集合框架
什么是集合
集合与数组一样,可以保存一组元素,并且提供了操作元素的相关方法,使用更方便.
java集合框架中相关接口:Collection
java.util.Collection接口:
java.util.Collection是所有集合的顶级接口.Collection下面有多种实现类,因此我们有更多的数据结构可供选择.
Collection下面有两个常见的子接口:
- java.util.List:线性表.是可重复集合,并且有序.
- java.util.Set:不可重复的集合,大部分实现类是无序的.
这里可重复指的是集合中的元素是否可以重复,而判定重复元素的标准是依靠元素自身equals比较的结果,为true就认为是重复元素.
集合方法:
boolean add(E e):向当前集合中添加一个元素.当元素成功添加后返回true
任何引用类型的元素都可以添加到集合中(集合只能添加引用元素)
int size():返回当前集合的元素个数
boolean isEmpty():判断当前集合是否为空集(不含有任何元素)
clear():清空集合
Collection c = new ArrayList();
//add方法:
c.add("one");
c.add("two");
c.add("three");
c.add("four");
c.add("five");
c.add(6);//自动装箱:int型转换为Integer
System.out.println(c);//[one, two, three, four, five,6]
//size()方法:
int size = c.size();
System.out.println("size:"+size);//size:6
c.add("zero");//当add一个新元素size会变
System.out.println("size:"+size);//size:7
//isEmpty()方法:
boolean isEmpty = c.isEmpty();
System.out.println("是否为空集:"+isEmpty);//isEmpty:false
//clear()方法:
c.clear();
System.out.println(c);//[]
System.out.println("size:"+c.size());//0
System.out.println("是否为空集:"+c.isEmpty());//isEmpty:true
集合与元素equals方法相关的方法
集合集合的很多操作有与元素的equals方法相关。
集合重写了Object的toString方法,输出的格式为: [元素1.toString(), 元素2.toString(), ....]
boolean contains(Object o):判断当前集合是否包含给定元素,这里判断的依据是给定元素是否与集合现有元素存在equals比较为true的情况。
remove():remove用来从集合中删除给定元素,删除的也是与集合中equals比较为true的元素。注意,对于可以存放重复元素的集合而言,只删除一次。
Collection c = new ArrayList();//list子类
//Collection c = new HashSet();//set子类
c.add(new Point(1,2));
c.add(new Point(3,4));
c.add(new Point(5,6));
c.add(new Point(7,8));
c.add(new Point(1,2));
//集合重写了Object的toString()方法:
System.out.println(c);
//[Point{x=1, y=2}, Point{x=3, y=4}, Point{x=5, y=6}, Point{x=7,
y=8},Point{x=1, y=2}]
Point p = new Point(1,2);
System.out.println("p"+p);//p:Point{x=1, y=2}
//contains()和remove()与equals相关
//contains()方法:
boolean contains = c.contains(p);
//此步需要判断Point类是否重写了equals()方法,不重写默认比较的是地址
System.out.println("包含:"+contains);
//重写equals:包含:true 不重写equals:包含:false
//remove()方法:
//[Point{x=1, y=2}, Point{x=3, y=4}, Point{x=5, y=6}, Point{x=7,
y=8},Point{x=1, y=2}]
c.remove(p);//p:Point{x=1, y=2}
//删除equals与p相同的元素,当有重复内容的多个元素,remove只会删第一个
//删掉以后那个元素就真的删掉了,集合长度相应减1
System.out.println(c);
//Point重写了equals:[Point{x=3, y=4}, Point{x=5, y=6}, Point{x=7, y=8},
Point{x=1, y=2}]
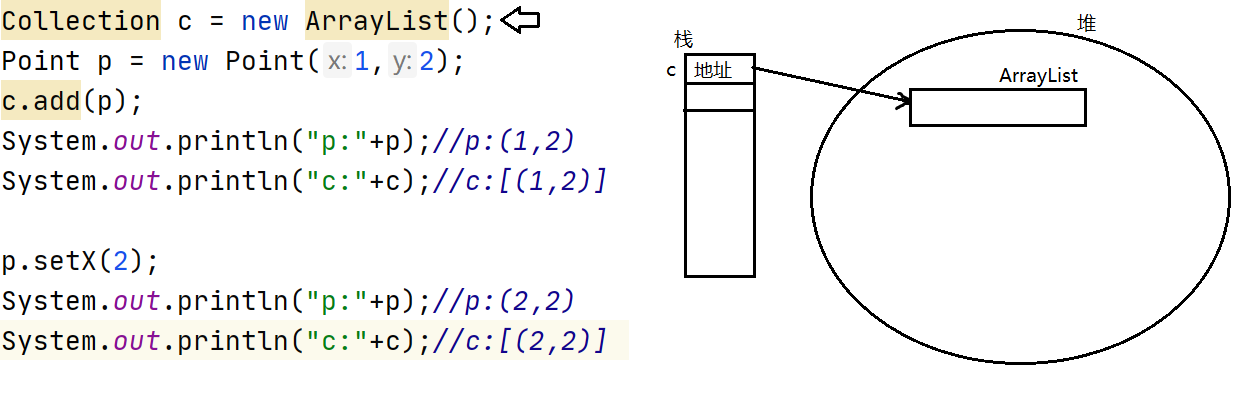
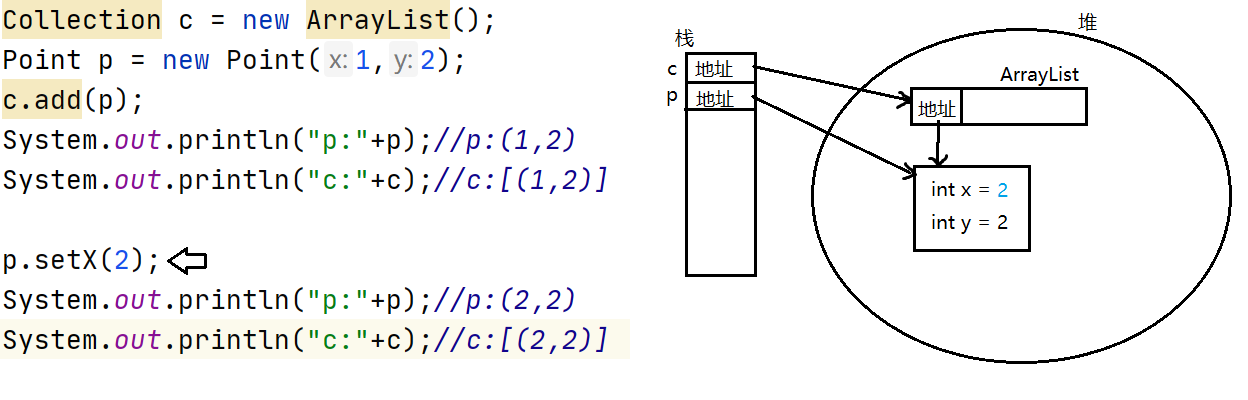
集合存放的是元素的引用
集合只能存放引用类型元素,并且存放的是元素的引用
Collection c = new ArrayList();
Point p = new Point(1,2);
c.add(p);
System.out.println("p:"+p);//p:(1,2)
System.out.println("c:"+c);//c:[(1,2)]
p.setX(2);
System.out.println("p:"+p);//p:(2,2)
System.out.println("c:"+c);//c:[(2,2)] 集合存的是个地址


集合间的操作
集合提供了:如取并集,删交集,判断包含子集等操作
boolean addAll(Collection c):将给定集合中的所有元素添加到当前集合中。当前集合若发生了改变则返回true
boolean containsAll(Collection c):判断当前集合是否包含给定集合中的所有元素
boolean removeAll(Collection c):删除当前集合中与给定集合中的共有元素
//list集合
Collection c1 = new ArrayList();//可重复元素
c1.add("java");
c1.add("c++");
c1.add(".net");
c1.add("android");
System.out.println("c1:"+c1); //c1:[java, c++, .net, android]
//set集合
Collection c2 = new HashSet();//不可重复元素
c2.add("android");
c2.add("ios");
System.out.println("c2:"+c2);//c2:[android, ios]
//addAll()方法:
boolean tf = c1.addAll(c2);//将集合2的所有元素添加到集合1中
System.out.println(tf);//true
System.out.println("c1:"+c1);
//c1:[java, c++, .net, android, android, ios]
c2.addAll(c1);//将集合1的所有元素添加到集合2中
System.out.println("c2:"+c2);
//c2:[c++, java, android, .net, ios]
Collection c3 = new ArrayList();
c3.add("ios");
c3.add("c++");
c3.add("php");
System.out.println("c3:"+c3);//[ios, c++, php]
//containsAll()方法:
boolean contains = c1.containsAll(c3);
//判断集合1中是否包含集合3中所有元素
System.out.println("c1是否包含c3:"+contains);//c1是否包含c3:false
//retainAll()方法:
//c1.retainAll(c3);//取交集,仅保留当前集合中与给定集合的共有元素
//System.out.println("c1:"+c1);//[c++]
//removeAll()方法:
c1.removeAll(c3);//删交集:删除当前集合与给定集合共有的元素
System.out.println("c1:"+c1);//c1:[java, .net, android]
集合的遍历
Collection提供了统一的遍历集合方式:迭代器模式
Collection接口没有定义单独获取某一个元素的操作,因为不通用。 但是Collection提供了遍历集合元素的操作。该操作是一个通用操作,无论什么类型的集合都支持此种遍历方式:迭代器模式。
Iterator iterator():该方法可以获取一个用于遍历当前集合元素的迭代器.
java.util.Iterator接口:迭代器接口,定义了迭代器遍历集合的相关操作,不同的集合都实现了一个用于遍历自身元素的迭代器实现类,我们无需记住它们的名字,用多态的角度把他们看做为Iterator即可.
迭代器遍历集合遵循的步骤为:问,取,删,其中删除元素不是必要操作
迭代器提供的相关方法:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() { throw new UnsupportedOperationException("remove");}
...
}boolean hasNext():判断集合是否还有元素可以遍历
E next():获取集合下一个元素(第一次调用时就是获取第一个元素,以此类推)
Collection c = new ArrayList();
c.add("one");
c.add("two");
c.add("three");
c.add("four");
c.add("five");
System.out.println(c);//[one, two, three, four, five]
//获取迭代器
Iterator it = c.iterator();
while(it.hasNext()){
String str = (String)it.next();
//此步强转原因:集合的遍历不仅仅是为了输出,
//更为了将来要拿出来使用,做具体的操作,所以要强转
System.out.println(str);
}
System.out.println(c);
迭代器遍历过程中不得通过集合的方法增删元素
迭代器要求遍历的过程中不得通过集合的方法增删元素,否则会抛出异常:
ConcurrentModificationException
Collection c = new ArrayList();
c.add("one");
c.add("#");
c.add("two");
c.add("#");
c.add("three");
c.add("#");
c.add("four");
c.add("#");
c.add("five");
System.out.println(c);//[one, #, two, #, three, #, four, #, five]
//获取迭代器:迭代器不能做加法(即add元素),容易死循环,可以做减法
Iterator it = c.iterator();//是将集合c的地址赋给了it
/*用集合的remove()方法删除:会抛出异常
while(it.hasNext()){
String str = (String)it.next();
System.out.println(str);
if("#".equals(str)){
c.remove(str);//不得通过集合的方法增删元素否则会抛出异常
}
}
*/
//用迭代器的remove()方法可以删除:问、取、删交替进行
while(it.hasNext()){//问
String str = (String)it.next();//取
System.out.println(str);
if("#".equals(str)){
it.remove();//删
//迭代器的remove方法可以将next方法获取的元素从集合中删除。
}
}
System.out.println(c);
/* 补充:c:[one, #, two, #, three, #, four, #, five]
Iterator it = c.iterator();
//it.remove();//一开始指向是第0个元素,没法删除
it.next();//指向下一个元素(第1个元素)
it.remove();//删除第1个元素
//删掉了第1个元素,第2个元素会自动前移到第1个位置
for(String s : c){
if("#".equals(s)){
it.remove();
//此步骤一开始指向的是第0个元素,但是没有经过问取,就直接删
//没有元素所以没法删除,报出异常
}
}
System.out.println(c);
//Exception in thread "main" java.lang.IllegalStateException
*/
增强型for循环
JDK5之后推出了一个特性:
增强型for循环:也称为新循环,使得我们可以使用相同的语法遍历集合或数组
新循环是java编译器认可的,并非虚拟机。
增强型for循环遍历数组就是普通循环遍历(编译器会在编译时进行替换)
增强型for循环遍历集合就是迭代器遍历(编译器会在编译时进行替换)
语法:
for(元素类型 变量名 : 集合或数组){
循环体
}
String[] array = {"one","two","three","four","five"};//数组
//普通for循环遍历数组
for(int i=0;i<array.length;i++){
String str = array[i];
System.out.println(str);
}
//增强for循环遍历数组:
for(String str : array){
System.out.println(str);
}
Collection c = new ArrayList();//集合
c.add("one");
c.add("two");
c.add("three");
c.add("four");
c.add("five");
//迭代器遍历
Iterator it = c.iterator();
while(it.hasNext()){
String str = (String)it.next();
System.out.println(str);
}
//新循环遍历
for(Object o : c){
String str = (String)o;
System.out.println(str);
}
泛型
JDK5之后推出的另一个特性:泛型
泛型也称为参数化类型,允许我们在使用一个类时指定它当中属性的类型,方法参数或返回值的类型,使得我们使用一个类时可以更灵活。
泛型在集合中被广泛使用,用来指定集合中的元素类型.
支持泛型的类在使用时若不指定泛型的具体类型则默认为原型Object
Collection接口的定义:public interface Collection<E> ...
Collection<E> 这里的<E>就是泛型
Collection中add方法的定义,参数为E: boolean add(E e)
Collection<String> c = new ArrayList<>();
c.add("one");//编译器会检查add方法的实参是否为String类型
c.add("two");
c.add("three");
c.add("four");
c.add("five");
// c.add(123);//编译不通过
//迭代器遍历
//迭代器也支持泛型,指定的与其遍历的集合指定的泛型一致即可
Iterator<String> it = c.iterator();
while(it.hasNext()){
//编译器编译代码时会根据迭代器指定的泛型补充造型代码
String str = it.next();//获取元素时无需在造型
System.out.println(str);
}
//新循环遍历
for(String str : c){
System.out.println(str);
}
List集合
List集合是Collection下面常见的一类集合。
java.util.List接口是所有List的接口,它继承自Collection。
List集合是可重复集,并且有序,提供了一套可以通过下标操作元素的方法
常用实现类:
java.util.ArrayList:内部使用数组实现,查询性能更好.
java.util.LinkedList:内部使用链表(双向链表)实现,首尾增删元素性能更好.
List集合的特点是:
可以存放重复元素,并且有序。其提供了一套可以通过下标操作元素的方法。
性能比较:
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构
对于随机访问get和set,ArrayList优于LinkedList
对于新增和删除操作add和remove,LinedList比较占优势。
补充:
ArrayList数组集合在内存中是一段连续的空间
LinkedList集合的每个元素不是连续的,每个元素都有两个地址(相当于两条线:上线、下线,它连接着前一个元素的下线,后一个元素的上线),所以集合的遍历速率较低,中间的元素只能从第一元素通过其连接的地址找到,但是首尾元素遍历效率很高。
List集合常见方法
get()与set():
E get(int index):获取指定下标对应的元素
E set(int index,E e):将给定元素设置到指定位置,返回值为该位置原有的元素----替换元素操作
List<String> list = new ArrayList<>();//ArrayList实现类
// List<String> list = new LinkedList<>();//LinkedList实现类
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
System.out.println(list);//[one,two,three,four,five]
//获取第三个元素
String e = list.get(2);
System.out.println(e);//three
//获取集合的所有元素
for(int i=0;i<list.size();i++){
e = list.get(i);//相当于数组遍历的:String e =array[i]
System.out.println(e);
}
//替换元素:
String old = list.set(1,"six");//将第2个元素替换为six
System.out.println(list);//[one,six,three,four,five]
System.out.println("被替换的元素是:"+old);//two
//集合反转:
for(int i = 0;i<list.size()/2;i++){
list.set(i,list.set(list.size()-1-i,list.get(i)));
//String e = list.set(list.size()-1-i,list.get(i));
//list.set(i,e);
}
System.out.println(list);//[five,four,three,two,one]重载的add()和remove()
List集合提供了一对重载的add,remove方法
void add(int index,E e):将给定元素插入到指定位置
E remove(int index):删除并返回指定位置上的元素
List<String> list = new ArrayList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
System.out.println(list);//[one, two, three, four, five]
list.add(0,"zero");
System.out.println(list);//[zero, one, two, three, four, five]
list.add(2,"2");
System.out.println(list);//[zero, one, 2, two, three, four, five]
String e = list.remove(2);
System.out.println(list);//[zero, one, two, three, four, five]
System.out.println("被删除的元素:"+e);//2
subList()方法:获取子集
List subList(int start,int end):获取当前集合中指定范围内的子集。两个参数为开始与结束的下标(含头不含尾)
对子集元素的操作就是对原集合对应元素的操作:删除、修改等操作都会改变原集合的元素
List<Integer> list = new ArrayList<>();
//将数字1-10添加到list集合中
for(int i=1;i<11;i++){
list.add(i);
}
System.out.println(list);//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
//获取4-8这部分
List<Integer> subList = list.subList(3,8);
System.out.println(subList);//[4, 5, 6, 7, 8]
//将子集每个元素扩大10倍
for(int i=0;i<subList.size();i++){
subList.set(i,subList.get(i) * 10);
}
System.out.println(subList);//[40,50,60,70,80]
System.out.println(list);//[1, 2, 3, 40, 50, 60, 70, 80, 9, 10]
//删除list集合中的1-3
list.subList(0,3).clear();
System.out.println(list);//[40, 50, 60, 70, 80, 9, 10]
集合与数组的转换
Collection提供了一个方法:toArray,可以将当前集合转换为一个数组
public interface Collection<E> extends Iterable<E> {
Object[] toArray();//无参:作用:为了重载
<T> T[] toArray(T[] a);
...}重载的toArray方法要求传入一个数组,内部会将集合所有元素存入该数组后将其返回(前提是该数组长度>=集合的size)。如果给定的数组长度不足, 则方法内部会自行根据给定数组类型创建一个与集合size一致长度的数组并将集合元素存入后返回。
List<String> list = new ArrayList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
System.out.println(list);//[one, two, three, four, five]
// Object[] array = list.toArray();
//原数组类型为String类型,该无参方法作用就是为了之后的重载
String[] array = list.toArray(new String[list.size()]);
//严丝合缝,正好是集合的长度
System.out.println(array.length);//5
System.out.println(Arrays.toString(array));
//[one, two, three, four, five]
String[] array1 = list.toArray(new String[10]);
//给的数组长度大于集合的长度
System.out.println(Arrays.toString(array1));
//[one, two, three, four, five]
String[] array2 = list.toArray(new String[0]);
//给的数组长度小于集合的长度
System.out.println(Arrays.toString(array2));
//[one, two, three, four, five]
String[] arr = new String[0];
System.out.println(Arrays.toString(arr));//[]数组转换为List集合
数组的工具类Arrays提供了一个静态方法asList(),可以将一个数组转换为一个List集合
asList:只能转成list集合,不能转成set,因为set不能放重复元素,但list可以放重复的
对该List集合的注意事项:
对数组转换的集合进行元素操作就是对原数组对应的操作
由于数组是定长的,因此对该集合进行一切增删元素(改变数组的长度)的操作是不支持的,会抛出异常:java.lang.UnsupportedOperationException
若希望对集合进行增删操作,则需要自行创建一个集合,然后将该集合元素导入。
所有的集合都支持一个参数为Collection的构造方法,作用是在创建当前集合的同时包含给定集合中的所有元素
String[] array = {"one","two","three","four","five"};
System.out.println(Arrays.toString(array));
//array:[one, two, three, four, five]
List<String> list = Arrays.asList(array);
System.out.println(list);
//list:[one, two, three, four, five]
list.set(1,"six");//将list集合下标为1(第2个元素)替换为"six"
System.out.println(list);//list:[one, six, three, four, five]
//数组跟着改变了
System.out.println(Arrays.toString(array));
//array:[one, six, three, four, five]
//不能对转换后的集合增删,否则会抛出异常
//list.add("seven");
//若希望增删,创建新的集合导入
//List<String> list2 = new ArrayList<>();
//list2.addAll(list);
//通过Collection的构造方法导入,新创建的可以增删
List<String> list2 = new ArrayList<>(list);
System.out.println("list2:"+list2);
//list2:[one, six, three, four, five]
list2.add("seven");//新集合增加元素
System.out.println("list2:"+list2);
//list2:[one, six, three, four, five, seven]集合的排序:自然排序
集合的工具类:java.util.Collections类,里面定义了很多静态方法用于操作集合
其中提供了一个静态方法sort,可以对List集合
Collections.sort(List list)方法:可以对List集合进行自然排序(从小到大)
List<Integer> list = new ArrayList<>();
Random random = new Random();
for(int i=0;i<10;i++){
list.add(random.nextInt(100));
}
System.out.println(list);//[75, 13, 44, 32, 70, 68, 26, 9, 99, 52]
Collections.sort(list);//自然排序(默认从小到大)
System.out.println(list);//[9, 13, 26, 32, 44, 52, 68, 70, 75, 99]
Collections.sort(list,(o1,o2)->o2-o1);//从大到小排
System.out.println(list);//[99, 75, 70, 68, 52, 44, 32, 26, 13, 9]
Collections.shuffle(list);//补充:乱序(无规则,可用于洗牌操作)
System.out.println(list);//[70, 68, 75, 52, 26, 99, 13, 9, 32, 44]排序自定义类型元素
Comparable接口
Collections.sort(List list)在排序List集合时要求集合元素必须实现Comparable接口。
该接口中有一个抽象方法compareTo,这个方法用来定义元素之间比较大小的规则
只有实现了该接口的元素才能利用这个方法比较出大小进而实现排序操作
实现了该接口的类必须重写一个方法compareTo,否则编译不通过。
public interface Comparable<T> {
public int compareTo(T o);
}Comparator接口 :比较器接口,用于单独定义比较规则
重载的Collections.sort(List list,Comparator c)方法
@FunctionalInterface//函数式接口可以用lambda公式
public interface Comparator<T> {
int compare(T o1, T o2);//抽象方法,必须重写
* @see Object#equals(Object)
* @see Object#hashCode()
boolean equals(Object obj);
//equals不是Comparator特有的,继承自Object超类,该方法重写了equals方法
default Comparator<T> reversed() {//该方法是一个实现方法:使用关键字default
//JDK1.8新增(打脸之前版本接口中都是抽象方法,没有实现方法)
return Collections.reverseOrder(this);
...
}排序对象:
内部类: //集合的排序:元素是对象类型
List<Point> list = new ArrayList<>();
list.add(new Point(1,2));
list.add(new Point(15,8));
list.add(new Point(9,7));
list.add(new Point(5,3));
System.out.println(list);
//[Point{x=1, y=2}, Point{x=15, y=8}, Point{x=9, y=7}, Point{x=5, y=3}]
//Collections.sort(list);//编译不通过 compare比较 comparable可以比较的
//System.out.println(list);
//第二种:通过Comparator接口的匿名内部类创建一个比较器(适用于只实现一次,只创建一个对象)
Comparator<Point> c = new Comparator<Point>() {
@Override
public int compare(Point o1, Point o2) {
int len1 = o1.getX()*o1.getX()+o1.getY()*o1.getY();
int len2 = o2.getX()*o2.getX()+o2.getY()*o2.getY();
return len1-len2;
}
};
Collections.sort(list,c);//回调模式
System.out.println(list);
//[Point{x=1, y=2}, Point{x=5, y=3}, Point{x=9, y=7}, Point{x=15, y=8}]
/* 实现比较器接口后必须重写方法compare.
* 该方法用来定义参数o1与参数o2的比较大小规则
* 返回值用来表示o1与o2的大小关系*/
//最终没有入侵性的写法:
Collections.sort(list, new Comparator<Point>() {
@Override
public int compare(Point o1, Point o2) {
int len1 = o1.getX()*o1.getX()+o1.getY()*o1.getY();
int len2 = o2.getX()*o2.getX()+o2.getY()*o2.getY();
return len1-len2;
}
});
//使用lambda公式:List<Point> list = new ArrayList<>();
//list中定义了一个泛型Point,所以编译可以识别出o1、o2也是Point
Collections.sort(list, (o1,o2)->
o1.getX()*o1.getX()+o1.getY()*o1.getY()-
o2.getX()*o2.getX()-o2.getY()*o2.getY()
);
}
}
外部类:
//有侵入性:
/*第一种:外部创建一个类:实现Comparator接口(实际开发中基本不会用,为了辅助理解)
class MyComparator implements Comparator<Point>{
public int compare(Point o1,Point o2){
int len1 = o1.getX()*o1.getX()+o1.getY()*o1.getY();
int len2 = o2.getX()*o2.getX()+o2.getY()*o2.getY();
return len1-len2;
*/实际开发中,我们并不会让我们自己定义的类(如果该类作为集合元素使用)去实现Comparable接口,因为这对我们的程序有侵入性.
侵入性:当我们调用某个API功能时,其要求我们为其修改其他额外的代码,这个现象就是侵入性。侵入性越强的API越不利于程序的后期可维护性,应当尽量避免.
排序字符串
默认排序规则:按照Unicode的编码顺序 (从小到大),首字符相同,比较第2个字符,类推。
java中提供的类,如:String,包装类都实现了Comparable接口,但有时候这些比较规则不能满足我们的排序需求时,同样可以临时提供一种比较规则来进行排序.
//英文字符串:'A'=48;'a'=97
List<String> list = new ArrayList<>();
list.add("Tom");
list.add("jackson");
list.add("rose");
list.add("jill");
list.add("ada");
list.add("hanmeimei");
list.add("lilei");
list.add("hongtaoliu");
list.add("Jerry");
System.out.println(list);
//[Tom, jackson, rose, jill, ada, hanmeimei, lilei, hongtaoliu, Jerry]
Collections.sort(list);
System.out.println(list);
//[Jerry, Tom, ada, hanmeimei, hongtaoliu, jackson, jill, lilei, rose]
//中文字符串:用Unicode排序规则不满足实际需求
//自定义排序规则:按照字符多少排序
list.add("苍老师");
list.add("传奇");
list.add("小泽老师");
list.add("小");
System.out.println(list);
//[苍老师, 传奇, 小泽老师, 小]
Collections.sort(list, (o1, o2) -> o1.length() - o2.length());//从小到大
System.out.println(list);
//[小, 传奇, 苍老师, 小泽老师]
Collections.sort(list, (o1, o2) -> o2.length() - o1.length());//反过来就是:从大到小
System.out.println(list);
//[小泽老师, 苍老师, 传奇, 小]
/*(o1, o2) -> o1.length() - o2.length()可这样理解:
第1参数o1,第2参数o2,当返回值:小于0--->从小到大:自然排序
大于0--->从大到小(即反过来的效果)*/
集合框架:Map接口
java.util.Map接口
Map称为查找表,体现的结构是一个多行两列的表格。其中左列称为key,右列称为value.
Map总是根据key获取对应的value,key和value可以分别指定不同类型。
常用实现类:
java.util.HashMap:称为散列表,哈希表。是使用散列算法实现的Map,当今查询速度最快的
数据结构
java.util.TreeMap:使用二叉树算法实现的Map
方法
V put(K k,V v):将一组键值对存入Map中,Map要求key不允许重复。
如果put方法存入的键值对中,key不存在时,则直接将key-value存入,返回值为null
如果key存在,则是替换value操作,此时返回值为被替换的value
V get(Object k):根据给定的key获取对应的value,如果给定的key不存在,则返回值为null
int size():获取集合的长度(键值对个数),一对键值对作为一个元素
boolean isEmpty():判断集合是否为空
boolean containsKey(Object key):判断Map是否包含给定的key
boolean containsValue(Object value):判断Map是否包含给定的value
V remove(Object key):从map中删除给定的key对应的这一组键值对。返回值为该key对应的value
Map<String,Integer> map = new HashMap<>();
//put()方法:
Integer value = map.put("语文",99);
System.out.println(value);//没有被替换的value:返回null
map.put("数学",98);
map.put("英语",97);
map.put("物理",96);
map.put("化学",99);
System.out.println(map);//{物理=96, 数学=98, 化学=99, 语文=99, 英语=97}
value = map.put("物理",60);
System.out.println(map);//{物理=60, 数学=98, 化学=99, 语文=99, 英语=97}
System.out.println(value);//96
//get()方法:
value = map.get("化学");
System.out.println(value);//99
value = map.get("体育");
System.out.println(value);//null
//size():
int size = map.size();
System.out.println("size:"+size);//size:5
//containsKey()和containsValue()
boolean ck = map.containsKey("语文");
System.out.println("包含key:"+ck);//包含key:true
ck = map.containsKey("音乐");
System.out.println("包含key:"+ck);//包含key:false
boolean cv = map.containsValue(99);
System.out.println("包含value:"+cv);//包含value:true
cv = map.containsValue(66);
System.out.println("包含value:"+cv);//包含value:false
//remove():
System.out.println(map);//{物理=60, 数学=98, 化学=99, 语文=99, 英语=97}
value = map.remove("语文");
System.out.println(map);//{物理=60, 数学=98, 化学=99, 英语=97}
System.out.println(value);//99
value = map.remove("美术");
System.out.println(map);//{物理=60, 数学=98, 化学=99, 英语=97}
System.out.println(value);//map集合key中没有"美术",返回:null
Map的遍历
- Map提供了三种遍历方式:
- 1:遍历所有的key
- 2:遍历每一组键值对
- 3:遍历所有的value(该操作不常用)
Set keySet():
将当前Map中所有的key以一个Set集合形式返回,遍历该集合等同于遍历所有的key 。
Set entrySet():
将当前Map中每一组键值对以一个Entry实例形式表示,并存入Set集合后返回
java.util.Map.Entry的每一个实例用于表示Map中的一组键值对,
其中方法:
K getKey():获取对应的key
V getValue():获取对应的value
Collection values():将当前Map中所有的value以一个集合形式返回
Map<String,Integer> map = new HashMap<>();
map.put("语文",99);
map.put("数学",98);
map.put("英语",97);
map.put("物理",96);
map.put("化学",99);
System.out.println(map);//{物理=96, 数学=98, 化学=99, 语文=99, 英语=97}
//遍历方法1:遍历所有的key
Set<String> keySet = map.keySet();//将map集合中所有key存储到一个set集合中
//set集合存储不重复元素,而key也是唯一性
System.out.println(keySet);//[物理, 数学, 化学, 语文, 英语]
for(String key : keySet){
System.out.println("key:"+key);
}
/*输出:
key:物理
key:数学
key:化学
key:语文
key:英语 */
//遍历方法2:遍历每一组键值对
Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
System.out.println(entrySet);//[物理=96, 数学=98, 化学=99, 语文=99, 英语=97]
for(Map.Entry<String,Integer> e : entrySet){
String key = e.getKey();//获取每一个key
Integer value = e.getValue();//获取每一个value
System.out.println(key+":"+value);
}
/*输出:
物理:96
数学:98
化学:99
语文:99
英语:97 */
//遍历方法3:遍历所有的value(不常用)
Collection<Integer> values = map.values();
System.out.println(values);//[96, 98, 99, 99, 97]
for(Integer value : values){
System.out.println("value:"+value);
}
/*输出:
value:96
value:98
value:99
value:99
value:97 */
Map和Collection:lambda表达式遍历
JDK8之后,Collection和Map都提供了支持使用lambda表达式遍历的操作
//Collection集合
Collection<String> c = new ArrayList<>();
c.add("one");
c.add("two");
c.add("three");
c.add("four");
c.add("five");
System.out.println(c);//[one, two, three, four, five]
//for新循环遍历:
for(String s : c){
System.out.println(s);
}
//lambda表达式遍历:
c.forEach(s->System.out.println(s));//只有一句话的输出可以简写成此种格式
//c.forEach(System.out::println);//当后面输出的也是s时,可以用此种写法
//Map集合
Map<String,Integer> map = new HashMap<>();
map.put("语文",99);
map.put("数学",98);
map.put("英语",97);
map.put("物理",96);
map.put("化学",99);
System.out.println(map);//{物理=96, 数学=98, 化学=99, 语文=99, 英语=97}
//lambda表达式遍历:
map.forEach((k,v)-> System.out.println(k+":"+v));//最终简写补充:Map的lambda表达式遍历的完整代码
//补充:Map的lambda表达式遍历的完整代码:
//最终简写
map.forEach((k,v)-> System.out.println(k+":"+v));
//完整代码
map.forEach()源代码:
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
public interface BiConsumer<T, U> {
void accept(T t, U u);
...}
public static <T> T requireNonNull(T obj) {
if (obj == null)
throw new NullPointerException();
return obj;
}
//步骤1:实现Bicosumer接口:通过匿名内部类并重写accept(),内部类的对象引用名:action
BiConsumer<String,Integer> action = new BiConsumer<String, Integer>() {
public void accept(String k, Integer v) {
System.out.println(k+":"+v);
}
};
//遍历每一组键值对
Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
for(Map.Entry<String,Integer> e : entrySet) { //41行
String k = e.getKey();
Integer v = e.getValue();
action.accept(k,v);//每一次遍历实现BiConsumer接口,将key和value传入 //46行
}
//步骤2:2Map的forEache方法的回调写法
BiConsumer<String,Integer> action = new BiConsumer<String, Integer>() {
public void accept(String k, Integer v) {
System.out.println(k+":"+v);
}
};
map.forEach(action);//这个等效上面41-46行(可参考forEach源代码)---回调模式
//步骤3:使用lambda表达式形式创建
BiConsumer<String,Integer> action =(k,v)->System.out.println(k+":"+v);
map.forEach(action);
//步骤4:最终写法
map.forEach((k,v)->System.out.println(k+":"+v));