概念
用来做像素融合,提取特征。(1×1 的卷积核用来做通道融合)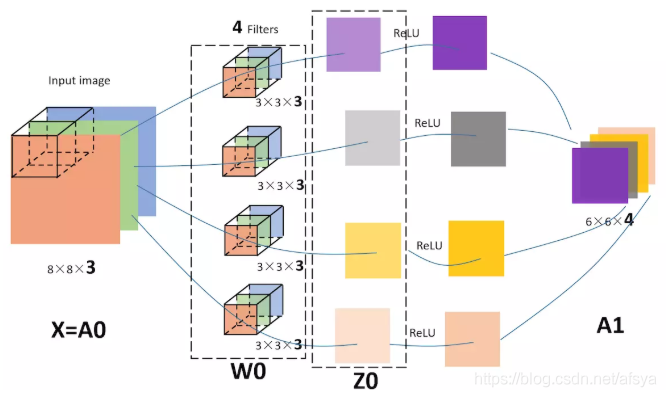
卷积核层数与输入层数相同,卷积核个数与输出层数相同,每个卷积核卷提取一种特征,最后用全连接得到一个特征图。(全连接的参数不更新,只做特征融合)
特征图尺寸:w’ = (w - k + 2p) / s + 1
w:原图大小。
k:卷积核大小。
p:填充。
s:步长。
结果带小数时,向下取整。(例如:原图大小为 6×6,卷积核大小为 3×3,步长为 1,不填充,得到的特征图尺寸为 2×2)
权重共享
共享:一个卷积核卷整张图的参数共享。
目的:减少参数量,提高计算的速度和性能。
参数量减少后,为了得到全面的特征信息,需要用多个卷积核去卷一张图,每个卷积核负责一种特征。
计算量:H’W’K²NM
H’W’:输出特征大小。(特征图的点数,也就是卷积核走的步数,步长大,次数就少,但是会丢特征)
K²:卷积核大小。(卷积核每步都是在这个区域的对应位置相乘相加)
- 卷积核大:计算量大,速度慢,效果好,代表的原图范围大。
- 卷积核小:计算量小,速度快,效果不好。
- 信息要充分融合,可以使用小卷积核卷多次代替大卷积核卷一次。(3×3 卷两次比 5×5 卷一次快,而且加深了网络)
N:输入通道数。
M:输出通道数。
实验(手写数字识别)
数据集:MNIST。
网络结构:CNN + 标准化(BN)+ 激活(ReLU)+ 全连接。
优化器:Adam。
损失函数:交叉熵(CrossEntropyLoss),自带 one-hot 类型和 softmax。
输出:one-hot 类型,结果为最大的索引值。
网络
import torch
from torch import nn
class MyNet(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential(
# 28*28*3
nn.Conv2d(1, 16, 3, 2, 1), nn.BatchNorm2d(16), nn.ReLU(),
# 14*14*16
nn.Conv2d(16, 32, 3, 2, 1), nn.BatchNorm2d(32), nn.ReLU(),
# 7*7*32
nn.Conv2d(32, 64, 3, 2, 1), nn.BatchNorm2d(64), nn.ReLU()
)
self.mlp = nn.Linear(4 * 4 * 64, 10)
def forward(self, x):
out = self.conv(x)
out = out.reshape(-1, 4 * 4 * 64)
return self.mlp(out)
训练
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import os
from PIL import Image, ImageDraw, ImageFont
from matplotlib import pyplot as plt
from net import MyNet
batch_size = 100
net_path = r"modules/mynet.pth"
train_flag = False
# 数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
if train_flag:
dataset = datasets.MNIST(r"data", train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size, shuffle=True)
else:
dataset = datasets.MNIST(r"data", train=False, transform=transform, download=False)
dataloader = DataLoader(dataset, batch_size, shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == '__main__':
# 加载网络
net = MyNet().to(device)
if os.path.isfile(net_path):
net.load_state_dict(torch.load(net_path))
opt = torch.optim.Adam(net.parameters())
loss_fn = nn.CrossEntropyLoss()
if train_flag:
# 训练
net.train()
while True:
for i, (x, y) in enumerate(dataloader):
x = x.to(device)
y = y.to(device)
out = net(x)
loss = loss_fn(out, y)
opt.zero_grad()
loss.backward()
opt.step()
# 结果是 one-hot 类型,取最大索引
result = torch.argmax(out, 1)
acc = torch.mean(torch.eq(result, y).float())
print("i:{},loss:{:.5},acc:{:.3}".format(i, loss, acc))
# 保存网络
torch.save(net.state_dict(), net_path)
else:
# 测试
net.eval()
font = ImageFont.truetype(r"arial.ttf", size=10)
plt.ion()
for x, y in dataloader:
# [n,c,h,w] → [h,w]
img_array = x[0][0] * 255
img = Image.fromarray(img_array.numpy())
draw = ImageDraw.ImageDraw(img)
out = net(x)
result = torch.argmax(out, 1)
draw.text((0, 0), str(result[0].item()), 255, font)
plt.imshow(img)
plt.pause(0.5)
plt.ioff()
版权声明:本文为afsya原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。