前言
基于阿里开源项目 dataX 和 datax-web 实现可视化数据同步。
基础软件安装
- MySQL (5.5+) 必选,对应客户端可以选装, Linux服务上若安装mysql的客户端可以通过部署脚本快速初始化数据库
- JDK (1.8.0_xxx) 必选
- Maven (3.6.1+) 必选
- DataX 必选
- Hadoop 必选
- Python (2.x) (支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/datax-web/datax-python3下) 必选,主要用于调度执行底层DataX的启动脚本,默认的方式是以Java子进程方式执行DataX,用户可以选择以Python方式来做自定义的改造
以下是本篇文章正文内容,下面案例可供参考
一、安装Python2.x
网上有很多安装文档,此处推荐:https://blog.csdn.net/weixin_43790276/article/details/89439226
安装包:百度网盘 python-2.7.13.amd64.msi 提取码:kue4
二、安装Hadoop3.0.0
- 因Datax是基于Hadoop开发的,所以还需安装Hadoop
- 因官网下载速度很慢,工具包已上传至百度网盘 点我下载 提取码:wkgb
- 安装文档请参考:https://blog.csdn.net/zhouzhiwengang/article/details/88116399
三、安装DataX
1.直接下载DataX工具包:DataX下载地址
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
自检脚本: python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
2.配置示例:从stream读取数据并打印到控制台
- 进入datax / bin目录
- 创建stream2stream.json文件
- 将以下内容复制进去:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
- 启动DataX
$ cd {YOUR_DATAX_DIR_BIN}
$ python datax.py ./stream2stream.json
- 同步结束,显示日志如下:
...
2015-12-17 11:20:25.263 [job-0] INFO JobContainer -
任务启动时刻 : 2015-12-17 11:20:15
任务结束时刻 : 2015-12-17 11:20:25
任务总计耗时 : 10s
任务平均流量 : 205B/s
记录写入速度 : 5rec/s
读出记录总数 : 50
读写失败总数 : 0
到此,datax安装完毕
四、DataX-Web部署启动
- 下载master分支或者release版本到本地
GitHub DataX Web下载地址
码云 DataX Web下载地址 - Linux:一键部署
- 开发环境部署
- 执行bin/db下面的datax_web.sql文件(注意老版本更新语句有指定库名)
- 修改项目配置
admin模块下的bootstrap.properties文件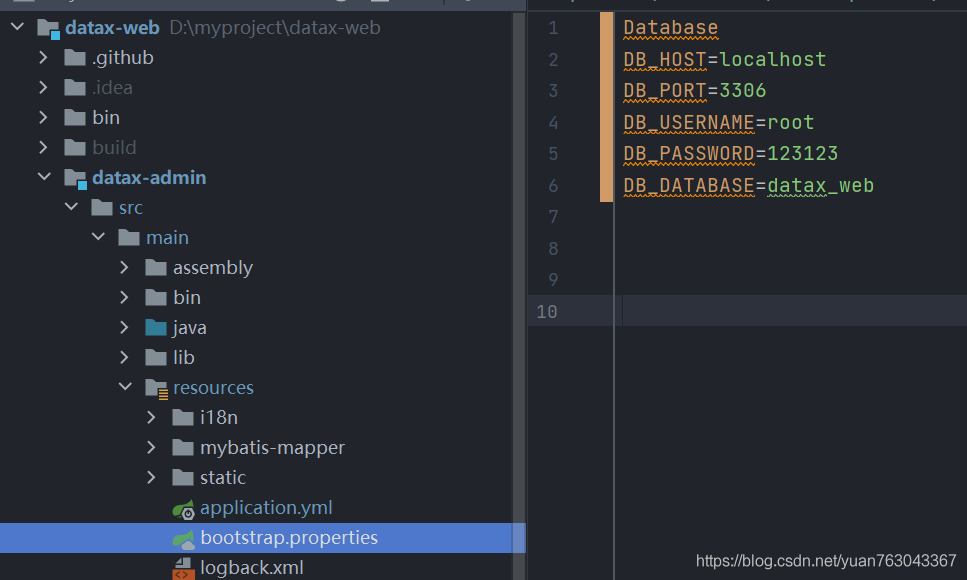
admin模块下的application.yml文件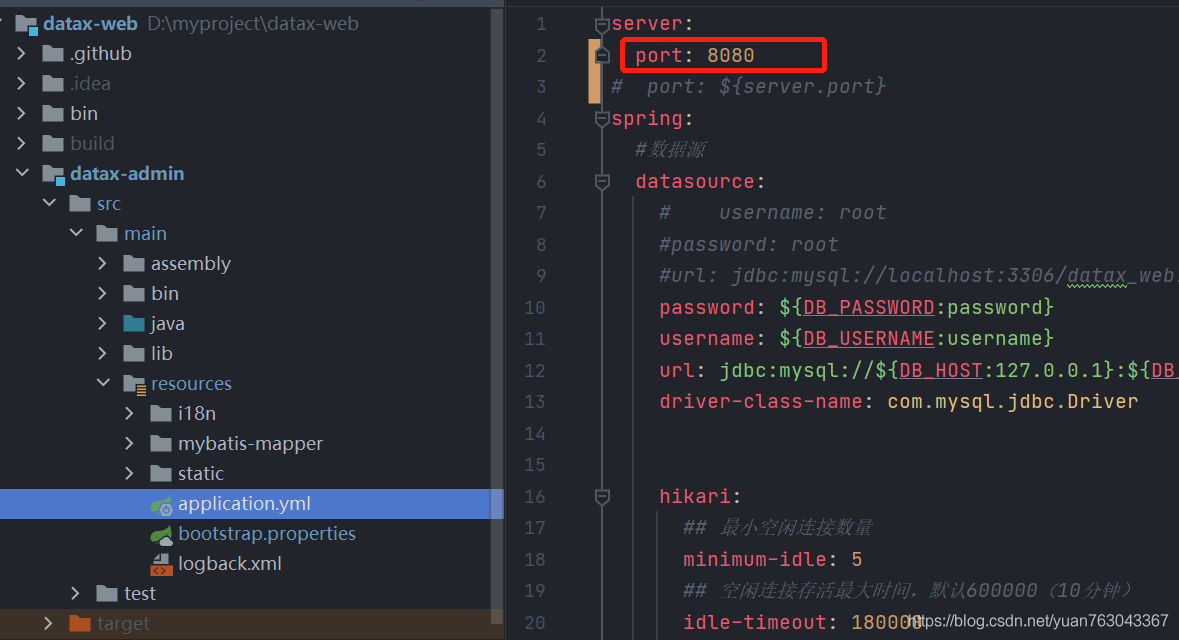
executor模块下的application.yml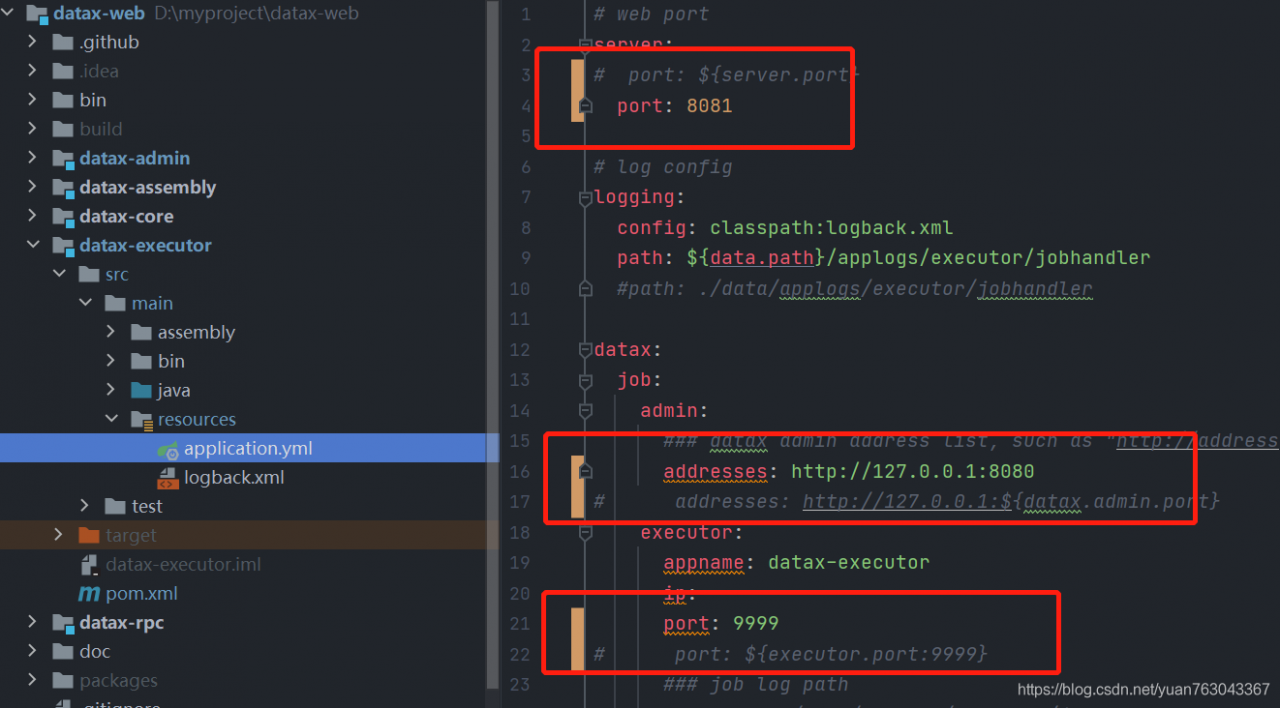
- 启动项目
首先启动admin模块下的启动类
再启动executor模块下的启动类 - 启动成功后打开页面(默认管理员用户名:admin 密码:123456) http://localhost:8080/index.html#/dashboard
五、生产打包部署
修改线上对应数据库信息 maven打包成XX.jar
如果运行提示无主清单程序
修改admin模块和executor模块下的pom文件:
首先注释掉下图部分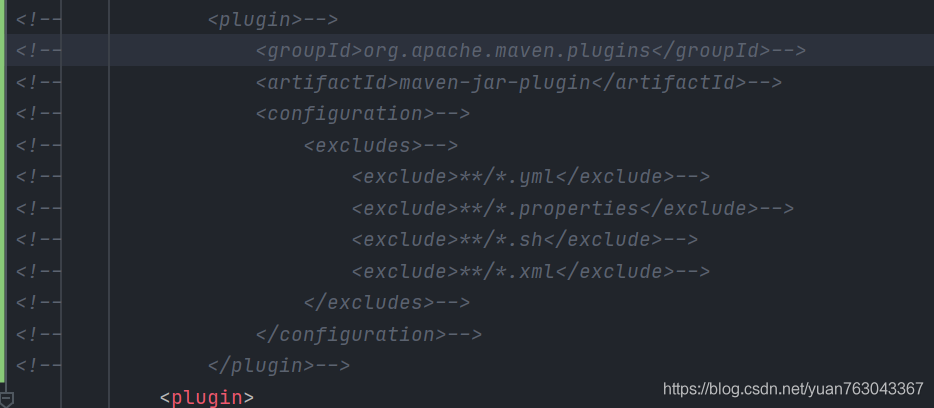
admin模块新增打包plugin<plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <phase>package</phase> <goals> <goal>repackage</goal> </goals> </execution> </executions> <configuration> <includeSystemScope>true</includeSystemScope> <mainClass>com.wugui.datax.admin.DataXAdminApplication</mainClass> </configuration> </plugin>executor模块新增打包plugin
<plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <phase>package</phase> <goals> <goal>repackage</goal> </goals> </execution> </executions> <configuration> <includeSystemScope>true</includeSystemScope> <mainClass>com.wugui.datax.executor.DataXExecutorApplication</mainClass> </configuration> </plugin>然后使用命令启动jar程序
admin模块 java -Xmx1024M -Xms1024M -Xmn448M -XX:MaxMetaspaceSize=192M -XX:MetaspaceSize=192M -jar datax-admin-2.1.2.jar executor模块 java -Xmx1024M -Xms1024M -Xmn448M -XX:MaxMetaspaceSize=192M -XX:MetaspaceSize=192M -jar datax-executor-2.1.2.jar
六、集群部署
调度中心、执行器支持集群部署,提升调度系统容灾和可用性。
1.调度中心集群:
DB配置保持一致;
集群机器时钟保持一致(单机集群忽视);
2.执行器集群:
执行器回调地址(admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作。
同一个执行器集群内AppName(executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了DataX+DataX-Web的安装以及部署,而DataX-Web的使用需自行探索
推荐
datax-web作者文章:增量的配置方式 https://my.oschina.net/u/4259890/blog/4362748
其他集群部署方式:https://blog.csdn.net/fairynini/article/details/106836238?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.control
版权声明:本文为yuan763043367原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。