Redis的详细安装步骤请移步:看详细安装步骤点击我
1 字符串(String)
字符串类型是Redis最基础的数据结构。首先键都是字符串类型,而且其他几种数据结构都是在字符串类型基础上构建的,所以字符串类型能为其他四种数据结构的学习奠定基础。如图2-7所示,字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字(整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能超过512MB。
1.1 命令
字符串类型的命令还是比较多,这里进行一个分类,分为常用命令和不常用命令
1.1.1 常用命令
- (1)设置值(set)
set key value [ex seconds] [px milliseconds] [nx|xx]
实列:设置键(K) 为hello 值为 word的 键值对,返回结果为OK 表示设置成功
127.0.1:6379> set hello word
OK
127.0.1:6379>
set设置命令有4个选项
| 选项 | 含义 |
|---|---|
| ex seconds | 设置多少秒过期时间 |
| px milliseconds | 设置多少毫秒过期时间 |
| nx | 键必须不存在,才能设置成功,用于添加新值 |
| xx | 键必须存在 才可以设置成功,用于跟新值 |
实列:设置键(K)为hello 值为word 的键值对,10秒过期
127.0.1:6379> set heloo word ex 10
OK
127.0.1:6379>
其他的set命令 按照格式填充命令即可
set命令的扩展:Redis还提供了setex和setnx两个设置命令
他们的作用和ex和nx选项一样
setex key seconds value
setnx key value
下面举例说明set、setnx、setxx
先查询键hello 存不存在 0为不存在 1为存在
127.0.1:6379> exists hello
(integer) 0
127.0.1:6379>
不存在 我们就设置一个键为hello 值为word的键值对
127.0.1:6379> set hello word
OK
127.0.1:6379>
通过setnx(键必须不存在) 设置 hello 因为hello键已经存在 会失败 返回结果为0
127.0.1:6379> setnx hello redis
(integer) 0
127.0.1:6379>
因为hello已经存在 所以set .....xx成功,返回结果为OK 值跟新成功
127.0.1:6379> set hello redis xx
OK
127.0.1:6379>
setnx和setxx在实际使用中有什么应用场景吗?以setnx命令为例子,由于Redis的单线程命令处理机制,如果有多个客户端同时执行setnx key value,根据setnx的特性只有一个客户端能设置成功,setnx可以作为分布式锁的一种实现方案。
- (2)获取值(get)
get key
实列:获取键为hello的值
127.0.1:6379> get hello
"redis"
127.0.1:6379>
如果获取不存在的键,会返回nil 表示为空
127.0.1:6379> get hello111
(nil)
127.0.1:6379>
- (3)批量设置值(mset)
mset key value [key value …]
实列:通过mset命 一次性设置4个键值对
1 2 3 4 为键 a b c d为值
127.0.1:6379> mset 1 a 2 b 3 c 4 d
OK
127.0.1:6379>
- (4)批量获取值(mget)
mget key [key …]
实列:批量获取上面批量设置的键为 1 2 3 4 的值
127.0.1:6379> mget 1 2 3 4
1) "a"
2) "b"
3) "c"
4) "d"
127.0.1:6379>
如果批量获取的时候其中有些键不存在,那么它的值为nil(空),结果是按照传入的键的顺丰返回
127.0.1:6379> mget 1 3 5 4
1) "a"
2) "c"
3) (nil)
4) "d"
127.0.1:6379>
- (5)计数自增(incr)
incr key
incr命令用于对值做自增操作,返回结果分为3种情况
| 情况 | 说明 |
|---|---|
| 值不是整数 | 返回错误 |
| 值是整数 | 返回自增后的结果 |
| 键不存在 | 按照值为0自增,返回结果为1 |
实列:对以上3种情况 进行一一测试
第一种情况:值不是整数
准备测试数据,设置一个键 test 值为0.2 键值对
127.0.1:6379> set test 0.2
OK
127.0.1:6379>
值为小数不为整数 所以报错
127.0.1:6379> incr test
(error) ERR value is not an integer or out of range
127.0.1:6379>
将键为test的值改为整数 1
127.0.1:6379> set test 1 xx
OK
127.0.1:6379> get test
"1"
127.0.1:6379>
值为整数 所以成功 初始值为1 返回自增后的结果为2
127.0.1:6379> incr test
(integer) 2
127.0.1:6379>
测试键不存在 按照值为0自动 返回结果为1
127.0.1:6379> incr test11
(integer) 1
127.0.1:6379>
- (6)自减(decr)
decr key
decr命令用于对值做自减操作,返回结果分为3种情况
| 情况 | 说明 |
|---|---|
| 值不是整数 | 返回错误 |
| 值是整数 | 返回自减后的结果 |
| 键不存在 | 按照值为0自减,返回结果为-1 |
键不存在 返回结果为-1
127.0.1:6379> decr decrtest
(integer) -1
127.0.1:6379>
值不为整数,结果返回错误,
先将键decrtest的值改为0.2 再进程测试 返回结果错误
127.0.1:6379> set decrtest 0.2 xx
OK
127.0.1:6379> decr decrtest
(error) ERR value is not an integer or out of range
127.0.1:6379>
值为整数 返回自减结果
先将键decrtest值改为整数2 再进行测试 返回结果为1
127.0.1:6379> set decrtest 2 xx
OK
127.0.1:6379> decr decrtest
(integer) 1
127.0.1:6379>
- (7)自增指定数字(incrby)
incrby key increment
incrby命令用于对值和指定数字相加操作,返回结果分为3种情况
| 情况 | 说明 |
|---|---|
| 值不是整数 | 返回错误 |
| 值是整数 | 返回相加后的结果 |
| 键不存在 | 按照值为0相加,返回结果为指定数字 |
测试1 键不存在则返回 指定数字
127.0.1:6379> incrby test 10
(integer) 10
测试2 值不为整数 返回结果错误
先将键test 值改为小数0.2 再进行测试 结果返回错误
在这里插入127.0.1:6379> set test 0.2 xx
OK
127.0.1:6379> incrby test 1
(error) ERR value is not an integer or out of range
代码片
测试3 值为整数 结果返回相加结果
127.0.1:6379> set test 1 xx
OK
127.0.1:6379> incrby test 1
(integer) 2
- (8)自减指定数字(decrby)
decrby key increment
decrby命令用于对值和指定数字相减操作,返回结果分为3种情况
| 情况 | 说明 |
|---|---|
| 值不是整数 | 返回错误 |
| 值是整数 | 返回相减后的结果 |
| 键不存在 | 按照值为0相加,返回结果为指定数字的负数 |
测试1 值为不为整数 先将键test 值改为 小数0.2 进行测试 返回结果为错误
127.0.1:6379> set test 0.2 xx
OK
127.0.1:6379> decrby test 1
(error) ERR value is not an integer or out of range
127.0.1:6379>
测试2 值为整数 先将键test 值改为整数1 再进行测试
127.0.1:6379> set test 1 xx
OK
127.0.1:6379> decrby test 2
(integer) -1
127.0.1:6379>
测试3 键不存在 返回0-指定数的结果 =负的指定数字
先删除键test 再进行测试
127.0.1:6379> del test
(integer) 1
127.0.1:6379> decrby test 10
(integer) -10
127.0.1:6379>
- (9)自增浮点数(incrbyfloat)
incrbyfloat key increment
incrbyfloat命令用于对值和指定浮点数字(小数)[整数也可以]、相加操作 返回结果分为2种情况
| 情况 | 说明 |
|---|---|
| 键存在 | 返回与指定数相加的结果 |
| 键不存在 | 按照值为0相加,返回结果为指定数字 |
测试1 键不存在
127.0.1:6379> incrbyfloat float 0.5
"0.5"
127.0.1:6379>
测试2 键存在
127.0.1:6379> incrbyfloat float 2.5
"3"
127.0.1:6379>
1.1.2 不常用命令
- (1) 追加值(append)
append key value
append可以想字符串尾部追加值,实列如下:
127.0.1:6379> set hello nihao
OK
127.0.1:6379> get hello
"nihao"
127.0.1:6379> append hello wojiaoredis
(integer) 16
127.0.1:6379> get hello
"nihaowojiaoredis"
- (2) 字符串长度(strlen)
strlen key
实列:获取键 hello 的长度 长度为16
127.0.1:6379> strlen hello
(integer) 16
127.0.1:6379>
以下实列返回长度为11 因为一个汉字3个字节
127.0.1:6379> set hello redis"你好"
OK
127.0.1:6379> strlen hello
(integer) 11
127.0.1:6379>
- (3) 设值并返回原值(getset)
getset key value
getset和set一样都是设置值,唯一不同的是getset会返回原值(设置前的值) 实列如下:
127.0.1:6379> get hello
"word"
127.0.1:6379> getset hello redis
"word"
127.0.1:6379>
- (4) 设置(替换)指定位置的字符(setrange)
setrange key offeset vlue
==offeset替换字符的开始位置从左往右从第一个字符的位置为0 依次类推 ==
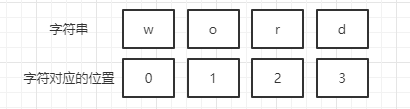
实列:将键为hello的值word 的wo字符设置为he
127.0.1:6379> set hello word
OK
127.0.1:6379> setrange hello 0 he
(integer) 4
127.0.1:6379> get hello
"herd"
127.0.1:6379>
- (5) 获取部分字符串[指定位置范围的字符串](getrange)
getrange key start end
start开始位置 end结束位置 位置从0开始计算
实列:获取herd 的前两个字符
127.0.1:6379> getrange hello 0 1
"he"
127.0.1:6379>
1.2 字符串命令的时间复杂度
此表可以给我们再开发过程中根据自生业务需求和数据大小来选择合适的命令
| 命令 | 时间复杂度 |
|---|---|
| set key value | O(1) |
| get key | O(1) |
| del key [key …] | O(k),k是键的个数 |
| mset key value [key value …] | O(k),k是键的个数 |
| mget key [key …] | O(k),k是键的个数 |
| incr key | O(1) |
| decr key | O(1) |
| incrby key increment | O(1) |
| decrby key increment | O(1) |
| incrbyfloat key increment | O(1) |
| append key value | O(1) |
| strlen key | O(1) |
| setrange key offset value | O(1) |
| getrange key start end | O(n),n是字符串长度,由于获取字符串非常快,所以如果字符串不是很长,可以视为 O(1) |
1.3 字符串类型的内部编码
字符串类型的内部编码有3种
第一种:int:8个字节的长整型
第二种:embstr:小于等于39个字符的字符串
第三种:raw:大于39个字节的字符串
Redis会根据当前的值的类型和长度决定使用哪种内部编码实现
int整数类型实列如下:
127.0.1:6379> set key 888
OK
127.0.1:6379> object encoding key
"int"
127.0.1:6379>
embstr测试
127.0.1:6379> set key embstr
OK
127.0.1:6379> object encoding key
"embstr"
127.0.1:6379>
rwa测试
127.0.1:6379> set key nijkjkljlkjkljkljlkjkljlkjkljkjlkjiojiojkljkljkl;jkljkl;jk;jl;kjkl;jkhjhjhjkhuihhjkhjkhjkhjk
OK
127.0.1:6379> object encoding key
"raw"
127.0.1:6379>
2 哈希(hash)
几乎所有的编程语言都提供了哈希( hash)类型,它们的叫法各有不同有的是哈希、字典、关联数组。在Redis中,哈希类型是指键值本身又是一个键值对结构,形如value={ {field1,value1 },… fieldN,valueN}},Redis键值对和哈希类型二者的关系可以下图来表示。
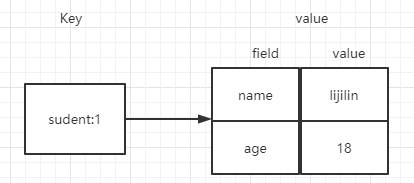
1.1 命令
1.1.1 设置值(hset)
hset key field value
实列:为studet:1添加一对field-value:
127.0.1:6379> hset student:1 name lijilin
(integer) 1
127.0.1:6379>
1.1.2 获取值(hget)
hget key field
实列:获取sudent:1的name域(属性)对应的值:
127.0.1:6379> hget student:1 name
"lijilin"
127.0.1:6379>
如果键或者field不存在,会返回nil
127.0.1:6379> hget student:2 name
(nil)
127.0.1:6379> hget student:1 age
(nil)
127.0.1:6379>
1.1.3 删除(hdel)
hdel key field [field …]
hdel会删除一个或多个field,返回结果为成功删除field的个数,例如:
127.0.1:6379> hdel sudent:1 name
(integer) 0
127.0.1:6379> hdel sudent:1 age
(integer) 0
127.0.1:6379>
1.1.4 计算field个数(hlen)
hlen key
实列:列如sudent:1 有2个field
127.0.1:6379> hset student:1 name xiaoming
(integer) 0
127.0.1:6379> hset student:1 age 18
(integer) 1
127.0.1:6379> hlen student:1
(integer) 2
127.0.1:6379>
1.1.5 批量设置(hmset)
hmset key field value [field value…]
实列:批量设置 student 两个field name和age
127.0.1:6379> hmset student name lijlin age 18
OK
127.0.1:6379>
1.1.6 批量获取(hmget)
hmget key field [field …]
实列:获取批量设置的student 的name 和age
127.0.1:6379> hmget student name age
1) "lijlin"
2) "18"
127.0.1:6379>
1.1.7 判断field是否存在(hexists)
hexists key field
实列:判断student age是否存在,存在返回1,不存在返回0
127.0.1:6379> hexists student age
(integer) 1
127.0.1:6379>
1.1.8 获取所有的field(hkeys)
hkeys命令应该叫hfields更为恰当,它返回指定哈希键所有的field
hkeys key
实列:获取student 的所有field
127.0.1:6379> hkeys student
1) "name"
2) "age"
127.0.1:6379>
1.1.9 获取所有的value(hvals)
hvals key
实列:获取student 所有value
127.0.1:6379> hvals student
1) "lijlin"
2) "18"
127.0.1:6379>
1.1.10 获取所有的fiedl-value(hgetall)
hgetall key
实列:获取studen 所有的field-value
127.0.1:6379> hgetall student
1) "name"
2) "lijlin"
3) "age"
4) "18"
127.0.1:6379>
在使用hgetall时,如果哈希元素个数比较多,会存在阻塞Redis的可能。如果开发人员只需要获取部分field,可以使用hmget,如果一定要获取全部field-value,可以使用hscan命令,该命令会渐进式遍历哈希类型。
1.1.11 自增指定整数(hincrby)
hincrby key field increment
实列:给student的age 指定增加10
127.0.1:6379> hincrby student age 10
(integer) 28
127.0.1:6379>
只能为整数 不为整数会返回错误
127.0.1:6379> hincrby student age 10.2
(error) ERR value is not an integer or out of range
127.0.1:6379>
1.1.12 自增浮点数(hincrbyfloat)
hincrbyfloat key field increment
实列:为studen 的float 自增浮点数10.22 然后再自增10 由此得出可以自增浮点数也可以是整数
127.0.1:6379> hincrbyfloat student float 10.22
"10.22"
127.0.1:6379> hincrbyfloat student float 10
"20.22"
127.0.1:6379>
1.1.13 计算value的字符串长度(hstrlen)
需要Redis3.2以上版本才支持。
hstrlen key field
实列:获取student 的 nage的value
127.0.1:6379> hstrlen student name
(integer) 6
127.0.1:6379>
1.2 哈希类型命令的时间复杂度
我们可以根据开发中的实际场景选择合适的命令
| 命令 | 时间复杂度 |
|---|---|
| hset key field value | O(1) |
| hget get field | O(1) |
| hdel key field [field …] | O(n),n是field的个数 |
| hlen key | O(1) |
| hgetall key | O(n),n是field的总数 |
| hmget key field [field …] | O(n),n是field的个数 |
| hmset kye field [field …] | O(n),n是field的个数 |
| hexists key field | O(1) |
| hkeys key | O(n),n是field的总数 |
| hvals key | O(n),n是field的总数 |
| hsetnx key value | O(1) |
| hincrby key field increment | O(1) |
| hincrbyfloat key field increment | O(1) |
| hstrlen key field | O(1) |
1.3 哈希类型的内部编码
哈希类型有两种内部编码:
- ziplist(压缩列表):
当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
- hashtable(哈希表):
当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O (1)。
实列1:当field的数量较少并且没有大于value时,内部编码是ziplist
127.0.1:6379> hmset hashtest a1 v1 b1 v2
OK
127.0.1:6379> object encoding hashtest
"ziplist"
127.0.1:6379>
实列2:当有value大于64个字节,内部编码或有ziplist转为hashtable
127.0.1:6379> hset hashtest a1 "dsafdsafdsafdasfdasjfkdasjfdsafdafdafdajklfdjakfdjaf dafdafdasfjdksafjdksafjdask;fjdaskf jdsafdasfhdjsahfdjsahfdjsahfdjsalfhdjsafhdjsalfhdjsafhdjsafhdsjafhdjasfhdsjafhdsajf dafdhsjafhdsajlfhdsajfhdjasfhdsjafhdsajfhas"
(integer) 0
127.0.1:6379> object encoding hashtest
"hashtable"
127.0.1:6379>
实列3:当field个数超过512时,内部编码或有ziplist转为hashtable
127.0.1:6379> hmset hashtest a1 v1 b1 v2 a3 v3 .....省略..... a513 v513
OK
127.0.1:6379> object encoding hashtest
"hashtable"
3 列表(list)
列表(list)类型是用来存储多个有序的字符串,列如对a、b、c、d、e五个元素从左到右组成了一个有序的列表,列表中的每个字符串称为元素(element),一个列表最多可以存储232-1个元素。在Redis中,可以对列表两端(左右两端)插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景。
列表两端插入和弹出操作 示意图

子列表获取删除操作示意图
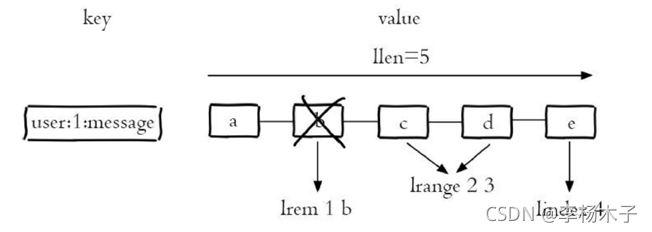
列表类型有两个特点:第一、列表中的元素是有序的,这就意味着可以通过索引下标获取某个元素或者某个范围内的元素列表,例如要获取下图的第5个元素,可以执行lindex user: 1: message4(索引从0算起)就可以得到元素e。第二、列表中的元素可以是重复的。

1.1 命令
集合(list)的5种操作类型的命令如下
| 操作类型 | 操作 |
|---|---|
| 添加 | rpush lpush linsert |
| 查 | lrange lindex llen |
| 删除 | lpop rpop lrem ltrim |
| 修改 | lset |
| 阻塞操作 | blpop brpop |
1.1 添加操作
(1)从右边插入元素
rpush key value [vaule …]
实列:
127.0.1:6379> rpush listkeys c b a
(integer) 3
127.0.1:6379>
lrange0 -1命令可以从左到右获取列表的所有元素:
127.0.1:6379> lrange listkeys 0 -1
1) "c"
2) "b"
3) "a"
127.0.1:6379>
(2)从左边插入元素
lpush key value [value …]
实列:从左边插入 a b c 三个元素
127.0.1:6379> lpush listkeysl a b c
(integer) 3
127.0.1:6379>
(3)向指定元素的前或者后插入元素
linsert key before|after pivot value
linsert命令会从列表中找到等于(指定的元素)pivot的元素,在其前(before)或者后(after)插入一个新的元素value
实列:对集合listkeys 的b元素前插入 元素值为Java
127.0.1:6379> linsert listkeys before b java
(integer) 4
127.0.1:6379>
返回结果为4,代表当前命令的长度,当前列表变更为
127.0.1:6379> lrange listkeys 0 -1
1) "c"
2) "java"
3) "b"
4) "a"
127.0.1:6379>
1.2 查找
(1)获取指定范围内的元素列表
lrange key start end
lrange操作会获取列表指定范围所有的元素。索引下标有两个特点:
第一,索引下标从左到右分别是0~N-1,但是从右到左分表是-1~-N.
地儿,lrange中的end选项包含了自身,列如获取列表第2到第4个元素,如下:
127.0.1:6379> lrange listkeys 1 3
1) "java"
2) "b"
3) "a"
127.0.1:6379>
(2)获取列表指定索引下标的元素
lindex key index
列如:查找列表最后一个元素
127.0.1:6379> lindex listkeys -1
"a"
127.0.1:6379>
(3)获取列表的长度
llen key
列如:获取listkeys列表的长度
127.0.1:6379> llen listkeys
(integer) 4
127.0.1:6379>
1.3 删除
(1)从列表左侧弹出(删除)元素
lpop key
列如:删除listkeys列表最后最左侧的元素
我们先看一下弹出之前的列表
127.0.1:6379> lrange listkeys 0 -1
1) "c"
2) "java"
3) "b"
4) "a"
127.0.1:6379>
弹出命令
127.0.1:6379> lpop listkeys
"c"
127.0.1:6379>
弹出后listkeys列表变更为:Java、b、a
弹出后就代表该元素已经取出,所以不会在列表中
127.0.1:6379> lrange listkeys 0 -1
1) "java"
2) "b"
3) "a"
127.0.1:6379>
(2)从列表右侧弹出
rpop key
它的用法和lpop是一样的,只不过从列表右侧弹出
我们先看一下弹出之前的listkeys列表
127.0.1:6379> lrange listkeys 0 -1
1) "c"
2) "java"
3) "b"
4) "a"
127.0.1:6379>
从右侧弹出
127.0.1:6379> rpop listkeys
"a"
127.0.1:6379>
弹出之后listkeys列表为
127.0.1:6379> lrange listkeys 0 -1
1) "c"
2) "java"
3) "b"
127.0.1:6379>
(3)删除指定元素
lrem key count value
lerm命令会从列表中找到等于value的元素进行删除,根据count的不同分为三种情况:
| 情况 | 操作 |
|---|---|
| count>0 | 从左到右,删除最多count个元素 |
| count<0 | 从右到左,删除最多count绝对值个元素 |
| count=0 | 删除所有元素 |
列如:想列表从左到右插入5个a,列表变为 ”a a a a a c java b“
127.0.1:6379> lpush listkeys a a a a a
(integer) 8
127.0.1:6379> lrange listkeys 0 -1
1) "a"
2) "a"
3) "a"
4) "a"
5) "a"
6) "c"
7) "java"
8) "b"
127.0.1:6379>
下面操作从列表左边开始删除4个为a的元素
127.0.1:6379> lrem listkeys 4 a
(integer) 4
127.0.1:6379> lrange listkeys 0 -1
1) "a"
2) "c"
3) "java"
4) "b"
127.0.1:6379>
从右到左删除测试:listkeys列表从右删除元素b
127.0.1:6379> lrem listkeys -1 b
(integer) 1
127.0.1:6379> lrange listkeys 0 -1
1) "a"
2) "c"
3) "java"
127.0.1:6379>
删除所有a元素测试
127.0.1:6379> lrem listkeys 0 a
(integer) 1
127.0.1:6379> lrange listkeys 0 -1
1) "c"
2) "java"
127.0.1:6379>
(4)按照索引范围修剪列表
ltrim key start end
我问先看一下操作之前的列表数据
127.0.1:6379> lrange listkeys 0 -1
1) "b"
2) "a"
3) "c"
4) "java"
127.0.1:6379>
只保留列表listkeys 第2个到第4个元素
127.0.1:6379> ltrim listkeys 1 3
OK
127.0.1:6379> lrange listkeys 0 -1
1) "a"
2) "c"
3) "java"
127.0.1:6379>
1.4 修改
修改指定索引下标的元素
lset key index newVaule
列如:将列表listkeys中的第三个元素改为c++
我们先看看修改之前的列表数据
127.0.1:6379> lrange listkeys 0 -1
1) "a"
2) "c"
3) "java"
127.0.1:6379>
修改第三个元素为c++
127.0.1:6379> lset listkeys 2 c++
OK
127.0.1:6379> lrange listkeys 0 -1
1) "a"
2) "c"
3) "c++"
127.0.1:6379>
1.5 阻塞操作
阻塞式弹出如下:
blpop key [key …] timout
brpop key [ke …] timout
blpop和brpop是lpop和rpop的阻塞版本,它们除了弹出方向不同,使用方法基本相同,所以下面以brpop命令进行说明,brpop命令包含两个参数:
brpop命令包含两个参数:
- key[key …]:多个列表的键
- timeout:阻塞时间(单位:秒)
(1)列表为空:如果timeout=3,那么客户端要等到3秒后返回,如果timeout=0,那么客户端一直阻塞等下去
127.0.1:6379> brpop list:test 3
(nil)
(3.05s)
127.0.1:6379>
127.0.1:6379> brpop list:test 0
....阻塞.......
如果在此期间添加了元素a,客户端会立即返回
127.0.1:6379> brpop list:test 3
1) "list:test"
2) "a"
127.0.1:6379>
(2.05s)
127.0.1:6379>
(2)列表不为空:客户端会立即返回
127.0.1:6379> brpop list:test 0
1) "list:test"
2) "a"
127.0.1:6379>
在使用brpop时,需要注意以下2点:
- 第1点:如果是多个键,那么brpop会从左到右遍历键,一旦有一个键能弹出元素,客户端会立即返回
127.0.1:6379> brpop list:1 list:2 list:3 0
..阻塞..
此时另一个客户端分别向list:2和list:3插入元素:
client-lpush> lpush list : 2 element2
(integer) 1
client-lpush> lpush list: 3
element3integer) i
客户端会立即返回list:2中的element2,因为lsit:2最先有可以弹出的元素
127.0.1:6379> brpop list:1 list:2 list:3 0
1) "list:2"
2) "elemnt2"
127.0.1:6379>
- 第2点:如果多个客户端对同一个键执行brpop,那么最先执行brpop命令的客户端可以获取到弹出值
客户端1:
client-1> brpop list:test o
...阻塞...
|客户端2:
client-2> brpop list:test o
...阻塞...
|客户端3:
client-3> brpop list:test o
...阻塞...
此时另一个客户端lpush一个元素到list:test列表中
127.0.1:6379> lpush list:test a
(integer) 1
那么客户端1会最先获取到元素,因为客户端1最先执行brpop,而客户端2和客户端3继续阻塞
client-1> brpop list:test o
1)"list:test"
2) "a"
1.2 列表命令的时间复杂度
以下是列表命令的时间复杂度,我们可以根据开发中的实际情况参考此表选择合适的命令
| 操作类型 | 命令 | 时间复杂度 |
|---|---|---|
| 添加 | rpush key value [value …] | O(k),k是元素个数 |
| 添加 | lpush key value [value …j | O(k),k是元素个数 |
| 添加 | linsert key beforelafter pivot value | O(N).n是 pivot距离列表头或尾的距离 |
| 查找 | lrange key start end | O(s+n),s是start偏移量,n是start到end的范围 |
| 查找 | lindex key index | O(n),n是索引的偏移量 |
| 查找 | llen key | O(1) |
| 删除 | ipop key | O(1) |
| 删除 | rpop key | O(1) |
| 删除 | lrem count value | O(n),n是列表长度 |
| 删除 | ltrim key start end | O(n).n是要裁勇的元素总数 |
| 修改 | lset key index value | O(o),n是索引的偏移量 |
| 阻塞操作 | blpop brpop | O(1) |
1.3 内部编码
列表类型的内部编码有两种
-ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时(默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。
-linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
Redis3.2版本提供了quicklist内部编码,简单地说它是以一个ziplist为节点的linkedlist,它结合了ziplist和linkedlist两者的优势,为列表类型提供了一种更为优秀的内部编码实现。
4 集合(set)
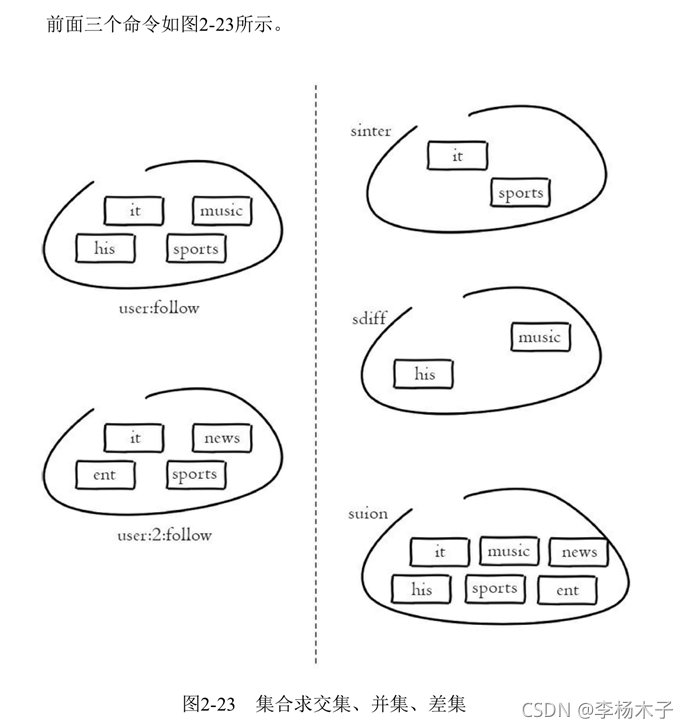
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。如图2-22所示,集合user: 1: follow包含
着"it"、“music”、“his”、"sports"四个元素,一个集合最多可以存储232-1个元素。Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多实际问题。
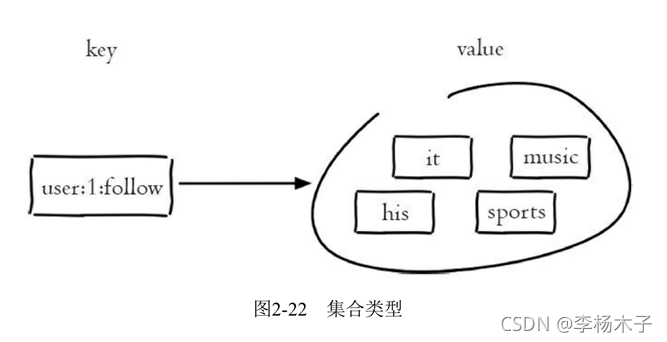
1.1 命令
我们按照集合内操作和集合间两个维度对集合的常用命令进行介绍
1.1 集合内操作
1.1.1 添加元素(sadd )
sadd key element [element …]
返回结果为添加成功元素的个数。列如
127.0.1:6379> exists myset
(integer) 0
127.0.1:6379> sadd myset a b c
(integer) 3
127.0.1:6379> sadd myset a b
(integer) 0
127.0.1:6379>
集合中的元素不能重复,所以sadd myset a b 返回结果为0
1.1.2 删除元素(srem )
srem key element [element …]
返回结果为删除成功元素的个数,列如
127.0.1:6379> srem myset a b
(integer) 2
//不存在的元素则返回0
127.0.1:6379> srem myset java
(integer) 0
127.0.1:6379>
1.1.3 计算元素个数(scard )
scard key
scard的时间复杂度为O(1),它不会遍历集合所有元素,而是直接用Redis内部的变量,列如
127.0.1:6379> scard myset
(integer) 1
127.0.1:6379>
1.1.4 判断元素是否在集合中(sismember )
sismember key element
如果给定元素在集合内则返回1,不存在返回0,列如
//存在
127.0.1:6379> sismember myset c
(integer) 1
//不存在
127.0.1:6379> sismember myset java
(integer) 0
127.0.1:6379>
1.1.5 随机从集合返回指定多少个元素(srandmember)
srandmember key[count]
[count]是可选参数,如果不写默认为1,列如
127.0.1:6379> srandmember myset 3
1) "d"
2) "b"
3) "a"
127.0.1:6379> srandmember myset
"e"
127.0.1:6379>
1.1.6 获取所有元素(smembers)
smembers key
下面获取myst所有元素,并且返回结果是无序的:
127.0.1:6379> smembers myset
1) "e"
2) "d"
3) "b"
4) "c"
5) "a"
127.0.1:6379>
smembers和lrange、hgetall都属于比较重的命令,如果元素过多存在阻塞Redis的可能性,这时候可以使用sscan来完成
1.1.7 从集合中随机弹出
spop key
spop操作可以从集合中随机弹出一个元素
127.0.1:6379> smembers myset
1) "e"
2) "d"
3) "b"
4) "c"
5) "a"
127.0.1:6379> spop myset
"a"
127.0.1:6379> smembers myset
1) "e"
2) "d"
3) "b"
4) "c"
127.0.1:6379>
1.2 集合间操作
现在有两个集合,他们分别是student:1:follow和student:2:follow
127.0.1:6379> sadd studet:1:follow it music his sports
(integer) 4
127.0.1:6379> sadd studet:2:follow it news ent sports
(integer) 4
127.0.1:6379>
1.1.1 求多个集合的交集(sinter )相同元素
sinter key [key …]
列如:求student:1:follow和student:2:follow两个集合的交集,返回结果如下
127.0.1:6379> sinter studet:1:follow studet:2:follow
1) "it"
2) "sports"
127.0.1:6379>
1.1.2 求多个集合的并集(sunion )多个集合所有的元素
sunion key [key …]
列如:求student:1:follow和student:2:follow两个集合的并集,返回结果如下
127.0.1:6379> sunion studet:1:follow studet:2:follow
1) "ent"
2) "music"
3) "news"
4) "his"
5) "it"
6) "sports"
127.0.1:6379>
1.1.3 求多个集合的差集(sdiff )不相同的元素
sdiff key [key …]
列如:求student:1:follow和student:2:follow两个集合的差集,返回结果如下
127.0.1:6379> sdiff studet:1:follow studet:2:follow
1) "music"
2) "his"
127.0.1:6379>
1.1.4 将交集、并集、差集的结果保存
sinterstore destination key [key …]
suinstore destination key [key …]
sdiffstore destination key [key …]
集合间的运算在元素较多的情况下会比较耗时,所以Redis提供了上面三个命令(原命令+store)将集合间交集、并集、差集的结果保存在destination key中,例如下面操作将studet: 1: follow和studet: 2: follow两个集合的交集结果保存在studet: 1_2: inter中,studet: 1_2: inter本身也是集合类型:
sinterstore destination key [key ...] 测试
127.0.1:6379> sinterstore student:1_2 studet:1:follow studet:2:follow
(integer) 2
127.0.1:6379> smembers student:1_2
1) "it"
2) "sports"
127.0.1:6379>
1.3 集合常用命令时间复杂度
下表是集合命令的时间复杂度,平时开发可以根据实际需求对照下表选择合适的命令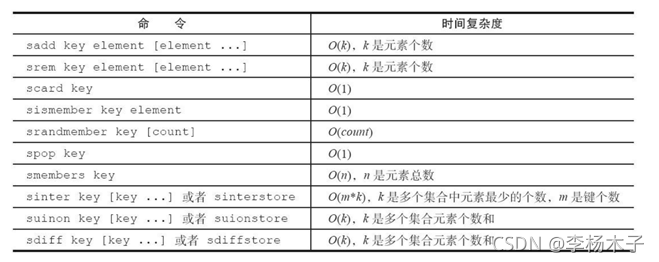
1.4 内部编码
集合的内部编码有2种:
-intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。
-hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
下面有列子来说明
1.1.1 当元素个数较少且都为整数时,内部编码为inset:
127.0.1:6379> sadd setkey 1 2 3 4
(integer) 4
127.0.1:6379> object encoding setkey
"intset"
127.0.1:6379>
1.1.2 当元素个数超过512个,内部编码变为hashtable
127.0.1:6379> sadd setkey 1 2 3 4 6 ... 512 513
(integer) 509
127.0.1:6379> object encoding setkey
"hashtable"
127.0.1:6379>
1.1.3 当元素不为整数时,内部编码变为hashtable
127.0.1:6379> sadd setkeys a b c d e
(integer) 5
127.0.1:6379> object encoding setkeys
"hashtable"
1.5 使用场景
集合类型比较典型的使用场景是标签( tag)。例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于用户体验以及增强用户黏度比较重要。例如一个电子商务的网站会对不同标签的用户做不同类型的推荐,比如对数码产品比较感兴趣的人,在各个页面或者通过邮件的形式给他们推荐最新的数码产品,通常会为网站带来更多的利益。

用户和标签的关系维护应该在一个事务内执行,防止部分命令失败造成数据的不一致。

前面只是给出了使用Redis集合类型实现标签的基本思路,实际上一个标签系统远比这个要复杂得多,不过集合类型的应用场景通常为以下几种:
- sadd=Taggin(标签)
- spop/srandmember=Random item (生成随机数,比如抽奖)
- sadd+sinter=Social Graph (社交需求)
5 有序集合(set)
既然叫它有序集合那么和集合必然有着联系,它保留了集合不能有重复成员的特性,但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据。如下图所示,该有序集合包含kris、mike、frank、tim、martin、tom,它们的分数分别是1、91、200、220、250、251,有序集合提供了获取指定分数和元素范围查询、计算成员排名等功能,合理的利用有序集合,能帮助我们在实际开发中解决很多问题。
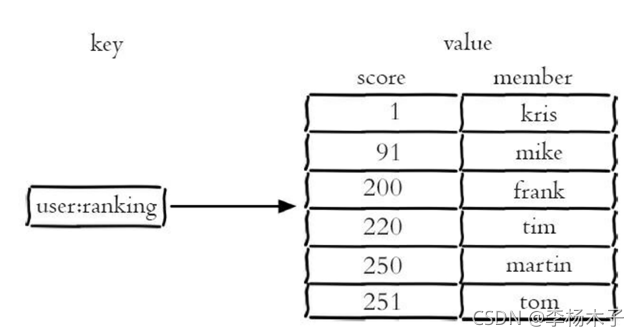
有序集合中的元素不能重复,但是score可以重复,就和一个班的的学号不能重复,但是分数可以一样是同一个道理。
列表、集合、有序集合三者的异同点
| 数据结构 | 是否允许重复元素 | 是否有序 | 有序实现方式 | 应用场景 |
|---|---|---|---|---|
| 列表 | 是 | 是 | 索引下标 | 时间轴、消息列队 |
| 集合 | 否 | 否 | 无 | 标签、社交等 |
| 有序集合 | 否 | 是 | 分值 | 排行榜系统、社交等 |
1.1 命令
我们按照集合内和集合外两个维度对有序集合的命令进行介绍
1.1.1 集合内
1.1.1.1 添加(zadd)
zadd key [NX| XX] [GTILT] [CH][INCR] score member [score member …]
列如:给user:1集合添加用户xiaoming 他的分数为200
127.0.1:6379> zadd user:1 200 xiaoming
(integer) 1
127.0.1:6379>
返回结果代表添加成功的成员个数
127.0.1:6379> zadd user:1 1 xiaohei 80 xiaohua 100 lilin
(integer) 3
127.0.1:6379>
在使用zadd命令有两点需要注意:
(1)Redis3.2为zadd命令添加了 nx、xx、ch、incr四个选用
| 选项 | 用途 |
|---|---|
| nx | member必须不存在,才可设置成功 用于添加 |
| xx | member必须存在,才可设置成功 用于跟新 |
| ch | 返回此次操作后,有序集合元素和分数发生变化的个数 |
| incr | 对score做增加,相当于zincrby |
(2)有序集合相比集合提供了排序字段,但是性能就没有集合好,zadd的时间复杂度为O(log(n)),sadd时间复杂度为O(1).
1.1.1.2 计算成员个数(zcard)
zcard key
列如:返回有序集合user:1的成员数,时间复杂度为O(1)
127.0.1:6379> zcard user:1
(integer) 4
127.0.1:6379>
1.1.1.3 计算某成员的分数score(zcore)
127.0.1:6379> zscore user:1 xiaoming
"200"
127.0.1:6379>
如果成员不存在,则返回的是nil
127.0.1:6379> zscore user:1 tom
(nil)
127.0.1:6379>
1.1.1.4 计算某成员的排名(zrank/zrevrank)
zrank key member
zrevrank key member
zrank 是将分数从低到高返回排名
zrevrank 是将分数从高到低返回排名
列如:xiaoming的排名
127.0.1:6379> zrank user:1 xiaoming
(integer) 3
127.0.1:6379> zrevrank user:1 xiaoming
(integer) 0
127.0.1:6379>
1.1.1.5 删除(zrem)
zrem key memebr[memeber …]
列如:从user:1有序集合中删除成员xiaoming
127.0.1:6379> zrem user:1 xiaoming
(integer) 1
127.0.1:6379>
返回结果为删除成功的个数
1.1.1.6 增加成员分数(zincrby)
zincrby key increment member
列如:为成员xiaohei 原来分数1分 分数增加9分后分数变为10分
127.0.1:6379> zincrby user:1 9 xiaohei
"10"
127.0.1:6379>
1.1.1.7 返回指定排名范围的成员(zrange/zrevrange)
zrange key start end [withscores]
zrevrange key start end [withscores]
有序集合是按照分值score进行排序
zrange 从低到高,zrevrange 从高到低
加上withscores 则会同时返回分数
列如:按照从低到高排序返回前3的成员
127.0.1:6379> zrange user:1 0 2 withscores
1) "xiaohei"
2) "10"
3) "xiaohua"
4) "80"
5) "lilin"
6) "100"
127.0.1:6379>
按照从高到低排序
127.0.1:6379> zrevrange user:1 0 2 withscores
1) "lilin"
2) "100"
3) "xiaohua"
4) "80"
5) "xiaohei"
6) "10"
127.0.1:6379>
1.1.1.8 返回指定分数范围内的成员
zrangebyscore key min max [withscores] [limit offset count]
zrevrangebyscore key max min [withscores] [limit offset count]
其中zangebyscore按照分数从低到高返回,zrevrangebyscore反之。例如下面操作从低到高返回80到100分的成员,withscores选项会同时返回每个成员的分数。[limit offset count]选项可以限制输出的起始位置和个数:
127.0.1:6379> zrangebyscore user:1 80 100 withscores
1) "xiaohua"
2) "80"
3) "lilin"
4) "100"
127.0.1:6379> zrevrangebyscore user:1 100 80 withscores
1) "lilin"
2) "100"
3) "xiaohua"
4) "80"
127.0.1:6379>
同时min和max还支持开区间(小括号)和闭区间(中括号),-inf和+inf分别代表无限小和无限大
127.0.1:6379> zrangebyscore user:1 (80 +inf withscores
1) "lilin"
2) "100"
127.0.1:6379>
1.1.1.9 返回指定分数范围的成员(zcount)
zcount key min max
返回80到100分的成员国个数
127.0.1:6379> zcount user:1 80 100
(integer) 2
127.0.1:6379>
1.1.1.10 删除指定排名内的升序元素
zremrangebyrank key start end
删除0~2名的成员
127.0.1:6379> zremrangebyrank user:1 0 2
(integer) 3
127.0.1:6379>
1.1.1.11 删除指定分数范围的成员
zremrangebyscore key min max
列如:删除200分以上的全部成员
先添加一些数据
127.0.1:6379> zadd user:1 200 xiaoming
(integer) 1
127.0.1:6379> zadd user:1 260 tom
(integer) 1
127.0.1:6379>
127.0.1:6379> zremrangebyscore user:1 (200 +inf
(integer) 1
127.0.1:6379>
1.1.2 集合间的操作
将下图两个有序集合导入redis中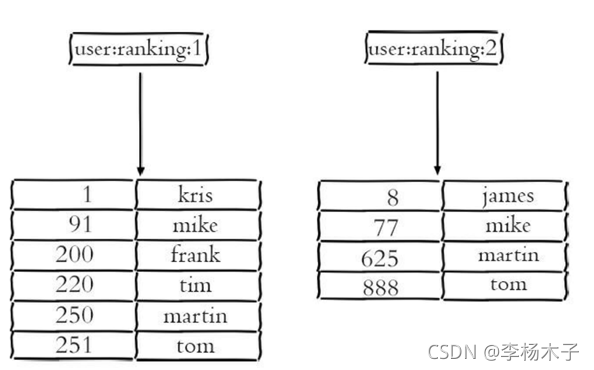
127.0.1:6379> zadd user:ranking:1 1 kris 91 mike 200 frank 220 tim 250 martin 251 tom
(integer) 6
127.0.1:6379> zadd user:ranking:2 8 james 77 mike 625 martin 888 tom
(integer) 4
127.0.1:6379>
1.1.1.1 交集
zinterstore destination numkeys key [key …] [weights weight [weight …]] [ aggregate sum / min l max ]
这个命令参数说明如下:
| 参数 | 说明 |
|---|---|
| destination | 交集计算结果保存的键 |
| numkeys | 需要做交集计算键的个数 |
| numkeys | 需要做交集计算键的个数 |
| key [key …] | 需要做交集计算键 |
| weights weight [weight …] | 每个键的权重,在做交集计算时,每个键中的每个member会将自己分数乘以这个权重,每个默认权重为1 |
| aggregate sum / min l max | 计算成员交集后,分值可以按照sum(和)、min(最小)、max(最大值)最汇总,默认是sum |
下面操作对user: ranking:1和user: ranking: 2做交集,weights和aggregate使用了默认配置,可以看到目标键user: ranking: l_inter_2对分值做了sum操作

如果想让user: ranking: 2的权重变为0.5,并且聚合效果使用max,可以执行如下操作:

1.1.1.2 并集
zunionstore destination numkeys key [key …] [weights weight [weight …]] [ aggregate sum / min l max ]
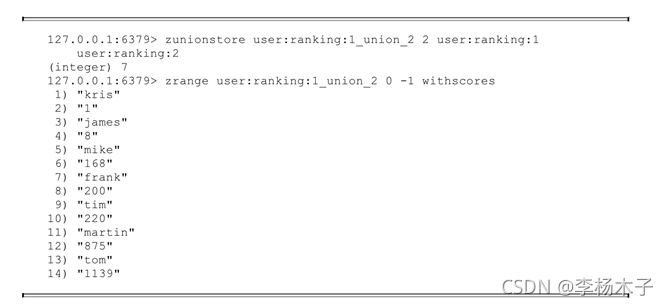
该命令的所有参数和zinterstore是一致的,只不过是做并集计算,例如下面操作是计算user: ranking:1和user: ranking:2的并集,weights和aggregate使用了默认配置,可以看到目标键user: ranking: 1_union_2对分值做了sum操作:
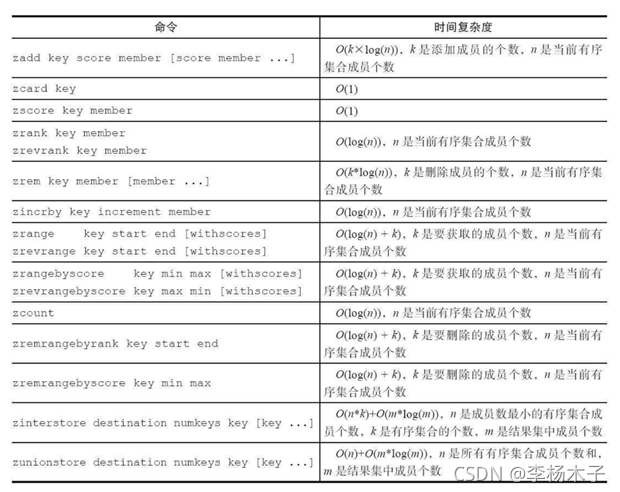
1.2 有序集合命令的时间复杂度
1.3 内部编码
有序集合的内部编码有两种
-ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,ziplist可以有效减少内存的使用。
-skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降。
(1)当元素个数较少且每个元素较小时,内部编码为ziplist

(2) 当元素个数超过128个,内部编码为"skiplist"

(3) 当某个元素大于64字节时,内部编码也会变为"skiplist"
127.0.1:6379> zadd zsetkey 20 "one string is bigger than 64 btye ..................................."
(integer) 1
127.0.1:6379> object encoding zsetkey
"skiplist"
1.4 使用场景
有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。本节使用赞数这个维度,记录每天用户上传视频的排行榜。主要需要实现以下4个功能。
1.1.1 添加用户赞数
例如用户mike上传了一个视频,并获得了3个赞,可以使用有序集合的zadd和zincrby功能:

如果之后再获得要给赞,可以使用zincrby

1.1.2 取消用户赞数
由于各种原因(例如用户注销、用户作弊)需要将用户删除,此时需要将用户从榜单中删除掉,可以使用zrem。例如删除成员tom:

1.1.3 展示获取赞数最多的十个用户
此功能使用zevrange命令实现:
1.1.4 展示用户信息以及用户分数
此功能将用户名作为键后缀,将用户信息保存在哈希类型中,至于用户的分数和排名可以使用zscore和zrank两个功能:
