前言:
本文总结了redis常用的数据类型以及底层数据结构,这在平常开发中经常使用,关于redis,作为内存数据库,在越来越多的场景中被使用到。更多的信息可以关注Redis官网,redis的作者以及社区对redis进行不断的更新。这篇文章内容是从一些博客,和《redis设计和实现》一书中总结出来的知识点。
六大数据类型:
Redis主要有六大数据类型:string,hash,list,set,zset,stream。
1. String
string是redis基本的数据类型,一个key对应一个value。redis中string类型是二进制安全的,redis的string可以包含任何数据,图片或者序列化的对象,一个redis中字符串value最多可以是512M。string之所以是二进制安全的,是因为redis内部使用了一种特殊的数据结构。我们都知道C字符串中的字符必须符合某种编码比如ASCII编码,除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将被误认为是字符串的结尾,这些限制使得C字符串只能保存文本数据,而不能保存图片,音频,视频等二进制数据。为了确保redis可以满足不同的使用场景,SDS数据结构的API都是二进制安全的,所有SDS API都会以处理二进制的方式来处理SDS存放在buf数组中的数据,程序不会对其中的数据做任何限制,过来和假设,数据写入时是怎么样,写出时还是什么样。这也就是我们将SDS中的buf属性称为字节数组的原因——redis不是用这个数组保存字符,而是用来保存二进制数据。SDS使用len属性的值而不是空字符串来判断字符串是否结束,所以用SDS来保存特殊格式的字符串没有任何问题。

应用场景:
一、 计数,由于redis是单线程的特点,可以通过incrby命令进行自增,而不用考虑线程安全问题
二、 限制次数: 比如登录次数校验,错误超过三次,五分钟内不让登录,每次登录设置key自增一次,并设置key的过期时间是5分钟,每次登录检查一下key的值来限制登录
三、 分布式锁: 通过setnx来实现分布式锁,关于分布式锁,后面会单独写一篇文章进行分析。
2. Hash:
hash是一个键值对集合,key还是一个string类型的key,但是value是一个键值对,类似于Java中的Map<String,Map<String,Object>> 集合。
同样是存储字符串,Hash和String的区别:
1. 把所有相关的值聚在一个key中,节省内存空间;
2. 只是用一个key,减少key冲突
3. 当需要批量获取值时,只需要一个命令,减少IO操作,节省时间。
使用场景:
1. 购物车:

最终用法:
- 以客户id作为key,每位客户创建一个hash存储结构存储对应的购物车信息
- 将商品编号作为field,购买数量作为value进行存储
- 添加商品:追加全新的field与value
- 浏览:遍历hash
- 更改数量:自增/自减,设置value值
- 删除商品:删除field
- 清空:删除key
- 全选:hgetall
- 购物车总数量:hlen
- 增加某件商品的数量:hincrby
2. 节日抢购:
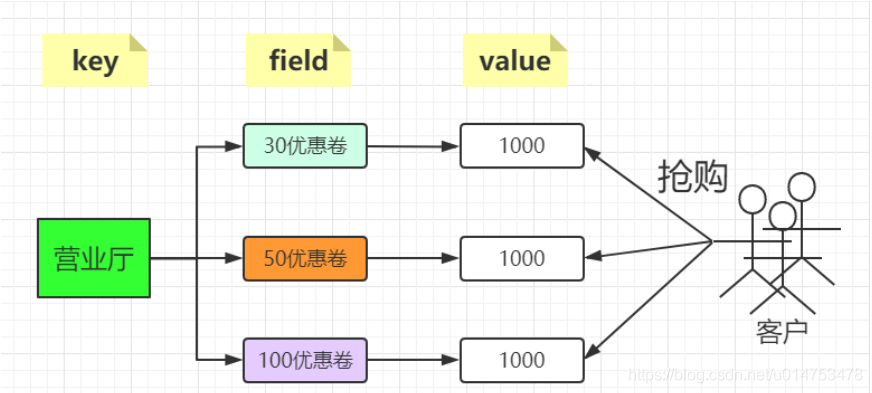
最终用法:
- 以商家id作为key
- 将参与抢购的商品id作为field
- 将参与抢购的商品数量作为对应的value
- 抢购时使用降值得方式控制产品数量
- 实际业务中还有超卖等实际问题,此处暂不考虑
hmset p01 c30 1000 c50 1000 c100 1000
hincrby p01 c30 -1
3. 实现单点登录,value里面可以存放用户的更多信息
3. List:
list列表,是简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部或者尾部,底层其实是一个链表。list有两个特点:有序,可以重复。这两个特点刚好区别于后面的集合和有序集合。
使用场景: 可以实现简单的消息队列,另外可以利用lrange命令,做基于redis的内存分页功能
4. Set:
Redis的set是string类型的无序集合,相对于list,有两个特点: 无序,不可重复。
使用场景:对于 set 数据类型,由于底层是字典实现的,查找元素特别快,另外set 数据类型不允许重复,利用这两个特性我们可以进行全局去重,比如在用户注册模块,判断用户名是否注册;另外就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
5. Zset:
zset(sorted set 有序集合),和上面的set 数据类型一样,也是 string 类型元素的集合,但是它是有序的。
应用场景: 对于 zset 数据类型,有序的集合,可以做范围查找,排行榜应用,取 TOP N 操作等。
6. Redis 5.0 新数据结构—stream:
Redis Stream 的内部,其实也是一个队列,每一个不同的key,对应的是不同的队列,每个队列的元素,也就是消息,都有一个msgid,并且需要保证msgid是严格递增的。在Stream当中,消息是默认持久化的,即便是Redis重启,也能够读取到消息。那么,stream是如何做到多播的呢?其实非常的简单,与其他队列系统相似,Redis对不同的消费者,也有消费者Group这样的概念,不同的消费组,可以消费同一个消息,对于不同的消费组,都维护一个Idx下标,表示这一个消费群组消费到了哪里,每次进行消费,都会更新一下这个下标,往后面一位进行偏移。
Redis底层数据结构:
通过OBJECT ENCODING key可以查看五大数据类型的底层数据结构,对于String类型,数据结构有embstr和int
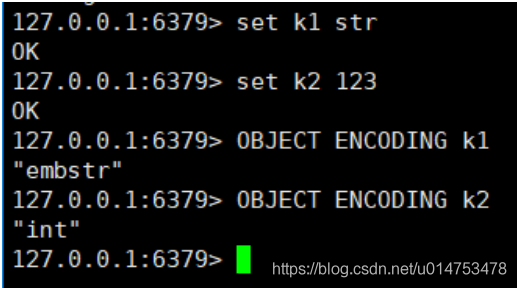
对于list数据类型,底层数据结构是quicklist。
1. 简单动态字符串SDS:
上面我们介绍了,redis的string是二进制安全的,是因为redis内部自己构建了一种名为简单动态字符串(simple dynamic string,sds)的抽象类型,并将SDS作为redis的默认字符串表示。
SDS数据结构:
structsdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度
intlen;
//记录 buf 数组中未使用字节的数量
intfree;
//字节数组,用于保存字符串
charbuf[];
}
SDS类型定义:
1. len保存了SDS中字符串的长度
2. buf[]数据用来保存字符串中的每个元素
3. free记录了buf数组中未使用的字节数量
这种数据结构的优点:
1. 获取字符串长度时间复杂度是O(1)
由于SDS中有len属性,可以直接读取字符串的长度,对于C语言,获取字符串的长度通常是通过遍历计数来实现的。在redis中通过strlen key命令可以获取key的字符串长度
2. 杜绝了缓冲区溢出
对于SDS数据类型,在进行字符修改时,会首先根据记录的len属性检查内存空间是否满足,如果不满足会进行相应的空间扩展,然后再进行修改操作,所以不会出现缓冲区溢出
3. 减少修改字符串的内存重新分配次数
C语言不会记录字符串的长度,所以修改时要重新分配,先释放再申请。如果不重新分配可能造成内存缓冲区溢出或者泄露。而SDS,由于len和free属性的存在,对于修改字符串SDS实现了空间预分配和惰性空间释放两种策略:
1、空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
2、惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用 free 属性将这些字节的数量记录下来,等待后续使用。(当然SDS也提供了相应的API,当我们有需要时,也可以手动释放这些未使用的空间。)
4. 二进制安全
因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。
5. 兼容C字符串
另外SDS除了保存数据库中的字符串值以外,SDS还可以作为缓冲区buffer。
2. 链表:
链表作为一种常用的数据结构,在C语言内部并没有内置这种数据结构的实现,Redis自己构建了链表的实现。
redis链表的特性:
a. 双端: 链表具有前置节点和后置节点的引用,获取这两个节点的时间复杂度都是O(1)
b. 无环: 表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问都是以 NULL 结束。
c. 带链表长度计数器: 通过len属性获取链表长度的时间复杂度是O(1)
d. 多态: 链表节点可以保存不同类型的值。
3. 字典:
字典又称为符号表或者关联数组,是一种用于保存键值对的抽象数据结构。字典中每一个键key都是唯一的,通过key可以对值进行查找和修改。Redis的字典使用哈希表作为底层实现。数据结构如下:
typedefstructdictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsignedlongsize;
//哈希表大小掩码,用于计算索引值
//总是等于 size-1
unsignedlongsizemask;
//该哈希表已有节点的数量
unsignedlongused;
}dictht
哈希表是由数组 table 组成,table 中每个元素都是指向 dict.h/dictEntry 结构,dictEntry 结构定义如下:
typedefstructdictEntry{
//键
void*key;
//值
union{
void*val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
structdictEntry *next;
}dictEntry
我们知道hash表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。Redis中采用的是链地址法,通过next指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。
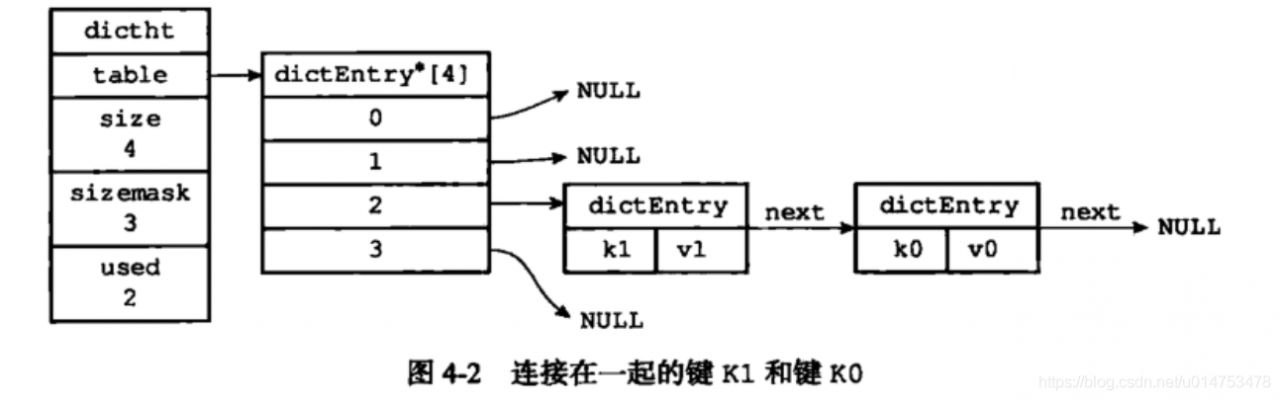
渐进式rehash:
所谓渐进式rehash是说扩容和收缩操作不是一次性完成的,而是分多次,渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行 增加操作,一定是在新的哈希表上进行的。
4. 跳表 skipList
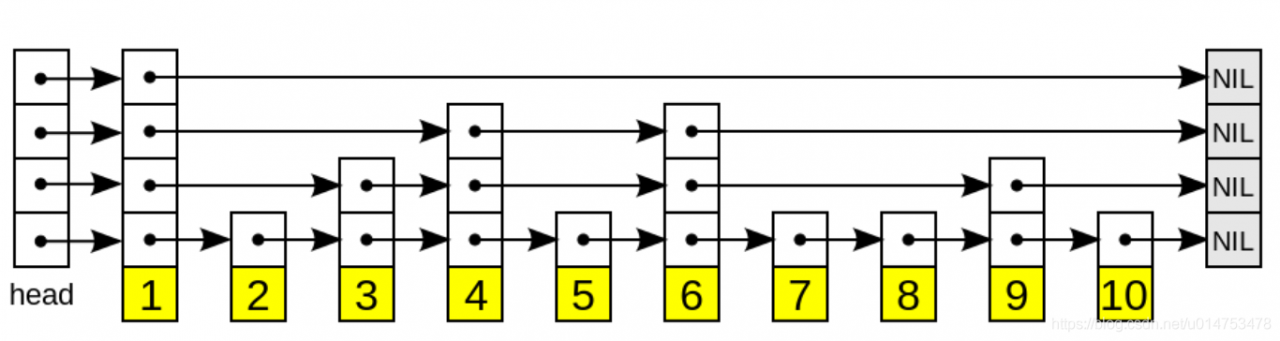
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳跃表具有如下性质:
a. 由很多层结构组成;
b. 每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
c、最底层的链表包含了所有的元素;
d、如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
e、链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;
Redis中跳跃表节点数据结构定义如下:
typedefstructzskiplistNode {
//层
structzskiplistLevel{
//前进指针
structzskiplistNode *forward;
//跨度
unsignedintspan;
}level[];
//后退指针
structzskiplistNode *backward;
//分值
doublescore;
//成员对象
robj *obj;
} zskiplistNode
多个跳跃节点组成一个跳跃表:
typedefstructzskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsignedlonglength;
//表中层数最大的节点的层数
intlevel;
}zskiplist;
①、搜索:从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么则往下找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,一直找到最底层的最后一个节点,如果找到则返回,反之则返回空。
②、插入:首先确定插入的层数,有一种方法是假设抛一枚硬币,如果是正面就累加,直到遇见反面为止,最后记录正面的次数作为插入的层数。当确定插入的层数k后,则需要将新元素插入到从底层到k层。
③、删除:在各个层中找到包含指定值的节点,然后将节点从链表中删除即可,如果删除以后只剩下头尾两个节点,则删除这一层。
5. 整数集合:
整数集合(intset)是Redis用于保存整数值的集合抽象数据类型,可以保存类型为int16_t, int32_t, int64_t的整数值,并且保证集合中不会出现重复元素。
6. 压缩列表:
压缩列表(ziplist)是redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包括任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是为了节省内存。
Redis数据类型实现原理:
每次在Redis中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,Redis中每个对象都由redisObject结构来表示:
typedefstructredisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void*ptr;
//引用计数
intrefcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
a. type属性:对象的type属性记录了对象的类型,就是redis中的五大数据类型。在redis中,键总是一个字符串对象,而值可以是五大数据类型中的一个,我们通常所说的是键对应的值的类型。
b. encoding 属性和 *prt 指针: 对象的prt指针指向对象底层的数据结构,而数据结构由encoding属性来决定。
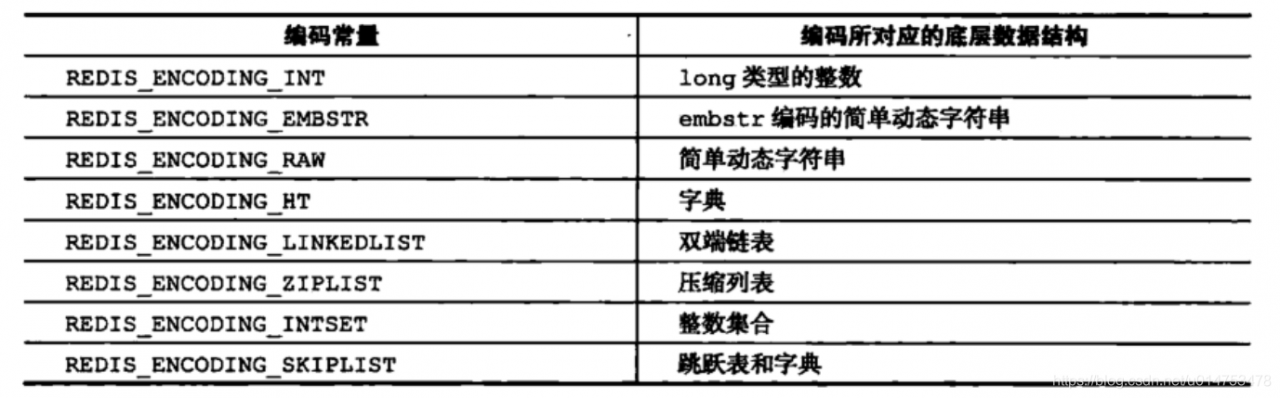
每种类型的对象至少使用了两种不同的编码:

1. 字符串对象:
Redis中key都是字符串类型,其他几种数据类型构成的元素也是字符串,字符串的长度不能超过512M。
编码:
字符串对象的编码可以使int,raw,embstr
1、int 编码:保存的是可以用 long 类型表示的整数值。
2、raw 编码:保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
3、embstr 编码:保存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
其实embstr是专门用来保存短字符串的一种优化编码,raw和embstr区别:embstr与raw都使用redisObject和sds保存数据,区别在于,embstr的使用只分配一次内存空间(因此redisObject和sds是连续的),而raw需要分配两次内存空间(分别为redisObject和sds分配空间)。因此与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。
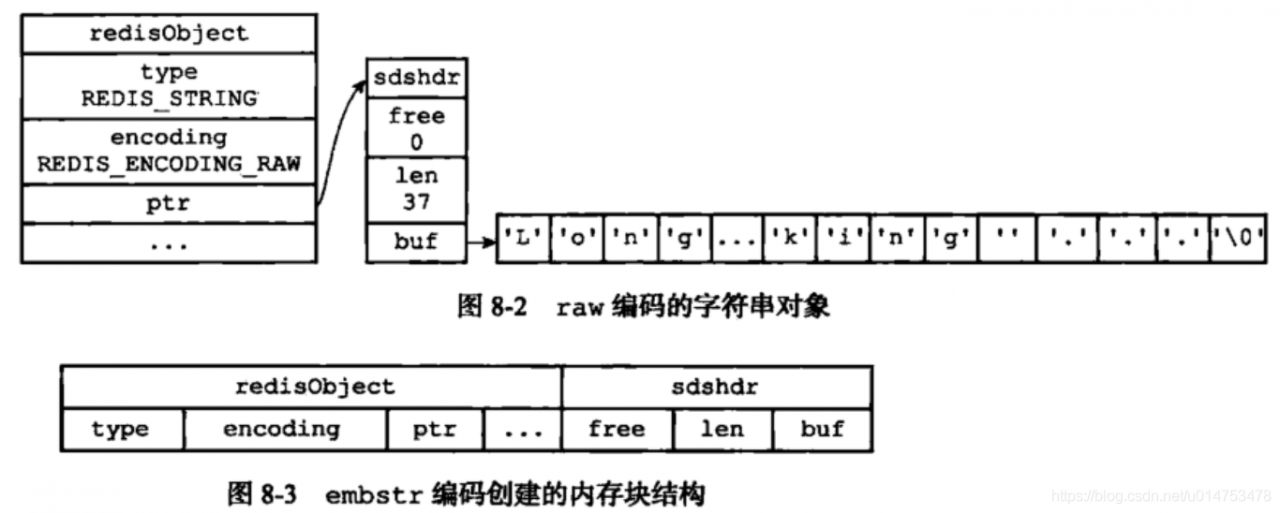
编码的转换:
当int编码保存的值不再是整数时,或者大小超过long的范围时,自动转换为raw
对于 embstr 编码,由于 Redis 没有对其编写任何的修改程序(embstr 是只读的),在对embstr对象进行修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。
2. 列表对象:
list列表,是简单的字符串列表,底层实际上是链表结构。
编码:
列表对象的编码可以使ziplist和linkedlist。
ziplist编码表示如下:

linkedlist编码表示如下:
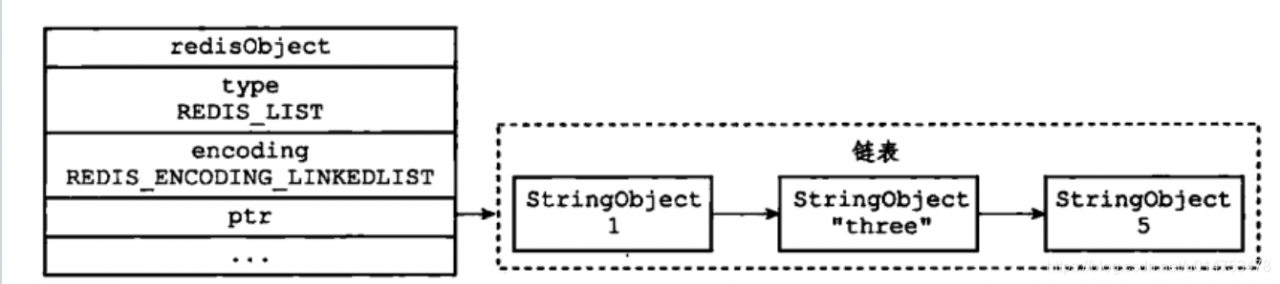
编码转换:
当满足如下条件时,使用ziplist编码:
1. 列表保存元素长度小于512个
2. 每个元素长度小于64字节
不满足上面两个条件的时候使用linkedlist编码, 上面两个条件可以在redis.conf 配置文件中的 list-max-ziplist-value选项和 list-max-ziplist-entries 选项进行配置。
3. hash对象:
哈希对象键是一个字符串对象,值是一个键值对集合。
编码:
哈希类型的编码是ziplist活着hashtable。
当使用ziplist的时候,新增的键值对是在压缩列表的表尾。存储结构如下:

当使用hashtable编码时,存储结构如下:

压缩列表是redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序存储结构,相对于字典数据结构,压缩列表的优势在于集中存储,节省空间。
编码转换:
和上面列表对象使用 ziplist 编码一样,当同时满足下面两个条件时,使用ziplist(压缩列表)编码:
1、列表保存元素个数小于512个
2、每个元素长度小于64字节
不能满足这两个条件的时候使用 hashtable 编码。第一个条件可以通过配置文件中的 set-max-intset-entries 进行修改。
4. 集合对象:
集合对象 set 是 string 类型(整数也会转换成string类型进行存储)的无序集合。注意集合和列表的区别:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
intset 编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合中。
hashtable 编码的集合对象使用 字典作为底层实现,字典的每个键都是一个字符串对象,这里的每个字符串对象就是一个集合中的元素,而字典的值则全部设置为 null。这里可以类比Java集合中HashSet 集合的实现,HashSet 集合是由 HashMap 来实现的,集合中的元素就是 HashMap 的key,而 HashMap 的值都设为 null。

字典表存储结构如下:

编码转换:
当集合同时满足以下两个条件时,使用 intset 编码:
1、集合对象中所有元素都是整数
2、集合对象所有元素数量不超过512
不能满足这两个条件的就使用 hashtable 编码。第二个条件可以通过配置文件的 set-max-intset-entries 进行配置。
5. 有序结合对象
有序集合对象是有序的,与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数score作为排序依据。
编码:
ziplist 编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。
压缩列表存储结构:
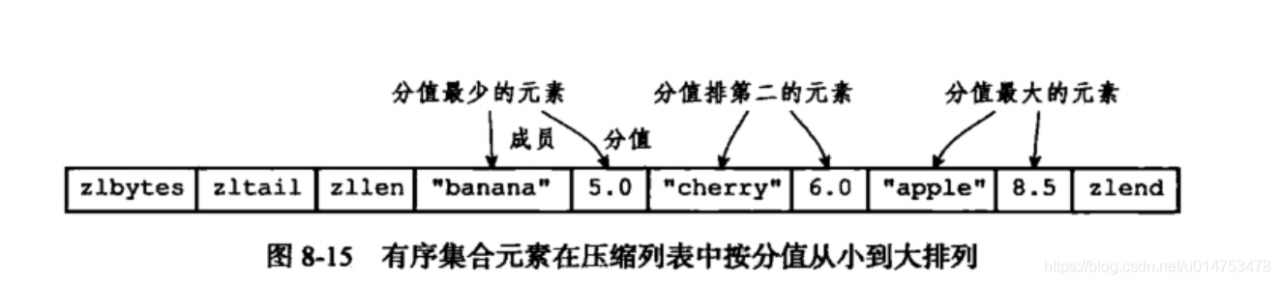
字典的键保存元素的值,字典的值则保存元素的分值;跳跃表节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。
这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,造成内存的浪费。
说明:其实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合。
编码转换:
当有序集合对象同时满足以下两个条件时,对象使用 ziplist 编码:
1、保存的元素数量小于128;
2、保存的所有元素长度都小于64字节。
不能满足上面两个条件的使用 skiplist 编码。以上两个条件也可以通过Redis配置文件zset-max-ziplist-entries 选项和 zset-max-ziplist-value 进行修改。
总结:
大多数情况下,redis使用SDS作为字符串的表示,相对于C语言字符串,SDS具有常数复杂度获取字符串长度,杜绝了缓存区的溢出,减少了修改字符串长度时所需的内存重分配次数,以及二进制安全能存储各种类型的文件,并且还兼容部分C函数;
通过为链表设置不同类型的特定函数,Redis链表可以保存各种不同类型的值,除了用作列表键,还在发布与订阅、慢查询、监视器等方面发挥作用;
Redis字典底层使用hash表实现,每个字典表通常有两个hash表,一个平常使用,另一个渐进式rehash的时候使用,使用链地址法解决hash冲突;
跳跃表通常是有序集合的底层实现之一,表中的节点按照分值大小进行排序;
整数集合是集合键的底层实现之一,底层由数组构成,升级特性能尽可能的节省内存;
压缩列表是一种为了节省内存而开发的顺序型数据结构,通常作为列表键和hash键的底层实现之一。