文章目录
集合框架
集合:集合是java中的一种容器,可用于存储多个数据。
集合与数组的区别
- 数组长度是固定的。集合长度是可变的。
- 数组存储的是同一类型的元素,可存储基本数据类型值。而集合存储的是对象,且对象类型可以不一致,也可以一致,在开发过程中,当对象多时使用集合进行存储。
Collection集合框架 常用关系结构图
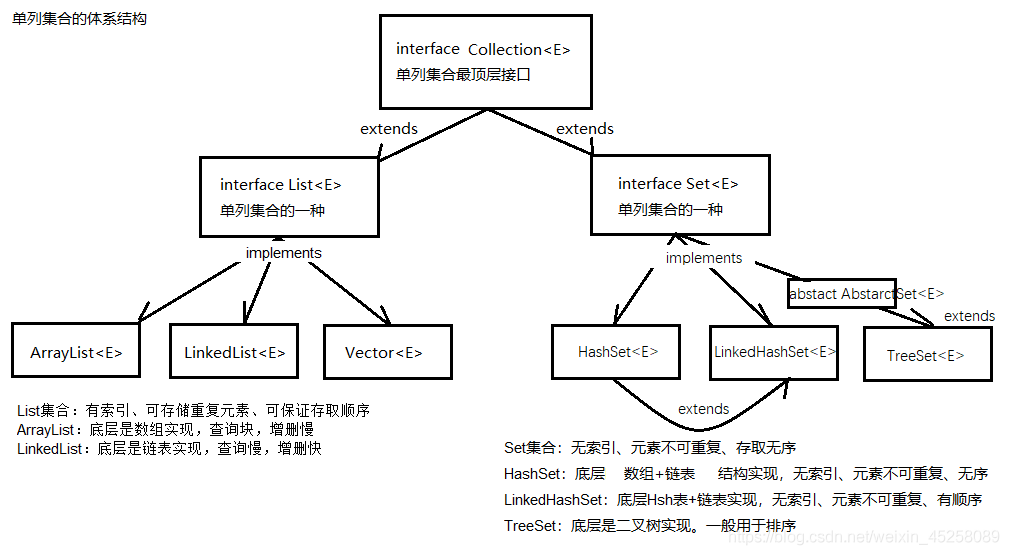
Collection是最顶层的接口,List集合和Set集合都是继承Collection接口的接口
1、Collection<E> 接口集合 JDK 1.2
Collection是最顶层的接口。
常用方法
public abstract boolean add(E e):向数组集合中添加元素public abstract boolean remove(E e):删除索引值为index的元素public abstract int size():获取数组集合的长度大小,返回元素个数public abstract boolean contains(Object o):判断是否包含指定元素public abstract void clear():清空所有元素public abstract Object[] toArray():将集合转为一个数组
public class TestCollection{
public static void main(String[] args){
// 注意:从JDK 1.7 开始,右侧的尖括号内可以不写泛型,但本身是要写的。
Collection<String> coll = new ArrayList<>(); // 由于接口不可实例化,所以使用多态进行实例
coll.add("A");
coll.add("B");
coll.add("C");
System.out.println(coll); // 输出 [A,B,C]
coll.remove("B");
System.out.println(coll); // 输出 [A,C]
}
}
2、List<E> 接口集合 JDK 1.2
java.util.List接口 注意越界,越界异常:IndexOutOfBundsException
List集合特点:
- 有序的集合,存储元素和取出元素的顺序一致
- 有索引,包含了一些带索引的方法
- 允许存储重复的元素
常用方法 (特有)
public abstract void add(int index, E element):将指定的元素,添加到集合中的指定位置中public abstract E get(int index):返回集合中指定位置的元素public abstract E remove(int index):移除列表中指定位置的元素,返回的是被移除的元素public abstract E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素
public class TestArrayList{
public static void main(String[] args){
List<String> list = new List<>();
list.add("a");
list.add("b");
list.add("a");
System.out.println(list); // [a,b,a]
String reElement = list.remove(1);
System.out.println(reElement); // b
System.out.println(list); // [a,a]
String seElement = list.set(1, "c");
System.out.println(seElement); // a
System.out.println(list); // [a,c]
// 遍历list的3种方法
for(String s: list){
System.out.println(s);
}
for(int i = 0; i < list.size(); i++){
System.out.println(list.get(i));
}
Iterator<String> iterator = list.iterator();
if(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
3、ArrayList<E>集合 JDK 1.2
数组的长度不可变化,但是ArrayList集合的长度是可以随意变化的。E为泛型,泛型只能是引用类型。可调整大小的数组的实现的List接口。
如果查询比较多的话,就使用ArrayList集合。因为增删改的操作时,每次都要调用底层的源代码,进行数组的大小调整,效率较慢。
数组结构就是查询快,增删慢。
常用方法
public boolean add(E e):向数组集合中添加元素public E get(int index):得到索引值为index的元素public E remove(int index):删除索引值为index的元素,并返回被删除的元素public int size():获取数组集合的长度大小,返回元素个数public boolean contains(Object o):判断是否包含指定元素public int indexOf(Object o):返回该元素的索引值public int lastIndexOf(Object o):返回该元素最后一次出现的索引值
public class TestArrayList{
public static void main(String[] args){
// 注意:从JDK 1.7 开始,右侧的尖括号内可以不写泛型,但本身是要写的。
ArrayList<String> list = new ArrayList<>();
System.out.println(list); // 输出 []
list.add("A");
list.add("B");
list.add("C");
System.out.println(list); // 输出 [A,B,C]
}
}
4、LinkedList<E>集合 JDK 1.2
java.util.LinkedList 类
LinkedList集合的特点:
- List接口有的特点(有序集合、有索引、可重复元素)
- 底层是一个链表结构:查询慢,增删块
- 该集合包含了大量的首位元素的方法
常用方法
public void addFirst(E e):将指定元素插入到开头位置public void addLast(E e):将指定元素插入到结尾位置public void push(E e):同addFirst方法public void clear():清空列表public E removeFirst():将开头元素移除,返回该元素public E removeLast():将结尾元素移除,返回该元素public E pop():同removeFirst方法,返回该元素public boolean isEmpty():如列表不包含元素,则返回true
5、Vector<E> 集合 JDK 1.0
线程安全 每一个方法都使用synchronized关键字
之前是独立的集合,从Java 2平台v1.2,这个类被改造为实现[List接口。它与新集合实现不同, Vector是同步的(单线程)。 如果不需要线程安全的实现,建议使用ArrayList代替Vector 。
在最开始jdk1.0的时候
- 实现添加元素方法为:
public void addElement(E obj),jdk1.2之后继承了list接口,有了add()方法添加元素。 - 遍历元素的方法为:
public Enumeration<[E]> elements(),返回一个Enumeration集合,该集合与Iterator迭代器类似。Enumeration集合有两个方法:boolean hasMoreElements()测试是否还有更多的元素 和E nextElement()返回此枚举下一个元素。jdk1.2之后可以使用iterator迭代器对该集合遍历。
6、Set<E> 接口集合 JDK 1.2
java.util.Set接口和java.util.List接口一样,同样继承自Conllection接口,它与Conllection接口中的方法基本一致,并没有Conllection接口进行功能的扩充,只是比Conllection接口更加严格了。与List接口不同的是,Set接口中元素无序,并且都会以某种规则保证存入的元素不出现重复。
Set接口集合有多个子类,这里我们介绍其中的java.util.HashSet、java.util.LinkedHashSet这两个集合。
tips:Set集合取出元素的方式可以采用迭代器、增强for
特点:
- 存储元素无序
- 存储元素不重复
- 无索引
HashSet、LinkedHashSet、TreeSet底层 源码
// 1************************************************************************************
public HashSet() {
map = new HashMap<>();
}
// add方法
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 2************************************************************************************
public LinkedHashSet() {
super(16, .75f, true);
}
--->
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
---> private transient HashMap<E,Object> map;
// 3************************************************************************************
public TreeSet() {
this(new TreeMap<E,Object>());
}
可见底层是HashMap,HashMap底层是哈希表
7、HashSet<E> 集合 JDK 1.2
此类实现Set接口,由哈希表(实际也是HashMap实例)支持
特点:
- 不允许存储重复元素
- 没有索引
- 是一个无序集合,存储元素和取出元素的顺序可能不一致
- 底层是一个哈希表结构(查询的速度非常快)
public class Test{
public static void main(String[] args){
HashSet<Integer> hashSet = new HashSet<>();
hashSet.add(1);
hashSet.add(3);
hashSet.add(2);
hashSet.add(1);
Iterator<Integer> iterator = hashSet.iterator();
if(iterator.hasNext()){
System.out.println(iterator.next()); // 输出 1,2,3
}
for(Integer i : hashSet){
System.out.println(i); // 输出 1,2,3
}
}
}
由上可看出,HashSet的特点。
HashSet存储数据的结构(哈希表)
哈希表结构:在jdk8之前是数组+链表;jdk8开始时数组+链表/红黑树(查询速度快)
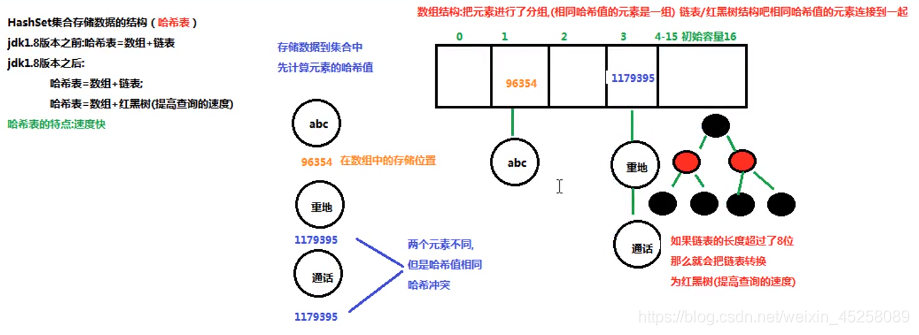
在jdk8开始,当相同hashcode下的链表长度超过8位就会自动转换为红黑树,这样提高查询速度。
tips:了解红黑树,请移步至Java数据结构与算法:红黑树.md
hashCode()方法
public native int hashCode()
Object类hashCode方法原生写法,应该是将物理地址转换成整数然后将该整数通过hash算法,算出值。
native主要用于方法上:
1、一个native方法就是一个Java调用非Java代码的接口。一个native方法是指该方法的实现由非Java语言实现,比如用C或C++实现。
2、在定义一个native方法时,并不提供实现体(比较像定义一个Java Interface),因为其实现体是由非Java语言在外面实现的。
对象的内容通过hash函数的算法就得到了hashcode。该hashcode值就是在hash表中对应的位置。HashCode的存在主要是为了查找的快捷性。
为什么hashcode查找更快?
假如hash表中有1、2、3、4、5、6、7、8个位置,存第一个数,hashcode为1,该数就放在hash表中1的位置,存到100个数字,hash表中8个位置会有很多数字了,1中可能有20个数字,存101个数字时,他先查hashcode值对应的位置,假设为1,那么就有20个数字和他的hashcode相同,他只需要跟这20个数字相比较(equals),如果没一个相同,那么就放在1这个位置,这样比较的次数就少了很多,实际上hash表中有很多位置,这里只是举例只有8个,所以比较的次数会让你觉得也挺多的,实际上,如果hash表很大,那么比较的次数就很少很少了。
set集合存储不重复元素的原理

equals方法和hashcode的关系
先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。
- 如果两个对象equals相等,那么这两个对象的HashCode一定也相同
- 如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
如果对象的equals方法被重写,那么对象的HashCode方法也要重写。
equals方法与hashcode方法必须一起重写。
存储自定义类型,重写hashcode、equals
自定义的类型,一定要重写hashcode和equals方法!!!
Person.java
// 要求:名字、年龄一样则视为同一个人
// 自定义Person类
public class Person {
private String name;
private String age;
public Person() {
}
public Person(String name, String age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age='" + age + '\'' +
'}';
}
}
Person.java
// 通过快捷 重写hashcode和equals方法
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name) &&
Objects.equals(age, person.age);
}
// 可以明显看到hashCode方法,将对象中的内容进行hash值,所以输入内容一样得出的hash值肯定是一样的,也不排除hash冲突。如果不重写的话,调用的Object的hashCode方法,那么就是通过对象的物理地址进行hash算法,结果肯定不同。
// 有了hash冲突,就得用equals方法去判断存储内容是不是一样的,如果不一样就存入hash结构表中,如果一样则存入。不重写equals,调用的是Object类的equals方法,该方法底层是用==比较
Test.java
public class Test {
public static void main(String[] args) {
Person p1 = new Person("heroC","18");
Person p2 = new Person("heroC","18");
Person p3 = new Person("张还行","18");
HashSet<Person> set = new HashSet<>();
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println(set);
System.out.println(p1.equals(p2));
}
}
// 没有重写hashcode和equals方法输出的结果:
// [Person{name='张还行', age='18'}, Person{name='heroC', age='18'}, Person{name='heroC', age='18'}]
// false
// 重写hashcode和equals方法输出的结果:
// [Person{name='heroC', age='18'}, Person{name='张还行', age='18'}]
// true
8、LinkedHashSet<E> 集合 JDK 1.2
HashSet保证元素唯一,但元素存放没有顺序,因此有了LinkedHashSet类,java.util.LinkedHashSet,该类实现了Set接口同时也是HashSet类的子类。它是链表和哈希表组合的一个数据存储结构。
特点:
底层是一个哈希表(数组+链表/红黑树)+链表;多了一条链表(用于记录元素的存储顺序),保证元素有序
public class Test {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("www");
set.add("abc");
set.add("heroC");
System.out.println(set); // [heroC, abc, www] 无序
LinkedHashSet<String> linked = new LinkedHashSet<>();
linked.add("www");
linked.add("abc");
linked.add("heroC");
System.out.println(linked); // [www, abc, heroC] 有序
}
}
9、TreeSet<E> 集合 JDK 1.2
java.util.TreeSet 底层红黑树
特点:
- 无索引
- 无重复元素
- 可按照自然顺序自动排序
public class Test {
public static void main(String[] args) {
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(45);
treeSet.add(234);
treeSet.add(234);
treeSet.add(13);
treeSet.add(10);
System.out.println(treeSet); // 输出 [10, 13, 45, 234]
Iterator<Integer> iterator = treeSet.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
for (Integer i: treeSet){
System.out.println(i);
}
}
}
Collections集合工具类
从JDK1.2开始 java.util.Collections extends Object 该类是集合工具类,对集合进行操作的类。该工具类,可以调用同步集合(调用的同步集合在方法内加入了synchronized关键字)。
常用方法
public static <T> boolean addAll(Collection<? super T> c, T... elements)将所有指定的元素添加到指定的集合。 要添加的元素可以单独指定或作为数组指定。public static void shuffle(List<?> list)使用默认的随机源随机排列指定的列表。 所有排列都以大致相等的可能性发生。public static <T extends Comparable<? super T> > void sort(List<T> list)将集合按照默认规则排序。public static <T> void sort(List<T> list, Comparator<? super T> c)将集合中的元素按照指定规则排序。
public static void main(String[] args){
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "a","b","c","d","e");
System.out.println(list); // 输出 [a,b,c,d,e]
Collectons.shuffle(list);
System.out.println(list); // 输出 [b,d,a,c,e] 每次输出结果不同,作用在于打乱顺序
Collections.sort(list);
System.out.println(list); // 输出 [a,b,c,d,e] 默认规则,自然规则排序
}
自定义类型的集合,排序( 常用方法3关于自定义类型的集合实现方法 ):
Person.java
public class Person implements Comparable<Person>{
private String name;
private int age;
public Person(){
}
public Person(String name, int age){
this.name = name;
this.age = age;
}
// 此处省略 getter/setter 方法
@Override
public int compareTo(Person p){
return this.getAge() - p.getAge(); // *****按照年龄升序排序 反过来减就是降序
}
}
Test.java
public class Test{
public static void main(String[] args){
ArrayList<Person> list = new ArrayList<>();
Collections.addAll(list, new Person("a", 28),new Person("b", 18),new Person("c", 38));
Collections.sort(list);
System.out.println(list);
// 输出 [Person{"b", 18},Person{"a", 28},Person{"c", 38}]
}
}
注意:自定义类型的集合,一定要实现 Comparable<E> 接口,并且重写排序规则方法 compareTo(Object o) ,这样在自定义类型的集合在排序的时候,才不会报错。java内置的类型实现了该接口,并重写了该方法。
两个sort方法的比较:
Comparable与Comparator的区别
- Comparable:是自己this对象与另一个对象,进行比较的规则。实现Comparable接口重写CompareTo方法。
- Comparator:是第三方来给定规则,来排序这个集合里的所有元素。自定义类型就不用实现Comparable接口了不用重写方法了。
ArrayList<Person> list = new ArrayList<>();
Collections.addAll(list, new Person("a", 28),new Person("b", 18),new Person("c", 38));
Collections.sort(list, new Comparator<Person>(){
@Override
public int compare(Person p1, Person p2){
return p1.getAge() - p2.getAge(); // 按年龄升序
}
});
// 如果年龄一样,按照名字排序
ArrayList<Person> listA = new ArrayList<>();
Collections.addAll(listA, new Person("a", 28),new Person("c", 18),new Person("b", 18));
Collections.sort(listA, new Comparator<Person>(){
@Override
public int compare(Person p1, Person p2){
int result = p1.getAge() - p2.getAge(); // 按年龄升序,如果年龄一样
if( result == 0){
result = p1.getName().charAt(0) - p2.getName().charAt(0); // 按照名字的第一个字符顺序排序。如果名字第一个字符一样,那么在添加在这个集合中时,谁在前,谁就排在前面
}
return result;
}
});
System.out.println(listA); // 输出 [Person{"b", 18},Person{"c", 18},Person{"a", 28}]
初始化一个静态/不可变的map集合
public class test{
private static final Map<String,String> map;
static {
Map<String,String> map1 = new HashMap<>();
map1.put("1","11");
map1.put("2","22");
Map<String, String> map2 = Collections.unmodifiableMap(map1);
map = map2;
}
public static void main(String[] args) {
map.put("3","33"); // 报异常 UnsupportedOperationException
}
}
同样Collections工具类,还有其他不可修改的集合方法
unmodifiableCollection(Collection<? extends T> c)
unmodifiableList(List<? extends T> list)
unmodifiableSet(Set<? extends T> s)