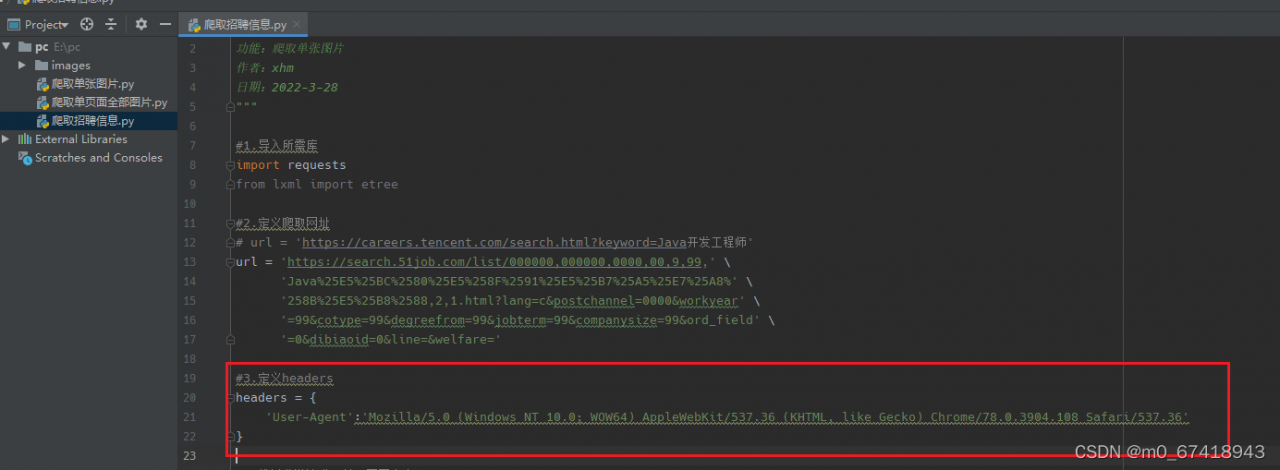
1.首先新建一个python文件,开始爬取招聘信息
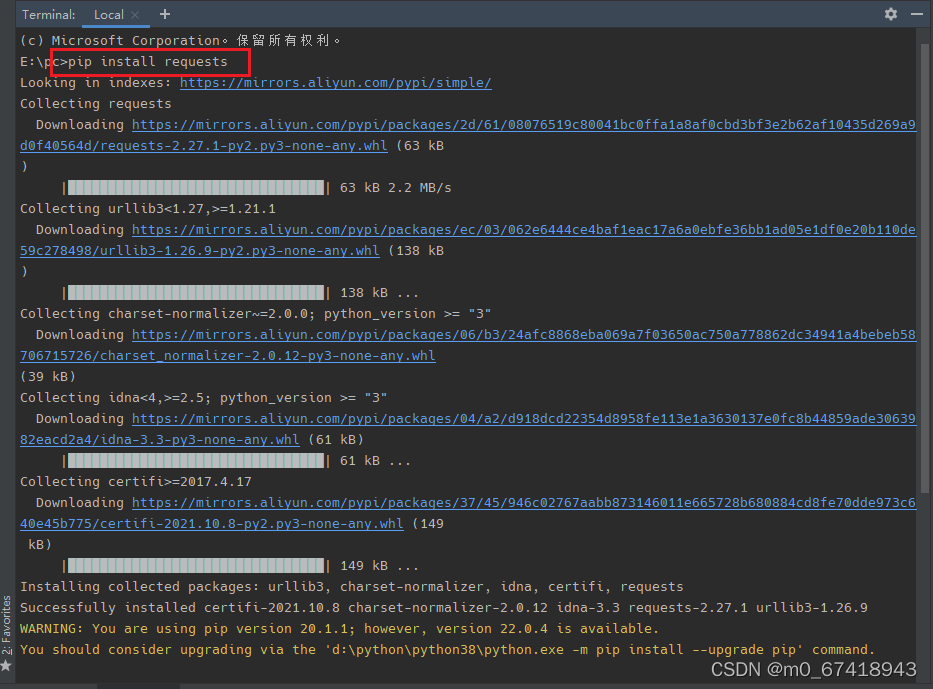
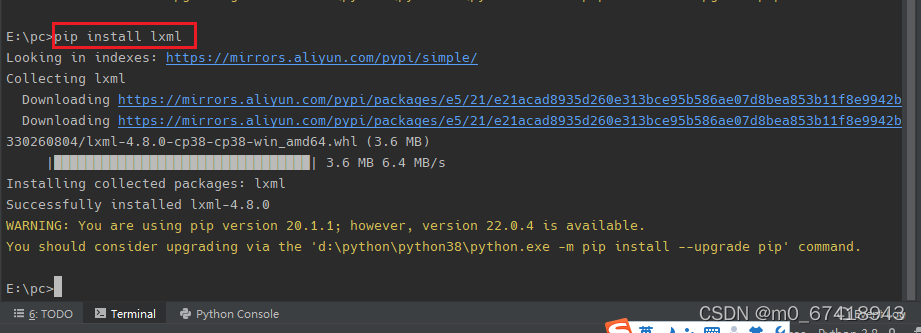
2.在终端中输入pip install requests/lxml,安装所需库
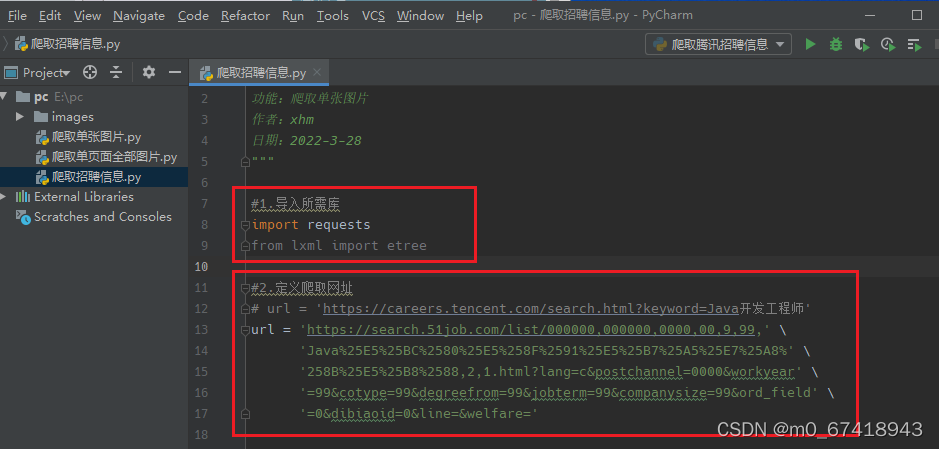
3.导入所需要的库以及定义好要爬取招聘信息网页的网址
4.定义好headers
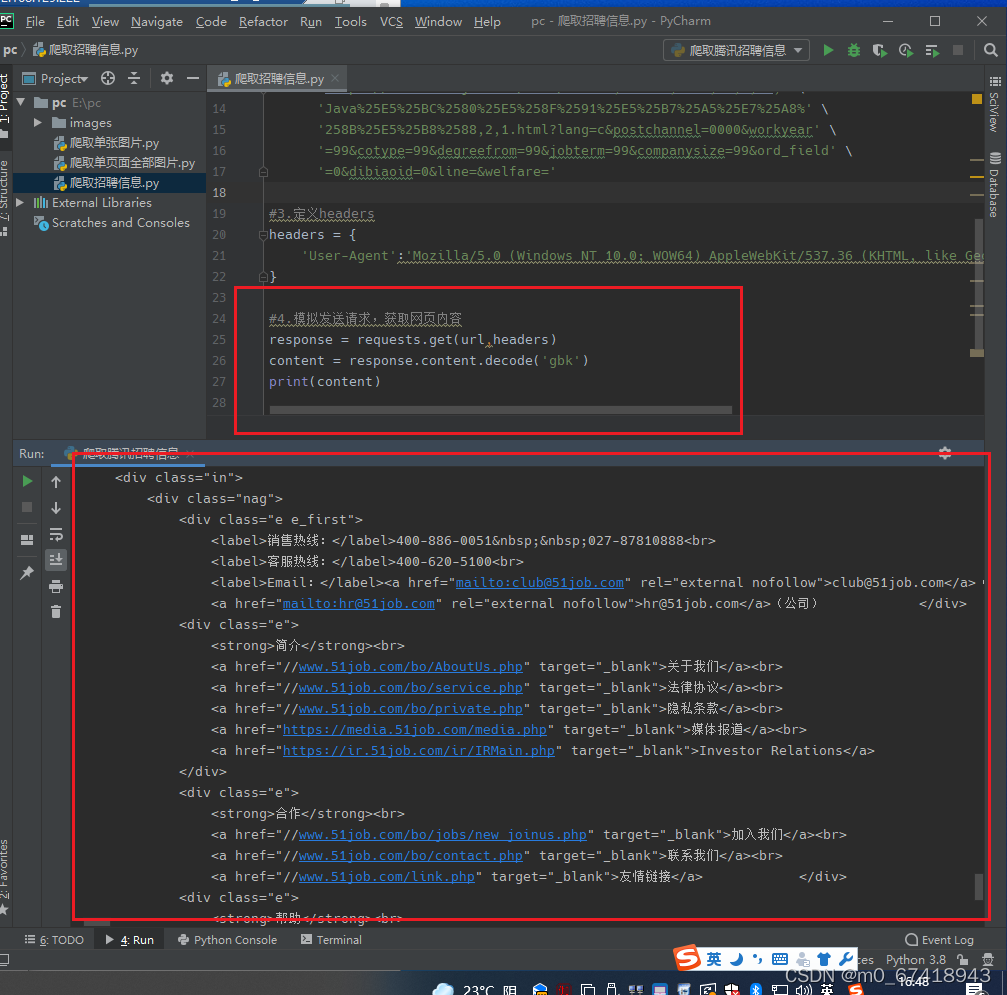
5.模拟发送请求,获取网页的所有内容
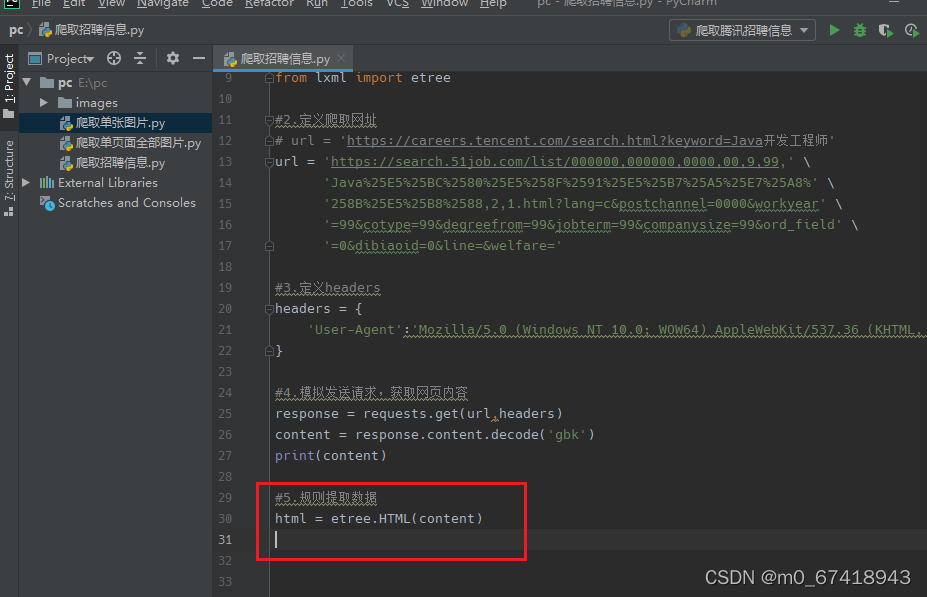
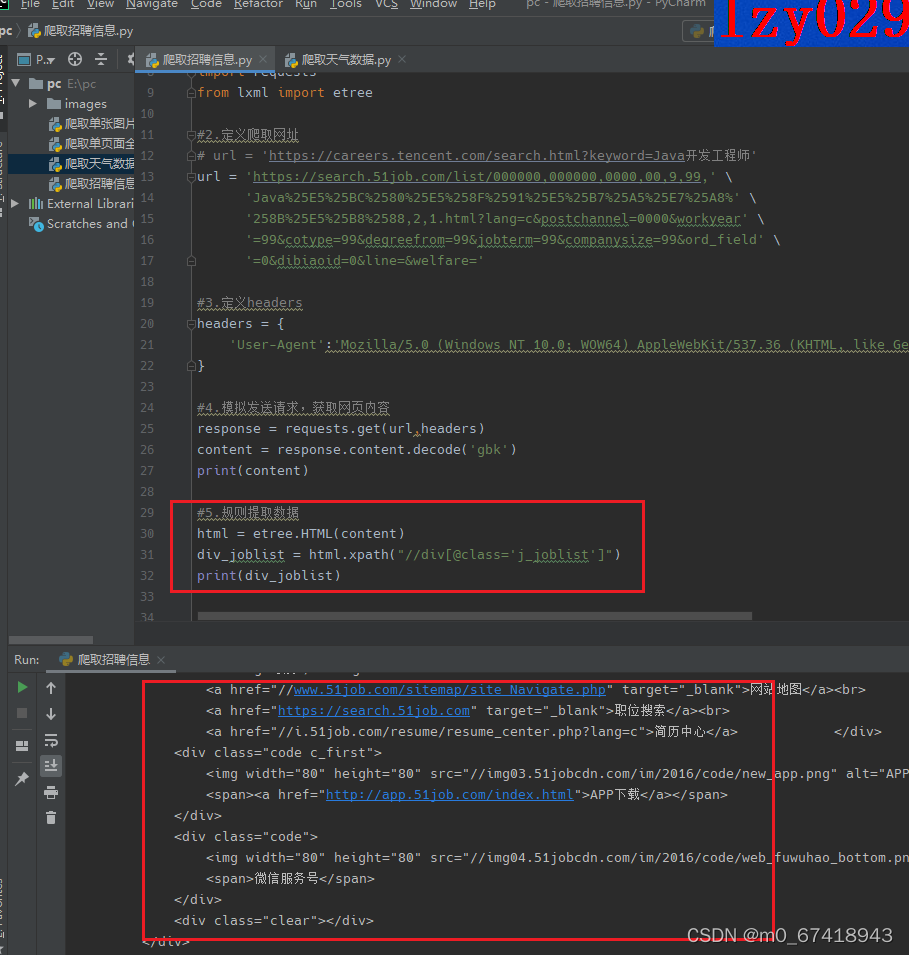
6.利用etree来梳理所爬取的网页
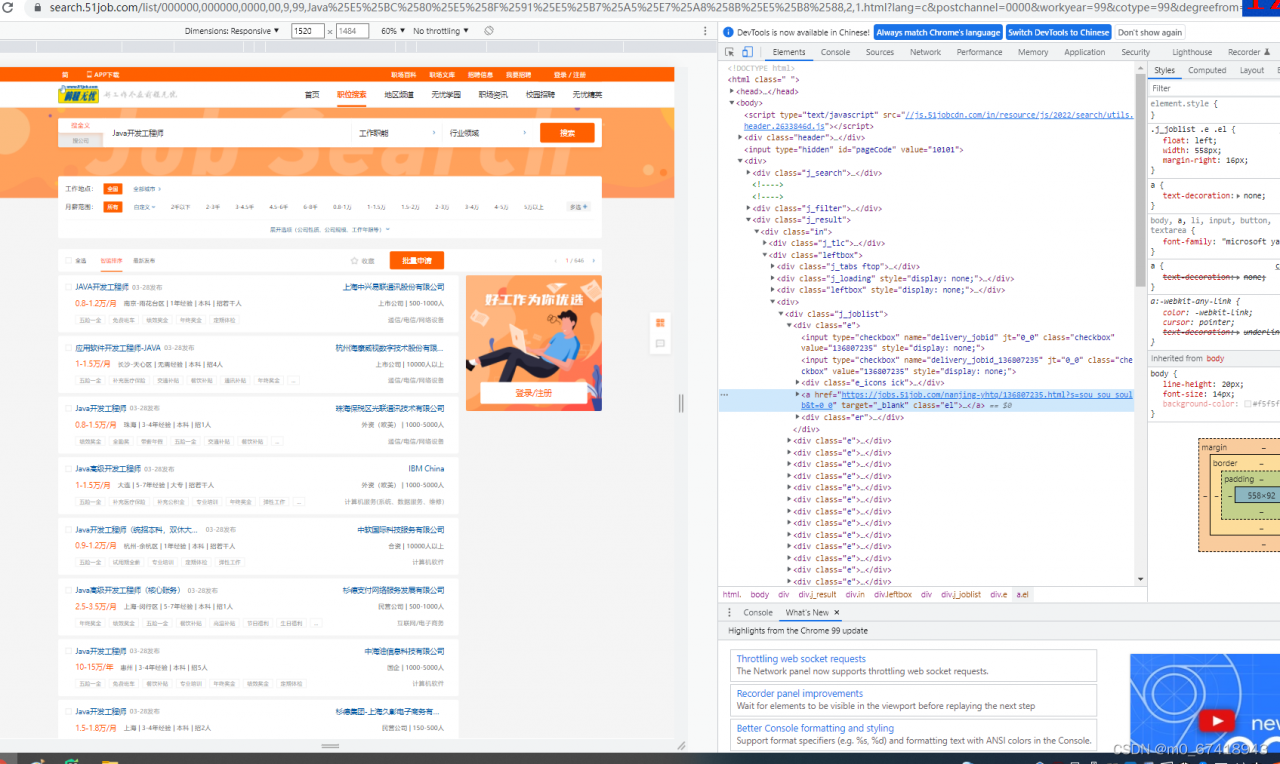
7.分析所要爬取的网页结构
8.提取数据
版权声明:本文为m0_67418943原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
1.首先新建一个python文件,开始爬取招聘信息
2.在终端中输入pip install requests/lxml,安装所需库
3.导入所需要的库以及定义好要爬取招聘信息网页的网址
4.定义好headers
5.模拟发送请求,获取网页的所有内容
6.利用etree来梳理所爬取的网页
7.分析所要爬取的网页结构
8.提取数据