1、配置ES集群
a、克隆单机安装es的centos
b、启动克隆的centos修改ip

修改ip
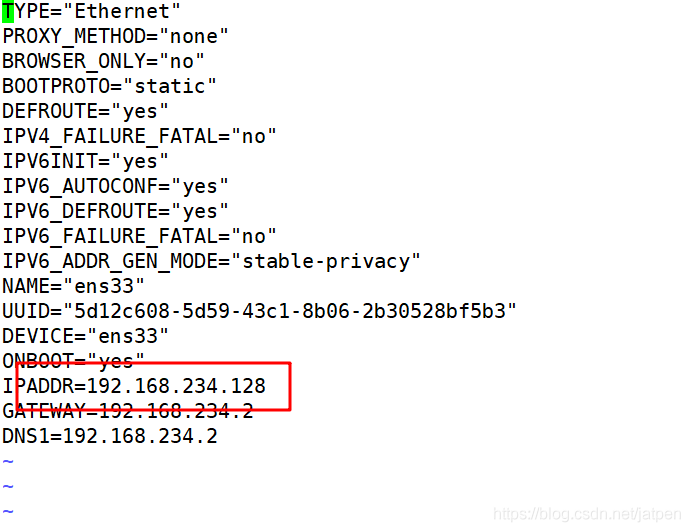
现在准备了两台机器ip分别为192.168.234.128和192.168.234.130
b、进入es安装目录vim elasticsearch.yml
cluster.name: aubin-cluster #必须相同
# 集群名称(不能重复)
node.name: els1(必须不同)
# 节点名称,仅仅是描述名称,用于在日志中区分(自定义)
#指定了该节点可能成为 master 节点,还可以是数据节点
node.master: true
node.data: true
path.data: /opt/data
# 数据的默认存放路径(自定义)
path.logs: /opt/logs
# 日志的默认存放路径
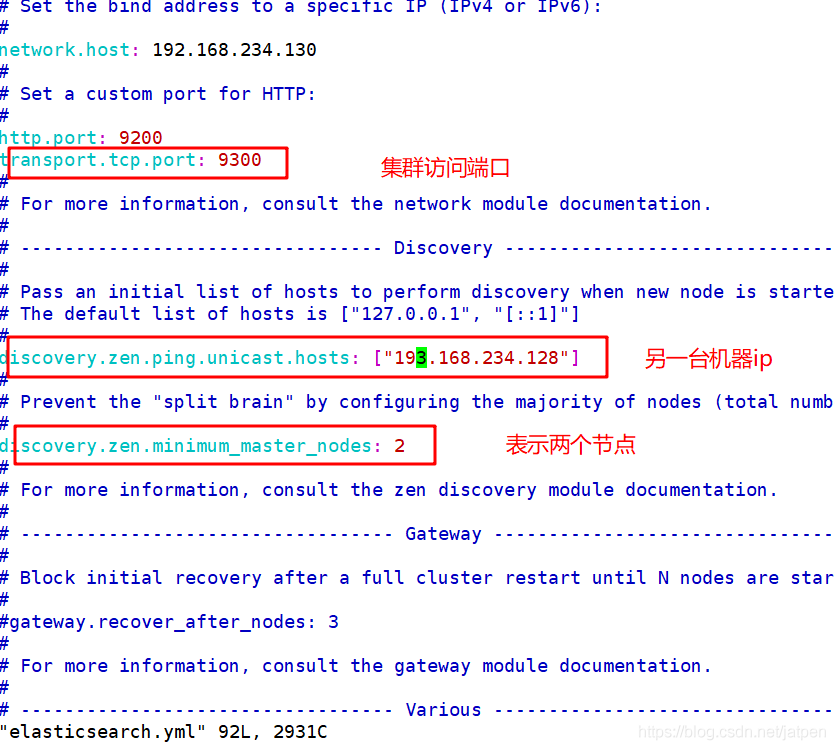
network.host: 192.168.0.1
# 当前节点的IP地址
http.port: 9200
# 对外提供服务的端口
transport.tcp.port: 9300
#9300为集群服务的端口
discovery.zen.ping.unicast.hosts: ["172.18.68.11", "172.18.68.12","172.18.68.13"]
# 集群个节点IP地址,也可以使用域名,需要各节点能够解析
discovery.zen.minimum_master_nodes: 2
# 为了避免脑裂,集群节点数最少为 半数+1
启动测试:
cerebro-0.8.3进行es集群监控
将地址粘进去
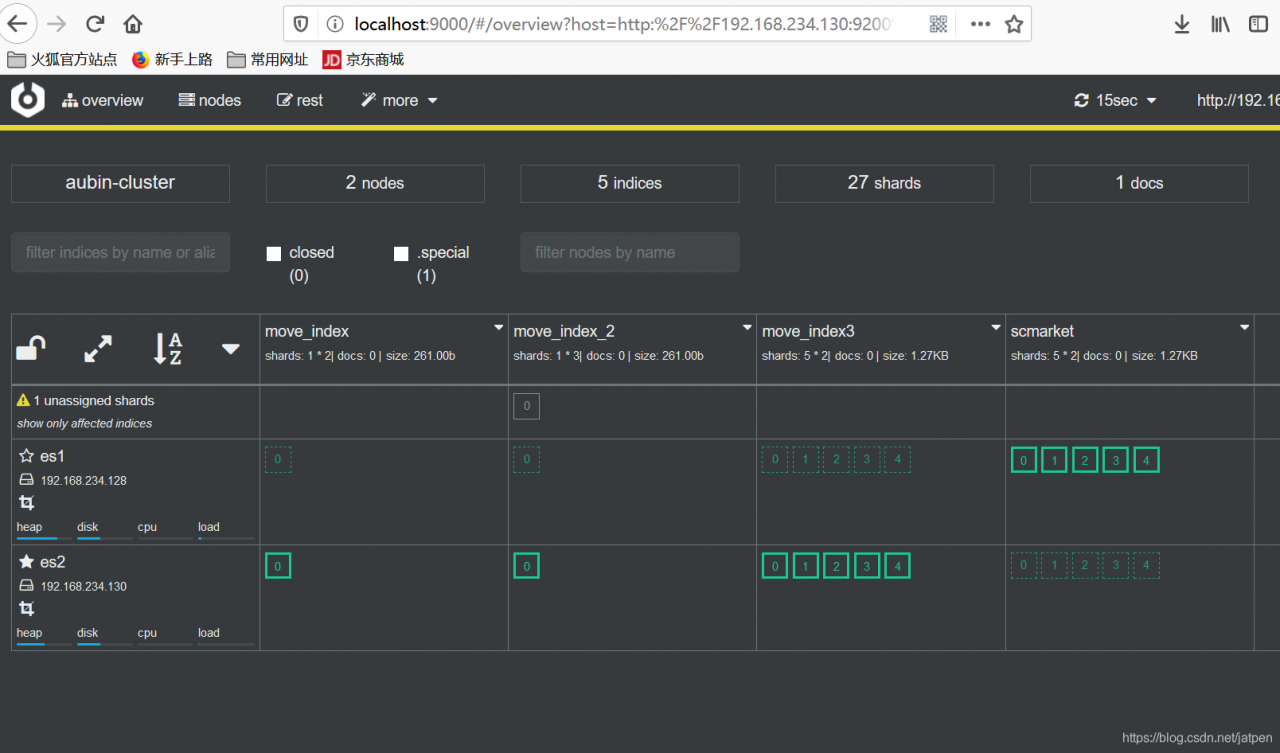
2、集群简介
一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,它们具有相同的cluster.name,它们协同工作,分享数据和负载。
当加入新的节点或者删除一个节点时,集群就会感知到并平衡数据(同步)。
3、集群节点
- 集群中一个节点会被选举为主节点(master)
- 主节点临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。
- 主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。
- 任何节点都可以成为主节点。
- 用户,我们能够与集群中的任何节点通信,包括主节点。
- 每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上。
- 我们访问的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch处理。
4、集群健康
在Elasticsearch集群中可以监控统计很多信息,但是只有一个是最重要的:集群健康(cluster health)。集群健康有三种状态:green、yellow或red。在一个没有索引的空集群中运行如上查询,将返回这些信息:
颜色 | 意义 |
green | 所有主要分片和复制分片都可用 |
yellow | 所有主要分片可用,但不是所有复制分片都可用 |
red | 不是所有的主要分片都可用 |
5、集群分片
索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.
分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分,是一个Lucene实例,并且它本身就是一个完整的搜索引擎。我们的文档存储在分片中,并且在分片中被索引,但是我们的应用程序不会直接与它们通信,取而代之的是,直接与索引通信。
分片是Elasticsearch在集群中分发数据的关键。把分片想象成数据的容器。文档存储在分片中,然后分片分配到你集群中的节点上。当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片,以使集群保持平衡。
- 主分片
索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据。
理论上主分片能存储的数据大小是没有限制的,限制取决于你实际的使用情况。分片的最大容量完全取决于你的使用状况:硬件存储的大小、文档的大小和复杂度、如何索引和查询你的文档,以及你期望的响应时间。
- 副分片
复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档。
6、操作数据节点工作流程
每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
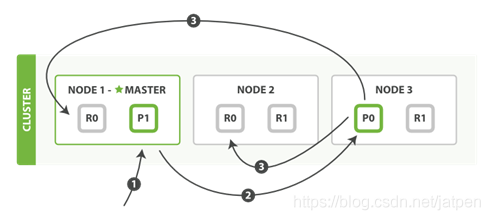
- 客户端给Node 1发送新建、索引或删除请求。
- 节点使用文档的_id确定文档属于分片0。它转发请求到Node 3,分片0位于这个节点上。
- Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于Node 1和Node 2的复制节点上。当所有的复制节点报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。