List的结构
相关代码为: src/t_list.c, src/ziplist.c ,src/quicklist.c
redis 4.0版本中的list的数据结构为一种 quicklist的数据结构。
/* Node, quicklist, and Iterator are the only data structures used currently. */
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 12 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
可以看处quicklist 可以简单看作双端链表结构,保留头指针和尾部指针,但node里面存的是一种ziplist的结构
/* The ziplist is a specially encoded dually linked list that is designed
* to be very memory efficient. It stores both strings and integer values,
* where integers are encoded as actual integers instead of a series of
* characters. It allows push and pop operations on either side of the list
* in O(1) time. However, because every operation requires a reallocation of
* the memory used by the ziplist, the actual complexity is related to the
* amount of memory used by the ziplist.
*
* ----------------------------------------------------------------------------
*
* ZIPLIST OVERALL LAYOUT
* ======================
*
* The general layout of the ziplist is as follows:
*
* <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
*
* NOTE: all fields are stored in little endian, if not specified otherwise.
*
* <uint32_t zlbytes> is an unsigned integer to hold the number of bytes that
* the ziplist occupies, including the four bytes of the zlbytes field itself.
* This value needs to be stored to be able to resize the entire structure
* without the need to traverse it first.
*
* <uint32_t zltail> is the offset to the last entry in the list. This allows
* a pop operation on the far side of the list without the need for full
* traversal.
*
* <uint16_t zllen> is the number of entries. When there are more than
* 2^16-2 entires, this value is set to 2^16-1 and we need to traverse the
* entire list to know how many items it holds.
*
* <uint8_t zlend> is a special entry representing the end of the ziplist.
* Is encoded as a single byte equal to 255. No other normal entry starts
* with a byte set to the value of 255.
*
* ZIPLIST ENTRIES
* ===============
*
* Every entry in the ziplist is prefixed by metadata that contains two pieces
* of information. First, the length of the previous entry is stored to be
* able to traverse the list from back to front. Second, the entry encoding is
* provided. It represents the entry type, integer or string, and in the case
* of strings it also represents the length of the string payload.
* So a complete entry is stored like this:
*
* <prevlen> <encoding> <entry-data>
*
* Sometimes the encoding represents the entry itself, like for small integers
* as we'll see later. In such a case the <entry-data> part is missing, and we
* could have just:
*
* <prevlen> <encoding>
*
* The length of the previous entry, <prevlen>, is encoded in the following way:
* If this length is smaller than 254 bytes, it will only consume a single
* byte representing the length as an unsinged 8 bit integer. When the length
* is greater than or equal to 254, it will consume 5 bytes. The first byte is
* set to 254 (FE) to indicate a larger value is following. The remaining 4
* bytes take the length of the previous entry as value.
*
* So practically an entry is encoded in the following way:
*
* <prevlen from 0 to 253> <encoding> <entry>
*
* Or alternatively if the previous entry length is greater than 253 bytes
* the following encoding is used:
*
* 0xFE <4 bytes unsigned little endian prevlen> <encoding> <entry>
*
* The encoding field of the entry depends on the content of the
* entry. When the entry is a string, the first 2 bits of the encoding first
* byte will hold the type of encoding used to store the length of the string,
* followed by the actual length of the string. When the entry is an integer
* the first 2 bits are both set to 1. The following 2 bits are used to specify
* what kind of integer will be stored after this header. An overview of the
* different types and encodings is as follows. The first byte is always enough
* to determine the kind of entry.
*
* |00pppppp| - 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* "pppppp" represents the unsigned 6 bit length.
* |01pppppp|qqqqqqqq| - 2 bytes
* String value with length less than or equal to 16383 bytes (14 bits).
* IMPORTANT: The 14 bit number is stored in big endian.
* |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
* String value with length greater than or equal to 16384 bytes.
* Only the 4 bytes following the first byte represents the length
* up to 32^2-1. The 6 lower bits of the first byte are not used and
* are set to zero.
* IMPORTANT: The 32 bit number is stored in big endian.
* |11000000| - 3 bytes
* Integer encoded as int16_t (2 bytes).
* |11010000| - 5 bytes
* Integer encoded as int32_t (4 bytes).
* |11100000| - 9 bytes
* Integer encoded as int64_t (8 bytes).
* |11110000| - 4 bytes
* Integer encoded as 24 bit signed (3 bytes).
* |11111110| - 2 bytes
* Integer encoded as 8 bit signed (1 byte).
* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
* Unsigned integer from 0 to 12. The encoded value is actually from
* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
* subtracted from the encoded 4 bit value to obtain the right value.
* |11111111| - End of ziplist special entry.
*
* Like for the ziplist header, all the integers are represented in little
* endian byte order, even when this code is compiled in big endian systems.
*
* EXAMPLES OF ACTUAL ZIPLISTS
* ===========================
*
* The following is a ziplist containing the two elements representing
* the strings "2" and "5". It is composed of 15 bytes, that we visually
* split into sections:
*
* [0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
* | | | | | |
* zlbytes zltail entries "2" "5" end
*
* The first 4 bytes represent the number 15, that is the number of bytes
* the whole ziplist is composed of. The second 4 bytes are the offset
* at which the last ziplist entry is found, that is 12, in fact the
* last entry, that is "5", is at offset 12 inside the ziplist.
* The next 16 bit integer represents the number of elements inside the
* ziplist, its value is 2 since there are just two elements inside.
* Finally "00 f3" is the first entry representing the number 2. It is
* composed of the previous entry length, which is zero because this is
* our first entry, and the byte F3 which corresponds to the encoding
* |1111xxxx| with xxxx between 0001 and 1101. We need to remove the "F"
* higher order bits 1111, and subtract 1 from the "3", so the entry value
* is "2". The next entry has a prevlen of 02, since the first entry is
* composed of exactly two bytes. The entry itself, F6, is encoded exactly
* like the first entry, and 6-1 = 5, so the value of the entry is 5.
* Finally the special entry FF signals the end of the ziplist.
*
* Adding another element to the above string with the value "Hello World"
* allows us to show how the ziplist encodes small strings. We'll just show
* the hex dump of the entry itself. Imagine the bytes as following the
* entry that stores "5" in the ziplist above:
*
* [02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64]
*
* The first byte, 02, is the length of the previous entry. The next
* byte represents the encoding in the pattern |00pppppp| that means
* that the entry is a string of length <pppppp>, so 0B means that
* an 11 bytes string follows. From the third byte (48) to the last (64)
* there are just the ASCII characters for "Hello World".
*
* ----------------------------------------------------------------------------
*
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily. */
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previos entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
源码里面给出的解释是
ziplist 是一种经过特殊编码的双链表,非常节约内存。他可以同时存储字符串和整数,整数是按实际的值来存储的,他允许在O(1)的时间复杂度弹出顶部和底部元素,但是每个操作都会重新分配ziplist的内存,实际的复杂度和内存的使用挂钩(这就是为什么压缩列表的长度不能过大)。
ziplist的结构大致为 …
zlbytes 32位无符号整数:保存zl的大小,
zltail 32位无符号整数 : 保存尾部的offset
zllen 16位无符号整数 保存entry的数量
zlend 结束符标志 其值为 255
entry的结构大致为
如果entry为数字(0-12)类型的时候,也可以表示为
prevlen 如果长度小于254,那么他就占一个字节,如果长度大于等于254那么他就占5个字节来表示无符号整数。这在代码_quicklistNodeAllowInsert (quicklist.c)就有体现。
如果大于254,那么第一个字节用254表示,后面4个字节代表他的真实长度。(len也是一样的道理)
比如 0xFE <4 bytes unsigned little endian prevlen>
encoding 的前两个字节代表entry的类型以及len的长度,前两位为1代表类型为数字,其他为字符串 比如-
11000000 entry为16位整数 11010000 entry为32位整数 11100000 64位整数
00pppppp 前两位为0 所以代表长度只有6bit也就是最大64
01pppppp|qqqqqqqq 前两位为01,代表16bit的长度
10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt 第3到8位没用,其他代表长度 大于16384
比如介绍中的例子
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
| | | | | |
zlbytes zltail entries “2” “5” end如果ziplist 为2,5 那么可以表示为
zlbytes 代表 这个ziplist 占用 0f即 15个字节
zltail 代表 ziplist 最后一个字节的下标,最后一个字节的第一个byte为第12位
entries 为zlen代表两个entry
00 f3 00对应的是prevlen 表示前面的长度为0,标记头节点,f3二进制为 11110011 ,前面两个bit代表数字类型,根据协议11110000 代表 24 bit signed (3 bytes).,所以 11110011 从 11110001表示0,11110011 表示2
02 f6 02对应的是 prevlen 前面的长度位2,f6同上面理 ,表示5
插入流程
先来code,来push的,也就是redis中 lpush 的执行流程
void pushGenericCommand(client *c, int where) {
int j, pushed = 0;
robj *lobj = lookupKeyWrite(c->db,c->argv[1]);
if (lobj && lobj->type != OBJ_LIST) {
addReply(c,shared.wrongtypeerr);
return;
}
for (j = 2; j < c->argc; j++) {
if (!lobj) {
lobj = createQuicklistObject();
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);
}
listTypePush(lobj,c->argv[j],where);
pushed++;
}
addReplyLongLong(c, (lobj ? listTypeLength(lobj) : 0));
if (pushed) {
char *event = (where == LIST_HEAD) ? "lpush" : "rpush";
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
}
server.dirty += pushed;
}
/* The function pushes an element to the specified list object 'subject',
* at head or tail position as specified by 'where'.
*
* There is no need for the caller to increment the refcount of 'value' as
* the function takes care of it if needed. */
void listTypePush(robj *subject, robj *value, int where) {
if (subject->encoding == OBJ_ENCODING_QUICKLIST) {
int pos = (where == LIST_HEAD) ? QUICKLIST_HEAD : QUICKLIST_TAIL;
value = getDecodedObject(value);
size_t len = sdslen(value->ptr);
quicklistPush(subject->ptr, value->ptr, len, pos);
decrRefCount(value);
} else {
serverPanic("Unknown list encoding");
}
}
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
可以看出,redis 中 lpush的流程如下(将node推到头部)
- 根据key查找相关数据,如果数据的类型不是OBJ_LIST返回error
- 根据遍历每个参数,对每个参数执行操作,比如lpush key value1 value2
- 如果list为空,创建list,然后初始化参数,增加进键值对中(dbadd)
- 序列化值,转化为SDS(动态字符串,后面String系列再说),并获取长度
- 判断当前值能不能插入ziplist中,
- 就如上面ziplist结构,先序列化,
- 根据size获取prevlen和encoding的长度
- 如果当前ziplist的长度小于fill(fill 小于0 的时候 ,后面说)返回可插入
- 如果当前ziplist长度大于8192,返回不可插入 ,可以理解为对fill设置为正数时候的补偿
- 如果当前ziplist中元素的个数小于fill (fill大于0),返回可插入
- 如果能插入ziplist,就将当前元素插入ziplist , 不更新头节点吗,插入ziplist的流程如下 (这里只说明插入头部的流程)
- 确定prelen的长度
- 看字符串能不能encoding成整数,如果能转化我数字,如果不能直接存字符串
- 确定encoding的长度
- 确定是否更新下一个entry的prelen的空间(长度发生改变时,但是长度空间能cover时不一定会更新,这里需要注意,不是每一次都会更新nextkey的prelen的占用空间)
- 移动空间执行插入ziplist操作
- 如果流程不能插入ziplist,则创建新的quicklistnode,然后执行4的操作,然后更换头节点,压缩后面的节点,那么压缩步骤为
- 如果是节点可以再次被压缩(如果压缩失败,不压缩,如果压缩成功,修改encoding,和节点的recompress)
- 如果是待压缩,先检查当前压缩 compress(下面再说这个参数)是不是等于0
- 如果compress等于0,说明不需要压缩,如果当前quicklist的空间小于2倍压缩的空间,也不需要压缩
- 如果compress大于0,就压缩这个深度。即头部和尾部有compress个元素不压缩,其他元素压缩。
- 如果深度
- 更新占用空间,list的count增加1,head的count+1
在4.0版本中,compress等于1的时候 quicklist的结构可以大致如下图

quicklist和头节点中中保留整个list中的长度(并非node的长度),每个node都关联一个ziplist。除了头尾节点,其他节点将被compress(压缩)
尾部插入和中间插入
如果是尾部插入,和头部插入时类似的,
如果中间插入,且目标节点所在的ziplist 和 前后ziplist 都没有剩余的空间,会造成节点分裂。
插入的代码如下
/* Insert a new entry before or after existing entry 'entry'.
*
* If after==1, the new value is inserted after 'entry', otherwise
* the new value is inserted before 'entry'. */
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz, int after) {
int full = 0, at_tail = 0, at_head = 0, full_next = 0, full_prev = 0;
int fill = quicklist->fill;
quicklistNode *node = entry->node;
quicklistNode *new_node = NULL;
if (!node) {
/* we have no reference node, so let's create only node in the list */
D("No node given!");
new_node = quicklistCreateNode();
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
__quicklistInsertNode(quicklist, NULL, new_node, after);
new_node->count++;
quicklist->count++;
return;
}
/* Populate accounting flags for easier boolean checks later */
if (!_quicklistNodeAllowInsert(node, fill, sz)) {
D("Current node is full with count %d with requested fill %lu",
node->count, fill);
full = 1;
}
if (after && (entry->offset == node->count)) {
D("At Tail of current ziplist");
at_tail = 1;
if (!_quicklistNodeAllowInsert(node->next, fill, sz)) {
D("Next node is full too.");
full_next = 1;
}
}
if (!after && (entry->offset == 0)) {
D("At Head");
at_head = 1;
if (!_quicklistNodeAllowInsert(node->prev, fill, sz)) {
D("Prev node is full too.");
full_prev = 1;
}
}
/* Now determine where and how to insert the new element */
if (!full && after) {
D("Not full, inserting after current position.");
quicklistDecompressNodeForUse(node);
unsigned char *next = ziplistNext(node->zl, entry->zi);
if (next == NULL) {
node->zl = ziplistPush(node->zl, value, sz, ZIPLIST_TAIL);
} else {
node->zl = ziplistInsert(node->zl, next, value, sz);
}
node->count++;
quicklistNodeUpdateSz(node);
quicklistRecompressOnly(quicklist, node);
} else if (!full && !after) {
D("Not full, inserting before current position.");
quicklistDecompressNodeForUse(node);
node->zl = ziplistInsert(node->zl, entry->zi, value, sz);
node->count++;
quicklistNodeUpdateSz(node);
quicklistRecompressOnly(quicklist, node);
} else if (full && at_tail && node->next && !full_next && after) {
/* If we are: at tail, next has free space, and inserting after:
* - insert entry at head of next node. */
D("Full and tail, but next isn't full; inserting next node head");
new_node = node->next;
quicklistDecompressNodeForUse(new_node);
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_HEAD);
new_node->count++;
quicklistNodeUpdateSz(new_node);
quicklistRecompressOnly(quicklist, new_node);
} else if (full && at_head && node->prev && !full_prev && !after) {
/* If we are: at head, previous has free space, and inserting before:
* - insert entry at tail of previous node. */
D("Full and head, but prev isn't full, inserting prev node tail");
new_node = node->prev;
quicklistDecompressNodeForUse(new_node);
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_TAIL);
new_node->count++;
quicklistNodeUpdateSz(new_node);
quicklistRecompressOnly(quicklist, new_node);
} else if (full && ((at_tail && node->next && full_next && after) ||
(at_head && node->prev && full_prev && !after))) {
/* If we are: full, and our prev/next is full, then:
* - create new node and attach to quicklist */
D("\tprovisioning new node...");
new_node = quicklistCreateNode();
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
new_node->count++;
quicklistNodeUpdateSz(new_node);
__quicklistInsertNode(quicklist, node, new_node, after);
} else if (full) {
/* else, node is full we need to split it. */
/* covers both after and !after cases */
D("\tsplitting node...");
quicklistDecompressNodeForUse(node);
new_node = _quicklistSplitNode(node, entry->offset, after);
new_node->zl = ziplistPush(new_node->zl, value, sz,
after ? ZIPLIST_HEAD : ZIPLIST_TAIL);
new_node->count++;
quicklistNodeUpdateSz(new_node);
__quicklistInsertNode(quicklist, node, new_node, after);
_quicklistMergeNodes(quicklist, node);
}
quicklist->count++;
}
弹出流程
实际上根据上面数据结构,可以看出弹出流程就是,ziplist的删除流程
- 确定元素的位置
- 获取元素
- 删除元素(和新增元素ziplist操作的反向操作差不多)
- 如果中间弹出,涉及到ziplist的merge
参数
list-max-ziplist-entries
字段在4.0版本已经废弃
list-max-ziplist-value
字段在4.0版本已经废弃
list-max-ziplist-size和list-compress-depth
这两个值是ziplist的参数,部分代码应用如下
void pushGenericCommand(client *c, int where) {
int j, pushed = 0;
robj *lobj = lookupKeyWrite(c->db,c->argv[1]);
if (lobj && lobj->type != OBJ_LIST) {
addReply(c,shared.wrongtypeerr);
return;
}
for (j = 2; j < c->argc; j++) {
if (!lobj) {
lobj = createQuicklistObject();
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);
}
listTypePush(lobj,c->argv[j],where);
pushed++;
}
addReplyLongLong(c, (lobj ? listTypeLength(lobj) : 0));
if (pushed) {
char *event = (where == LIST_HEAD) ? "lpush" : "rpush";
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
}
server.dirty += pushed;
}
这两个参数是quicklist的初始化参数
list-compress-depth的范围是 [0 , 1 << 16]
list-max-ziplist-size 的范围是 [-5 , 1 << 15]
即quicklist中的 compress 和 fill的值的设置
/* Create a new quicklist.
* Free with quicklistRelease(). */
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
return quicklist;
}
compress 和 fill
这两个值是List中最重要的参数,也是可调节的参数,
这两个参数是对以前版本中的list-max-ziplist-entries 和 list-max-ziplist-value的优化,当然数据结构也有优化,
compress默认值为0,fill为-2.当然 fill为-2,并不是他的真正的值,而是他在数组中的下标 ,如代码
/* Optimization levels for size-based filling */
static const size_t optimization_level[] = {4096, 8192, 16384, 32768, 65536};
-2代表,他是第二个值 也就相当于正值 8192。
compress
compress代表压缩度。表示头部多少个节点和尾部多少个节点不被压缩,其他节点被压缩。
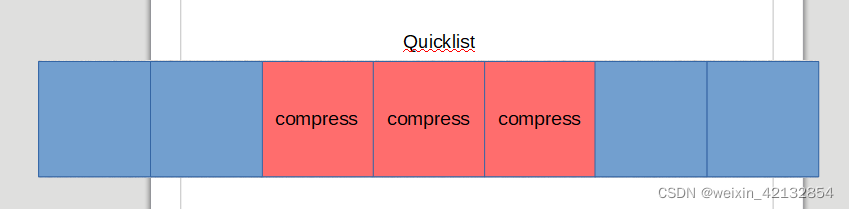
当compress等于2时,头部和尾部有两个ziplist不会被压缩。
为什么会有compress
在list结构中,我们希望增删数据和节约内存兼顾,list常常用作队列来对头尾节点进行操作,所以我们需要list头尾部节点不压缩以增加增删数据的速度。中间部分不经常操作,希望用更少的内存进行存储。所以我们需要自定义compree深度
怎么设置这个值
如果增删非常频繁,可以考虑增大这个值来提高弹出和推入的速率。
如果对一个list 增删很少,且数据量很大,那么可以减小.
如果数据很多且press很大,为了节约内存,建议减小这个值。如果多种情况不同的key同时存在,那么就看自己的取舍了
fill
fill大于0和小于0是不同的作用的,当fill大于0时,代表ziplist中的长度不得大于多少,fill小于0时代表其占用的空间的最大值。
fill的默认值为-2,代表8192,即8kb
REDIS_STATIC int _quicklistNodeSizeMeetsOptimizationRequirement(const size_t sz,
const int fill) {
if (fill >= 0)
return 0;
size_t offset = (-fill) - 1;
if (offset < (sizeof(optimization_level) / sizeof(*optimization_level))) {
if (sz <= optimization_level[offset]) {
return 1;
} else {
return 0;
}
} else {
return 0;
}
}
为什么默认为8KB
需要契合内存页,内存页一般为4KB,没压缩过的ziplist占两个内存页,
![]()
怎么设置这个字段
个人不建议将ziplist设置成正数,正数表示ziplist中有多少entry.因为每个entry占用的大小不确定,容易造成ziplist占用内存不确定性。
将ziplist设置为负数,为什么不设置为-1代表大多数内存页设置4k,因为涉及到压缩,在不压缩的情况下,设置为-1,也许是一个好的选择。
那么什么情况下设置为-3(16kb),-4(32kb),-5(64kb)呢,个人觉得会根据服务器内存页的设置情况和压缩数据的情况。