一、HIVE的定义
Hive是一个基于 Hadoop 的数据仓库工具,可以将结构化的数据文件映射成一张数据表,并可以使用类似SQL的方式来对数据文件进行读写以及管理。这套Hive SQL 简称HQL。Hive的执行引擎可以是MR、Spark、Tez。
本质
Hive的本质是将HQL转换成MapReduce任务,完成整个数据的分析查询,减少编写MapReduce的复杂度 。
二、Hive的优缺点
优点
1.学习成本低:提供了类SQL查询语言HQL,使得熟悉SQL语言的开发人员无需关心细节,可以快速上手.
2.海量数据分析:底层是基于海量计算到MapReduce实现.
3.可扩展性:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统),Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
4.延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
5.良好的容错性:某个数据节点出现问题HQL仍可完成执行。
6.统计管理:提供了统一的元数据管理
缺点
1.Hive的HQL表达能力有限
2.迭代式算法无法表达.
3.Hive的效率比较低.
4.Hive自动生成的MapReduce作业,通常情况下不够智能化.
5.Hive调优比较困难,粒度较粗.
三、Hive的架构
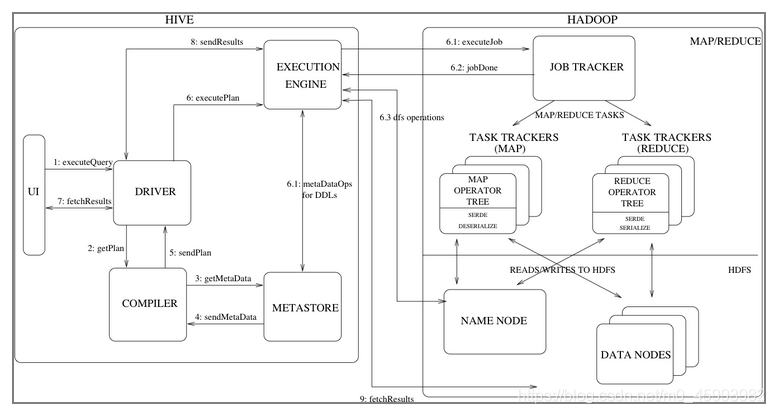 Hive一些重要的组件:
Hive一些重要的组件:
UI:主要是Hive的各种客户端。这是用户使用Hive的窗口,包括我们之前使用的HiveCli、Beeline等CLI,以及一些Web GUI接口。用户通过UI来提交自己的操作请求。
Driver:接收用户查询,并且实现了会话处理,基于JDBC/ODBC实现了执行、拉取数据等API。
Compiler:解析查询语句,做语义分析,最终借助在Metastore中查询到的表和分区的元数据生成执行计划(execution plan),这个和传统的RDBMS比较像。当然其实Hive也有优化器(Optimizer),图中没有画出来。
Metastore:存储表和分区的元数据信息,包括字段、字段类型、读写数据需要的序列化和反序列化信息。
Execution Engine:执行引擎,用来执行Compiler生成的执行计划,是Hive和Hadoop之间的桥梁。现在Hive支持的计算引擎包括MR(逐渐废弃)、Tez、Spark。
下面我们看看一下一次查询的完整流程(下面的step n对应图中的数组序号):
- 用户通过UI提交自己的查询请求到Driver(step 1);
- Driver创建一个会话来处理用户的这次请求,将请求发到Compiler以生成执行计划(step 2);
- Compiler从Metastore获取一些必要的元数据信息(step 3、4),做类型检查以及一些优化操作,然后最终生成执行计划发送给Driver(step 5),Driver再将执行计划发送给Execution Engine(以下简称EE)。
- EE拿到执行计划之后,会发送给合适的组件(step 6.1、6.2、6.3)。Hive的数据存储在HDFS上,所以执行的时候必然要和HDFS打交道。比如要先去NameNode上面查询数据的位置,然后去DataNode上面获取数据。如果是DDL操作的话(比如CREATE、DROP、ALTER等),还要和Hive的MetaStore通信。图中画的是使用MR的情况,MR可能有多个阶段,中间也会生成一些临时文件,这些文件都存储在HDFS上面。如果是DML操作,最后会将临时文件直接重命名(HDFS的重命名是一个原子操作)为最终的表名。如果是查询语句,Driver会调用fetch语句,通过Execution Engine直接从HDFS上面读取临时文件。
四、表类型详解
- 表分类
在Hive中,表类型主要分为两种:
内部表: 也叫管理表,表目录会创建在hdfs的/user/hive/warehouse/下的相应的库对应的目录中。
外部表: 外部表会根据创建表时LOCATION指定的路径来创建目录,如果没有指定LOCATION,则位置跟内部表相同,一般使用的是第三方提供的或者公用的数据。
- 两者之间区别
内部表和外部表在创建时的差别
内部表
CRAATE TABLE T_INNER(ID INT);
外部表
CREATE EXTERNAL TABLE T_OUTER(ID INT) LOCATION 'HDFS:///AA/BB/CC';
Hive表创建时要做的两件事:
- 在HDFS下创建表目录
- 在元数据库Mysql创建相应表的描述数据(元数据)
drop时有不同的特性:
- drop时,元数据都会被清除
- drop时,内部表的表目录会被删除,但是外部表的表目录不会被删除。
使用场景
内部表:平时用来测试或者少量数据,并且自己可以随时修改删除数据。
外部表使用后数据不想被删除的情况使用外部表(推荐)所以,整个数据仓库的最底层的表使用外部表。
Hive 的基本操作
1. 注释语法:
-- 单行注释
// 单行注释
/*
* 多行注释
*/
2. 大小写规则:
Hive的数据库名、表名都不区分大小写
建议关键字大写
3. 命名规则:
- 名字不能使用数字开头
- 不能使用关键字
- 尽量不使用特殊符号
- 如果表比较多,那么表名和字段名可以定义规则加上前缀.
4. 快速创建库和表:
-- hive有一个默认的数据库default,如果不明确的说明要使用哪个库,则使用默认数据库。
hive> create database user;
hive> create database if not exists user;
hive> create database if not exists db comment 'this is a database of practice';
-- 创建库的本质:在hive的warehouse目录下创建一个目录(库名.db命名的目录)
-- 切换库:
hive> use uer;
--创建表
hive> create table t_user(id int,name string);
-- 使用库+表的形式创建表:
hive> create table db.t_user(id int,name string);
--创建表时加上加载数据的分隔符
create table t_user ( id int, name string )
row format delimited fields terminated by ',';
5.查看表
# 查看当前数据库的表
show tables;
# 查看另外一个数据库中的表
show tables in zoo;
# 查看表信息
desc tableName;
# 查看详细信息
desc formatted tableName;
#查看创建表信息
show create table tableName;
6.修改表
修改表名
alter table t7 rename to a1;
修改列名
alter table a1 change column name name1 string;
修改列的位置
alter table log1 change column ip ip string after status;
修改字段类型+修改注释
alter table a1 change column name1 name string comment '修改字段名';
增加字段
alter table a1 add columns (sex int);
替换字段
alter table a1 replace columns
( id int, name string, size int, pic string );
内部表和外部表转换
内部表转外部表,true 一定要大写;
alter table a1 set tblproperties('EXTERNAL'='TRUE');
false大小写都没有关系
alter table a1 set tblproperties('EXTERNAL'='false');
7.加载数据到Hive
- load方式读文件
-- 从hdfs中加载数据
hive> load data inpath 'hivedata/user.csv' into table user;
-- 从本地加载数据
hive> load data local inpath 'hivedata/user.csv' into table user;
加载数据的本质:
- 如果数据在本地,加载数据的本质就是将数据copy到hdfs上的表目录下。
- 如果数据在hdfs上,加载数据的本质是将数据移动到hdfs的表目录下。
- 如果重复加载同一份数据,不会覆盖
注意:
Hive使用的是严格的读时模式:加载数据时不检查数据的完整性,读时发现数据不对则使用NULL来代替。
Mysql使用的是写时模式:在写入数据时就进行检查。
- insert into 方式灌入数据
先创建一个和旧表结构一样的表
create table usernew(
id int,
name string
)
comment 'this is a table'
row format delimited fields terminated by ','
lines terminated by '\n' stored as textfile;
- 克隆表
不带数据,只克隆表的结构
-- 从usernew 克隆新的表结构到userold
create table if not exists userold like usernew;
克隆表并带数据
create table t7
as
select * from t6;
8.Hive Shell技巧
查看所有hive参数
hive> set
只执行一次Hive命令
[root@hadoop01 hive]# hive -e "select * from cat"
单独执行一个sql文件
[root@hadoop01 hive]# hive -f /path/cat.sql
执行Linux命令
加上前缀! 最后以分号;结尾,可以执行linux的命令
hive> ! pwd ;
执行HDFS命令
hive> dfs -ls /tmp
五、分区表
1.分区的原因
随着系统运行的时间越来越长,表的数据量越来越大,而hive查询通常是使用全表扫描,这样 会导致大量不必要的数据扫描,从而大大降低了查询的效率。
为了提高查询的效率,从而引进分区技术,使用分区技术,能避免hive做全表扫描,从而提交查询效率。可以将用户的整个表在存储上分成多个子目录(子目录以分区变量的值来命名)。
可以让用户在做数据统计的时候缩小数据扫描的范围,因为可以在select是指定要统计 哪个分区,譬如某一天的数据,某个地区的数据等.
分区本质
在表的目录或者是分区的目录下在创建目录,
分区的目录名为指定字段=值
2.创建分区表
通过下面的 partitioned by 指定分区名,另外分区名(dt)是一个伪字段,是在part1之外的字段
create table if not exists part1(
id int,
name string
)
-- 根据需求选择,数据非常大才需要三级分区
-- 一级分区
partitioned by (dt string)
-- 二级分区
partitioned by (year string,month string)
-- 三级分区
partitioned by (year string,month string,day string)
row format delimited fields terminated by ',';
3.分区表基本操作
- 分区表加载数据
-- 一级分区
load data local inpath "/opt/data/user.txt" into table part1
partition(dt="2019-08-08");
-- 二级分区
load data local inpath '/opt/soft/data/user.txt' into table part2
partition(year='2020',month='02');
-- 三级分区
load data local inpath '/opt/soft/data/user.txt' into table part3
partition(year='2020',month='02',day='20');
- 新增分区
alter table part5 add partition(dt='2020-03-21');
- 增加分区并设置数据
alter table part5 add partition(dt='2020-11-11')
location '/user/hive/warehouse/part1/dt=2019-08-08';
- 修改分区的hdfs的路径
alter table part5 partition(dt='2020-03-21')
set location 'hdfs://hadoop01:8020/user/hive/warehouse//part1/dt=2019-09-11'
- 删除分区
alter table part5 drop partition(dt='2020-03-24'),partition(dt='2020-03- 26');
4.分区表类型
- 静态分区
加载数据到指定分区的值,新增分区或者加载分区时指定分区名
- 动态分区
数据未知,根据分区的值来确定需要创建的分区。
动态分区的属性配置
是否能动态分区
hive.exec.dynamic.partition=true
设置为非严格模式
hive.exec.dynamic.partition.mode=nonstrict
最大分区数
hive.exec.max.dynamic.partitions=1000
最大分区节点数
hive.exec.max.dynamic.partitions.pernode=100
创建动态分区表
create table dy_part1(
id int,
name string
)
partitioned by (dt string)
row format delimited fields terminated by ',';
加载数据
先创建临时表导入数据后:
insert into dy_part1 partition(dt)
select id,name,dt from temp_part;
- 混合分区
静态和动态都有。
创建混合分区表
create table dy_part2(
id int,
name string
)
partitioned by (year string,month string,day string)
row format delimited fields terminated by ',';
加载数据
先创建临时表导入数据后:
insert into dy_part2 partition (year='2020',month,day)
select id,name,month,day from temp_part2;
- 注意
1.hive的分区使用的是表外字段,分区字段是一个伪列,但是分区字段是可以做查询
过滤。
2.分区字段不建议使用中文
3.一般不建议使用动态分区,因为动态分区会使用mapreduce来进行查询数据,如果分区数据过多,导致 namenode 和 resourcemanager 的性能瓶颈。所以建议在使用动态分区前尽可能预知分区数量。
4.分区属性的修改都可以使用修改元数据和hdfs数据内容。
五、分桶表
1.分桶的意义
当单个的分区或者表的数据量过大,分区不能更细粒度的划分数据,就需要使用分桶技术将数 据划分成更细的粒度。
2. 关键字及其原理
bucket
分桶的原理:跟MR中的HashPartitioner原理一样,都是key的hash值取模reduce的数量
MR中:按照key的hash值除以reduceTask取余
Hive中:按照分桶字段的hash值取模除以分桶的个数
3.分桶表的操作
- 创建
create table t_stu(
Sno int,
Sname string,
Sex string,
Sage int,
Sdept string
)
row format delimited fields terminated by ','
stored as textfile;
- 加载数据
load方式加载数据不能体现分桶
load data local inpath '/root/hivedata/students.txt' into table t_stu;
临时表方式
加载数据到临时表
load data local inpath '/hivedata/buc1.txt' into table temp_buc1
使用分桶查询将数据导入到分桶表
insert overwrite table buc13
select id,name,age from temp_buc1
cluster by (id);
- 分桶查询
语法:
tablesample(bucket x out of y on sno)
注意:tablesample一定是紧跟在表名之后 x:代表从第几桶开始查询 y:查询的总桶数,y可以是总桶数的倍数或者因子,x不能大于y
默认有4桶
查询第一桶
select * from buc3 tablesample(bucket 1 out of 4 on sno);
查询第一桶和第三桶
select * from buc3 tablesample(bucket 1 out of 2 on sno);
查询第一桶的前半部分
select * from buc3 tablesample(bucket 1 out of 8 on sno);
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了4份,当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y。例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。
注意:x的值必须小于等于y的值,否则
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
查询sno为奇数的数据
select * from buc3 tablesample(bucket 2 out of 2 on sno);
查询sno为偶数且age大于30的人
select * from buc3 tablesample(bucket 1 out of 2 on sno) where age>30;
查出三行
select * from buc3 limit 3;
查出三行
select * from buc3 tablesample(3 rows);
查出13%的内容,(如果百分比不够现实 一行,至少会显示一行,如果百分比为0,显示第一桶)
select * from buc3 tablesample(13 percent);
查出68B包含的数据,如果是 0B,默认显示第一桶 要求随机抽取3行数据:
select * from buc3 tablesample(68B);
随机显示3条数据
select * from t_stu order by rand() limit 3;