实际开发中,使用的就是完全分布式环境。所谓完全分布式就是在整个集群中有真实的主机(3台以上),用于完成各种任务。但是个人在学习时,购买多个机器显然是不划算的。这里,我们采用VMWare克隆出多个虚拟机来模仿完全分布式环境。
环境:
- VMware Fusion 11 pro
- Linux系统为Ubuntu 16.04
- 每个虚拟机的配置为1G内存和20G磁盘空间
- PC:mbp2018 8G内存 256G固态
步骤
1. 准备3台客户机
1.1 按照之前的方法完成单台虚拟机的搭建(步骤一、步骤二和步骤三)。
1.2 在虚拟机关闭的情况下,克隆两台虚拟机。
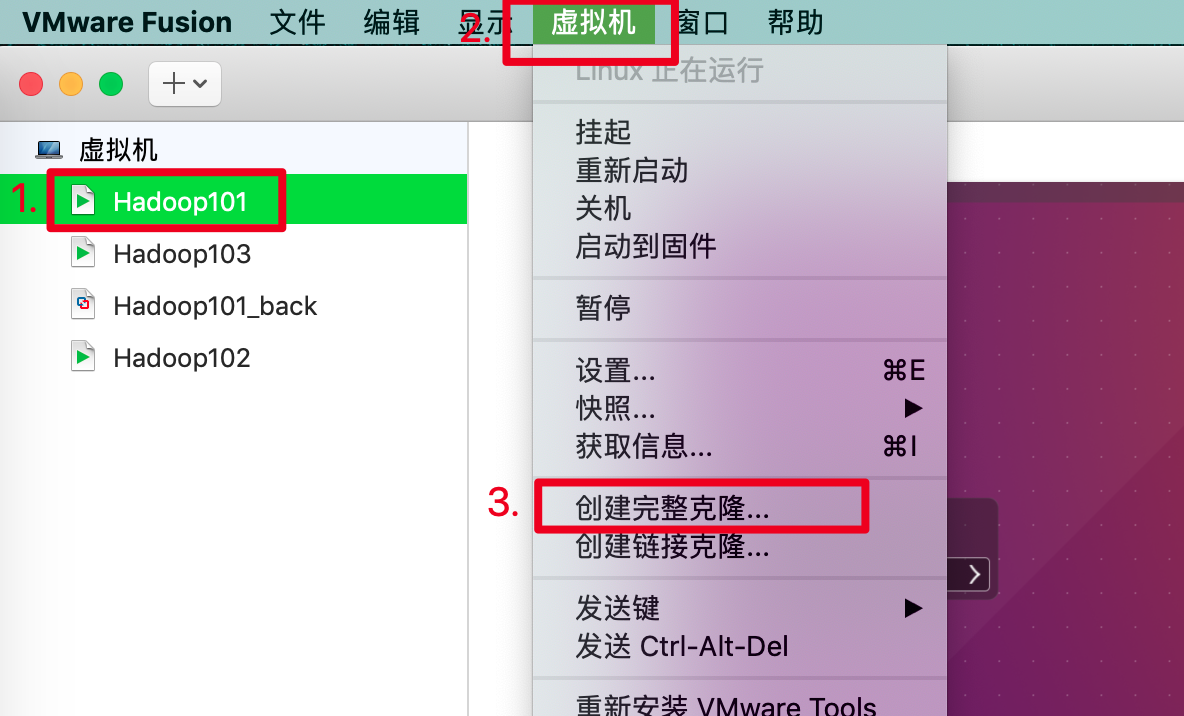
修改名称和存储位置即可。
1.3 修改静态IP。
1.3.1 查看你PC上为VMware分配的IP地址段、子网掩码和网关。打开终端,输入如下命令:more /Library/Preferences/VMware\ Fusion/vmnet8/dhcpd.conf
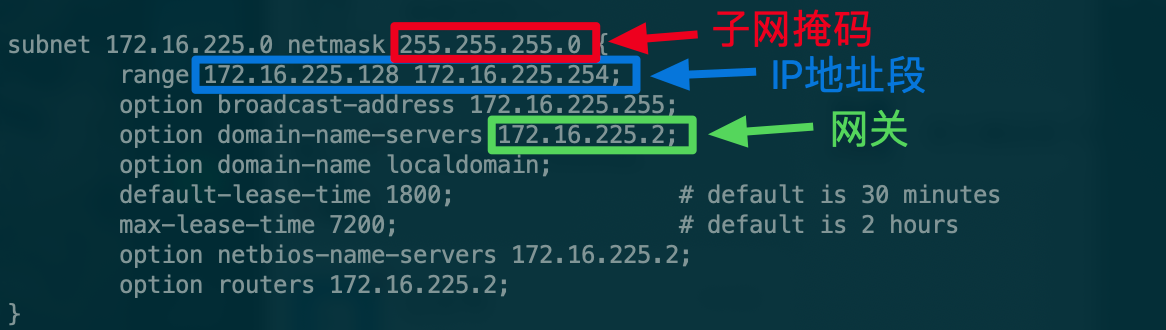
1.3.2 打开克隆好的虚拟机,修改配置文件,在终端输入如下命令:
sudo vim /etc/network/interferfaces添加以下信息:
auto ens33 # 本机的网卡,可通过`ifconfig`命令查看
iface ens33 inet static
address 172.16.225.133 # 从IP地址段中任意选一个
netmask 255.255.255.0
gateway 172.16.225.2
dns-nameservers 172.16.225.2
重启机器即可完成静态IP的修改。记得ping www.baidu.com测试网络的连通性。
1.4 修改主机名称,针对Ubuntu而言:
1.4.1 修改主机名称sudo vim /etc/hostname
将文件修改为你的主机名,例如hadoop101
1.4.2 修改主机名和host的映射sudo vim /etc/hosts
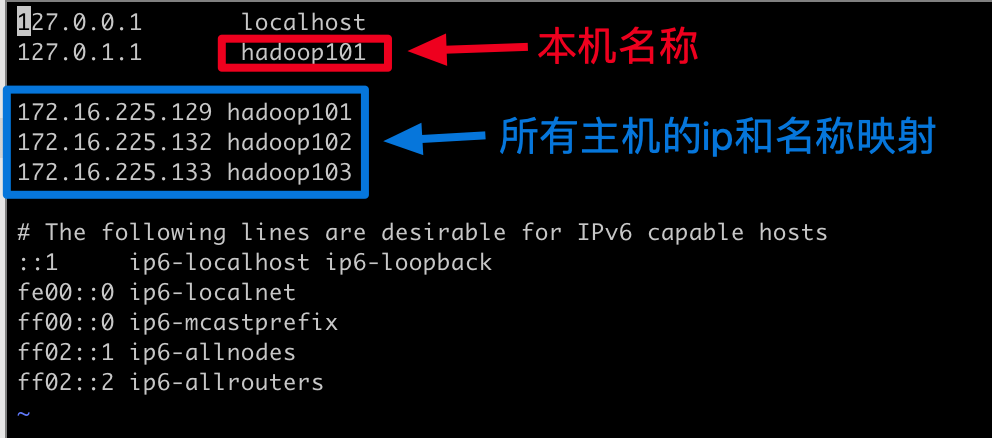
1.4.3 重启机器,并使用
ping hadoop10x测试连通性。2. 安装JDK和Hadoop
如果你在第一台虚拟机上完成了伪分布模式的搭建,那么此时克隆的两台机器也同样拥有JDK和Hadoop。
scp命令
此时,如果只有一台机器完成了jdk和Hadoop的安装配置,我们可以使用scp命令完成数据的安全拷贝。
命令格式:scp -r 要拷贝的文件路径/名称 user@ip:目的路径/名称
- 在hadoop101上,将hadoop101的
/opt/modeul目录下的东西拷贝到hadoop102上scp -r /opt/module root@hadoop102:/opt/module - 在hadoop103上,将hadoop101的
/opt/module目录下的东西拷贝到hadoop102上scp -r root@hadoop101:opt/module roor@hadoop102:/opt/module
rsync命令
与scp相同的还有一个命令时rsync,其主要用于备份和镜像。rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp将所有文件都复制过去。使用方法和scp一样。
基本格式:rsync -rvl 源文件 目的路径
集群分发脚本
脚本sxync.sh可以更好的同步数据到其他机器上
#! /bin/bash
#1获取输入参数的个数,如果没有参数直接退出
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1);pwd`
echo pdir=$pdir
#4 获取当前用户的名称
user=`whoami`
#5循环
for((host=102;host<104;host++));do
echo -----------hadoop$host-----------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
3. 配置集群
集群配置图
3.1 配置core-site.xml
<!-- 指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-x.x.x/data/tmp</value>
</property>
3.2 HDFS配置文件
3.2.1 配置hadoop-env.sh
export JAVA_HOME=jdk安装路径
3.2.2 配置hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定hadoop辅助名称节点主机配置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
3.3 YARN配置文件
3.3.1 配置yarn-env.sh
export JAVA_HOME=jdk安装路径
3.3.2 配置yarn-site.xml文件
<!-- Reducer获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定yarn的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
3.4 MapReduce配置文件
3.4.1 配置mapred-env.sh
export JAVA_HOME=jdk安装路径
3.4.2 配置mapred-site.xml文件
<!-- -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.5 在集群上分发配置好的Hadoop配置文件
xsync /opt/module/hadoop-x.x.x/
3.6 查看文件分发情况
4. 集群的单点启动
4.1 查看后台是否有Hadoop的相关进程,如果有,则全部关闭
4.2 删除$HADOOP_HOME/的data/和logs/目录
rm -rf data/ logs/
注意,此时要删除所有节点的
data/和logs/
4.3 格式化NameNode
bin/hdfs namenode -format
4.4 启动hadoop集群
4.4.1 在hadoop101上启动namenodesbin/hadoop-daemon.sh start namenode
4.4.2 在hadoop101上启动namenodesbin/hadoop-daemon.sh start namenode
4.4.3 在hadoop101上启动namenodesbin/hadoop-daemon.sh start namenode
4.5 查看集群是否启动成功
5. 配置SSH免密登录
5.1 配置hadoop101免密登录hadoop102和Hadoop03
5.1.1 在hadoop101上使用指令ssh-keygen -t rsa生成公钥和密钥
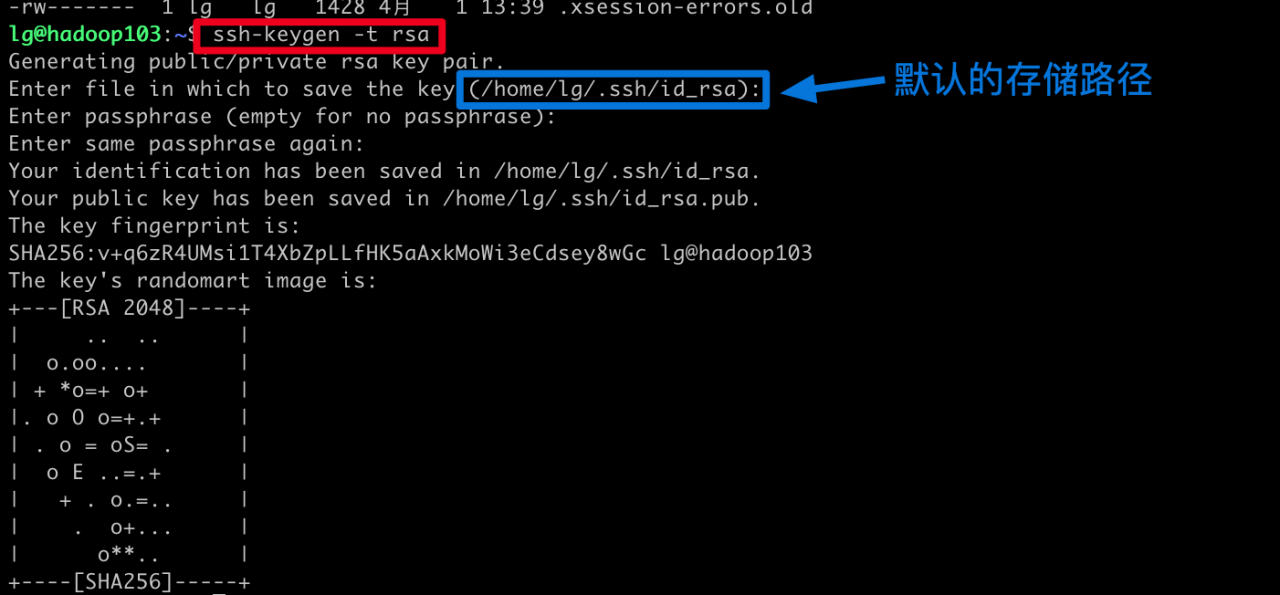
5.1.2 查看生成的公钥和私钥
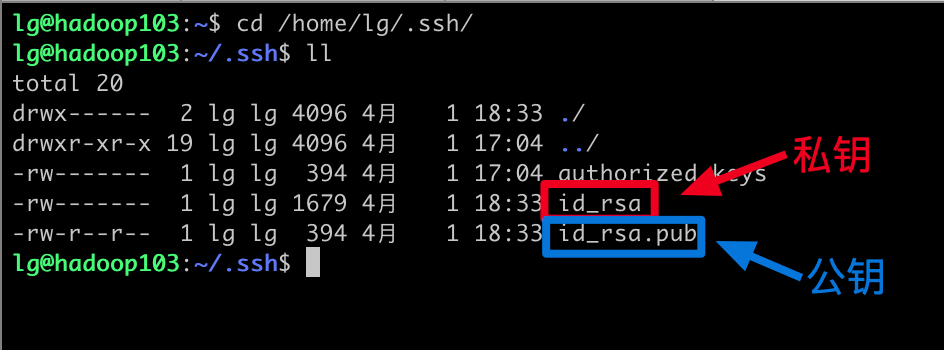
5.1.3 将公钥分发给hadoop102和hadoop03
ssh-copy-id hadoop102 ssh-copy-id hadoop103