elasticsearch
第一章 ES
第二章 es stack:ELK
文章目录
基于mysql思考:
1、单表数据量过大时如何存储
2、复杂搜索 单表千万级时模糊搜索,文档搜索、分词后搜索等mysql无法实现的功能
明显mysql搞不定,es搜索引擎,能解决如上的问题。 可以简单理解为企业级的百度搜索
一、基础知识
1、概念
| ES | mysqy | 备注 |
|---|---|---|
| index | 数据库 | 数据库 |
| type | N/A | 忽略 之前对应mysql的表, 但es趋势废弃这个默认_doc |
| doc | 行 | |
| 属性 | 字段 | |
| node节点 | 数据库节点 | 集群环境下多个节点 |
| master节点 | 额外管理集群范畴的变动,如索引本身的定义,集群中添加节点、删除节点 | |
| 协调节点 | 用于路由,文档读写操作都是由协调节点路由到具体节点,不会因流量增加造成主节点瓶颈 | |
| data节点 | 默认是数据节点 | |
| 主分片 | 分表(写) | 用主库并不是很合适,主分片写,一个索引会先分片(分表),比如分成3个表,则这3个主分片负责写,每个主分片再备份数据叫副分片 |
| 副本分片 | 备份表(读) | es提高容错性/吞吐量的手段,主分片写完后会备份到副本分片(主从复制的过程由ES自身完成),副本越多,读效率越高 |
| 倒排索引 | I love you,被拆词为三行,保存在数据字典中,每个词只对应文档 |
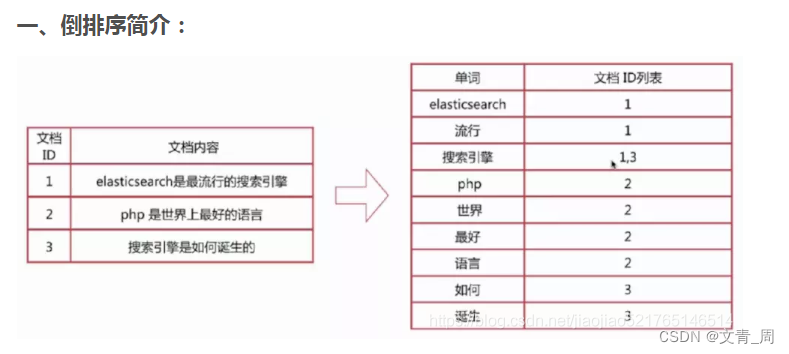
2、建索引
"aliases": {
"qd-quotation-indexs": {}
},
"settings": {
"index":{
## 最大查询结果 默认10000条 分页查询结果超过了就会报错
"max_result_window": 20000
},
"refresh_interval": "500ms",## 准实时的时间差异,内存查询到OS cache的周期
"number_of_shards": 4,##主分片
"number_of_replicas": 1, ## 副本分片
"codec": "best_compression",
"analysis": {
"normalizer": {
"lowercase_normalizer": {
"filter": ["lowercase", "asciifolding"],
"type": "custom",
"char_filter": []
}
},
"analyzer": {
## 二、ES分词流程:Character filter-->>Tokenizer-->>Token filters
"ngram_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer",
"filter": ["lowercase"]
},
"productCode_search_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase"]
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 20
}
}
}
},
"mappings": {
"_doc": {
"dynamic": "false",
"_routing": {
"required": false
},
"_all": {
"enabled": false
},
"properties": {
"pkid": {
"type": "keyword"
},
"belongIndustry": {
"type": "byte"
},
"custNickName": {
"type": "text",
"analyzer": "ik_max_word"
},
"quotationContent": {
"type": "text",
"analyzer": "ngram_analyzer",
"search_analyzer": "productCode_search_analyzer"
},
"standardName": {
"type": "keyword",
"normalizer": "lowercase_normalizer"
},
"staffName": {
"type": "text",
"analyzer": "ik_max_word"
},
"productList": {
"type": "nested",
"properties": {
"pkid": {
"type": "keyword"
},
}
}
}
}
3、查询语法
POST _scripts/quotation-index-page-search-template
{
"script": {
"lang": "mustache",
"source": "********替换为下面的并转义分号"
}
}
{
"query": {
"bool": {
"must": [
{"exists": {
"field": "pkid"
}},
{{#accountIdsStr}},
{"terms": {
"accountId": [
{{#toJson}}accountIdsStr{{/toJson}}
]
}}
{{/accountIdsStr}}
{{#customerName}},
{"match": {
"custNickName": "{{customerName}}"
}}
{{/customerName}}
{{#customerOpenid}},
{"term": {
"custOpenId": "{{customerOpenid}}"
}}
{{/customerOpenid}}
]
{{#manualQuotation}},
"must_not": [
{
"exists": {
"field": "originalText"
}
}
]
{{/manualQuotation}}
}
}
{{#start}},
"from": {{start}}
{{/start}}
{{#pageSize}},
"size": {{pageSize}}
{{/pageSize}}
,
"sort": [{
"pkid": "desc"
}]
}
分析器组成:
Character filter–>>Tokenizer–>>Token filters
二、应用场景
1、大数据存储
2、复杂搜索
3、日志(ELK)
三、原理
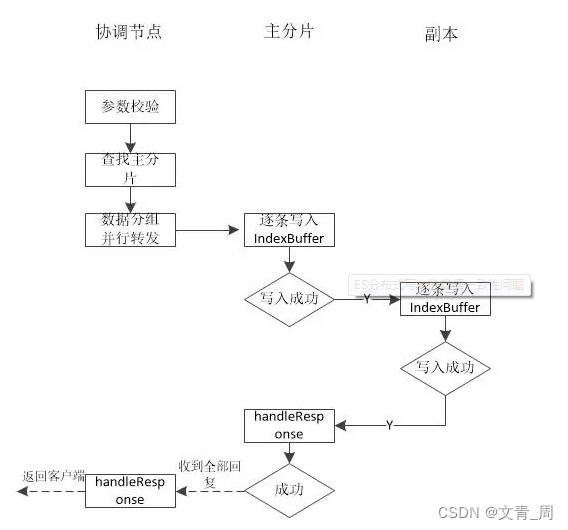
写流程
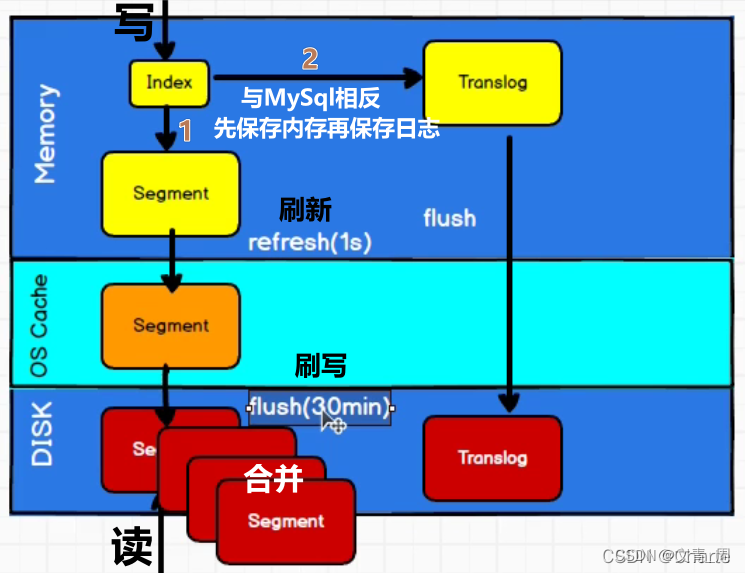
写入成本很大,故默认不做实时写入,攒一波批量写,先写内存,默认1s刷新到os cache即操作系统缓存,此时才能被搜索到,每刷新一次生成一个segment文件,搜索时是从segment文件中获取并合并,
段合并:小文件太多了不行,故会合并
.del文件,如果是更新操作,则会记录一个del文件中,查询好后通过del文件过滤掉结果,合并段的时候也会永久删除del了的doc。
内存中的数据会待比较久,flush操作时才刷新到磁盘,如何保证数据不丢呢? 于是就出现了translog,兜底机制,防止数据丢失的,这只是记录写的日志,并不需要分词、倒排索引等处理,写入成本远远低于写到索引数据写磁盘
读流程
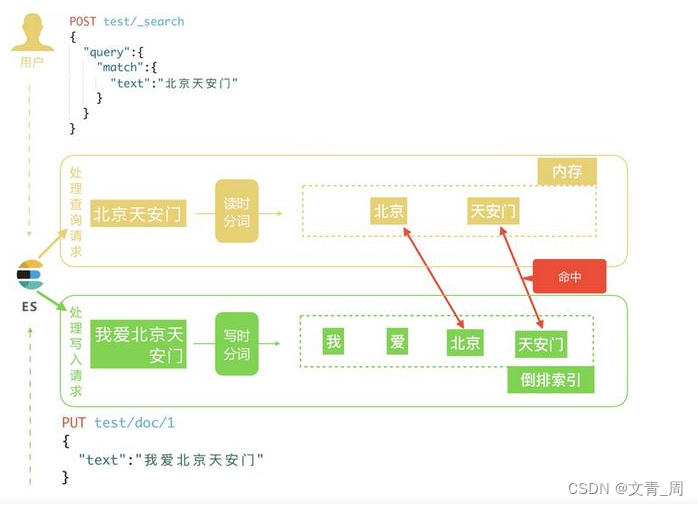
1、 指定id的话 则由协调节点路由
2、Query Then Fetch 如果是普通的search,则由协调发给每一个分片(主副选一个),再返回id给协调结果,协调节点聚合后通过id再查一遍
Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少
的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document
frequency,这个评分更准确,但是性能会变差。
四、组件对比
es vs solr
它们都是基于Lucene搜索引擎库基础之上开发,一款优秀的,高性能的企业级搜索服务器。【是因为他们都是基于分词技术构建的倒排索引的方式进行查询】
solr太老,技术栈的核心思想跟不上
es新,流行度更高,其实也说不上两者的核心差异,solr没用过
es vs mysql
es搜索功能强于mysql,数据间关系明显低于mysql
es会比mysql快吗?
mysql索引是b-tree
五、常见问题
- master节点的作用
主节点负责集群范畴的工作
a、索引创建删除等
b、主节点负责ping其他节点,确定节点状态
c、决定分片在节点间的分配等
依照单一职责原则,尽量让主节点只作为主节点,而不作为数据节点
- 主节点选举流程
个人理解,选举原则是和大部分节点网络是通的&只有一个主节点
a、和大部分节点网络是通的,即ping一遍集群全部节点,每一个节点从ping通的节点中选一个主节点出来,包括自己。 不用等全部投票,xxxx个节点投票即可(xxxx个一般配置成集群节点数过半,防止脑裂问题)
b、如果候选主节点有多个,则按相同的排序规则,如节点id排序,选第一个
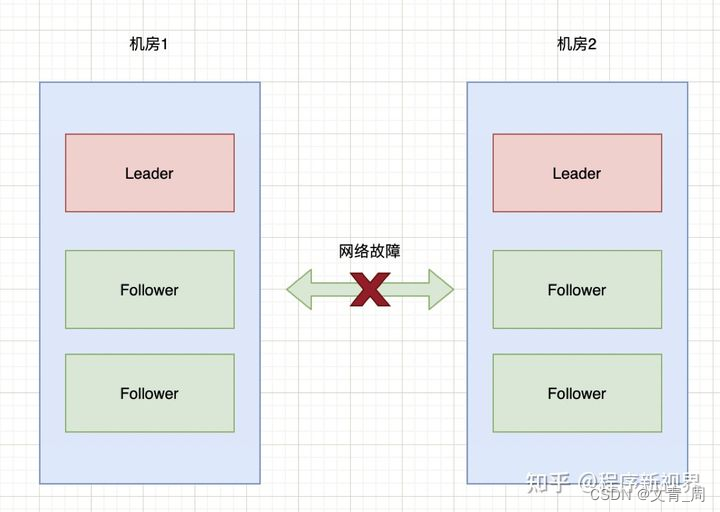
- 集群脑裂问题(多个主节点)
脑裂问题是分布式系统中和分区容忍性关联度非常高的一个问题,典型原因是网络问题,造成两个机房各自为政,各自为一个集群,当网络恢复后,数据如何合并会非常非常复杂,通用的方法就是主节点的过半选举原则,比如总共5个或者6个节点时,必须要有3个或者4个节点选择主节点,这样另一个机房的就选不出主节点而不能成为一个集群
数据一致性
通过版本号乐观锁控制,
a、同一个分片上的数据:
同一个docid每次写时,旧数据不变,新数据版本号+1,旧的数据会放入del中(不确定,但感觉会放),当指定版本号更新时,版本号不对就报错,未指定,则会CAS操作,先找最大的版本号,更新前再判断一把是不是最大版本号。
b、主副分片的数据一致性(可配置一致性级别)
写的时候,是写主分片,然后同步给副本分片,可以配置副本同步的进度,可以是大部分副本写完或者不等或者必须全部写完才返回成功,一般不会全部写完,没有强一致性
复制可能是异步的,通过版本号控制就能确保同步的是最新的数据索引优化思考和总结
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用极其苛刻的态度使用内存。
对于使用Elasticsearch进行索引时需要注意:
不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
Bulk方式效率高于index 大概是10倍