前言
随着flutter_novel项目进入到书架部分,设计一个结合本地和网络共同存储与处理的框架就是现在的第一目标;由此带来的一个问题就是:
本地持久化应该怎么做
当然,这个问题的答案有很多很多,99.99%的人抠着脚都能说出好几种方案,但是不知道你有没有仔细考虑过其中的区别和优缺点呢?
在 Flutter 中,dev Package 中Like较高的几个数据存储方案又这么几个:
那么,现在就来分析一下;
首先需要了解下基本知识:
什么是SQL,什么是NoSQL
SQL的全称是 structured query language ,也就是结构化查询语言的意思;当然,记这个全称除了装逼外吊用没有,一般大家都将其理解为:关系型数据库;
至于 NoSQL嘛,自然就是No structured query language 喽,非结构化查询语言,或者说非关系型,那么大一个No这么明显嘛;
其实,这个No,其具体含义好像还不是很确定,至少我在找资料的时候就看到两种说法:
- 一种是上面提到的,直译出来的 非关系型 的意思;
- 另一种的解释,是将No两字拆开,将 No 定义为 not only 的缩写,也就是 不仅仅是关系型 的意思;
但是至少能达成一致的是:
NoSQL 不是基于关系表来做的;
那么SQL 知道了是 关系型数据库这种东西,NoSQL 又是以一种什么姿态体现出来的?
现在主要的NoSql类型有这么四个:
- 文档数据库 : 将数据存储在类似于 JSON 对象的文档中。每个文档包含成对的字段和值。
- 键值数据库 : 其中每个项目都包含键和值。通常只能通过引用键来检索值,因此学习如何查询特定键值对通常很简单。键值数据库非常适合需要存储大量数据但无需执行复杂查询来检索数据的使用案例。
- 宽列存储 : 将数据存储在表、行和动态列中。宽列存储提供了比关系型数据库更大的灵活性,因为不需要每一行都具有相同的列。宽列存储非常适合需要存储大量数据并且可以预测查询模式的情况。
- 图形数据库 : 将数据存储在节点和边中。节点通常存储有关人物、地点和事物的信息,而边缘则存储有关节点之间的关系的信息。在需要遍历关系以查找模式(例如社交网络,欺诈检测和推荐引擎)的使用案例中,图形数据库非常出色。
一般来说,键值数据库 和 文档数据库 我们接触的比较多;
回到正题,在 Flutter 中,这几个数据存储方案有什么优缺点?该选哪个?
首先大部分人最先接触的SQL
先是 sqflite:
sqflite就是标准的SQL数据库,使用SQL语句查询,按其说明,使用方法大概是这些:
// Get a location using getDatabasesPath
var databasesPath = await getDatabasesPath();
String path = join(databasesPath, 'demo.db');
// Delete the database
await deleteDatabase(path);
// open the database
Database database = await openDatabase(path, version: 1,
onCreate: (Database db, int version) async {
// When creating the db, create the table
await db.execute(
'CREATE TABLE Test (id INTEGER PRIMARY KEY, name TEXT, value INTEGER, num REAL)');
});
// Insert some records in a transaction
await database.transaction((txn) async {
int id1 = await txn.rawInsert(
'INSERT INTO Test(name, value, num) VALUES("some name", 1234, 456.789)');
print('inserted1: $id1');
int id2 = await txn.rawInsert(
'INSERT INTO Test(name, value, num) VALUES(?, ?, ?)',
['another name', 12345678, 3.1416]);
print('inserted2: $id2');
});
// Update some record
int count = await database.rawUpdate(
'UPDATE Test SET name = ?, value = ? WHERE name = ?',
['updated name', '9876', 'some name']);
print('updated: $count');
// Get the records
List<Map> list = await database.rawQuery('SELECT * FROM Test');
List<Map> expectedList = [
{'name': 'updated name', 'id': 1, 'value': 9876, 'num': 456.789},
{'name': 'another name', 'id': 2, 'value': 12345678, 'num': 3.1416}
];
print(list);
print(expectedList);
assert(const DeepCollectionEquality().equals(list, expectedList));
// Count the records
count = Sqflite
.firstIntValue(await database.rawQuery('SELECT COUNT(*) FROM Test'));
assert(count == 2);
// Delete a record
count = await database
.rawDelete('DELETE FROM Test WHERE name = ?', ['another name']);
assert(count == 1);
// Close the database
await database.close();
其实也不复杂,第一次用,感觉还可以?
但是用过这个一段时间的人,遇到几次要改结构或者其他导致升级数据库升级操作的需求后,都不会再觉得这玩意好用,维护成本那是肉眼可见增加;
其实这也是关系型数据库的通病:
关系型数据库适用于数据结构固定,不会发生太大改动的情况;数据模式比较统一,不会这个多一点,那个少一点;
另外,按照我查阅资料的网站上的说法:

项目延期其实不怪你,都是前人打造的使用SQL的世界的错~~~~
在看下 floor
floor 同样是 SQL ,但是它跟 sqflite 相比,做了很多抽象和封装的工作,尤其是其中的 dao 这个概念,不由得让我想起了曾经写Android用greenDao的那段日子~
使用方式上,确实比sqflite好了很多,毕竟基于注解用脚本自动生成代码,肯定比手写省事:
其使用方式分这么几个步骤:
1、 创建Entity,生成表
// entity/person.dart
import 'package:floor/floor.dart';
@entity
class Person {
@primaryKey
final int id;
final String name;
Person(this.id, this.name);
}
2、 创建DAO层
// dao/person_dao.dart
import 'package:floor/floor.dart';
@dao
abstract class PersonDao {
@Query('SELECT * FROM Person')
Future<List<Person>> findAllPersons();
@Query('SELECT * FROM Person WHERE id = :id')
Stream<Person?> findPersonById(int id);
@insert
Future<void> insertPerson(Person person);
}
3、 创建数据库代理
// database.dart
// required package imports
import 'dart:async';
import 'package:floor/floor.dart';
import 'package:sqflite/sqflite.dart' as sqflite;
import 'dao/person_dao.dart';
import 'entity/person.dart';
part 'database.g.dart'; // the generated code will be there
@Database(version: 1, entities: [Person])
abstract class AppDatabase extends FloorDatabase {
PersonDao get personDao;
}
4、 运行build_runner脚本,然后就生成完毕可以使用了
不过既然是SQL ,上面说的缺点,该有的还是有,作为SQL是无法避免的;
Drift
Drift 的使用流程上,其实跟floor差不多,但是它在封装层面又多做了一点点:
现在主要差别有这么几点:
- 生成表通过继承与方法,而非实体类:
import 'package:drift/drift.dart';
// assuming that your file is called filename.dart. This will give an error at first,
// but it's needed for drift to know about the generated code
part 'filename.g.dart';
// this will generate a table called "todos" for us. The rows of that table will
// be represented by a class called "Todo".
class Todos extends Table {
IntColumn get id => integer().autoIncrement()();
TextColumn get title => text().withLength(min: 6, max: 32)();
TextColumn get content => text().named('body')();
IntColumn get category => integer().nullable()();
}
// This will make drift generate a class called "Category" to represent a row in this table.
// By default, "Categorie" would have been used because it only strips away the trailing "s"
// in the table name.
@DataClassName("Category")
class Categories extends Table {
IntColumn get id => integer().autoIncrement()();
TextColumn get description => text()();
}
// this annotation tells drift to prepare a database class that uses both of the
// tables we just defined. We'll see how to use that database class in a moment.
@DriftDatabase(tables: [Todos, Categories])
class MyDatabase {
}
当然,Drift 同样还是SQL
现在压力来到了NoSQL这块
hive
hive 的使用方法非常简单,毕竟不需要关系表查询语句那些嘛:
var box = Hive.box('products');
box.put('name', 'foo');
var name = box.get('name');
print('Product Name: $name');
如果要放自定义类型的话,也是以实体类的形式放进去;
@HiveType(typeId: 0)
class Person extends HiveObject {
@HiveField(0)
String name;
@HiveField(1)
int age;
}
var box = await Hive.openBox('myBox');
var person = Person()
..name = 'Dave'
..age = 22;
box.add(person);
print(box.getAt(0)); // Dave - 22
person.age = 30;
person.save();
print(box.getAt(0)) // Dave - 30
可以看到,使用非常非常简单,没那么抽象类要写,也不需要脚本之类的东西;
而且性能吊打sqlite:
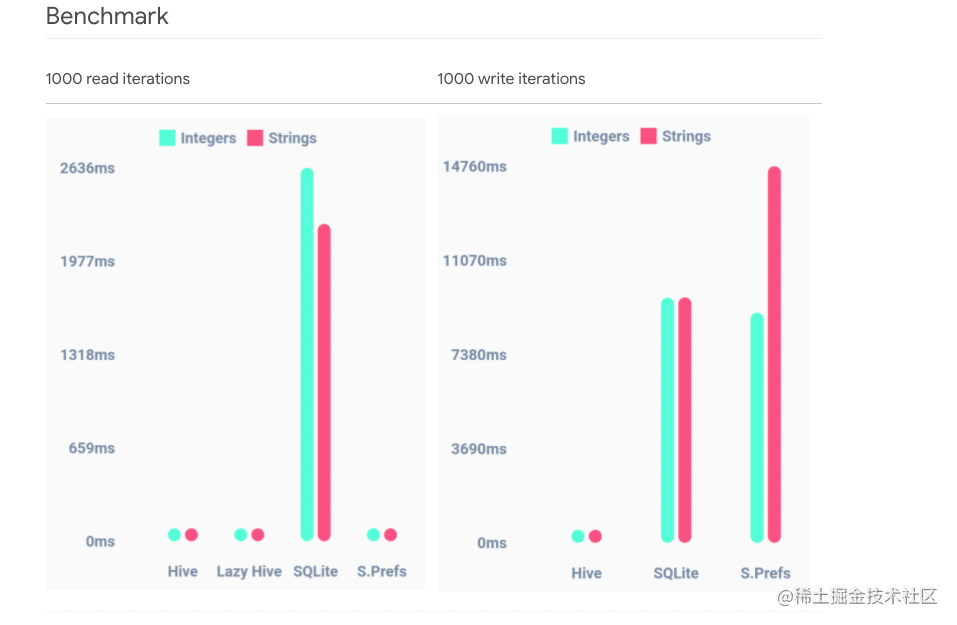
那么,古尔丹,代价是什么呢?
关系表的存在提高了操作难度,降低了查询速度,但是其存在并不是毫无意义的;
如果打个比方来说,关系表就好比管家、海关、等一系列帮你把关的,没有关系表,可能就会存在大量重复或者无用的数据;而且由于并没有关系表来约束数据结构,可能在NOSQL的数据库中,存在大量杂乱无序的数据;
总结一下SQL和NOSQL:
- SQL:
- 数据要求合规且格式统一,虽然性能比NOSQL差,但是其数据能保证正确符合事实要求,但也带来修改方面的问题,可拓展性差;
- 由于SQL查询语句的存在,使其在复杂情况多表联合查询上不会太复杂;
- NOSQL :
- 对于存储没有什么特别规范,因此可拓展性非常高;
- 查询速度也因为不需要经过关系表,因此查询特别快;
- 但是过度的自由就有可能带来问题,比如说大量重复数据的存在;这样获取某个指标的数据可能就不准确(放俩假数据让你当场懵逼还不好找出来);
- 对于复杂情况的多级查询,就要自己写逻辑判断,会不会出现几百个if else、switch case 那种就不得而知了;
结语
看到这里,是不是觉得该下一个结论,用哪个比较好?
其实正如上面总结的,SQL和NoSQL都有自己的优势和不足,即使同为NoSQL,也会因为技术选型等因素存在不同的优缺点;
所以并没有这个好那个好这一说,或者说,符合项目和自身需求的才是最好的数据存储方案;
PS :但是如果非要让我说一个,无脑选好感最高的话,文中提到的那四个全不选 ;MMKV(虽然 Like 很少,是不是腾讯名声太差了) 才是我心目中的最佳方案;
作为老牌的键值对存储框架,其稳定性那是杠杠的;性能方面那也是在原生上面的Top级别的;个人感觉,一般性质的存储查询,用MMKV就完全足够了
(现在想想,好像客户端这块,好像一般情况下,也没啥复杂到要上关系型数据库来保存数据关系的情景?IM算一个,还有其他的么?)
我总结了一些Android核心知识点,以及一些最新的大厂面试题、知识脑图和视频资料解析。
需要的直接点击文末小卡片可以领取哦我免费分享给你,以后的路也希望我们能一起走下去。(谢谢大家一直以来的支持,需要的自己领取)
Android学习PDF+架构视频+面试文档+源码笔记
部分资料一览:
- 330页PDF Android学习核心笔记(内含8大板块)


- Android学习的系统对应视频
- Android进阶的系统对应学习资料
- Android BAT大厂面试题(有解析)

领取地址:
