进行分隔字符串
'''
#None是Python的一种数据类型,NaN是浮点类型 两个都用作空值
#None和NaN的区别
print('None的数据类型',type(None))
from numpy import NaN
print('NaN的数据类型',type(NaN))
#输出:
#None的数据类型 <class 'NoneType'>
#NaN的数据类型 <class 'float'>
dateSer[0:3]
'''输出
0 2018-01-01
1 2018-01-02
2 2018-01-06
dtype: object
'''
#修改销售时间这一列的值
salesDf.loc[:,'销售时间']=dateSer
salesDf.head() 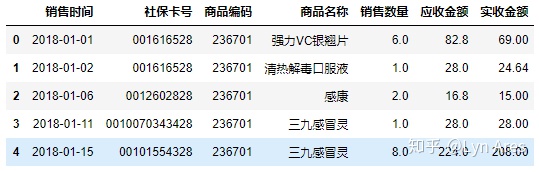
'''
数据类型转换:字符串转换为日期
'''
#errors='coerce' 如果原始数据不符合日期的格式,转换后的值为空值NaT
#format 是你原始数据中日期的格式
salesDf.loc[:,'销售时间']=pd.to_datetime(salesDf.loc[:,'销售时间'],
format='%Y-%m-%d',
errors='coerce')
salesDf.dtypes
'''输出:
销售时间 datetime64[ns]
社保卡号 object
商品编码 object
商品名称 object
销售数量 float64
应收金额 float64
实收金额 float64
dtype: object
'''
'''
转换日期过程中不符合日期格式的数值会被转换为空值,
这里删除列(销售时间,社保卡号)中为空的行
'''
salesDf=salesDf.dropna(subset=['销售时间','社保卡号'],how='any')⑤数据排序
print('排序前的数据集')
salesDf.head()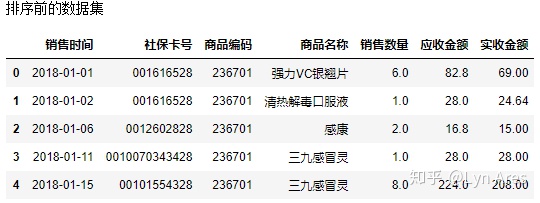
'''
by:按哪几列排序
ascending=True 表示升序排列,
ascending=False 表示降序排列
na_position=True表示排序的时候,把空值放到前列,这样可以比较清晰的看到哪些地方有空值
官网文档:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sort_values.html
'''
#按销售日期进行升序排列
salesDf=salesDf.sort_values(by='销售时间',
ascending=True,
na_position='first')
print('排序后的数据集')
salesDf.head()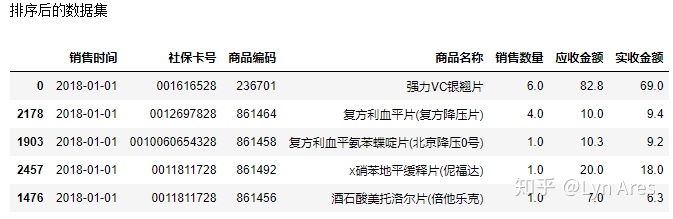
#重命名行名(index):排序后的列索引值是之前的行号,需要修改成从0到N按顺序的索引值
salesDf=salesDf.reset_index(drop=True)
salesDf.head()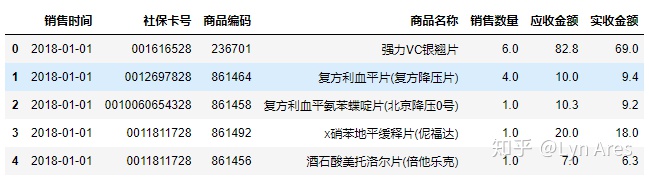
⑥异常值处理
#描述指标:查看出“销售数量”值不能小于0
salesDf.describe()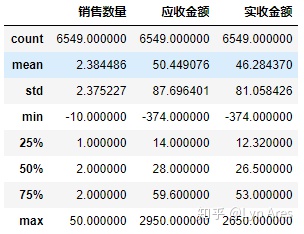
#删除异常值:通过条件判断筛选出数据
#查询条件
querySer=salesDf.loc[:,'销售数量']>0
#应用查询条件
print('删除异常值前:',salesDf.shape)
salesDf=salesDf.loc[querySer,:]
print('删除异常值后:',salesDf.shape)
#删除异常值前: (6549, 7)
#删除异常值后: (6506, 7)4)构建模型
业务指标1:月均消费次数=总消费次数 / 月份数
'''
总消费次数:同一天内,同一个人发生的所有消费算作一次消费
#根据列名(销售时间,社区卡号),如果这两个列值同时相同,只保留1条,将重复的数据删除
'''
kpi1_Df=salesDf.drop_duplicates(
subset=['销售时间', '社保卡号'])
#总消费次数:有多少行
totalI=kpi1_Df.shape[0]
print('总消费次数=',totalI)
#总消费次数= 5342
#计算月份数:时间范围
#第1步:按销售时间升序排序
kpi1_Df=kpi1_Df.sort_values(by='销售时间',
ascending=True)
#重命名行名(index)
kpi1_Df=kpi1_Df.reset_index(drop=True)
kpi1_Df.head()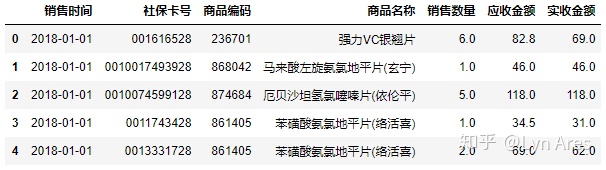
#第2步:获取时间范围
#最小时间值
startTime=kpi1_Df.loc[0,'销售时间']
#最大时间值
endTime=kpi1_Df.loc[totalI-1,'销售时间']
#第3步:计算月份数
#天数
daysI=(endTime-startTime).days
#月份数: 运算符“//”表示取整除
#返回商的整数部分,例如9//2 输出结果是4
monthsI=daysI//30
print('月份数:',monthsI)
#月份数: 6
#业务指标1:月均消费次数=总消费次数 / 月份数
kpi1_I=totalI // monthsI
print('业务指标1:月均消费次数=',kpi1_I)
#业务指标1:月均消费次数= 890业务指标2:月均消费金额 = 总消费金额 / 月份数
#总消费金额
totalMoneyF=salesDf.loc[:,'实收金额'].sum()
#月均消费金额
monthMoneyF=totalMoneyF / monthsI
print('业务指标2:月均消费金额=',monthMoneyF)
#业务指标2:月均消费金额= 50668.351666666305业务指标3:客单价=总消费金额 / 总消费次数
客单价(per customer transaction)是指商场(超市)每一个顾客平均购买商品的金额,客单价也即是平均交易金额。
'''
totalMoneyF:总消费金额
totalI:总消费次数
'''
pct=totalMoneyF / totalI
print('客单价:',pct)
#客单价: 56.9094178210404