文章目录
倍增优化DP
在线性DP中,我们一般是按照阶段将DP的状态线性增长,但是我们可以运用倍增思想,将线性增长转化为成倍增长
对于应用倍增优化DP,一般分为两个步骤
1.预处理 ,我们使用成倍增长的DP计算出与二的整次幂有关的代表状态
2.拼凑,根据二进制划分的思想,使用预处理出的状态拼凑出最后的答案(注意,此处一般是倒序循环)
好的下面来一道经典题目详细解释:
[NOIP2012 提高组] 开车旅行
题目描述
小 A \text{A}A 和小 B \text{B}B 决定利用假期外出旅行,他们将想去的城市从 $1 $ 到 n nn 编号,且编号较小的城市在编号较大的城市的西边,已知各个城市的海拔高度互不相同,记城市 i ii 的海拔高度为h i h_ihi,城市 i ii 和城市 j jj 之间的距离 d i , j d_{i,j}di,j 恰好是这两个城市海拔高度之差的绝对值,即 d i , j = ∣ h i − h j ∣ d_{i,j}=|h_i-h_j|di,j=∣hi−hj∣。
旅行过程中,小 A \text{A}A 和小 B \text{B}B 轮流开车,第一天小 A \text{A}A 开车,之后每天轮换一次。他们计划选择一个城市 s ss 作为起点,一直向东行驶,并且最多行驶 x xx 公里就结束旅行。
小 A \text{A}A 和小 B \text{B}B 的驾驶风格不同,小 B \text{B}B 总是沿着前进方向选择一个最近的城市作为目的地,而小 A \text{A}A 总是沿着前进方向选择第二近的城市作为目的地(注意:本题中如果当前城市到两个城市的距离相同,则认为离海拔低的那个城市更近)。如果其中任何一人无法按照自己的原则选择目的城市,或者到达目的地会使行驶的总距离超出 x xx 公里,他们就会结束旅行。
在启程之前,小 A \text{A}A 想知道两个问题:
1、 对于一个给定的 x = x 0 x=x_0x=x0,从哪一个城市出发,小 A \text{A}A 开车行驶的路程总数与小 B \text{B}B 行驶的路程总数的比值最小(如果小 B \text{B}B 的行驶路程为 0 00,此时的比值可视为无穷大,且两个无穷大视为相等)。如果从多个城市出发,小 A \text{A}A 开车行驶的路程总数与小 B \text{B}B 行驶的路程总数的比值都最小,则输出海拔最高的那个城市。
2、对任意给定的 x = x i x=x_ix=xi 和出发城市 s i s_isi,小 A \text{A}A 开车行驶的路程总数以及小 B \text BB 行驶的路程总数。
输入格式
第一行包含一个整数 n nn,表示城市的数目。
第二行有 n nn 个整数,每两个整数之间用一个空格隔开,依次表示城市 1 11 到城市 n nn 的海拔高度,即 h 1 , h 2 . . . h n h_1,h_2 ... h_nh1,h2...hn,且每个 h i h_ihi 都是互不相同的。
第三行包含一个整数 x 0 x_0x0。
第四行为一个整数 m mm,表示给定 m mm 组 s i s_isi 和 x i x_ixi。
接下来的 m mm 行,每行包含 2 22 个整数 s i s_isi 和 x i x_ixi,表示从城市s i s_isi 出发,最多行驶 x i x_ixi 公里。
输出格式
输出共 m + 1 m+1m+1 行。
第一行包含一个整数 s 0 s_0s0,表示对于给定的 x 0 x_0x0,从编号为 s 0 s_0s0 的城市出发,小 A \text AA 开车行驶的路程总数与小 B \text BB 行驶的路程总数的比值最小。
接下来的 m mm 行,每行包含 2 22 个整数,之间用一个空格隔开,依次表示在给定的 s i s_isi 和 x i x_ixi 下小 A \text AA 行驶的里程总数和小 B \text BB 行驶的里程总数。
【数据范围与约定】
对于 30 % 30\%30% 的数据,有1 ≤ n ≤ 20 , 1 ≤ m ≤ 20 1\le n \le 20,1\le m\le 201≤n≤20,1≤m≤20
对于40 % 40\%40% 的数据,有1 ≤ n ≤ 100 , 1 ≤ m ≤ 100 1\le n \le 100,1\le m\le 1001≤n≤100,1≤m≤100
对于 50 % 50\%50% 的数据,有1 ≤ n ≤ 100 , 1 ≤ m ≤ 1000 1\le n \le 100,1\le m\le 10001≤n≤100,1≤m≤1000
对于 70 % 70\%70% 的数据,有1 ≤ n ≤ 1000 , 1 ≤ m ≤ 1 0 4 1\le n \le 1000,1\le m\le 10^41≤n≤1000,1≤m≤104
对于 100 % 100\%100% 的数据:1 ≤ n , m ≤ 1 0 5 1\le n,m \le 10^51≤n,m≤105,− 1 0 9 ≤ h i ≤ 1 0 9 -10^9 \le h_i≤10^9−109≤hi≤109,1 ≤ s i ≤ n 1 \le s_i \le n1≤si≤n,0 ≤ x i ≤ 1 0 9 0 \le x_i \le 10^90≤xi≤109
数据保证 h i h_ihi 互不相同。
分析:我们先预处理出g a ( i ) , g b ( i ) ga(i),gb(i)ga(i),gb(i)表示从城市i出发下一步小A和小B分别会开往哪一个城市,这个可以通过平衡树实现
仔细阅读题面,我们会发现,本题有三个信息:1.天数,2.城市,3.小A和小B分别行驶的路程总长度
于是我们仔细思考可以发现,当我们知道了行驶天数和出发城市之后,我们肯定可以知道小A和小B分别行驶的路径总长度以及终点城市
于是这启发我们使用动态规划:但是观察1 0 5 10^5105的数据范围,这就必须使用上优化,于是我们考虑使用倍增优化DP
具体的,我们设F i , j , k F_{i,j,k}Fi,j,k表示在第2 i 2^i2i天,从城市j出发,当前是k(0A1B)在开车的终点城市
初值:F 0 , i , 0 = g a ( i ) , F 0 , i , 1 = g b ( i ) F_{0,i,0}=ga(i),F_{0,i,1}=gb(i)F0,i,0=ga(i),F0,i,1=gb(i)
由于当i = 1 i=1i=1的时候两人是一人一天,于是
F 1 , i , 0 = F 0 , F 0 , i , 0 , 1 , F 1 , i , 1 = F 0 , F 0 , i , 1 , 0 F_{1,i,0}=F_{0,F_{0,i,0},1},F_{1,i,1}=F_{0,F_{0,i,1},0}F1,i,0=F0,F0,i,0,1,F1,i,1=F0,F0,i,1,0
当i ≥ 2 i\ge 2i≥2时:
F i , j , k = F i − 1 , F i − 1 , j , k , k F_{i,j,k}=F_{i-1,F_{i-1,j,k},k}Fi,j,k=Fi−1,Fi−1,j,k,k
此时我们就可以通过递推求出F FF了,那么还有两个需要知道的信息,即小A和小B的路径长度
于是我们设d a i , j , k , d b i , j , k da_{i,j,k},db_{i,j,k}dai,j,k,dbi,j,k分别表示小A小B在前2 i 2^i2i天从城市j jj出发当前是k kk在开车的路径长度
与F数组相似的,我们有
初值:d a 0 , i , 0 = d i s t ( i , g a ( i ) ) , d b 0 , i , 1 = d i s t ( i , g b ( i ) ) da_{0,i,0}=dist(i,ga(i)),db_{0,i,1}=dist(i,gb(i))da0,i,0=dist(i,ga(i)),db0,i,1=dist(i,gb(i))其余全部为0
当i = 1 i=1i=1时有:
d a 1 , i , k = d a 0 , i , k + d a 0 , F 0 , i , k , 1 − k , d b 1 , i , k = d b 0 , i , k + d b 0 , F 0 , i , k , 1 − k da_{1,i,k}=da_{0,i,k}+da_{0,F_{0,i,k},1-k},db_{1,i,k}=db_{0,i,k}+db_{0,F_{0,i,k},1-k}da1,i,k=da0,i,k+da0,F0,i,k,1−k,db1,i,k=db0,i,k+db0,F0,i,k,1−k
当i ≥ 2 i\ge 2i≥2时有:
d a i , j , k = d a i − 1 , j , k + d a i − 1 , F i − 1 , j , k , k , d a i , j , k = d a i − 1 , j , k + d a i − 1 , F i − 1 , j , k , k da_{i,j,k}=da_{i-1,j,k}+da_{i-1,F_{i-1,j,k},k},da_{i,j,k}=da_{i-1,j,k}+da_{i-1,F_{i-1,j,k},k}dai,j,k=dai−1,j,k+dai−1,Fi−1,j,k,k,dai,j,k=dai−1,j,k+dai−1,Fi−1,j,k,k
对此进行DP,我们可以在O ( n log n ) O(n\log n)O(nlogn)的时间内得到关于2的整次幂的信息
下面我们考虑询问c a l c ( s , x ) calc(s,x)calc(s,x)表示从城市s出发最多行走x时小A和小B分别走的路程总数
记l a lala为小A路程总数,l b lblb为小B路程总数
1.我们按照二进制从大到小枚举2的整次幂,记作i ii,初始化当前城市p = s p=sp=s
2.若
l a + l b + d a i , p , 0 + d b i , p , 0 ≤ x la+lb+da_{i,p,0}+db_{i,p,0}\le xla+lb+dai,p,0+dbi,p,0≤x
则令l a + = d a i , p , 0 , l b + = d b i , p , 0 , p = F i , p , 0 la+=da_{i,p,0},lb+=db_{i,p,0},p=F_{i,p,0}la+=dai,p,0,lb+=dbi,p,0,p=Fi,p,0
循环结束后l a , l b la,lbla,lb即为所求
枚举起点计算就可以解决问题一,问题二就等同于计算多次c a l c ( s i , x i ) calc(s_i,x_i)calc(si,xi)
#define int long long;
struct node{
int val,f,ch[2],id;
}t[100005]
int root,tot;
#define lc(x) t[x].ch[0];
#define rc(x) t[x].ch[1];
void rotate(int x){
int y=t[x].f,z=t[y].f,k=rc(y)==x;
t[z].ch[rc(z)==y]=x;
t[x].f=z;
t[y].ch[k]=t[x].ch[k^1];
t[t[y].ch[k]].f=y;
t[y].f=x;
t[x].ch[k^1]=y;
}
void splay(int x,int goal=0){
while(t[x].f!=goal){
int y=t[x].f,z=t[y].f;
if(z!=goal){
rc(y)==x^rc(z)==y?rotate(x):rotate(y);
}
rotate(x);
}
if(!goal)root=x;
}
void insert(int id,int val){
int p=0,u=root;
while(u)p=u,u=t[u].ch[t[u].val<val];
u=++tot;
if(!p){
root=u;
t[u].f=0;
}
else{
t[p].ch[t[p].val<val]=u;
t[u].f=p;
}
t[u].ch[0]=t[u].ch[1]=0t[u].id=id,t[u].val=val;
splay(u);
}
int nxt(int val,int p){//0前驱1后继
int u=root;
while(t[u].ch[val>t[u].val]&&t[u].val!=val)u=t[u].ch[t[u].val<val];
splay(u);
u=t[u].ch[p];
while(t[u].ch[!p])u=t[u].ch[!p];
return u;
}
/*---------------以上是平衡树Splay求前驱后继----------------*/
#define N 100005
#define INF 0x7f7f7f7f7f7f
int n,m,h[N],x[N],s[N],ga[N],gb[N],w;
int f[18][N][2],da[18][N][2],db[18][N][2],la,lb;
void calc(int S,int X) {
la=lb=0;
int p=S;
for(int i=w;i>=0;i--)
if(f[i][p][0]&&la+lb+da[i][p][0]+db[i][p][0]<=X) {
la+=da[i][p][0];
lb+=db[i][p][0];
p=f[i][p][0];
}
}
signed main(){
// freopen("P1081_2.in","r",stdin)
scanf("%lld",&n);
insert(0,-INF);
insert(0,INF-1);
insert(0,INF);
insert(0,1-INF);/*插入哨兵方便计算*/
for(int i=1;i<=n;i++){
scanf("%lld",&h[i]);
}
scanf("%lld%lld",&x[0],&m);
for(int i=1i<=mi++)scanf("%lld%lld",&s[i],&x[i]);
w=log(n)/log(2);
for(int i=n;i>0;--i){
insert(i,h[i]);
int hj1=nxt(h[i],1);
int hj2=nxt(t[hj1].val,1);
int qq1=nxt(h[i],0);
int qq2=nxt(t[qq1].val,0);
int a=t[hj1].id==0?INF:t[hj1].val-h[i];
int b=t[qq1].id==0?INF:h[i]-t[qq1].val;//小A次小,小B最小
if(b<=a){
gb[i]=t[qq1].id;
b=t[qq2].id==0?INF:h[i]-t[qq2].val;
ga[i]=b<=a?t[qq2].id:t[hj1].id;//大小关系一定注意
}
else {
gb[i]=t[hj1].id;
a=t[hj2].id==0?INF:t[hj2].val-h[i];
ga[i]=b<=a?t[qq1].id:t[hj2].id;
}
}
for(int i=1;i<=n;i++)f[0][i][0]=ga[i],f[0][i][1]=gb[i];
for(int i=1;i<=n;i++)f[1][i][1]=f[0][f[0][i][1]][0],f[1][i][0]=f[0][f[0][i][0]][1];
for(int i=2;i<w;i++){
for(int j=1;j<=n;j++){
f[i][j][0]=f[i-1][f[i-1][j][0]][0];
f[i][j][1]=f[i-1][f[i-1][j][1]][1];
}
}
for(int i=1;i<=n;i++){
da[0][i][0]=abs(h[i]-h[ga[i]]);
db[0][i][0]=0;
da[0][i][1]=0;
db[0][i][1]=abs(h[i]-h[gb[i]]);
}
for(int i=1;i<=n;i++){
da[1][i][0]=da[0][i][0];
db[1][i][0]=db[0][f[0][i][0]][1];
da[1][i][1]=da[0][f[0][i][1]][0];
db[1][i][1]=db[0][i][1];
}
for(int i=2;i<w;i++){
for(int j=1;j<=n;j++){
da[i][j][0]=da[i-1][j][0]+da[i-1][f[i-1][j][0]][0];
da[i][j][1]=da[i-1][j][1]+da[i-1][f[i-1][j][1]][1];
db[i][j][0]=db[i-1][j][0]+db[i-1][f[i-1][j][0]][0];
db[i][j][1]=db[i-1][j][1]+db[i-1][f[i-1][j][1]][1];
}
}
/*如分析所言DP*/
calc(1,x[0]);
double ans=(lb?(double)la/lb:2e9);
int num=1;
for (int i=2;i<=n;i++) {
calc(i,x[0]);
if ((double)la/lb<ans||(((double)la/lb==ans)&&h[i]>h[num])){
num=i;
ans=(double)la/lb;
}
}
printf("%lld\n",num);
for(int i=1;i<=m;i++){
calc(s[i],x[i]);
printf("%lld %lld\n",la,lb);
}
}
最后,使用倍增优化DP的前提条件是问题的答案具有强可拼接性,即我们划分阶段做出决策的时候可以任意划分不影响答案(对划分有着限制,比如某个阶段不可以拼凑答案就不可以使用),这样我们就可以把答案的计算变成二的整次幂。
多次查询的dp问题:一般数据结构维护,重复计算很多的话可以倍增优化
数据结构优化DP
在DP过程中有着阶段,状态,决策三个步骤,我们之前的倍增DP和状压DP是从阶段设计和状态上入手进行的优化,数据结构优化DP就是从决策方面对DP进行的优化,包括我们下面的单调队列也是如此
思想概述:运用数据结构的功能加速最优决策的寻找与状态的转移
下面附上常用数据结构的功能
| 数据结构 | 支持操作 | 均摊时间复杂度 | 代码难度 | 常数 | 扩展性 |
|---|---|---|---|---|---|
| 线段树 | 维护区间信息(可加性),区间修改 | 单次 O ( log n ) O(\log n)O(logn) | 一般 | 较大 | 较好 |
| 树状数组 | 维护前缀和,区间前缀最值,单点修改 | 单次O ( log n ) O(\log n)O(logn) | 小 | 很小 | 不好 |
| 平衡树 | 维护最值,前驱后继,删除节点,rank | 单次期望O ( log n ) O(\log n)O(logn) | 较大 | 较大 | 较好 |
| Splay \operatorname{Splay}Splay | 关于序列70%的问题,平衡树操作,区间操作 | 单次期望O ( log n ) O(\log n)O(logn) | 略大 | 较大 | 好 |
| 堆(KaTeX parse error: Expected 'EOF', got '_' at position 30: …prioprity\text{_̲}queue}) | 插入,删除(STL不支持,懒惰删除法),最值 | 单次O ( log n ) O(\log n)O(logn) | 手写较大 | 很小 | 不好 |
| 分块 | 区间几乎所有问题 | 单次O ( n ) O(\sqrt{n})O(n) | 一般 | 较小 | 极好 |
| 树套树 | 取决于嵌套的结构,一般为功能总和 | 单次O ( log 2 n ) O(\log^2 n)O(log2n)+ | 极大(用得少) | 大 | 较好 |
| (可持久化)trie | 关于异或的操作(区间操作需要可持久化) | 单次O ( log V ) O(\log V)O(logV)V为值域 | 较小 | 较小 | 一般 |
| 可持久化线段树 | 线段树操作(除区间修改),区间rank,历史版本查询 | 单次O ( log n ) O(\log n)O(logn) | 较小 | 较小 | 一般 |
注:
1.普通线段树需要4 n 4n4n空间,可持久化数据结构需要一般形态的十倍至二十倍
2.线段树和树状数组可以经过离散化开值域上的,不仅仅限于序列上的
在状态转移方程中,如遇到某些数据结构支持的操作,便可以使用数据结构进行优化,下面给几个例题感受一下
清理班次2
题目描述:有N NN头奶牛,每一头奶牛在a i ∼ b i a_i\sim b_iai∼bi个班次内工作,需要付出代价c i c_ici,求使[ M , E ] [M,E][M,E]的班次内都有奶牛在工作的最小代价
由题:设F i F_iFi表示M ∼ i M\sim iM∼i的班次内的最小代价,明显有状态转移方程:
F b i = min a i − 1 ≤ j ≤ b i − 1 F j + c i F_{b_i}=\min_{a_i-1\le j \le b_i-1}F_j+c_iFbi=ai−1≤j≤bi−1minFj+ci
初值:F M − 1 = 0 F_{M-1}=0FM−1=0,其余均为正无穷,目标min i ≥ E F i \min_{i\ge E}{F_i}mini≥EFi,实现时需要注意边界
于是我们观察状态转移方程发现,我们需要查询一个区间内的最小值,而朴素写法无疑需要O ( n ) O(n)O(n)的时间,这一步就可以采用线段树进行优化
memset(f,0x3f,sizeof f);
int S,T;
scanf("%d%d%d",&n,&S,&T);
if(T>0)build(1,1,T);
if(T>0)f[0]=0;
int sum=0;
for(int i=1;i<=n;i++)scanf("%d%d%d",&ask[i].x,&ask[i].y,&ask[i].z),sum+=ask[i].z;
sort(ask+1,ask+n+1,cmp) ;
for(int i=1;i<=n;i++){
int mn=ask[i].x-1<=S?0:query(1,ask[i].x-1,min(T,ask[i].y-1));
f[ask[i].y]=min(mn+ask[i].z,f[ask[i].y]);
if(ask[i].y>0)update(1,ask[i].y,f[ask[i].y]) ;
}
printf("%d\n",f[T]>sum?-1:f[T]);
赤壁之战
题意:给定一个长度为N NN的序列A AA,求A AA中长度为M MM的严格递增子序列的个数
由题,很容易想到
设F i , j F_{i,j}Fi,j表示A AA中前i ii个数以A i A_iAi为结尾的组成长度为j jj的严格递增子序列的个数
不难得出状态转移方程:
F i , j = ∑ k < i , A k < A i F k , j − 1 F_{i,j}=\sum_{k<i,A_k<A_i}F_{k,j-1}Fi,j=k<i,Ak<Ai∑Fk,j−1
在这里,我们需要维护的决策集合为二元组( A k , F k , j − 1 ) (A_k,F_{k,j-1})(Ak,Fk,j−1),我们可以将A k A_kAk视作关键字,F k , j − 1 F_{k,j-1}Fk,j−1视作权值,则可以很轻松的使用平衡树进行维护,详细的说,我们维护子树的权值之和,在查询的时候就可以将A i A_iAi在平衡树中的非严格后继旋转至树根,此时树根的左子树的权值之和就是答案。注意我们此时需要将j jj的循环放在外层,对于当前的j jj,我们的决策集合是( k , F k , j − 1 ) ( k < i ) (k,F_{k,j-1})(k<i)(k,Fk,j−1)(k<i)于是我们可以在第二层循环i ii的时候先查询,再将( i , F i , j − 1 ) (i,F_{i,j-1})(i,Fi,j−1)插入决策集合,整个的复杂度为O ( n m log n ) O(nm\log n)O(nmlogn)。当然,当我们只是要求最长严格递增子序列的时候就可以省略掉j这一维度,做到O ( n log n ) O(n\log n)O(nlogn)
不过由于平衡树的常数较大,且实现难度较大,于是我们采用维护值域的树状数组做法
具体的:我们将A AA中的数离散化到[ 2 , N + 1 ] [2,N+1][2,N+1]之间,记v a l ( x ) val(x)val(x)表示x离散化后的值,特别的,我们令A 0 A_0A0为负无穷,v a l ( A 0 ) val(A_0)val(A0)为1,建立起维护值域[ 1 , N + 1 ] [1,N+1][1,N+1]的树状数组,起初所有值为0
1.对于插入决策的操作,就把v a l ( A k ) val(A_k)val(Ak)上的值增加F k , j − 1 F_{k,j-1}Fk,j−1
2.对于查询操作,就在树状数组中计算[ 1 , v a l ( A k ) − 1 ] [1,val(A_k)-1][1,val(Ak)−1]的前缀和即可
for(int i=1i<=mi++){
memset(c,0,sizeof c);//树状数组;
add(val(a[0]),f[0][i-1]);
for(int j=1;j<=n;j++){
f[j][i]=ask(val(a[j])-1);
add(val(a[j]),f[j][i-1]);
}
}
估算
给定一个长度为 N NN的整数数组A AA,你需要创建另一个长度为 N NN 的整数数组 B BB,数组 B BB 被分为 K KK 个连续的部分,并且如果 i ii 和 j jj 在同一个部分,则 B [ i ] = B [ j ] B[i]=B[j]B[i]=B[j]。
如果要求数组 B BB 能够满足 ∑ i = 1 n ∣ A [ i ] − B [ i ] ∣ \sum_{i=1}^n |A[i]−B[i]|∑i=1n∣A[i]−B[i]∣ 最小,那么最小值是多少,请你输出这个最小值。
题意即为我们将B BB分成K KK段,每一段段内元素都一样,求∑ i = 1 n ∣ A [ i ] − B [ i ] ∣ \sum_{i=1}^n |A[i]−B[i]|∑i=1n∣A[i]−B[i]∣的最小值,回想起中位数的结论,我们可以知道,设第i ii块的左右端点为L [ i ] , R [ i ] L[i],R[i]L[i],R[i],则B [ L [ i ] ∼ R [ i ] ] B[L[i]\sim R[i]]B[L[i]∼R[i]]的值应为A [ L [ i ] ∼ R [ i ] ] A[L[i]\sim R[i]]A[L[i]∼R[i]]的中位数,于是我们得到DP状态
设F [ i ] [ j ] F[i][j]F[i][j]表示前i ii个数分j jj段所得到的最小值,c o s t ( l , r ) cost(l,r)cost(l,r)为∑ i = l r ∣ A [ i ] − B [ i ] ∣ \sum_{i=l}^r|A[i]-B[i]|∑i=lr∣A[i]−B[i]∣的最小值,有状态转移方程
F [ i ] [ j ] = min j − 1 ≤ p < i { F [ p ] [ j − 1 ] + c o s t ( p + 1 , i ) } F[i][j]=\min_{j-1\le p <i}\lbrace F[p][j-1]+cost(p+1,i)\rbraceF[i][j]=j−1≤p<imin{F[p][j−1]+cost(p+1,i)}
若我们知道c o s t costcost的值,便可以O ( n 2 k ) O(n^2k)O(n2k)的DP出答案,而数据范围刚好只能支撑O ( n 2 k ) O(n^2k)O(n2k)的复杂度
而c o s t costcost的值又需要知道区间中位数才可以计算,于是我们可以使用对顶堆来动态维护中位数,这样我们就可以在O ( n 2 log n ) O(n^2\log n)O(n2logn)的复杂度内预处理出所有区间的中位数,于是在预处理中位数的同时我们就可以计算c o s t costcost了
总的时间复杂度是O ( n 2 log n ) + O ( n 2 k ) = O ( n 2 k ) O(n^2\log n)+O(n^2k)=O(n^2k)O(n2logn)+O(n2k)=O(n2k),足以通过本题
const int N=2050,K=30;
int f[N][K],midc[N][N],cost[N][N],a[N],n,k;
priority_queue<int>p,q;//p大根堆,q小根堆
int main(){
//freopen("estimate.in","r",stdin);
while(1){
n=read(),k=read();
if(n==0&&k==0)return 0;
for(int i=1;i<=n;i++){
a[i]=read();
}
for(int l=1;l<=n;l++){
priority_queue<int> empty1;
priority_queue<int> empty2;
swap(empty1, p);
swap(empty2, q);
int sumA=0,sumB=0;
for(int r=l;r<=n;r++){
if(l==r){
p.push(a[l]);
midc[l][r]=a[l];
sumA+=a[l];
cost[l][l]=0;
continue;
}
int siz=r-l+1;
if(p.empty())p.push(a[r]),sumA+=a[r];
else if(a[r]>p.top())q.push(-a[r]),sumB+=a[r];
else p.push(a[r]),sumA+=a[r];
while(p.size()>q.size()+1){
q.push(-p.top());sumB+=p.top(),sumA-=p.top();p.pop();
}
while(p.size()<q.size()){
sumA+=-q.top();
sumB+=q.top();
p.push(-q.top());q.pop();
}
midc[l][r]=(r-l+1)&1?p.top():p.top()-q.top()>>1;
cost[l][r]=(p.size()-q.size())*midc[l][r]+sumB-sumA;
}
}
memset(f,0x3f,sizeof f);
f[0][0]=0;
for(int i=1;i<=n;i++){
for(int j=1;j<=min(k,i);j++){
for(int q=i-1;q>=j-1;--q){
f[i][j]=min(f[q][j-1]+cost[q+1][i],f[i][j]);
}
}
}
printf("%d\n",f[n][k]);
}
return 0;
}
总结:无论DP的决策限制条件有多少,我们都要尽量对其进行分离,多维DP在执行内层循环时,我们可以将外层循环变量看作定值,状态转移取最优决策时,简单的限制条件循环处理,复杂的限制条件用数据结构维护,注重二者配合,在更难的题目中,还会出现数据结构的嵌套,以同时满足更多的限制条件
单调队列优化DP
思想:借助单调性,及时排出不可能的决策(可行性或最优性),保持决策集合的高效性与秩序性
模型:1D/1D动态规划
F [ i ] = min L ( i ) ≤ j ≤ R ( i ) { F [ j ] + val(i,j) } F[i]=\min_{L(i)\le j \le R(i)}\lbrace F[j]+\operatorname{val(i,j)} \rbraceF[i]=L(i)≤j≤R(i)min{F[j]+val(i,j)}
解释:这是一个最优化问题,其中的min \minmin也可以改为max \maxmax,且这只是一维的情况,很多时候DP方程式是外面有一维,里面才是这个模型,v a l valval是关于i , j i,ji,j的转移代价,L , R L,RL,R是两个关于i ii的线性函数,具备单调性(不一定严格),在这样的方程下,F FF必定具备非严格单调性,基于决策集合的单调性,我们可以使用单调队列优化
注意:v a l ( i , j ) val(i,j)val(i,j)这个多项式只能与i , j i,ji,j其中一项相关,不可以含i , j i,ji,j的乘积项(那是斜率优化的事情),不过因为i ii在外层循环,我们可以把关于i ii的多项式拿出来,因为这是必须计算的,可以单拿出来
编写技巧:
1.可以通过一些技巧将原本不可以使用单调队列优化的转换为这个模型
2.模型很可能只是内层的一维,外面还有维度,这时候我们使用的单调队列需要清空
3.注意单调队列与贪心的结合,很多时候是由贪心导出单调性
4.有些时候单调队列只能够维护决策集合,而不能高效的找出答案,这时候我们就需要其他的数据结构与单调队列建立映射关系,以此借另一个数据结构来快速找出答案,注意,单调队列增删,另一个数据结构也必须同步
5.可删堆可以用S T L < s e t > STL<set>STL<set>代替
6.单调队列解决问题维护一般分为三步:第一步:排出队头过于古老的决策,即超出了范围,第二步:取出队头决策更新状态。第三步:将此次更新的新状态作为以后的决策插入队列,插入时将所有比新决策坏的决策全部扔掉
7.单调队列内部其实是具有两段性的
8.对于如何猜性质,并且以此应用单调队列,我们可以用归纳法从反向思考要满足决策最优或者是某个决策必定不优,也或者演绎法直接硬钢(需要灵感)。当然需要注意的是我们可以先判断某两个决策相比较其中一个一定不优的情况,用数学归纳法一路推演到最优性(类比法)
例题感受
[SCOI2010]股票交易
题目描述
最近 lxhgww \text{lxhgww}lxhgww 又迷上了投资股票,通过一段时间的观察和学习,他总结出了股票行情的一些规律。
通过一段时间的观察,lxhgww \text{lxhgww}lxhgww 预测到了未来 T TT 天内某只股票的走势,第 i ii 天的股票买入价为每股 A P i AP_iAPi,第 i ii 天的股票卖出价为每股 B P i BP_iBPi(数据保证对于每个 i ii,都有 A P i ≥ B P i AP_i \geq BP_iAPi≥BPi),但是每天不能无限制地交易,于是股票交易所规定第 i ii 天的一次买入至多只能购买 A S i AS_iASi 股,一次卖出至多只能卖出 B S i BS_iBSi 股。
另外,股票交易所还制定了两个规定。为了避免大家疯狂交易,股票交易所规定在两次交易(某一天的买入或者卖出均算是一次交易)之间,至少要间隔 W WW 天,也就是说如果在第 i ii 天发生了交易,那么从第 i + 1 i+1i+1 天到第 i + W i+Wi+W 天,均不能发生交易。同时,为了避免垄断,股票交易所还规定在任何时间,一个人的手里的股票数不能超过 MaxP \text{MaxP}MaxP。
在第 1 11 天之前,lxhgww \text{lxhgww}lxhgww 手里有一大笔钱(可以认为钱的数目无限),但是没有任何股票,当然,T TT 天以后,lxhgww \text{lxhgww}lxhgww 想要赚到最多的钱,聪明的程序员们,你们能帮助他吗?
对于所有的数据,1 ≤ B P i ≤ A P i ≤ 1000 , 1 ≤ A S i , B S i ≤ MaxP 1\leq BP_i\leq AP_i\leq 1000,1\leq AS_i,BS_i\leq\text{MaxP}1≤BPi≤APi≤1000,1≤ASi,BSi≤MaxP
注意读题,我们很容易写出DP状态设计
设F [ i , j ] F[i,j]F[i,j]表示第i ii手里有j jj张股票的最大收益
那么我们现在有四种策
1.不买也不卖:
F [ i ] [ j ] = F [ i − 1 ] [ j ] F[i][j]=F[i-1][j]F[i][j]=F[i−1][j]
2.凭空买
F [ i ] [ j ] = − j × A P i F[i][j]=-j\times AP_iF[i][j]=−j×APi
3.从以前基础上买入:
F [ i ] [ j ] = max 1 ≤ k ≤ i − W − 1 , j − A S i ≤ x < j { F [ k ] [ x ] − ( j − x ) A P i } F[i][j]=\max_{1\le k\le i-W-1,j-AS_i\le x <j }\lbrace F[k][x]-(j-x)AP_i \rbraceF[i][j]=1≤k≤i−W−1,j−ASi≤x<jmax{F[k][x]−(j−x)APi}
4.从以前基础上卖出
F [ i ] [ j ] = max 1 ≤ k ≤ i − W − 1 , j < x ≤ j + B S i { F [ k ] [ x ] + ( x − j ) B P i } F[i][j]=\max_{1\le k\le i-W-1,j< x \le j+BS_i}\lbrace F[k][x]+(x-j)BP_i\rbraceF[i][j]=1≤k≤i−W−1,j<x≤j+BSimax{F[k][x]+(x−j)BPi}
观察方程式,我们会发现操作一,啥也不买F [ i ] [ j ] = F [ i − 1 ] [ j ] F[i][j]=F[i-1][j]F[i][j]=F[i−1][j]实际上是很有用的,因为它直接把前i ii天的最优解直接搬到了F [ i ] [ j ] F[i][j]F[i][j],以此满足了F FF数组的单调性(这就是我之前提到的编写技巧中的1),那么在操作3、4中的k kk也就不用枚举了,直接用k = i − W − 1 k=i-W-1k=i−W−1,以此我们省下了O ( T ) O(T)O(T)倍复杂度,但是目前复杂度O ( T M a x P 2 ) O(TMaxP^2)O(TMaxP2)仍然不足以通过本题,继续考虑优化
我们发现,将k = i − W − 1 k=i-W-1k=i−W−1带入方程3、4(以方程3为例,4同理),方程式会变成这样
F [ i ] [ j ] = max j − A S i ≤ x < j { F [ i − W − 1 ] [ x ] − ( j − x ) A P i } F[i][j]=\max_{j-AS_i\le x <j }\lbrace F[i-W-1][x]-(j-x)AP_i\rbraceF[i][j]=j−ASi≤x<jmax{F[i−W−1][x]−(j−x)APi}
对其进行变式,得到
F [ i ] [ j ] = max j − A S i ≤ x < j { F [ i − W − 1 ] [ x ] + x A P i } − j × A P i F[i][j]=\max_{j-AS_i\le x <j }\lbrace F[i-W-1][x]+xAP_i\rbrace-j\times AP_iF[i][j]=j−ASi≤x<jmax{F[i−W−1][x]+xAPi}−j×APi
观察这个式子,看出来了有木有!这就是我们上面提到的模型,准确的来说,随着j jj的每增大1,x xx的决策范围上下界都增大1,且F [ i − W − 1 ] [ x ] + x A P i F[i-W-1][x]+xAP_iF[i−W−1][x]+xAPi是一个已知量,我们可以以这个量为单调队列里的第二个限制(第一个是决策范围)
同样的,操作4也可以像这样使用单调队列优化,不过需要注意的是,由于操作4是增加操作,我们需要倒序枚举j jj
于是我们得到了一个O ( T M a x P ) O(TMaxP)O(TMaxP)的优秀算法,足以通过本题
#define max(a,b) (a)>(b)?(a):(b)
int n,m,ap,bp,as,bs,w,ans=0,f[2001][2001],l,r,q[2001];
int main(){
scanf("%d%d%d",&n,&m,&w);
memset(f,0x8f,sizeof(f));
for(int i=1;i<=n;i++){
scanf("%d%d%d%d",&ap,&bp,&as,&bs);
for(int j=0;j<=as;j++)f[i][j]=-j*ap;
for(int j=0;j<=m;j++)f[i][j]=max(f[i][j],f[i-1][j]);
if(i<=w)continue;
l=1,r=0;
for(int j=0;j<=m;j++){
while(l<=r&&q[l] < j-as)l++;
while(l<=r&&f[i-w-1][q[r]]+q[r]*ap<=f[i-w-1][j]+j*ap)r--;
q[++r]=j;
if(l<=r)f[i][j]=max(f[i][j],f[i-w-1][q[l]]+q[l]*ap-j*ap);
}
l=1,r=0;
for(int j=m;j>-1;j--){
while(l<=r&&q[l]>j+bs)l++;
while(l<=r&&f[i-w-1][q[r]]+q[r]*bp<=f[i-w-1][j]+j*bp)r--;
q[++r]=j;
if(l<=r)f[i][j]=max(f[i][j],f[i-w-1][q[l]]+q[l]*bp-j*bp);
}
}
printf("%d\n",f[n][0]);
return 0;
}
裁剪序列
题面:给定一个长度为 N NN 的序列 A AA,要求把该序列分成若干段,在满足“每段中所有数的和”不超过 M MM 的前提下,让“每段中所有数的最大值”之和最小。
试计算这个最小值。
序列A AA中所有值非负
看题目,提取关键信息:1.序列的长度2.每段和不超过M MM
于是我们可以设计出DP的状态:设f [ i ] f[i]f[i]表示前i ii个序列分成若干段,每段所有数的最大值之和的最小值
则有状态转移方程:
f [ i ] = min j < i , ∑ p = j + 1 i A [ p ] ≤ M { f [ j ] + max j < k ≤ i A [ k ] } f[i]=\min_{j<i,\sum_{p=j+1}^iA[p]\le M}{\lbrace f[j]+\max_{j< k \le i}{A[k]} \rbrace}f[i]=j<i,∑p=j+1iA[p]≤Mmin{f[j]+j<k≤imaxA[k]}
考虑优化:和的处理很明显可以用前缀和,这个式子很容易看出来f ff具有单调性
这时候我们因为有了单调性,所以可以考虑使用单调队列
下面我们分析两个决策的优劣,设k 1 , k 2 k1,k2k1,k2是f [ i ] f[i]f[i]的两个不同决策( k 1 < k 2 ) (k1<k2)(k1<k2),且都满足段和小于等于M MM,
试比较右式大小,分别是f [ k 1 ] + max k 1 < k ≤ i A [ k ] f[k1]+\max_{k1<k\le i}{A[k]}f[k1]+maxk1<k≤iA[k],f [ k 2 ] + max k 2 < k ≤ i A [ k ] f[k2]+\max_{k2<k\le i}{A[k]}f[k2]+maxk2<k≤iA[k]
我们发现,因为f ff是非严格单调递增的,于是乎,当max k 1 < k ≤ i A [ k ] ≤ max k 2 < k ≤ i A [ k ] \max_{k1<k\le i}A[k]\le \max_{k2<k\le i}A[k]maxk1<k≤iA[k]≤maxk2<k≤iA[k]
但因为若此式成立,当且仅当不等式取等号,于是乎,运用上文提到的数学归纳法,容易得到:
引理:决策k 1 k1k1是最优决策的必要条件除了∑ p = k 1 + 1 i A [ p ] ≤ M \sum_{p=k1+1}^iA[p]\le M∑p=k1+1iA[p]≤M之外,必定满足以下二者条件之一:
1.A [ k 1 ] = max q = k 1 i A [ q ] A[k1]=\max_{q=k1}^iA[q]A[k1]=maxq=k1iA[q]
2.∑ q = k 1 i A [ q ] > M \sum_{q=k1}^iA[q]>M∑q=k1iA[q]>M,即k 1 k1k1是满足条件∑ p = k 1 + 1 i A [ p ] ≤ M \sum_{p=k1+1}^iA[p]\le M∑p=k1+1iA[p]≤M的最小的决策
小总结:在这道题的结论猜测推导中,我们先是将两个决策作比较,这是运用单调队列优化寻找性质的常用手段,然后进行化一般为特殊,找到满足条件的特殊情况,对此运用归纳法进行倒推,得到一定性质之后大胆猜想,从而使用数学归纳法得出结论,在这里,我们其实也可以运用反证法以演绎法的思路去推导得出结论。反正就是列出状态相关不等式,从中找到性质
于是乎,我们有了这两个性质之后,便可以应用单调队列优化了
需要注意的是,对于性质2,我们可以使用双指针O ( n ) O(n)O(n)快速扫描即可得出答案,下面讨论如何维护性质1
表面上看,一个区间最值,可以直接上S T STST表,然后对这两个条件满足的决策(2个)进行比对便可得出解这就不用单调队列了
当然,我们为了追求时间的绝对快速,使用单调队列,根据引理,对于一个新决策j 2 j_2j2,若其与队尾决策j 1 j_1j1相比,j 1 < j 2 并且 A [ j 2 ] ≥ A [ j 1 ] j_1 < j_2\text{并且}A[j_2] \ge A[j_1]j1<j2并且A[j2]≥A[j1],则j 1 j_1j1便是一个无用决策,直接删掉,需要注意的是,我们只是保证了队列的单调性,但右边式子的单调性无法保证,于是我们需要建立一个可支持插入删除查询最大值的结构(比如二叉堆或者平衡树set),对此保持一样的决策集合,从另一个数据结构里拿出答案。还有就是,因为队列有单调性,所以满足性质1的就是队列里的下一个元素的A值
代码中采用set
#define ll long long
using namespace std;
int n,a[100010],c[100010],q[100010];
ll m,f[100010];
multiset<ll> s;
int main(){
scanf("%d%lld",&n,&m);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
ll sum=0;
for(int i=1,j=0;i<=n;i++){
sum+=a[i];
while(sum>m)sum-=a[j+1],j++;
c[i]=j;
}
int l=1,r=0;
for(int i=1;i<=n;i++){
while(l<=r&&q[l]<=c[i])
s.erase(f[q[l]]+a[q[++l]]);
while(l<=r&&a[q[r]]<=a[i])
s.erase(f[q[r-1]]+a[q[r--]]);
if(l<=r)s.insert(f[q[r]]+a[i]);
q[++r]=i;
f[i]=f[c[i]]+a[q[l]];
if(!s.empty())f[i]=min(f[i],*s.begin());
}
printf("%lld",f[n]);
}
单调队列优化多重背包
多重背包模型:有N NN种物品,每种有C [ i ] C[i]C[i]个,每个价值为W [ i ] W[i]W[i],体积为V [ i ] V[i]V[i],从中选出若干个放入容量为M MM的背包,使放入权值最大化
我们这样来思考,既然要使用单调队列优化多重背包,那么我们需要寻找决策集合的重叠性
我们循环的时候,在同一个外层i ii的循环内部,j − V [ i ] j-V[i]j−V[i]与j jj关于V [ i ] V[i]V[i]的决策集合是重叠的,只不过加上了V [ i ] V[i]V[i]这个决策,删去了j − C [ i ] V [ i ] − V [ i ] j-C[i]V[i]-V[i]j−C[i]V[i]−V[i]这个决策,对于这个过程,我们就可以使用单调队列优化,详细的说,我们对所有的状态j jj进行分组,按照模V [ i ] V[i]V[i]的值来分组,这样我们就对每一组都实行单调队列优化,因为在同一个阶段,所以这些状态不会互相干扰,于是,我们可以对每一组单独进行DP,DP完成后就可以了
详细的说,我们把倒序循环j jj的过程改为对模V [ i ] V[i]V[i]得到的值u ∈ [ 0 , V [ i ] − 1 ] u\in[0,V[i]-1]u∈[0,V[i]−1],倒序循环p = ⌊ ( M − u ) / V [ i ] ⌋ ∼ 0 p=\lfloor(M-u)/V[i]\rfloor\sim 0p=⌊(M−u)/V[i]⌋∼0,所对应的状态就是f [ u + p ∗ V [ i ] ] f[u+p*V[i]]f[u+p∗V[i]],决策候选集合就是p − C [ i ] ≤ k ≤ p − 1 p-C[i]\le k\le p-1p−C[i]≤k≤p−1,写出新的状态转移方程
f [ u + p ∗ V [ i ] ] = max p − C [ i ] ≤ k ≤ p − 1 { f [ u + k ∗ V [ i ] ] + W [ i ] ∗ ( p − k ) } f[u+p*V[i]]=\max_{p-C[i]\le k\le p-1}\lbrace f[u+k*V[i]]+W[i]*(p-k)\rbracef[u+p∗V[i]]=p−C[i]≤k≤p−1max{f[u+k∗V[i]]+W[i]∗(p−k)}
运用单调队列进行优化即可
// 单调队列优化多重背包
int n, m, V[210], W[210], C[210];
int f[20010], q[20010];
int calc(int i, int u, int k) {
return f[u + k*V[i]] - k*W[i];
}
int main() {
cin >> n >> m;
memset(f, 0xcf, sizeof(f)); // -INF
f[0] = 0;
// 物品种类
for (int i = 1; i <= n; i++) {
scanf("%d%d%d", &V[i], &W[i], &C[i]);
// 除以V[i]的余数
for (int u = 0; u < V[i]; u++) {
// 建立单调队列
int l = 1, r = 0;
// 把最初的候选集合插入队列
int maxp = (m - u) / V[i];
for (int k = maxp - 1; k >= max(maxp - C[i], 0); k--) {
while (l <= r && calc(i, u, q[r]) <= calc(i, u, k)) r--;
q[++r] = k;
}
// 倒序循环每个状态
for (int p = maxp; p >= 0; p--) {
// 排除过时决策
while (l <= r && q[l] > p - 1) l++;
// 取队头进行状态转移
if (l <= r)
f[u + p*V[i]] = max(f[u + p*V[i]], calc(i, u, q[l]) + p*W[i]);
// 插入新决策,同时维护队尾单调性
if (p - C[i] - 1 >= 0) {
while (l <= r && calc(i, u, q[r]) <= calc(i, u, p - C[i] - 1)) r--;
q[++r] = p - C[i] - 1;
}
}
}
}
int ans = 0;
for (int i = 1; i <= m; i++) ans = max(ans, f[i]);
cout << ans << endl;
}
斜率优化DP
这里推荐一个博客
【学习笔记】动态规划—各种 DP 优化
前置知识
平面直角坐标系内,两点连线的斜率:y 1 − y 2 x 1 − x 2 \dfrac{y_1 - y_2}{x_1 - x_2}x1−x2y1−y2。
Ⅰ 状态转移方程
列出状态转移方程,如果化简为以下的形式:
d p ( i ) = min 或 max ( a ( i ) × b ( j ) + c ( i ) + d ( j ) + C ) dp(i) = \min\text{或}\max(a(i) \times b(j) + c(i) + d(j)+C)dp(i)=min或max(a(i)×b(j)+c(i)+d(j)+C)
就可以考虑斜率优化DP。
需要注意的是:
c ( i ) c(i)c(i) 与 d ( i ) d(i)d(i) (之一)可能不存在,但必须存在 a ( i ) × b ( j ) a(i) \times b(j)a(i)×b(j) 才能斜率优化
a ( i ) , b ( j ) , c ( i ) , d ( j ) a(i),b(j),c(i),d(j)a(i),b(j),c(i),d(j)表示只和 i ii 或 j jj 有关的函数,下面写作 ( f 1 ( i ) + f 2 ( i ) + . . . ) (f_1(i) + f_2(i) + ...)(f1(i)+f2(i)+...) 等
大写 C CC 表示常数
此时时间复杂度 O ( n 2 ) O(n^2)O(n2),毒瘤们很不爽。
先去掉 min / max \min/\maxmin/max。
将只有 i ii ,只有 j jj 和 i , j i,ji,j 杂糅的项分别合并:
d p ( i ) = C + ( f 1 ( i ) + f 2 ( i ) + . . . ) + ( g 1 ( j ) + g 2 ( j ) + . . . ) + ( h 1 ( i ) + h 2 ( i ) + . . . ) × ( p 1 ( j ) + p 2 ( j ) + . . . ) dp(i) = C+(f_1(i) + f_2(i) + ...) + (g_1(j) + g_2(j) + ...) +(h_1(i) + h_2(i) + ...) \times (p_1(j) + p_2(j) + ...)dp(i)=C+(f1(i)+f2(i)+...)+(g1(j)+g2(j)+...)+(h1(i)+h2(i)+...)×(p1(j)+p2(j)+...)
Ⅱ 决策点关系
我们可以分析:如果存在 j 1 , j 2 j_1,j_2j1,j2 使得 j 2 j_2j2 优于 j 1 j_1j1(min \minmin对应F ( j 1 ) > F ( j 2 ) F(j_1)> F(j_2)F(j1)>F(j2) ,反之为 F ( j 1 ) < F ( j 2 ) F(j_1)< F(j_2)F(j1)<F(j2),F ( j x ) F(j_x)F(jx) 表示 min / max \min/\maxmin/max 里在j jj取j x j_xjx时的值),j 1 , j 2 j1,j2j1,j2 会有什么关系。
C + ( f 1 ( i ) + f 2 ( i ) + . . . ) + ( g 1 ( j 1 ) + g 2 ( j 1 ) + . . . ) + ( h 1 ( i ) + h 2 ( i ) + . . . ) × ( p 1 ( j 1 ) + p 2 ( j 1 ) + . . . ) \boxed{C+(f_1(i) + f_2(i) + ...)} + (g_1(j_1) + g_2(j_1) + ...) +(h_1(i) + h_2(i) + ...) \times (p_1(j_1) + p_2(j_1) + ...)C+(f1(i)+f2(i)+...)+(g1(j1)+g2(j1)+...)+(h1(i)+h2(i)+...)×(p1(j1)+p2(j1)+...)
小于或大于
C + ( f 1 ( i ) + f 2 ( i ) + . . . ) + ( g 1 ( j 2 ) + g 2 ( j 2 ) + . . . ) + ( h 1 ( i ) + h 2 ( i ) + . . . ) × ( p 1 ( j 2 ) + p 2 ( j 2 ) + . . . ) \boxed{C+(f_1(i) + f_2(i) + ...)} + (g_1(j_2) + g_2(j_2) + ...) +(h_1(i) + h_2(i) + ...) \times (p_1(j_2) + p_2(j_2) + ...)C+(f1(i)+f2(i)+...)+(g1(j2)+g2(j2)+...)+(h1(i)+h2(i)+...)×(p1(j2)+p2(j2)+...)
( g 1 ( j 1 ) + g 2 ( j 1 ) + . . . ) + ( h 1 ( i ) + h 2 ( i ) + . . . ) × ( p 1 ( j 1 ) + p 2 ( j 1 ) + . . . ) (g_1(j_1) + g_2(j_1) + ...) +(h_1(i) + h_2(i) + ...) \times (p_1(j_1) + p_2(j_1) + ...)(g1(j1)+g2(j1)+...)+(h1(i)+h2(i)+...)×(p1(j1)+p2(j1)+...)
小于或大于
( g 1 ( j 2 ) + g 2 ( j 2 ) + . . . ) + ( h 1 ( i ) + h 2 ( i ) + . . . ) × ( p 1 ( j 2 ) + p 2 ( j 2 ) + . . . ) (g_1(j_2) + g_2(j_2) + ...) +(h_1(i) + h_2(i) + ...) \times (p_1(j_2) + p_2(j_2) + ...)(g1(j2)+g2(j2)+...)+(h1(i)+h2(i)+...)×(p1(j2)+p2(j2)+...)
令:
( g 1 ( x ) + g 2 ( x ) + . . . ) = Y ( x ) (g_1(x) + g_2(x) + ...) = Y(x)(g1(x)+g2(x)+...)=Y(x)
( h 1 ( i ) + h 2 ( i ) + . . . ) = k 0 (h_1(i) + h_2(i) + ...) = k_0(h1(i)+h2(i)+...)=k0
( p 1 ( x ) + p 2 ( x ) + . . . ) = X ( x ) (p_1(x) + p_2(x) + ...) = X(x)(p1(x)+p2(x)+...)=X(x)
Y ( j 1 ) + k 0 × X ( j 1 ) 大于或小于 Y ( j 2 ) + k 0 × X ( j 2 ) Y(j_1) + k_0 \times X(j1) \text{大于或小于} Y(j_2) + k_0 \times X(j_2)Y(j1)+k0×X(j1)大于或小于Y(j2)+k0×X(j2)
− k 0 大于或小于 Y ( j 2 ) − Y ( j 1 ) X ( j 2 ) − X ( j 1 ) -k_0 \text{大于或小于} \dfrac{Y(j_2) - Y(j_1)}{X(j_2) - X(j_1)}−k0大于或小于X(j2)−X(j1)Y(j2)−Y(j1)
当上述不等式成立时,j 2 j_2j2 优于 j 1 j_1j1。
注:推式子时记得让 X ( j 2 ) > X ( j 1 ) X(j_2)>X(j_1)X(j2)>X(j1),乱做不等式乘法的小朋友是长不大的qwq
Ⅲ 凸壳
为方便计算,将 k 0 k_0k0 先赋值为 k 0 × − 1 k_0 \times -1k0×−1
仔细观察,上述不等式很像斜率式(所以是字母k kk)。
假设有三个决策点的 Y , X Y,XY,X 组成点 A , B , C A,B,CA,B,C。
A B ABAB斜率k 1 k_1k1,B C BCBC斜率k 2 k_2k2。
当 k 1 > k 2 k_1 > k_2k1>k2 时
如图: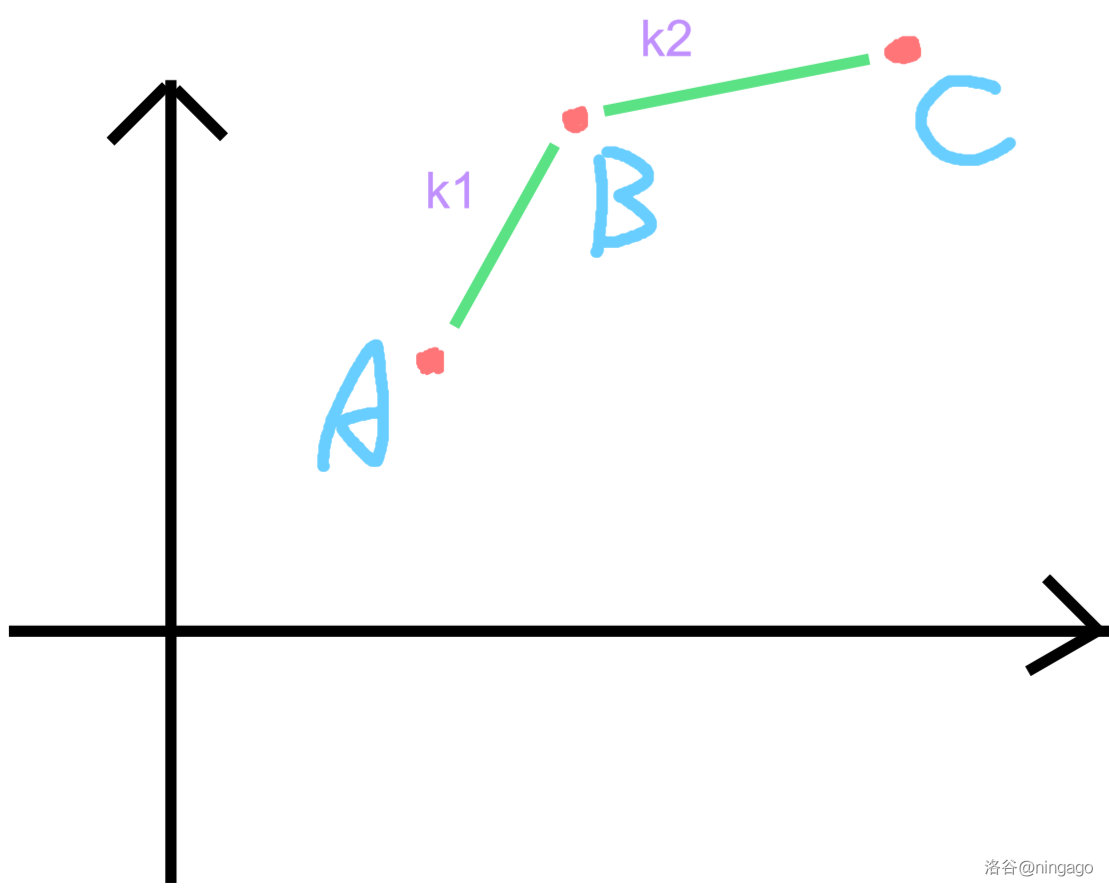
如果不等式符号为 > >> :
k 0 > k 1 k_0 > k_1k0>k1 时,B BB 优于 A AA,反之 A AA 优于 B BB。
k 0 > k 2 k_0 > k_2k0>k2 时,C CC 优于 B BB,反之 B BB 优于 C CC。
有三种情况:
k 0 > k 1 > k 2 k_0 > k_1 > k_2k0>k1>k2 ,C CC 优于 B BB 优于 A AA。
k 1 > k 0 > k 2 k_1 > k_0 > k_2k1>k0>k2 ,A AA 和 C CC 优于 B BB。
k 1 > k 2 > k 0 k_1 > k_2 > k_0k1>k2>k0 ,A AA 优于 B BB 优于 C CC。
综上所述,B BB 永远不会成为决策点,如下图: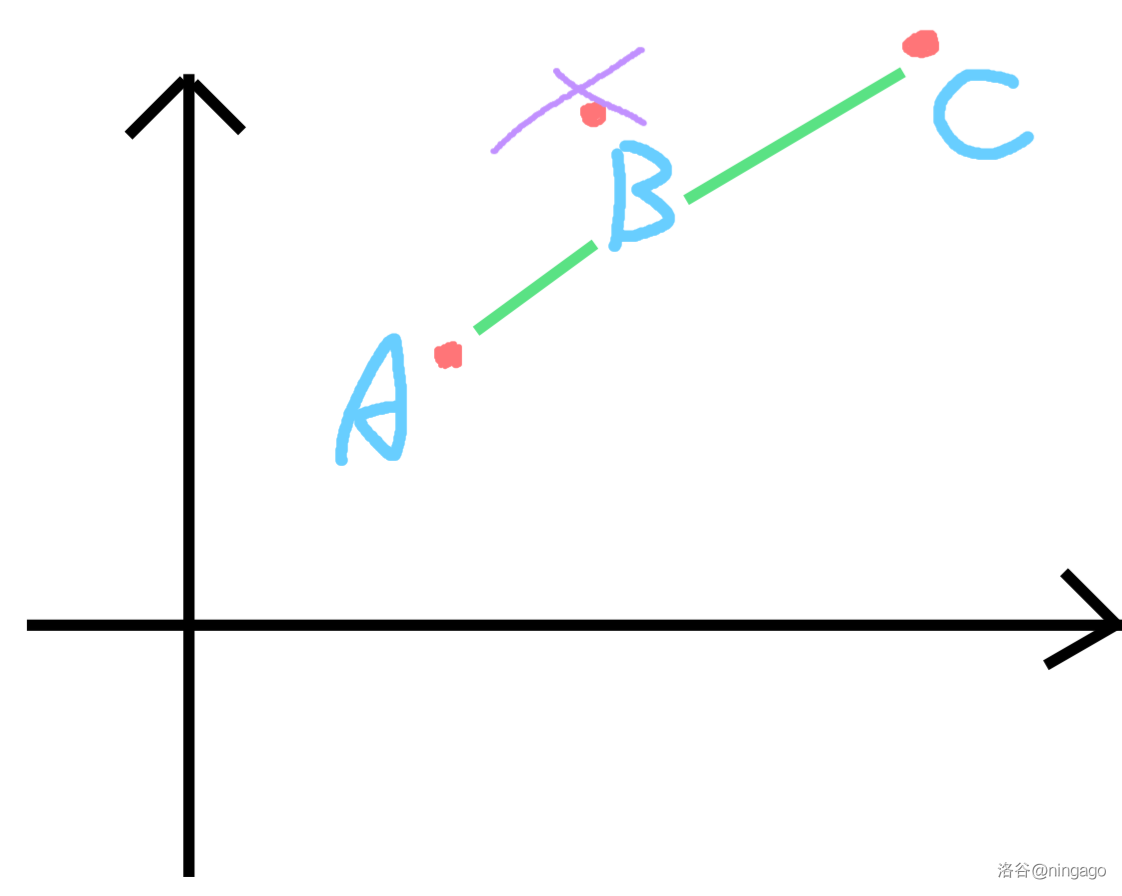
不难发现,可能成为决策点的点形成了一个下凸壳:
如果不等式符号为 ≤ \le≤ :
啥也研究不出……
当 k 1 < k 2 k_1 < k_2k1<k2 时
思路同上,如图: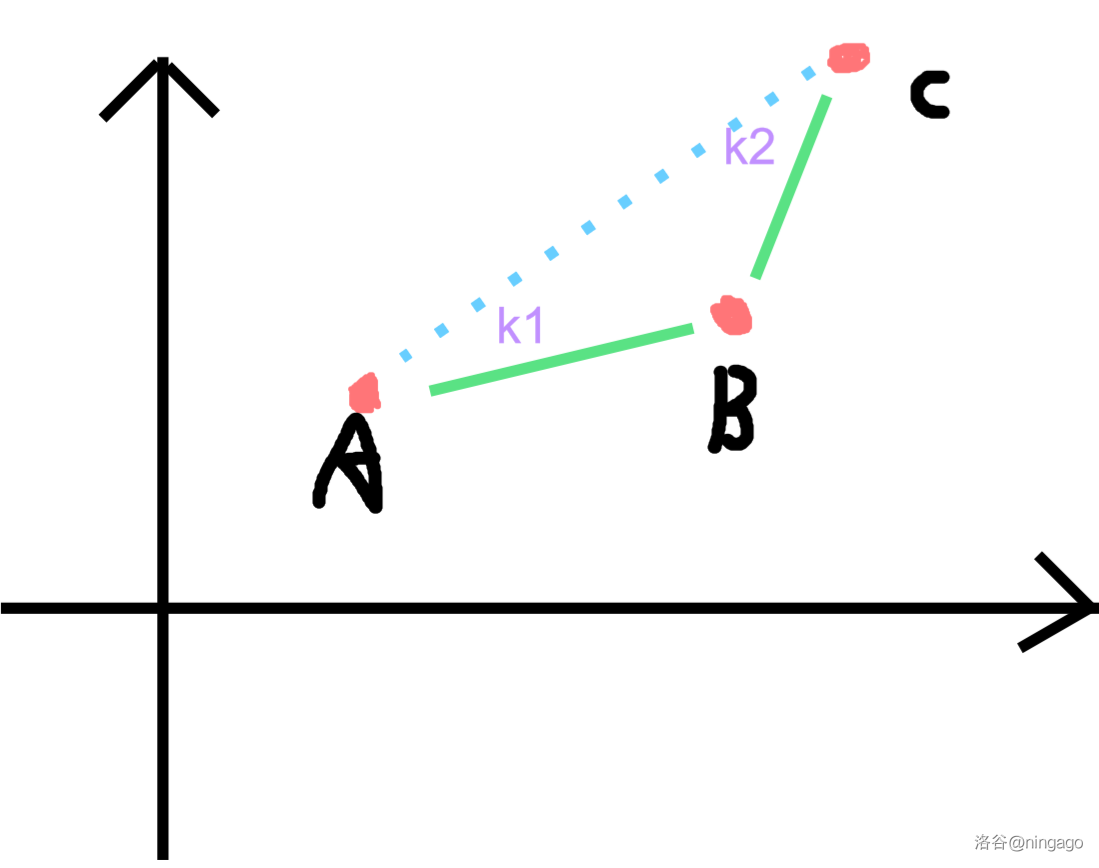
如果不等式符号为 ≤ \le≤ :
同理,但形成上凸壳,不再证明。
总结:取min时使用下凸壳,取max时使用上凸壳
于是当min时我们维护一个斜率单调递增的点集,max时维护一个斜率单调递减的点集
如果不等式符号为 ≥ \ge≥ :
啥也研究不出……
Ⅳ 维护答案
求值
下文默认下凸壳。
假设平面上已经维护了一个凸壳,现在需要知道 d p i dp_idpi,假设 i ii 对应的 k 0 k_0k0 是图中红线。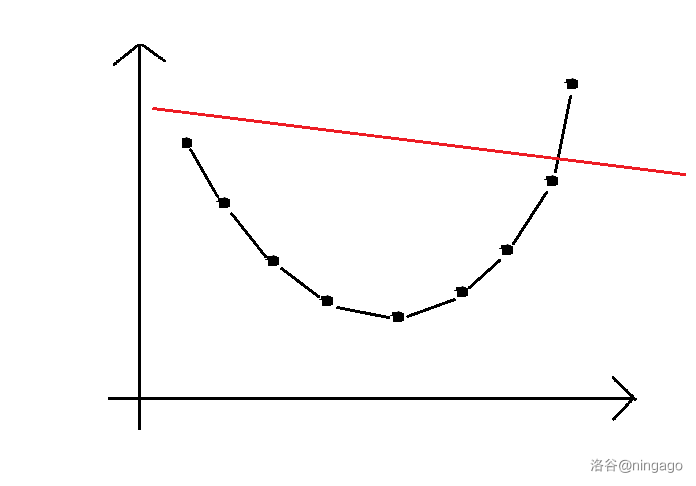
用眼睛可以看出五号点就是我们需要的决策点: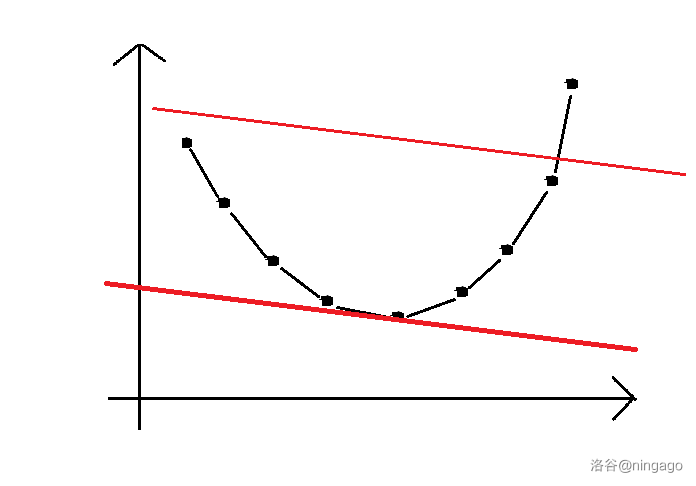
设维护出凸包的点集为 { ( x i , y i ) } ( i ∈ [ 1 , m ] ) \{(x_i,y_i)\}(i\in [1,m]){(xi,yi)}(i∈[1,m]),m mm 为集合大小。
由于凸壳的性质(默认下凸),这些点满足:y i − y i + 1 x i − x i + 1 ≤ y j − y j + 1 x j − x j + 1 \dfrac{y_i-y_{i+1}}{x_i-x_{i+1}}\le\dfrac{y_j-y_{j+1}}{x_j-x_{j+1}}xi−xi+1yi−yi+1≤xj−xj+1yj−yj+1,其中 i < j , i 和 j ∈ [ 1 , m ) i<j,i\text{ 和 }j\in [1,m)i<j,i 和 j∈[1,m)。
注意到优劣满足传递性,即如果 A AA 优于 B ( A < B ) B\ (A<B)B (A<B),那么 ∀ B < C , A \forall B<C,A∀B<C,A 优于 C CC。
因此,可以使用二分,O ( log n ) O(\log n)O(logn) 得到答案。
初始化将 l , r l,rl,r 设为 1 , m − 1 1,m-11,m−1(m − 1 m-1m−1 是因为 m mm 个点连 m − 1 m-1m−1 条线),二分的决策点先赋为一个不存在的指,并计算出 k 0 k_0k0:
int l = 1,r = m - 1,j = -0x3f3f3f3f
k0 = xxx
如果此时 m i d midmid 优于 m i d + 1 mid+1mid+1,就把答案 j jj 更新为 m i d midmid,移动右端点。反之移动左端点
while(l <= r)
{
ll mid = l + r >> 1;
// >=
if(k0 * (X(mid + 1) - X(mid)) <= (Y(mid + 1) - Y(mid)))
r = mid - 1,j = mid;
else
l = mid + 1;
}
如果二分结束后,j = 0x3f3f3f3f j=\texttt{0x3f3f3f3f}j=0x3f3f3f3f,那么说明切点在 [ 1 , m − 1 ] [1,m-1][1,m−1] 之外的那个点上,也就是 m mm 号点,此时将 j jj 赋值为 m mm。
if(j == -0x3f3f3f3f)
j = m;
然后根据转移方程填充 d p i dp_idpi 即可。
注:维护的数据结构不同,需要适当地改变二分模板。
加点
也就是把一个点(( X i , Y i ) (X_i,Y_i)(Xi,Yi))塞入凸包里
动态凸包问题可以使用平衡树或CDQ分治解决。
笔者不擅长CDQ,这里介绍平衡树做法:
(本段默认下凸,不会平衡树可跳过此段)
① 判断点是否在凸壳内部
如图所示:如果以该点为观测点,该点的前驱在后继的顺时针方向,那么就说明在凸壳内部(上凸对应逆时针),反之就在外部。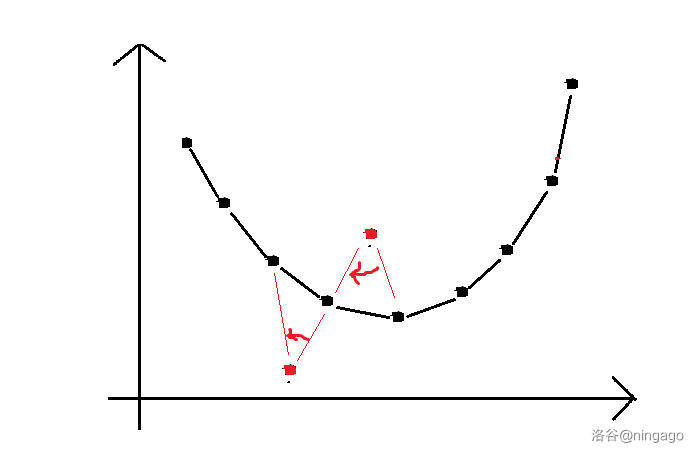
特殊地,没有前驱或后继相当于在外部。
下面是 ``set` 实现的伪代码
struct node
{
int x,y;
node operator - (const node &B)const
{
return (node){x - B.x,y - B.y};
}
int operator * (const node &B)const
{
return x * B.y - y * B.x;
}
bool operator < (const node &B)const
{
return (x != B.x) ? x < B.x : y > B.y;
}
};
multiset<node>s;
#define sit multiset<node>::iterator
顺逆时针叉积判断即可
bool inside(sit p)
{
if(p == s.begin())
return 0;
sit nx = next(p);
if(nx == s.end())
return 0;
sit pre = prev(p);
return ((*pre - *p) * (*nx - *p)) > 0;
// <
}
②加点
很明显,如果该点在凸壳内部,就无需加入凸壳(永远不可能成为决策点)
void ins(node t)
{
sit p = s.insert(t);
if(inside(p))
{
s.erase(p);
return;
}
...
否则先将点加入凸壳,再while判断前驱后继要不要删去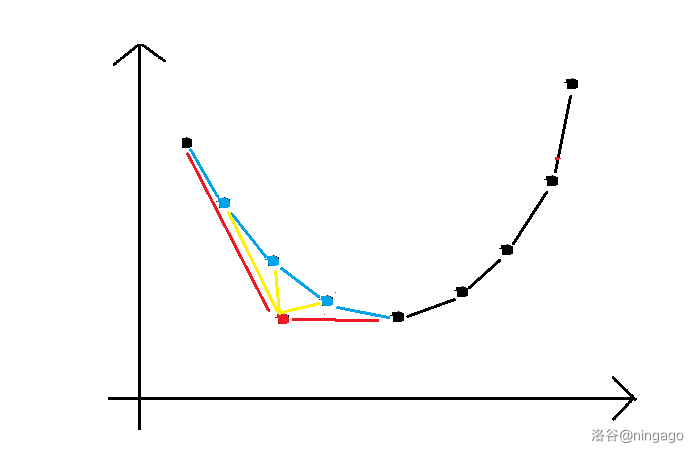
while(p != s.begin() && inside(prev(p)))
s.erase(prev(p));
while(next(p) != s.end() && inside(next(p))
s.erase(next(p));
}
(由于set不好自定义二分,一般使用 Splay或fhq以方便二分。
Ⅴ 特殊性
然而大部分题目都用不着上述算法,因为有一些奇妙的单调性:
如果 k 0 k_0k0 是单调(下凸对应上升,上凸对应下降)的,说明决策点随着 i ii 的增大而增大,此时可以使用一个双端队列来维护,避免了二分的过程。
先计算出 i ii 点的 k 0 k_0k0。
while(hh < tt && k0 >= K(q[hh],q[hh + 1]))
// <=
hh++;
ll j = q[hh];
dp[i] = /**/;
暴力找到决策点,不同于暴力的是不符合条件的点直接弹出队列。
由于每个节点只会被插入和删除一次,统计答案的时间复杂度加速为 O ( n ) O(n)O(n)
如果 X i X_iXi 是单调的,意味着每次插入点都是在凸包后(前)面,如图(红点为新加点,蓝点为被删点):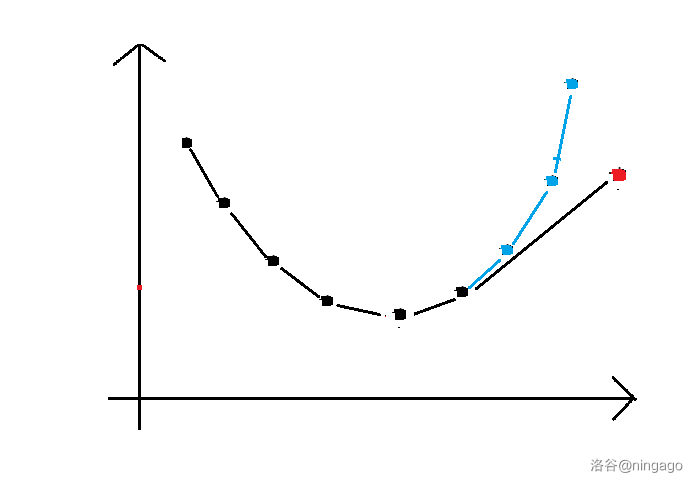
这样使得在平衡树中,每次插入点都是在平衡树尾部,也就是说没有必要使用平衡树了,使用栈即可(结合 k 0 k_0k0 单调就变成了双端队列)。
由单调性可知,i ii 一定在原凸壳外部。
while(hh < tt && K(q[tt - 1],q[tt]) >= K(q[tt - 1],i))
// <=
tt--;
q[++tt] = i;
把不符合凸性的点直接出队,最后将 i ii 入队。
在凸包最后加点。
加点的时间复杂度加速为 O ( n ) O(n)O(n)
Ⅵ 模板Code
二分(X i X_iXi 单调,k 0 k_0k0 不单调):
#include <cstdio>
#define N 300010
#define ll long long
ll q[N],hh = 1,tt = 1;
inline ll Y(ll x){
return /**/;
}
inline ll X(ll x){
return /**/;
}
int main(){
/*输入*/
for(ll i = 1;i <= n;i++){
ll k0 = /**/;
ll l = hh,r = tt - 1,j = -0x3f3f3f3f;
while(l <= r){
ll mid = l + r >> 1;
// >=
if(k0 * (X(q[mid + 1]) - X(q[mid])) <= (Y(q[mid + 1]) - Y(q[mid])))
r = mid - 1,j = q[mid];
else
l = mid + 1;
}
if(j == -0x3f3f3f3f)
j = q[tt];
dp[i] = /**/;
while(hh < tt && (Y(i) - Y(q[tt])) * (X(q[tt]) - X(q[tt - 1])) <= (Y(q[tt]) - Y(q[tt - 1])) * (X(i) - X(q[tt])))
// >=
tt--;
q[++tt] = i;
}
/*输出*/
return 0;
}
都单调:
#include <cstdio>
#include <iostream>
#include <cstring>
#define ll long long
#define N 50005
using namespace std;
ll n,dp[N],q[N];
inline ll X(ll x){
return /**/;
}
inline ll Y(ll x){
return /**/;
}
inline double K(ll j1,ll j2){
double res = (double)(Y(j2) - Y(j1)) / (double)(X(j2) - X(j1));
return res;
}
int main(){
/*输入*/
ll hh = 1,tt = 1;
for(ll i = 1;i <= n;i++){
ll k0 = /**/;
while(hh < tt && k0 >= K(q[hh],q[hh + 1]))
// <=
hh++;
ll j = q[hh];
dp[i] = /**/;
while(hh < tt && K(q[tt - 1],q[tt]) >= K(q[tt - 1],i))
// <=
tt--;
q[++tt] = i;
}
/*输出*/
return 0;
}
Ⅶ 注意事项
ⅰ 有时将除法写成乘法以保证精度
ⅱ 有时,d p dpdp 数组为多维,也就是 d p [ i ] [ j ] dp[i][j]dp[i][j] ,此时可考虑将 i , j i,ji,j 都枚举,再找 j jj 的决策点 k kk 也是可行的
ⅲ 注意初值,从 0 00 号点(也就是从头)转移有时要提前在凸壳里加入 { 0 , 0 } \{0,0\}{0,0} 等初值
ⅳ 对于一些题目,X ( j 2 ) − X ( j 1 ) = 0 X(j2) - X(j1) = 0X(j2)−X(j1)=0,此时再做除法直接上天,建议写成 X(j2) - X(j1) == 0 ? eps : X(j2) - X(j1),e p s epseps 为极小值,例如 1 e − 8 1e-81e−8
ⅴ注意要维护严格凸的凸壳,而不是下面这样(共线)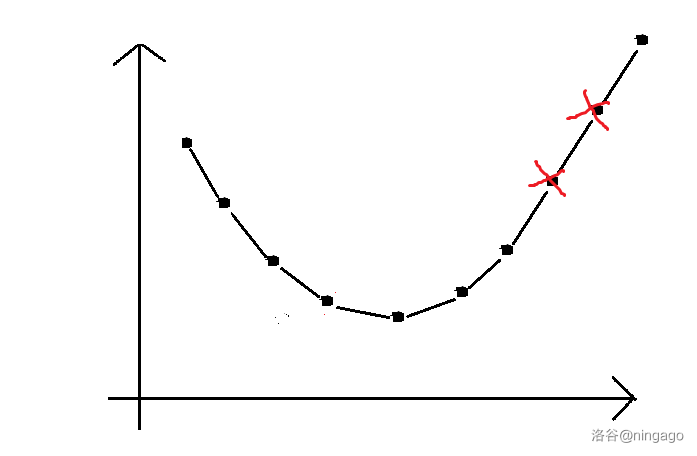
不然就会WA得莫名其妙
ⅵ 加点和统计答案是两个不同的事件,不是所有题目都统计完就加点
ⅶ 凸包维护有时不止一个,具体问题具体分析
Ⅷ 例题
注:此上内容大部分摘自洛谷日报409
K匿名序列
题意给出一个长度为 n nn的非严格递增整数序列,每次操作可以将其中的一个数减少一,问最少多少次操作后能够使得序列中的任何一个数在序列中都至少有 k − 1 k−1k−1 个数与之相同。
分析:由于操作只能够进行减少,于是很容易的我们就可以重新描述这个问题
对一个长度为 n nn 的非严格递增整数序列,将其分成若干段,使得每一段的长度不小于k kk,并把每一段都变成段内的最小数,求需要减少的值的总和的最小值,设这个序列为A AA
很轻松的可以设计出状态,设F [ i ] F[i]F[i]表示前i ii个数分成若干段,使得每一段的长度不小于k kk,并把每一段都变成段内的最小数,求需要减少的值的总和的最小值
设S [ i ] = ∑ j = 1 i A [ j ] S[i]=\sum_{j=1}^iA[j]S[i]=∑j=1iA[j]
有状态转移方程:
f [ i ] = min j ≤ i − k { f [ j ] + ( S [ i ] − S [ j ] ) − ( i − j ) × A [ j + 1 ] } f[i]=\min_{j\le i-k}\lbrace f[j]+(S[i]-S[j])-(i-j)\times A[j+1] \rbracef[i]=j≤i−kmin{f[j]+(S[i]−S[j])−(i−j)×A[j+1]}
我们发现,状态转移方程里只含有常数项,关于i ii或j jj的一次项,和i , j i,ji,j的乘积项,于是考虑斜率优化
去掉min \minmin函数,进行变式,将只含j的项移到右边,将其余的移到左边
得到:
f [ j ] − S [ j ] + j × A [ j + 1 ] = f [ i ] − S [ i ] + i × A [ j + 1 ] f[j]-S[j]+j\times A[j+1]=f[i]-S[i]+i\times A[j+1]f[j]−S[j]+j×A[j+1]=f[i]−S[i]+i×A[j+1]
进一步变式:
f [ j ] − S [ j ] + j × A [ j + 1 ] = i × A [ j + 1 ] + f [ i ] − S [ i ] f[j]-S[j]+j\times A[j+1]=i\times A[j+1]+f[i]-S[i]f[j]−S[j]+j×A[j+1]=i×A[j+1]+f[i]−S[i]
我们设X ( j ) = A [ j + 1 ] , Y ( j ) = f [ j ] − S [ j ] + j × A [ j + 1 ] , B ( j ) = f [ j ] − S [ j ] X(j)=A[j+1],Y(j)=f[j]-S[j]+j\times A[j+1],B(j)=f[j]-S[j]X(j)=A[j+1],Y(j)=f[j]−S[j]+j×A[j+1],B(j)=f[j]−S[j]
那么状态转移方程可以改写为:
F [ i ] = Y ( j ) − i × X ( j ) + S [ i ] F[i]=Y(j)-i\times X(j)+S[i]F[i]=Y(j)−i×X(j)+S[i]
同理,上面的变式也可以写作:
Y ( j ) = i × X ( j ) + B ( i ) Y(j)=i\times X(j)+B(i)Y(j)=i×X(j)+B(i)
此时:这就是一个直线的点斜式方程,其中i ii为斜率,B ( i ) B(i)B(i)为截距,对应到平面直角坐标系中的话这就代表点( i × A [ j + 1 ] , f [ j ] − S [ j ] + j × A [ j + 1 ] ) (i\times A[j+1],f[j]-S[j]+j\times A[j+1])(i×A[j+1],f[j]−S[j]+j×A[j+1])
事实上,运用斜率优化的时候我们经常通过定义函数X , Y , B X,Y,BX,Y,B表示x坐标,y坐标以及常数项,将其化为直线的点斜式方程,然后比较决策进行下一步处理
下面我们来比较三个决策:j 1 , j 2 , j 3 ( j 1 < j 2 < j 3 ) j_1,j_2,j_3(j_1<j_2<j_3)j1,j2,j3(j1<j2<j3)
就如上面分析的那样,记直线j 1 , j 2 j_1,j_2j1,j2的斜率为k 1 k_1k1,j 2 , j 3 j_2,j_3j2,j3的斜率为k 2 k_2k2,当然我们最初的状态转移方程里的斜率记作k 0 = i k_0=ik0=i
很明显,当k 1 > k 2 k_1>k_2k1>k2时,j 2 j_2j2是一个不可能的决策,此时图像呈上凸,于是的,我们需要维护一个斜率单调递增,并且决策下标也是单调递增的决策集合,事实上关于min \minmin函数的状态转移方程一般是维护单调递增的决策集合,max \maxmax函数反之,因为本题比较简单A AA和S SS都是具备单调性的,于是我们不需要去维护整个凸包,也不需要去二分,不需要动态加点,一个普普通通的就好
于是我们可以使用单调队列维护这个决策集合,记这个队列为q
1.检查队头:当队头两个决策的斜率小于等于i ii的时候将队头出队 (等于的时候是队头两个元素等价,为了维护凸包的严格单调性,必须删,否则会出现奇奇怪怪的错误)
2.更新答案f [ i ] = Y ( q [ l ] ) − i × X ( q [ l ] ) + S [ i ] f[i]=Y(q[l])-i\times X(q[l])+S[i]f[i]=Y(q[l])−i×X(q[l])+S[i]
3.入队,注意此处加入决策集合的决策是i − k + 1 i-k+1i−k+1,如果队尾两个决策之间的斜率大于等于新决策与队尾决策的斜率,则将队尾出队
int s[500005],a[500005],f[500050],n,m,q[500005],l,r;
int X(int j){
return a[j+1];
}
int B(int i){
return f[i]-s[i];
}
int Y(int j){
return B(j)+j*X(j);
}
int dx(int i,int j){
return X(i)-X(j);
}
int dy(int i,int j){
return Y(i)-Y(j);
}//编程时时刻注意模块化编程
int main(){
//freopen("kas 3-6.in","r",stdin);
int t;
scanf("%d",&t);
while(t--){
memset(f,0x3f,sizeof f);
l=r=1;
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
s[i]=s[i-1]+a[i];
}
f[0]=0;
for(int i=1;i<=n;i++){
while(l<r&&dy(q[l+1],q[l])<=i*dx(q[l+1],q[l]))l++;
f[i]=Y(q[l])-i*(X(q[l]))+s[i];
if(i<m+m-1)continue;
int qp=i;
i=i-m+1;
while(l<r&&dx(i,q[r])*dy(q[r],q[r-1])>=dx(q[r],q[r-1])*dy(i,q[r]))r--;
q[++r]=i;
i=qp;
}
printf("%d\n",f[n]);
}
}
最后总结:
对于斜率优化D P DPDP,我们可以将其抽象出来它的一般解决步骤
设计出状态,写出状态转移方程
当状态转移方程形如f [ i ] = min / max a ( i ) + b ( j ) + c ( i ) × d ( i ) + C f[i]=\min/\max a(i)+b(j)+c(i)\times d(i)+Cf[i]=min/maxa(i)+b(j)+c(i)×d(i)+C,其中函数a , b , c , d a,b,c,da,b,c,d都是多项式,a , b a,ba,b可能不存在,C CC是常数,且整个方程不含有关于i ii或j jj的高次式,此时可以考虑斜率优化
对状态转移方程进行变式,删掉min / max \min/\maxmin/max函数,并将其进行一项,将只与j相关的式子移至左边,其余移至右边,将其进行函数化变式,写成点斜式方程的样子Y ( j ) = k 0 X ( j ) + B ( j ) Y(j)=k_0X(j)+B(j)Y(j)=k0X(j)+B(j)
举出3个决策j 1 , j 2 , j 3 j_1,j_2,j_3j1,j2,j3并思考三个决策将其画在平面直角坐标系中的三决策连线的关系,无非只有两个:上凸或者下凸,在这两种情况中有一种是可以判断j 2 j_2j2是不可能决策,我们便需要维护这种情况的凸包
对函数a , b a,ba,b的单调性进行分类讨论
·a , b a,ba,b都单调:此时我们只需要维护凸包中< / > </></>斜率的部分,直接取单调队列队头为最优决策(如上例题)
·a aa单调,b bb不单调(与b单调,a不单调一样),此时我们需要维护整个凸包,即我们放弃队头决策的判断,只进行队尾是否可以加入凸包的判断,对于答案我们在凸包里二分(因为斜率单调),当遇到一个点,左边斜率< <\><答案斜率,右边斜率> / < >/<>/<答案斜率时,这个点就是答案,模板的话下文和上文都有
·二者都不单调,此时我们需要使用平衡树动态维护凸包
附赠代码
int find(int i,int k){//k即为我们的答案斜率
if(l==r)return q[l];
int L=l,R=r;
while(L<R){
int mid=(L+R)>>1;
if((__int128)(f[q[mid+1]]-f[q[mid]])<=(__int128)k*(C[q[mid+1]]-C[q[mid]]))L=mid+1;
else R=mid;
}
return q[L];
}
//主函数中
l=r=1;
for(int i=1;i<=n;i++){
int p=find(i,s+T[i]);
f[i]=f[p]-(s+T[i])*C[p]+T[i]*C[i]+s*C[n];
while(l<r&&(f[q[r]]-f[q[r-1]])*(C[i]-C[q[r]])>=(f[i]-f[q[r]])*(C[q[r]]-C[q[r-1]]))r--;
q[++r]=i;
}
·当a , b a,ba,b都不满足单调性时,此时非常麻烦,我们需要维护一个支持动态加点删点的凸包,一般采用平衡树实现
四边形不等式优化DP
四边形不等式:
定义:
设二元函数w ww是定义在整数域上的函数,若满足对于任意整数a ≤ b ≤ c ≤ d a\le b\le c\le da≤b≤c≤d有:
w ( a , d ) + w ( b , c ) ≥ w ( a , c ) + w ( b , d ) w(a,d)+w(b,c)\ge w(a,c)+w(b,d)w(a,d)+w(b,c)≥w(a,c)+w(b,d)
(注意是≥ \ge≥)成立,则称函数w ww满足四边形不等式定理
定理:
设二元函数w ww是定义在整数域上的函数,若满足对于任意整数a < b a< ba<b,有
w ( a , b + 1 ) + w ( a + 1 , b ) ≥ w ( a , b ) + w ( a + 1 , b + 1 ) w(a,b+1)+w(a+1,b)\ge w(a,b)+w(a+1,b+1)w(a,b+1)+w(a+1,b)≥w(a,b)+w(a+1,b+1)
成立,则w ww满足四边形不等式定理
证明:
∵ a < c , w ( a , c ) + w ( a + 1 , c + 1 ) ≤ w ( a + 1 , c ) + w ( a , c + 1 ) \because a<c,w(a,c)+w(a+1,c+1)\le w(a+1,c)+w(a,c+1)∵a<c,w(a,c)+w(a+1,c+1)≤w(a+1,c)+w(a,c+1)
∴ ∀ a + 1 < c , w ( a + 1 , c ) + w ( a + 2 , c + 1 ) ≤ w ( a + 2 , c ) + w ( a + 1 , c + 1 ) ∴\forall a+1<c,w(a+1,c)+w(a+2,c+1)\le w(a+2,c)+w(a+1,c+1)∴∀a+1<c,w(a+1,c)+w(a+2,c+1)≤w(a+2,c)+w(a+1,c+1)
上下两式相加,有:
w ( a , c ) + w ( a + 2 , c + 1 ) ≤ w ( a , c + 1 ) + w ( a + 2 , c ) w(a,c)+w(a+2,c+1)\le w(a,c+1)+w(a+2,c)w(a,c)+w(a+2,c+1)≤w(a,c+1)+w(a+2,c)
以此类推
∀ a ≤ b ≤ c , w ( a , c ) + w ( b , c + 1 ) ≤ w ( a , c + 1 ) + w ( b , c ) \forall a\le b\le c,w(a,c)+w(b,c+1)\le w(a,c+1)+w(b,c)∀a≤b≤c,w(a,c)+w(b,c+1)≤w(a,c+1)+w(b,c)
同理
∀ a ≤ b ≤ c ≤ d , w ( a , c ) + w ( b , d ) ≤ w ( a , d ) + w ( b , c ) \forall a\le b\le c\le d,w(a,c)+w(b,d)\le w(a,d)+w(b,c)∀a≤b≤c≤d,w(a,c)+w(b,d)≤w(a,d)+w(b,c)
得证
小知识:叫四边形不等式的原因是这样一个函数构造出的矩阵,左下角加右上角大于等于左上角加右下角
一维线性DP的四边形不等式优化
对于形如f [ i ] = min 0 ≤ j < i { f [ j ] + v a l ( i , j ) } f[i]=\min_{0\le j<i}\lbrace f[j]+val(i,j) \rbracef[i]=min0≤j<i{f[j]+val(i,j)}的状态转移方程,记p [ i ] p[i]p[i]为f [ i ] f[i]f[i]的最优决策j ′ j'j′,若p pp数组在[ 0 , N ] [0,N][0,N]上非严格单调递增,则称f ff具有决策单调性
决策单调性定理
对于形如f [ i ] = min 0 ≤ j < i { f [ j ] + v a l ( i , j ) } f[i]=\min_{0\le j<i}\lbrace f[j]+val(i,j) \rbracef[i]=min0≤j<i{f[j]+val(i,j)}的状态转移方程,f ff具有决策单调性当且仅当v a l valval函数满足四边形不等式
证明:
∀ i ∈ [ 1 , N ] , ∀ j ∈ [ 1 , p [ i ] − 1 ] \forall i\in[1,N],\forall j\in[1,p[i]-1]∀i∈[1,N],∀j∈[1,p[i]−1],根据p [ i ] p[i]p[i]的最优性,有:
f [ p [ i ] ] + v a l ( p [ i ] , i ) ≤ f [ j ] + v a l ( j , i ) f[p[i]]+val(p[i],i)\le f[j]+val(j,i)f[p[i]]+val(p[i],i)≤f[j]+val(j,i)
∀ i ′ ∈ [ i + 1 , N ] \forall i'\in[i+1,N]∀i′∈[i+1,N],根据四边形不等式,有:
v a l ( i ′ , j ) + v a l ( i , p [ i ] ) ≥ v a l ( i ′ , p [ i ] ) + v a l ( i , j ) val(i',j)+val(i,p[i])\ge val(i',p[i])+val(i,j)val(i′,j)+val(i,p[i])≥val(i′,p[i])+val(i,j)
移项得:
v a l ( i ′ , p [ i ] ) − v a l ( i , p [ i ] ) ≤ v a l ( i ′ , j ) − v a l ( i , j ) val(i',p[i])-val(i,p[i])\le val(i',j)-val(i,j)val(i′,p[i])−val(i,p[i])≤val(i′,j)−val(i,j)
两式相加得:
f [ p [ i ] ] + v a l ( i ′ , p [ i ] ) ≤ f [ j ] + v a l ( i ′ , j ) f[p[i]]+val(i',p[i])\le f[j]+val(i',j)f[p[i]]+val(i′,p[i])≤f[j]+val(i′,j)
此式的含义是,对于i ′ > i i'>ii′>i,决策p [ i ] p[i]p[i]也优于决策j jj,也即p [ i ′ ] ≥ p [ i ] p[i']\ge p[i]p[i′]≥p[i],得证
于是我们只需要证明v a l valval满足四边形不等式就行了,但由于多数情况下证明难度较大也比较复杂,当我们遇到一道数据范围较大,且数据结构,单调队列,斜率优化都无法使用,倍增DP也因限制退场的时候,我们就可以盲猜这满足四边形不等式,并将p pp数组和v a l valval数组进行打表验证递变规律,注意多对几组数据
下面我们来谈对具有决策单调性的一维DP如何优化:
首先,因为具备决策单调性,于是我们的p数组大概长这样(设各个决策为j):
j 1 , j 1 , j 1 , j 3 , j 3 , j 4 , j 5 , j 5 j_1,j_1,j_1,j_3,j_3,j_4,j_5,j_5j1,j1,j1,j3,j3,j4,j5,j5
当我们需要·插入一个新的决策的时候,由于决策单调性,p pp数组会被改成类似下面这个样子
j 1 , j 1 , j 1 , j 3 , i , i , i , i j_1,j_1,j_1,j_3,i,i,i,ij1,j1,j1,j3,i,i,i,i
直接修改数组效率过低,我们需要更高效的处理方式
我们发现,对于新加入的决策i ii来说,在p pp数组中一定有一个位置,使得s数组前面部分的决策比i ii优,后面比i ii差,这时候我们就需要把后面的全部改为i ii,因为单调性的存在,我们可以使用单调队列来维护这个数组
详细的说,维护一个单调队列,其内存储一个个三元组( l , r , k ) (l,r,k)(l,r,k),表示在p pp中p i = k , i ∈ [ l , r ] p_i=k,i\in[l,r]pi=k,i∈[l,r]我们将操作分成下面四步:
1.取出队尾,判断对于新决策i ii与队尾存储的决策q [ t a i l ] . k q[tail].kq[tail].k对于q [ t a i l ] . l q[tail].lq[tail].l来说谁更优,若i ii更优,则删除队尾,记p o s = q [ t a i l ] . l pos=q[tail].lpos=q[tail].l,继续执行步骤一,否则跳转到第二步
2.比较决策i ii与q [ t a i l ] . k q[tail].kq[tail].k对于q [ t a i l ] . r q[tail].rq[tail].r来说谁更优,若是i ii更优,执行第三步,若是q [ t a i l ] . k q[tail].kq[tail].k更优,执行第四步
3.在[ q [ t a i l ] . l , q [ t a i l ] . r ] [q[tail].l,q[tail].r][q[tail].l,q[tail].r]中二分查找到位置m i d midmid,使得对于m i d − 1 mid-1mid−1来说q [ t a i l ] . k q[tail].kq[tail].k更优,对于m i d midmid来说i ii更优秀,记p o s = m i d pos=midpos=mid
4.将队尾出队,依次插入三元组( q [ t a i l ] . l , p o s − 1 , q [ t a i l ] . r ) , ( p o s , n , i ) (q[tail].l,pos-1,q[tail].r),(pos,n,i)(q[tail].l,pos−1,q[tail].r),(pos,n,i)
值得注意的是,当我们插入了决策i ii之后,p pp数组中[ 1 , i ] [1,i][1,i]的位置便全无用处了,直接删掉
附赠模板一份:
struct node{
ll l,r,k;
}q[100050];
void pop(ll i){
while(head<=tail){
if(q[head].r<=i)head++;//删除无用决策[1,i]
else {
q[head].l=i+1;
break;
}
}
}
ll find(ll i){//二分查找到i的最优决策
ll l=head,r=tail;
while(l<=r){
ll mid = l+r>>1;
if(q[mid].l>i)r=mid-1;
else if(q[mid].r<i)l=mid+1;
else return q[mid].k;
}
}
LL calc(ll i,ll j){//val函数,计算代价
//因题而异
}
void insert(ll i){//插入新决策
ll k=-1;
while(head<=tail){
if(calc(q[tail].l,i)<=calc(q[tail].l,q[tail].k))k=q[tail].l,tail--;//步骤1
else {
if(calc(q[tail].r,q[tail].k)<=calc(q[tail].r,i))break;//步骤2
ll l=q[tail].l,r=q[tail].r;
while(l<r){
ll mid=l+r>>1;
if(calc(mid,q[tail].k)<calc(mid,i))l=mid+1;
else r=mid;
}//步骤3
q[tail].r=l-1,k=l;//步骤4.(1)
break;
}
}
if(k==-1)return ;
q[++tail]={k,n,i};//步骤4.(2)
}
使用四边形不等式优化一维线性DP,可以将复杂度从O ( N 2 ) O(N^2)O(N2)优化至O ( N log 2 N ) O(N\log_2 N)O(Nlog2N)
二维四边形不等式优化DP
常用于区间DP里形如:
f [ i , j ] = min i ≤ k < j { f [ i , k ] + f [ k + 1 , j ] + w ( i , j ) } f[i,j]=\min_{i\le k<j}\lbrace f[i,k]+f[k+1,j]+w(i,j)\rbracef[i,j]=i≤k<jmin{f[i,k]+f[k+1,j]+w(i,j)}的状态转移方程的优化
决策单调性定理
当f [ i , j ] = min i ≤ k < j { f [ i , k ] + f [ k + 1 , j ] + w ( i , j ) } ( 特别的 f [ i , i ] = w ( i , i ) = 0 ) f[i,j]=\min_{i\le k<j}\lbrace f[i,k]+f[k+1,j]+w(i,j)\rbrace(\text{特别的}f[i,i]=w(i,i)=0)f[i,j]=mini≤k<j{f[i,k]+f[k+1,j]+w(i,j)}(特别的f[i,i]=w(i,i)=0),f ff数组满足四边形不等式,当且仅当以下两个条件都成立
1.w ww满足四边形不等式,即w ( a , b + 1 ) + w ( a + 1 , b ) ≥ w ( a + 1 , b + 1 ) + w ( a , b ) w(a,b+1)+w(a+1,b)\ge w(a+1,b+1)+w(a,b)w(a,b+1)+w(a+1,b)≥w(a+1,b+1)+w(a,b)
2.对于任意整数a ≤ b ≤ c ≤ d a\le b\le c\le da≤b≤c≤d ,w ww函数满足:w ( b , c ) ≤ w ( a , d ) w(b,c)\le w(a,d)w(b,c)≤w(a,d)
定理(二维决策单调性)
在状态转移方程f [ i , j ] = min i ≤ k < j { f [ i , k ] + f [ k + 1 , j ] + w ( i , j ) } ( 特别的 f [ i , i ] = w ( i , i ) = 0 ) f[i,j]=\min_{i\le k<j}\lbrace f[i,k]+f[k+1,j]+w(i,j)\rbrace(\text{特别的}f[i,i]=w(i,i)=0)f[i,j]=mini≤k<j{f[i,k]+f[k+1,j]+w(i,j)}(特别的f[i,i]=w(i,i)=0)中,记p [ i , j ] p[i,j]p[i,j]为f [ i , j ] f[i,j]f[i,j]取到的最优决策点k kk,如果f ff满足四边形不等式,则有对于任意整数i < j i<ji<j:p [ i , j − 1 ] ≤ p [ i , j ] ≤ p [ i + 1 , j ] p[i,j-1]\le p[i,j]\le p[i+1,j]p[i,j−1]≤p[i,j]≤p[i+1,j]
两定理证明见:辰星凌-各种DP优化
其时间复杂度为O ( ∑ 1 ≤ i ≤ j ≤ n ( P [ i + 1 , j ] − P [ i , j − 1 ] + 1 ) ) = O ( n 2 ) O(\sum_{1\le i\le j\le n}(P[i+1,j]-P[i,j-1]+1))=O(n^2)O(∑1≤i≤j≤n(P[i+1,j]−P[i,j−1]+1))=O(n2)
综上所述,我们使用决策单调性将复杂度为O ( n 3 ) O(n^3)O(n3)的区间D P DPDP优化为了O ( n 2 ) O(n^2)O(n2)
由于四边形不等式优化DP的难点在于发现可以使用四边形不等式,而非运用,此处就不写例题了,很裸的
DP各常见优化的比较与思考
DP有三要素,分别是阶段,状态,决策
运用此三要素对我们的优化方法进行思考,可以归类为:
阶段:倍增
状态:倍增
决策:数据结构,单调队列,斜率优化,四边形不等式
可见对于决策优化的DP策略远远多于对阶段状态进行优化的策略,导致这个的原因个人认为有一点是对于状态阶段优化的DP策略非常灵活,而决策相对单调,有固定板子。
对于这些优化,我们再以动态规划类型分类:
- |1D/1D动态规划:|单调队列,斜率优化,一维四边形不等式|
- |任意方程式:|数据结构优化|
- |状态设计:|倍增|
下面我们来分析各种动态规划优化算法的应用场景:
1D/1D型动态规划
再次复习,模型类似于
f [ i ] = max L ( i ) ≤ j ≤ R ( i ) { f [ j ] + v a l ( i , j ) } f[i]=\max_{L(i)\le j\le R(i)}\lbrace f[j]+val(i,j) \rbracef[i]=L(i)≤j≤R(i)max{f[j]+val(i,j)}
或者:
f [ i ] = min L ( i ) ≤ j ≤ R ( i ) { f [ j ] + v a l ( i , j ) } f[i]=\min_{L(i)\le j\le R(i)}\lbrace f[j]+val(i,j) \rbracef[i]=L(i)≤j≤R(i)min{f[j]+val(i,j)}
单调队列优化
对于v a l ( i , j ) val(i,j)val(i,j)只含有与j jj或者i ii有关的多项式(只与i ii有关的可以踢出min / max \min/\maxmin/max函数)运用单调队列优化,前提是v a l ( i , j ) val(i,j)val(i,j)存在单调性,此时f ff也有着单调性
单调队列优化的步骤可以简单的描述为:
- 对于队头策略进行范围上的比较,超出范围出队
- 使用队头策略更新答案
- 将新进入决策集合的策略加入队尾,加入之前判断队尾是否劣于新决策,是的话出队
有时题目较复杂,我们可以使用单调队列维护决策集合,再使用其他数据结构(支持插入删除)维护高效的取出最优策略
斜率优化
斜率优化一般步骤上文也有,这里再提一次:
设计出状态,写出状态转移方程
当状态转移方程形如f [ i ] = min / max a ( i ) + b ( j ) + c ( i ) × d ( i ) + C f[i]=\min/\max a(i)+b(j)+c(i)\times d(i)+Cf[i]=min/maxa(i)+b(j)+c(i)×d(i)+C,其中函数a , b , c , d a,b,c,da,b,c,d都是多项式,a , b a,ba,b可能不存在,C CC是常数,且整个方程不含有关于i ii或j jj的高次式,此时可以考虑斜率优化
对状态转移方程进行变式,删掉min / max \min/\maxmin/max函数,并将其进行一项,将只与j相关的式子移至左边,其余移至右边,将其进行函数化变式,写成点斜式方程的样子Y ( j ) = k 0 X ( j ) + B ( j ) Y(j)=k_0X(j)+B(j)Y(j)=k0X(j)+B(j)
举出3个决策j 1 , j 2 , j 3 j_1,j_2,j_3j1,j2,j3并思考三个决策将其画在平面直角坐标系中的三决策连线的关系,无非只有两个:上凸或者下凸,在这两种情况中有一种是可以判断j 2 j_2j2是不可能决策,我们便需要维护这种情况的凸包
对函数a , b a,ba,b的单调性进行分类讨论
·a , b a,ba,b都单调:此时我们只需要维护凸包中< / > </></>斜率的部分,直接取单调队列队头为最优决策(如上例题)
·a aa单调,b bb不单调(与b单调,a不单调一样),此时我们需要维护整个凸包,即我们放弃队头决策的判断,只进行队尾是否可以加入凸包的判断,对于答案我们在凸包里二分(因为斜率单调),当遇到一个点,左边斜率< <\><答案斜率,右边斜率> / < >/<>/<答案斜率时,这个点就是答案,模板的话下文和上文都有
·二者都不单调,使用平衡树动态维护凸包
四边形不等式优化
推荐先观察题目范围明确需要进行优化,再对其他优化策略一个个排除,都不行的时候将v a l valval函数使用数学证明/打表验证规律(常用,毕竟咱不是数竞生),直接套板子即可,需要注意的是这个四边形不等式优化也可以用于区间DP
其他优化
数据结构优化
观察DP方程式,直接对于决策使用数据结构快速检索出最优决策实现快速转移
倍增优化
一般应用较少,需要保证的是答案满足可拼接性,即保证在拼接答案或者是倍增DP的时候不会出现冲突之类的,很灵活
多次查询的dp问题:一般数据结构维护,重复计算很多的话可以倍增优化