RecBole小白入门系列博客(三)
——Context类模型运行流程
注意:本系列基于RecBole v.0.2.0 版本!
传送门:
RecBole小白入门系列博客(一)——快速安装和简单上手
RecBole小白入门系列博客(二)——General类模型运行流程
写在前面
- 这次的内容和上次General类模型运行流程差不多,我会特别提一下Context类模型不一样和需要注意的地方。
- 由于模型的完整运行流程会牵扯到很多部分,从数据到参数,所以这里将简略的举出例子,让大家可以大致独立完成模型的运行。关于一些更加具体和细微的部分,我将在后面单独写博客为大家介绍。
选定模型
RecBole中共有15个Context类模型可供使用,模型列表如下:
关于模型的具体信息可以查看上面的链接,大家选用需要的模型即可。我们以模型FM为例。
设置模型超参数
每个模型的超参数都不一致,大家可以从上面的链接中查看自己所需模型的超参数有哪些。在RecBole中每个模型都有默认的参数,因此如果是想简单跑一跑就暂时不动。
模型默认参数在源码目录RecBole/recbole/properties/model 中,各位感兴趣在小伙伴可以在里面查看默认参数值。
那么想调参的同学怎么办呢?读过RecBole小白入门系列博客(一)——快速安装和简单上手的朋友可能知道,在RecBole中调整参数有好几种方法,这里我推荐使用自定义配置文件。
RecBole的配置文件格式均使用.yaml文件,十分简洁明了,大致的形式如下:
accum: "stack"
gcn_output_dim: 500
embedding_size: 64
dropout_prob: 0.3
sparse_feature: True
class_num: 2
num_basis_functions: 2
参数名称: 参数值这样的样式
参数值可以是字典嵌套,也可以是列表等,就像这样
load_col:
inter: [user_id, business_id, stars]
item: [business_id, address, categories]
user: [user_id, fans, compliment_hot, compliment_cool, complitment_cute, compliment_plain]
大家暂时不用管参数的含义等,后面会注意讲到。大致了解配置文件的格式之后,我再说下推荐的修改模型参数的方法:
- 在目录
RecBole/下新建配置文件test.yaml - 在
test.yaml中写入想要修改的参数 - 保存
例如,我想修改模型LR的参数,就去查看路径RecBole/recbole/properties/model/LR.yaml,可以发现LR参数很少,就只有一个:
embedding_size: 10
那如果我想把embedding_size改成32的话,就在test.yaml中写入
# model config
embedding_size: 32
别的模型参数同理
选定数据集
数据集基本格式
选定模型之后就是要选定要用的数据集了。RecBole框架使用的数据集要求处理成对应的原子文件才可以正常使用,目前支持6种原子文件,Context模型顾名思义会用到各种上下文,因此会用到的文件可能有多个 .inter、.item和**.user**
| 后缀 | 含义 | 例子 |
|---|---|---|
| .inter | 用户-商品交互特征 | user_id, item_id, rating, timestamp, review |
| .user | 用户特征 | user_id, age, gender |
| .item | 商品特征 | item_id, category |
每个原子文件可以被看作 m 行 n 列的表格(不计表头),代表该文件存储了 n 种不同的特征,共 m 条记录。 文件第一行为表头,表头中每一列的形式为 feat_name:feat_type,标示了该列特征的名字及类型。 约定特征为四种类型之一。
| feat_type | 含义 | 例子 |
|---|---|---|
| token | 单个离散特征 | user_id, age |
| token_seq | 离散特征序列 | review |
| float | 单个连续特征 | rating, timestamp |
| float_seq | 连续特征序列 | vector |
关于数据集原子文件的处理和格式等,我接下来会专门用一篇博客来讲,这里给出一个简明的例子即可,想马上了解的同学可以看他们的网站https://recbole.io/cn/atomic_files.html
以及RecBole提供的已经按格式处理好的数据集
https://github.com/RUCAIBox/RecDatasets
以 ml-1m 为例 :
处理过后可以得到 ml-1m.inter 文件,模式如下: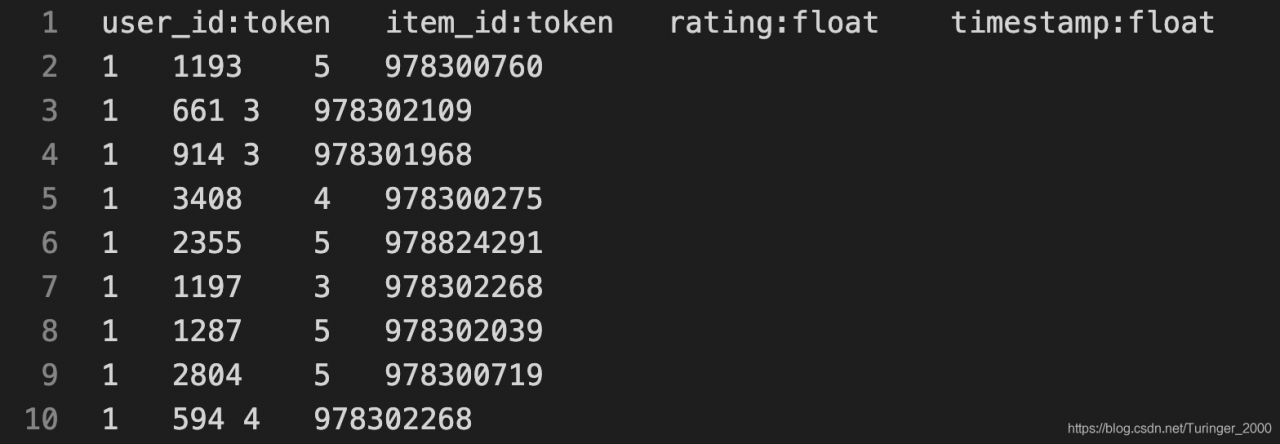
还要注意Context模型用的数据集可以没有用户id和物品id,但最好特征多一些,才能得到更好的结果。
设置数据集参数
针对特定数据集,需要设置相应的参数,才可以让模型正常运行。这里仍然以 ml-1m 数据集为例,给出相应的配置文件。在上文 test.yaml 继续写入数据集参数,我会在下面注释中给出各个参数的含义,这些都是必须设置的参数。
# dataset config
field_separator: "\t" #指定数据集field的分隔符
seq_separator: " " #指定数据集中token_seq或者float_seq域里的分隔符
USER_ID_FIELD: user_id #指定用户id域
ITEM_ID_FIELD: item_id #指定物品id域
RATING_FIELD: rating #指定打分rating域
TIME_FIELD: timestamp #指定时间域
NEG_PREFIX: neg_ #指定负采样前缀
LABEL_FIELD: label #指定标签域
#因为数据集没有标签,所以设置一个阈值,认为rating高于该值的是正例,反之是负例
threshold:
rating: 4
#指定从什么文件里读什么列,这里就是从ml-1m.inter里面读取user_id, item_id, rating, timestamp这四列,剩下的以此类推
load_col:
inter: [user_id, item_id, rating]
user: [user_id, age, gender, occupation]
item: [item_id, genre]
设置训练参数
设置好数据及之后,我们要继续设置训练的参数,在test.yaml中继续写入:
# training settings
epochs: 500 #训练的最大轮数
train_batch_size: 4096 #训练的batch_size
learner: adam #使用的pytorch内置优化器
learning_rate: 0.001 #学习率
training_neg_sample_num: 0 #负采样数目
eval_step: 1 #每次训练后做evalaution的次数
stopping_step: 10 #控制训练收敛的步骤数,在该步骤数内若选取的评测标准没有什么变化,就可以提前停止了
大家一定注意,因为Context类模型不用负采样,因此training_neg_sample_num一定是0
设置评测参数
运行前最后一步,需要设置评测参数。在test.yaml中继续写入:
# evalution settings
eval_setting: RO_RS #对数据随机重排,设置按比例划分数据集
group_by_user: False #是否将一个user的记录划到一个组里
split_ratio: [0.8,0.1,0.1] #切分比例
metrics: ['AUC', 'LogLoss'] #评测标准
valid_metric: AUC #选取哪个评测标准作为作为提前停止训练的标准
eval_batch_size: 4096 #评测的batch_size
注意,区别于General类模型,Context模型没有全排序,所以在eval_setting设置里是没有full的
总结参数设置
至此我们的参数设置就全都好了,完整的 test.yaml 应该是这个样子的:
# model config
embedding_size: 32
# dataset config
field_separator: "\t" #指定数据集field的分隔符
seq_separator: " " #指定数据集中token_seq或者float_seq域里的分隔符
USER_ID_FIELD: user_id #指定用户id域
ITEM_ID_FIELD: item_id #指定物品id域
RATING_FIELD: rating #指定打分rating域
TIME_FIELD: timestamp #指定时间域
NEG_PREFIX: neg_ #指定负采样前缀
LABEL_FIELD: label #指定标签域
#因为数据集没有标签,所以设置一个阈值,认为rating高于该值的是正例,反之是负例
threshold:
rating: 4
#指定从什么文件里读什么列,这里就是从ml-1m.inter里面读取user_id, item_id, rating, timestamp这四列,剩下的以此类推
load_col:
inter: [user_id, item_id, rating]
user: [user_id, age, gender, occupation]
item: [item_id, genre]
# training settings
epochs: 500 #训练的最大轮数
train_batch_size: 4096 #训练的batch_size
learner: adam #使用的pytorch内置优化器
learning_rate: 0.001 #学习率
training_neg_sample_num: 0 #负采样数目
eval_step: 1 #每次训练后做evalaution的次数
stopping_step: 10 #控制训练收敛的步骤数,在该步骤数内若选取的评测标准没有什么变化,就可以提前停止了
# evalution settings
eval_setting: RO_RS #对数据随机重排,设置按比例划分数据集
group_by_user: False #是否将一个user的记录划到一个组里
split_ratio: [0.8,0.1,0.1] #切分比例
metrics: ['AUC', 'LogLoss'] #评测标准
valid_metric: AUC #选取哪个评测标准作为作为提前停止训练的标准
eval_batch_size: 4096 #评测的batch_size
运行
将 ml-1m 数据集文件夹放在目录RecBole/dataset 下,至此几个关键文件的层次应该是:
-RecBole
-dataset
-ml-1m
ml-1m.inter
ml-1m.item
ml-1m.user
test.yaml
run_recbole.py
接下来按照我上期RecBole小白入门系列博客(一)——快速安装和简单上手讲的运行方法运行就好啦!
假设运行LR模型(别的模型同理,改一下model就好)
python run_recbole.py --model=LR --dataset=ml-1m \
--config_files=test.yaml
然后就有下面这样的信息输出了:
这里是打印出的训练参数信息,可以看到有很多我们没设置的默认信息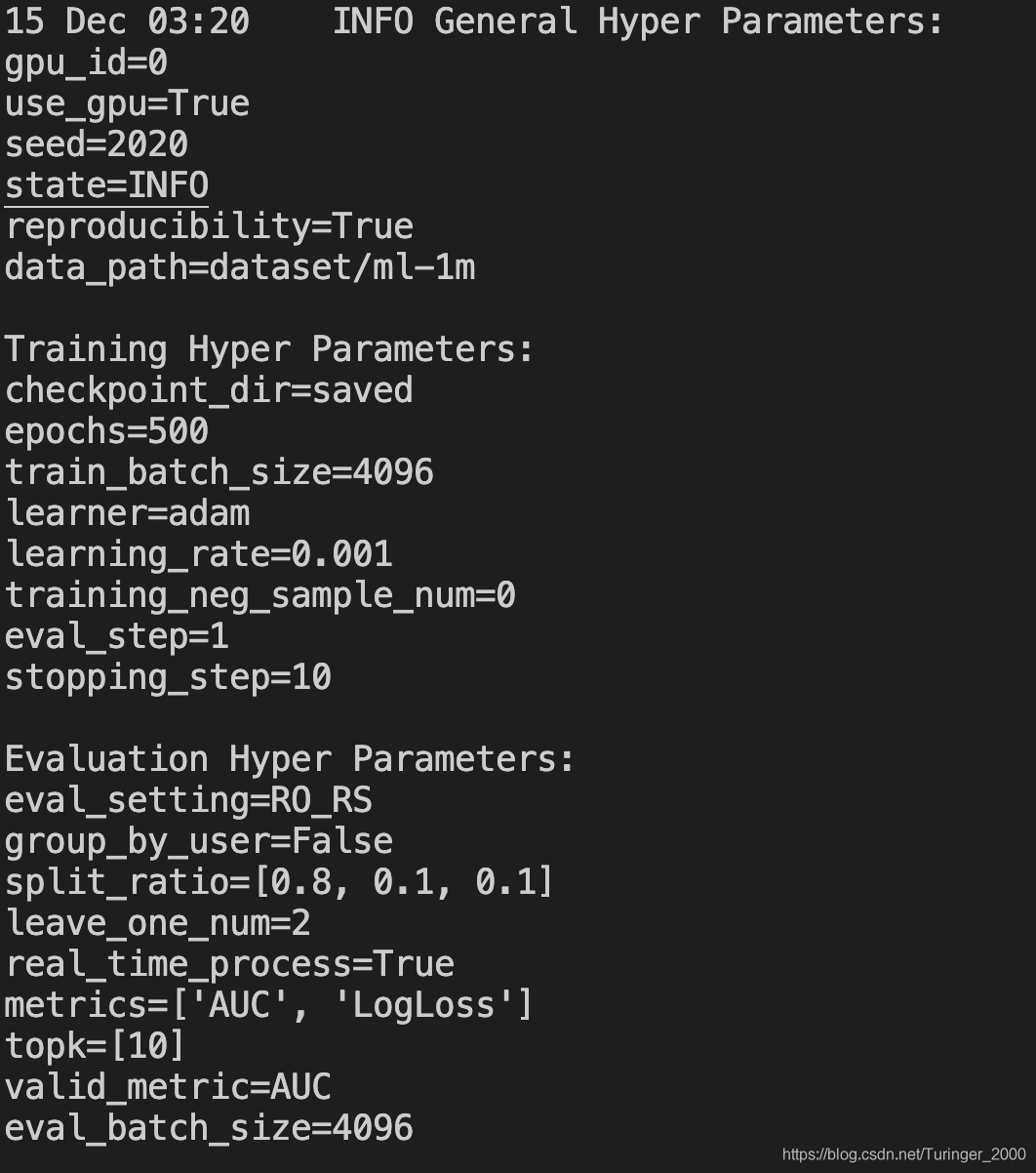
接下来是数据集的参数信息: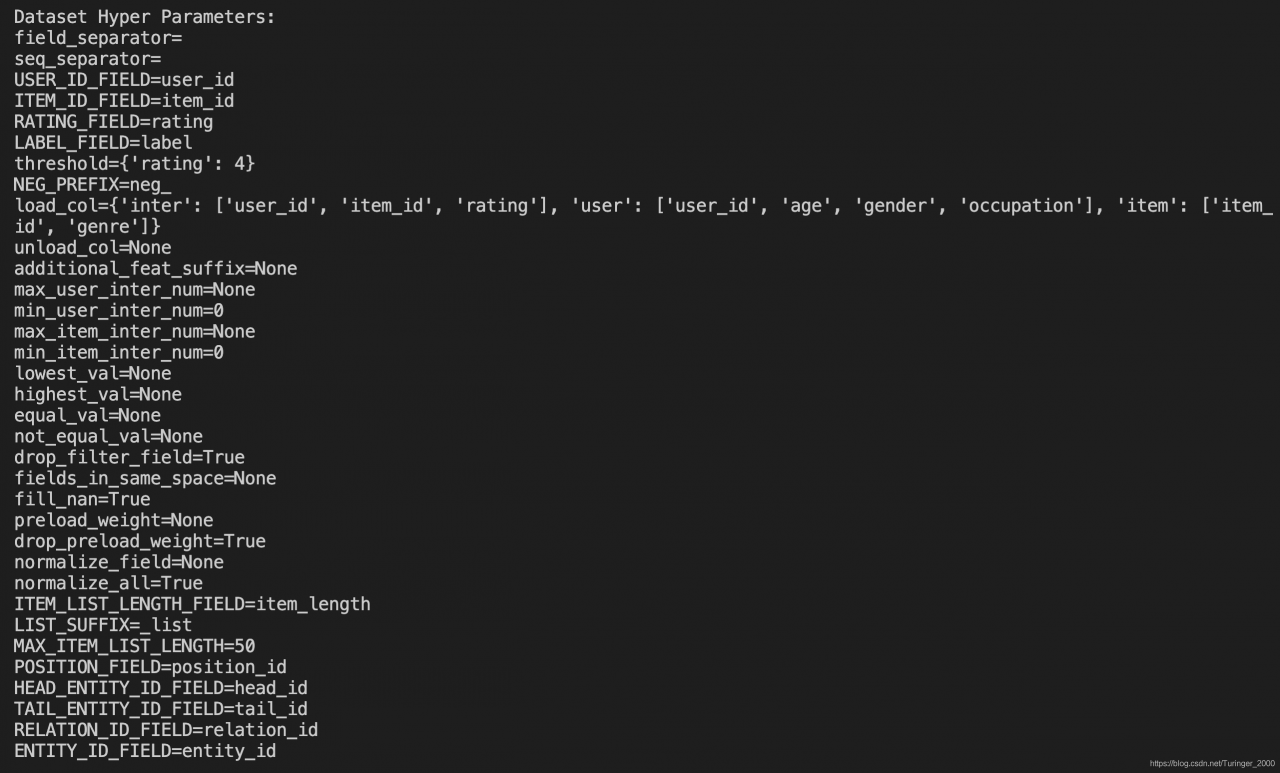
之后给出数据集的基本信息:
再然后是evaluation的设置: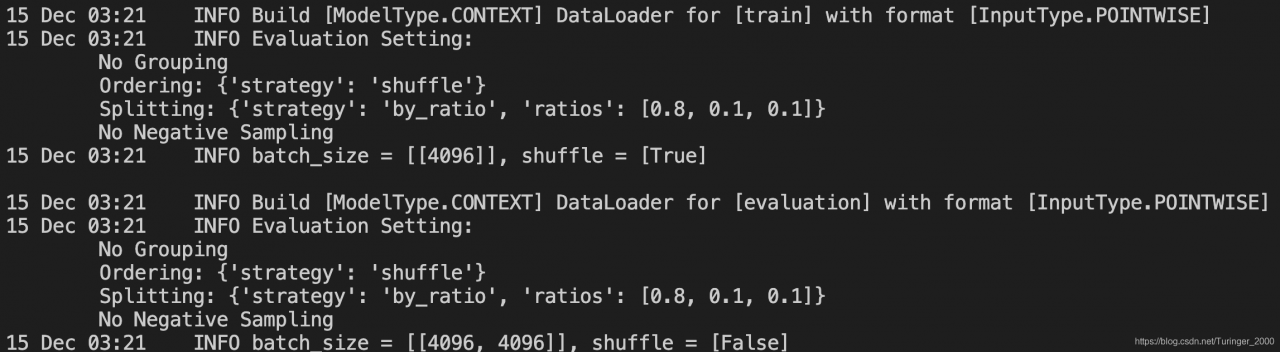
下面是模型结构: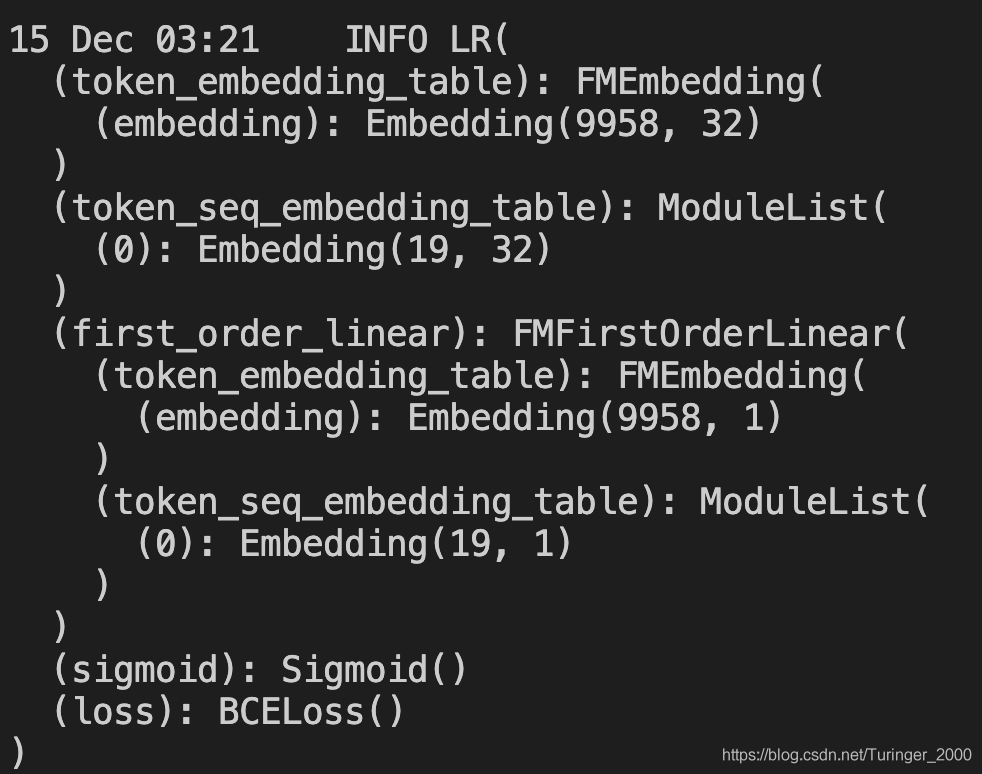
**接下来就开始训练啦,会打印出每一轮的结果: **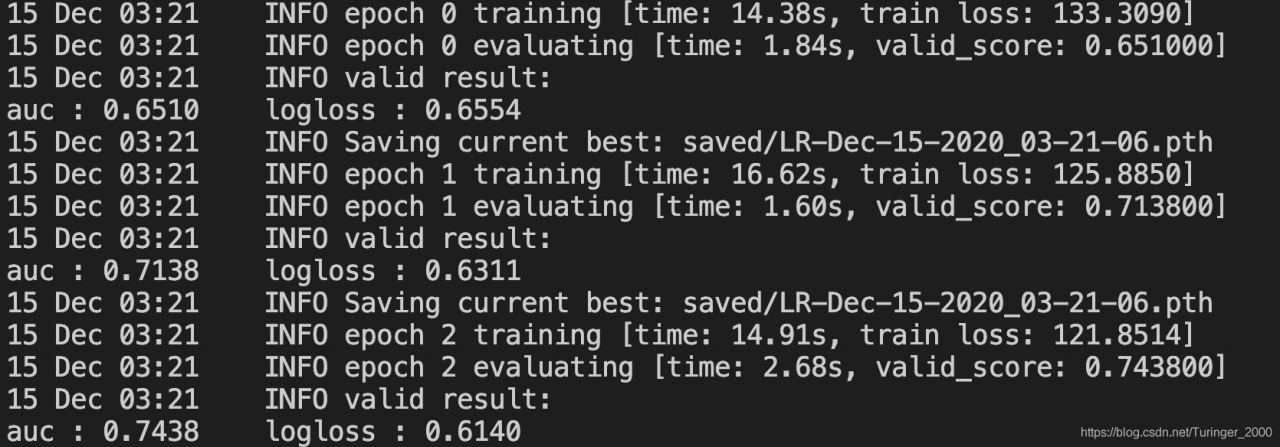
一直到训练结束,会给出最终的测试结果:
调(lian)参(dan)
参照上一期里的调参即可
RecBole小白入门系列博客(二) ——General类模型运行流程
结束语
Context类模型运行流程就写到这里,之后我还会继续更新剩下的两种模型运行流程,以及之前提到的各种参数设置,数据集处理,数据集配置等。大家还有什么想看的可以留言( ̄▽ ̄)~,有什么问题也欢迎和我讨论!
最后附上官网、API文档和GitHub链接~大家有兴趣可以自行查阅哦!
官网:https://recbole.io/cn/index.html
API文档:https://recbole.io/docs/
GitHub:https://github.com/RUCAIBox/RecBole