文章目录
Kafka分区
topic是逻辑的概念,partition是物理的概念,对用户来说是透明的。producer只需要关心消息发往哪个topic,而consumer只关心自己订阅哪个topic,并不关心每条消息存于整个集群的哪个broker。
为了性能考虑,如果topic内的消息只存于一个broker,那这个broker会成为瓶颈,无法做到水平扩展。所以把topic内的数据分布到整个集群就是一个自然而然的设计方式。Partition的引入就是解决水平扩展问题的一个方案。
每个partition可以被认为是一个无限长度的数组,新数据顺序追加进这个数组。物理上,每个partition对应于一个文件夹。一个broker上可以存放多个partition。这样,producer可以将数据发送给多个broker上的多个partition,consumer也可以并行从多个broker上的不同paritition上读数据,实现了水平扩展
分区对于Kafka集群来说,可以提高Kafka集群的负载能力,实现负载均衡
分区对于消费者来说,可以提高并发度,提高效率
Kafka文件存储机制

kafka安装目录下有个data文件夹,有个topic 起名叫first,并且有两个分区。图中first-0,和first-1就是存储该topic数据的地方,由于kafka是将数据存储在磁盘,为了提升读取效率,所以kafka也是采取了分片和索引的手段来提升数据查找读取效率。

随便cd到某一个分区文件下,就会看到有.index和.log两个文件,顾名思义.index就是该分区下的索引文件,.log文件就是正儿八经存数据的文件了。index和 log 文件以当前 segment(分片) 的第一条消息的 offset 命名。
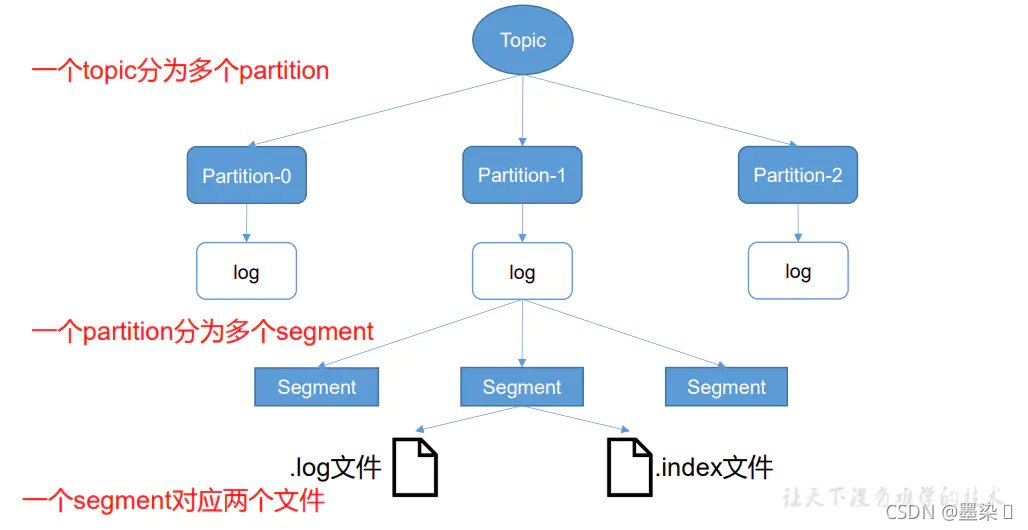
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制,将每个partition 分为多个 segment。每个segment对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,first 这个 topic 有三个分区,则其对应的文件夹为 first0,first-1,first-2。
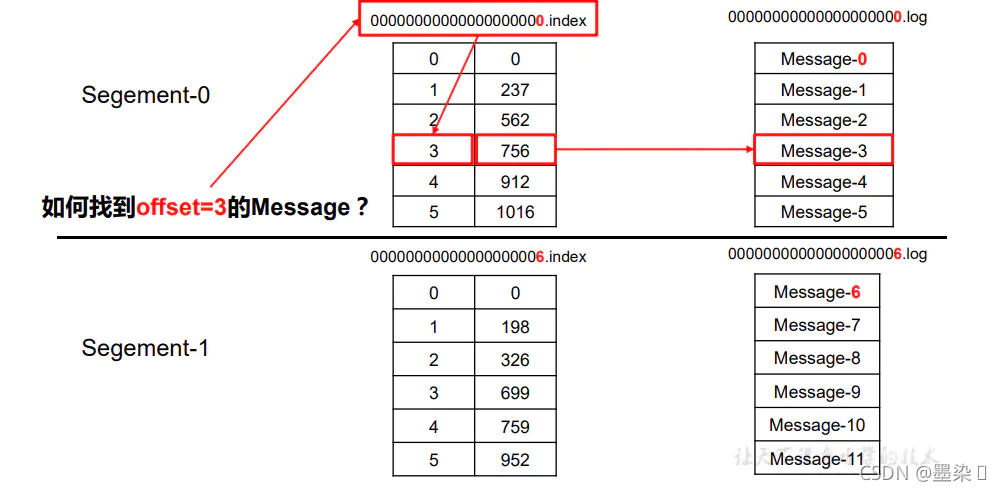
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message的物理偏移地址。“3”代表该分区下的第3条消息,“756”代表该条消息在所有分区中的偏移量,根据“756”这个偏移量去“.log”文件中查找offset=3的消息。
其实,在.index文件中还会存储该Message的长度,这样,假设第三个Message的长度是1000,如果要找第三个Message,那就在.log文件中找756-1756的数据就可以了
ISR
什么是ISR
生产者写数据到topics中,实际上是写在leader中,follower需要同步leader中的数据,但是生产并不知道leader是否已经写完且同步完数据,因此需要向生产者发生ack,但是要何时发送ack 有两种方案解决 ,第一种是半数机制,当有n个follower时,需要2n+1个机器备份,第二种是n+1个机器备份,这就存在着机器数量的差别,因此要选择第二种,但是当有10个follower时,如果有一台follower宕机了,leader就无法发送ack,因此需要isr来选出follower,只要isr中的follower同步完成,leader就可以直接发ack
ISR怎么选出来
选取follower进入isr有两个条件 一个是同步时间的长短 另一个是和leader差距的数据量 但是后来剔除了第二个条件 因为他有一个默认值 当同步的条数差距leader达到10000时 isr就会把follower踢出isr 但是当同步开始后 又会有新的follower写入isr isr会和zk交互 写入zk 这样造成zk频繁使用
ack
ack机制保证数据不丢失 当设置为-1时 生产者等待所有的leader和follower同步完成才发送ack 这就保证了数据不会丢失 HW能够保证副本一致性 当leader宕机 选取新的leader之后 会要求所有的follower把HW之后的部分截取掉 再和leader同步 这样 所有的leader和follower就能实现同步数据 再进行下一步
ack能够解决数据不丢失 但是无法保证数据不重复 HW能保证副本之间的数据一致性 但是无法保证数据不丢失和不重复 当ack=-1就可以体现出来
acks 参数配置:
0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还 没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower 同步成功之前 leader 故障,那么将会丢失数据
-1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower (ISRL里的follower,不是全部的follower)全部落盘成功后才 返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复
Exactly Once
Exactly Once 精准一次性写入 因为当ack为-1时 可能会产生数据重复 可以进行去重 但是不能在消费者端去重 因为这样会更麻烦 数据传输更慢 因此在broker中去重 需要利用幂等性 At Least Once+幂等性=Exactly Once 生产者在开启后会生成一个PID 发向同一个partition的消息会附带序列化号Seq Number 生成主键<PID,Partition,SeqNumber> broker把主键存入内存 存数据到broker会判断主键是否相同 如果相同就只保留一条 但是当生产者发完某条数据后宕机 再重启时会生成新的PID且会有不同的partition 这样就无法去重 所以Exactly Once只能保证在同分区同会话有效保证数据不重复
消费者分区分配策略
由于Kafka集群存在多个topic和消费者 topic中又存在多个partition 因此需要利用分区分配策略决定消费者消费哪些partition中的数据 有两种策略
一是轮询分区
二是范围分区
RoundRobin 轮询分区策略,是把所有的 partition 和所有的 consumer 都列出来,然后按照 hascode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者。
轮询分区分为如下两种情况:
①同一消费组内所有消费者订阅的消息都是相同的
②同一消费者组内的消费者所订阅的消息不相同
①如果同一消费组内,所有的消费者订阅的消息都是相同的,那么 RoundRobin 策略的分区分配会是均匀的。
例如:同一消费者组中,有 3 个消费者C0、C1和C2,都订阅了 2 个主题 t0 和 t1,并且每个主题都有 3 个分区(p0、p1、p2),那么所订阅的所以分区可以标识为t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终分区分配结果如下:
消费者C0 消费 t0p0 、t1p0 分区
消费者C1 消费 t0p1 、t1p1 分区
消费者C2 消费 t0p2 、t1p2 分区
②如果同一消费者组内,所订阅的消息是不相同的,那么在执行分区分配的时候,就不是完全的轮询分配,有可能会导致分区分配的不均匀。如果某个消费者没有订阅消费组内的某个 topic,那么在分配分区的时候,因为将所有的topic排序后轮询分发给消费者,会导致某个消费者没有订阅某个topic,但是分到的分区有该topic的分区
例如:同一消费者组中,有3个消费者C0、C1和C2,他们共订阅了 3 个主题:t0、t1 和 t2,这 3 个主题分别有 1、2、3 个分区(即:t0有1个分区(p0),t1有2个分区(p0、p1),t2有3个分区(p0、p1、p2)),假设整个消费者所订阅的所有分区排序后为t0p0、t1p0、t1p1、t2p0、t2p1、t2p2。具体而言,消费者C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2,最终分区分配结果如下:
消费者C0 消费 t0p0、t2p0
消费者C1 消费 t1p0、t2p1
消费者C2 消费 t1p1、t2p2
RoundRobin轮询分区的弊端:
从如上实例,可以看到RoundRobin策略也并不是十分完美,这样分配其实并不是最优解,因为完全可以将分区 t1p1 分配给消费者 C1。
所以,如果想要使用RoundRobin 轮询分区策略,必须满足如下两个条件:
①每个消费者订阅的主题,必须是相同的
②每个主题的消费者实例都是相同的。(即:上面的第一种情况,才优先使用 RoundRobin 轮询分区策略)
Range 范围分区策略是对每个 topic 而言的。首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。假如现在有 10 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6,7,8,9;消费者排序完之后将会是C1-0,C2-0,C3-0。通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
例如,10/3 = 3 余 1 ,除不尽,那么 消费者 C1-0 便会多消费 1 个分区,最终分区分配结果如下:
C1-0 消费 0,1,2,3 分区
C2-0 消费 4,5,6 分区
C3-0 消费 7,8,9 分区(如果有11 个分区的话,C1-0 将消费0,1,2,3 分区,C2-0 将消费4,5,6,7分区 C3-0 将消费 8,9,10 分区)
Range 范围分区的弊端:
如上,只是针对 1 个 topic 而言,C1-0消费者多消费1个分区影响不是很大。如果有 N 多个 topic,那么针对每个 topic,消费者 C1-0 都将多消费 1 个分区,topic越多,C1-0 消费的分区会比其他消费者明显多消费 N 个分区。这就是 Range 范围分区的一个很明显的弊端了
但是range分区容易随着topic的增加 导致消费者之间的数据不均衡 会数据倾斜
roundrobin以消费者组划分 range以topic划分
消费者offset存储
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
offset是存放在以(消费者组ID+topic+分区号,offset)这种K-V类型的结构中,如果不以消费者组去存放这个offset而是以消费者去存放的话,当消费者组中的某个消费者宕机,其他消费者组的消费者要去消费这个分区的数据时,并不知道上一次消费到那个地方,当以消费者组去存放时,当消费者组中的某个消费者宕机,消费者组中的其他消费者可以以消费者ID去找到这个offset
Kafka 高效读写数据
当Kafka以分布式模式时,因为Kafka集群是通过分区来并发读写,提高读写速度
当Kafka以单机模式时
(1)顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
(2)零复制技术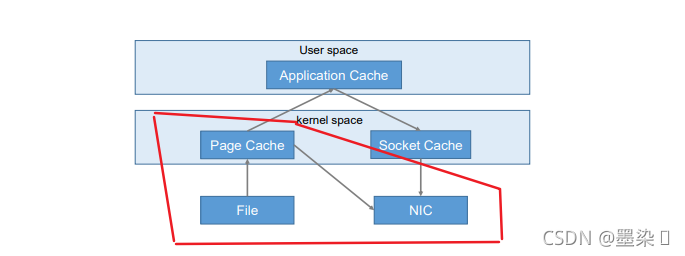
直接与操作系统交互,无需经过用户程序
producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的 Transaction ID,并将 Producer获得的PID 和Transaction ID 绑定。这样当Producer 重启后就可以通过正在进行的 TransactionID 获得原来的 PID
transactional.id与producerId在事务管理器中是一一对应关系。
即transactional.id作为key,producerId作为value这样的键值对方式存储在事务管理器中,当producer恢复时,会通过用户自己指定的transactional.id从事务管理器获取producerId,以此来确保幂等性不同会话之间发送数据的幂等性。
自定义分区器
由于业务需要 可能不能直接用默认的分区器 比如MR中要对传进来的数据根据Key做分区 不同key分到不同的分区中 这样就需要用自定义分区器来实现 重写partition方法 方法中获取可用的分区数量 再根据数据具体业务做下一步实现
KafkaProducer 发送消息流程
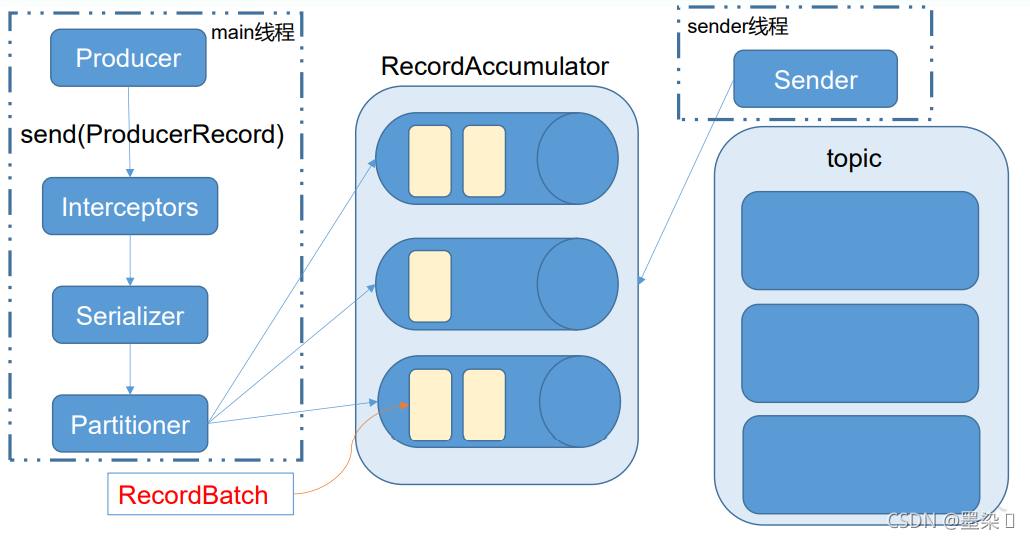
API发送方式:同步&&异步
同步方式:一定是逐条发送的,第一条响应到达后,才会请求第二条
异步方式:可以发送一条,也可以批量发送多条,特性是不需等第一次(注意这里单位是次,因为单次可以是单条,也可以是批量数据)响应,就立即发送第二次
同步发送
如果需要使用同步发送,可以在每次发送之后使用get方法,因为producer.send方法返回一个Future类型的结果,Future的get方法会一直阻塞直到该线程的任务得到返回值,也就是broker返回发送成功。
消费者API
消费者poll方法中参数代表每次等到该时长 在这个时长内收集到的数据才提交
消费者设定从头开始消费数据有两个条件 :
1.当前的消费者组没有初始化过offset || 当前消费者组是一个新的组
2.消费者组已经初始化过也就是已经消费过数据 但是宕机重启且之前的offset已经过期7天
offset默认保留七天 假如某个生产者消费完1000条数据提交offset后宕机 七天后又重启 这时 这个消费者将无法重新消费之前的1000条数据 而是从1000开始消费 那么消费者API中的Auto_offset_reset属性将只能读到1000开始消费的数据。 而如果是第一次消费数据的消费者组或者像上面的情况 已经消费过数据的消费者组宕机后重启 但是offset已经删除了的 可以通过设定这个属性值为earliest来获取最近没被删除的offset 而如果不符合这两种消费者组的消费者组将只会获取最新消费的数据 而不会再获取已经消费过的数据
自动提交和手动提交offset
消费者在消费消息的过程中,配置参数设置为不自动提交offset,在消费完数据之后如果不手动提交offset,那么在程序中和Kafka中的数据会如何处理?
1.如果在消费kafka的数据过程中,一直没有提交offset,那么在此程序运行的过程中它不会重复消费。但是如果重启之后,就会重复消费之前没有提交offset的数据。
2.如果在消费的过程中有几条或者一批数据数据没有提交offset,后面其他的消息消费后正常提交offset,那么服务端会更新为消费后最新的offset,不会重新消费,就算重启程序也不会重新消费。
3.消费者如果没有提交offset,程序不会阻塞或者重复消费,除非在消费到这个你不想提交offset的消息时你尝试重新初始化一个客户端消费者,即可再次消费这个未提交offset的数据。因为客户端也记录了当前消费者的offset信息,所以程序会在每次消费了数据之后,自己记录offset,而手动提交到服务端的offset与这个并没有关系,所以程序会继续往下消费。在你重新初始化客户端消费者之后,会从服务端得到最新的offset信息记录到本地。所以说如果当前的消费的消息没有提交offset,此时在你重新初始化消费者之后,可得到这条未提交消息的offset,从此位置开始消费。
手动提交offset VS 自动提交offset
由于自动提交offset中 当处理数据的延迟设定较短的时候 可能会因为没处理完就提交了offset 再从最新的offset开始拉取数据 就会导致数据丢失 而手动提交offset分为同步提交和异步提交 但是不管是哪种提交方式 如果在处理完数据之后 消费者宕机了 但是offset还没提交成功 那么都会造成数据重复问题 而先提交offset后消费数据又容易造成数据丢失 所以需要将offset保存在mysql等数据库中 并在两者之间设定事务 保证当某个消费者组宕机后 可以利用rebalance 将宕机的消费者组负责的分区分到其他消费者组消费 利用自定义的offset存储方式取到offset 再继续消费 由于中间设定了事务 所以不会出现数据丢失和重复问题