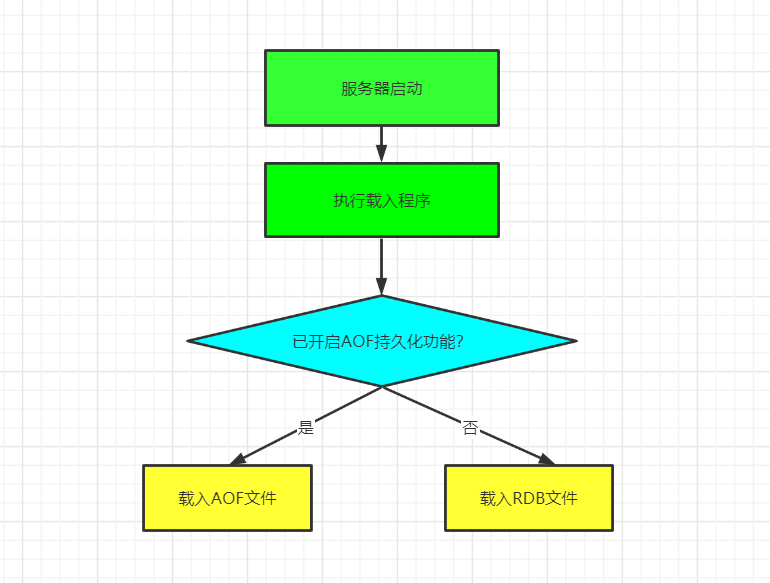
我们都知道Redis的数据都存在内存里,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证Redis的数据不会因为故障而丢失,这种机制就是Redis的持久化机制。 Redis的持久化机制主要是有两种,第一种是RDB快照,第二种是AOD日志。如果我们的服务器开启了AOF持久化功能,那么服务器会优先使用AOF文件来还原数据库的状态。只有在AOF持久化功能处于关闭的状态的时候,服务器才能使用RDB文件来还原数据库状态。
RDB持久化
RDB持久化是通过快照来实现的,在指定的时间间隔内将内存的数据集快照写入磁盘,恢复的时候就是将快照文件读取到内存中。 可是我们知道Redis是单线程的,内存快照又要要求Redis进行文件IO操作,可是文件IO操作时不能使用多路复用API,这意味着我们单线程要处理服务器上的请求,还有处理文件IO操作,显然是会拖垮服务器请求的性能。 我们是如何解决的呢,这用到了COW(Copy On Write)来实现持久化。 Redis会单独创建(Fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作。这就确保了极高的性能,如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那么RDB方式比AOF方式更加的高效。RDB的缺点就是最后一次持久化后的数据可能丢失。(默认的RDB文件为dump.rdb)

子进程做数据持久化,它不会修改现有的内存数据结构,它只是对数据结构进行遍历读取,然后序列化写到磁盘中。但是父进程不一样,它必须持续服务客户端请求,然后对内存数据结构进行不间断的修改。那我们不可能对同一片内存进行操作,所以用到了写入时复制。 数据段是由很多操作系统的页面组合而成,当父进程对其中一个页面的数据进行修改时,会将被共享内存复制一份分离出来,然后对这个复制的页面进行修改。这时子进程相应的页面是没有变化的,还是进程产生时那一瞬间的数据。所以才被称为快照的原因。(具体流程对应上图操作)
触发条件
我们上面也提到了RDB的操作,那么什么时候会触发呢?
指令触发:- SAVE:立刻redis数据持久化,其他全部阻塞
- BGSAVE:redis会在后台异步进行快照操作,同时还可响应客户端的请求,可用命令 lastsave 获取最后一次成功执行快照的时间
- FLUSHALL:清空命令也会触发持久化操作,但dump.rdb文件中是空的,无意义
- SHUTDOWN :关闭数据库命令也会触发redis持久化操作 ,前提是没有开启AOF持久化
- DEBUG RELAOD:用该命令重新加载Redis时,也会自动触发save操作
配置文件触发:- 在我们的Redis文件的redis.conf文件中可以设置save 指定在 seconds 秒内有 changes 次跟新操作,就进行一次持久化。(用的也是BGSAVE)
save 900 1
save 300 10
save 60 10000
复制代码
- 如果从节点执行全量复制操作,主节点自动执行BGSAVE 生成RDB文件并发送给从节点
优缺点
优点:- 对数据的完整性要求不高
- 因为主进程不进行任何的IO操作,所以对数据的大规模恢复有着极高的性能
缺点:- fork进程的时候,会占用一定的内存空间
- 需要一定的时间间隔来进行操作,如果redis意外宕机了,那么最后一次修改的数据就没有了
恢复持久化文件: 将备份文件移动至
dir 参数配置持久化文件的目录下,并将文件名改为
dbfilename 参数配置持久化参数的文件名,然后启动数据库即可恢复数据。 若 dump.rdb 文件存在异常,数据恢复将报错。可使用命令
redis-check-dump --fix 命令对 dump.rdb 持久化文件进行修复,然后重启redis服务即可。
AOF(Append-Only-File)持久化
以独立日志的方式记录每次写命令,写入的内容直接是文本协议格式,重启时再重新执行AOF文件中的命令达到恢复数据的目的,解决了数据持久化实时性问题。
appendonly no
复制代码
如果开启了AOF,默认的文件名是appendonly.aof,路径与RDB文件同级。
ReWrite重写机制
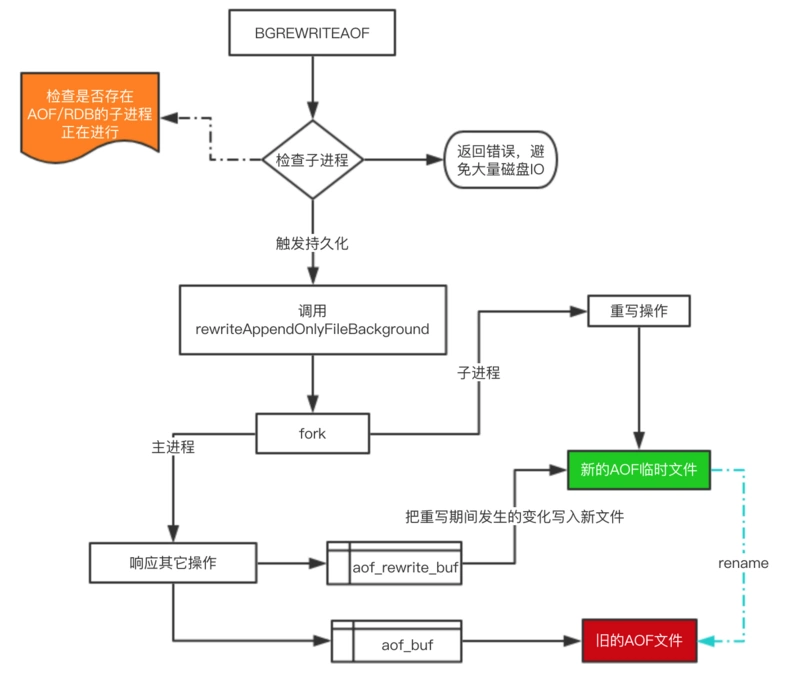
**引入重写机制背景:**AOF采用文件追加的方式,将导致文件越来越大,故新增重写机制。当AOF文件大小超过所设置的阈值时,Redis将启动AOF内容压缩,只保留可以恢复数据的最小指令集。 **原理:**Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身(重写)。其原理就是开辟一个子进程对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。序列化完毕后再将操作期间发生的增量AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。
AOF的具体工作流程:- 命令的实时写入,调用到命令
- 所有的写入命令追加到aof_buf(缓冲区)中
- AOF缓冲区根据对应的策略向硬盘做同步操作
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,压缩,父进程执行fork创建子进程,由子进程根据内存快照执行AOF重写,父进行继续响应后面的命令,在子进程完成重写后,父进程再把新增的写入命令写入到新的AOF文件中
- Redis服务重启,加载AOF文件进行数据恢复
触发机制
主动触发: 使用
bgrewriteaof命令
被动触发: 配置文件设置,有两个参数
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
复制代码
优缺点
优点:- 如果每一次都修改都同步的话,可以更好的保持数据完整性
- 如果每秒都同步一次的话,如果发生宕机什么的话,最多可能丢失一秒的数据
- 如果从不同步的话,具有效率最高的特点
缺点:- 相对于数据文件来说,AOF远远大于RDB,修复的速度也比RDB慢
- AOF运行效率也比RDB慢,所以我们Redis默认的配置就是RDB持久化
fsync同步策略
上面我们也说到了AOF缓冲区会根据对应的策略向硬盘做同步操作,那么具体有哪些同步策略呢? AOF缓冲区同步策略,通过参数appendfsync控制,具体有三个配值
| 选项的值 | 说明 | 其他 |
|---|
| always | 命令写入aof_buf后调用系统fsync操作同步到AOF文件,fsync完成后线程返回 | 每次写入都要同步AOF文件,在一般的SATA硬盘很难达到高性能 |
| everysec | 命令写入aof_buf后调用系统write操作,write完成后线程返回。fsync同步操作由线程每秒调用一次(建议策略) | 默认同步策略 |
| no | 命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步,同步硬盘操作由操作系统负责,通常同步周期最长30秒 | 操作系统每次同步AOF文件的周期不可控,而且会加大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证 |
**补充:**如果同时开启了RDB和AOF的话,我们是优先加载AOF。因为AOF保存的数据更加完整,最多也就损失1s的数据。
关于AOF的面试题
AOF为什么直接采用文本协议格式?- 文本协议具有良好的兼容性
- 开启AOF后,所有写入命令都包含追加操作,直接采用协议格式,避免二次处理开销
- 文本协议具有可读性,方便直接修改和处理
AOF 为什么把命令追加到aof_buf中- 写入缓存区aof_buf中,能提高性能,并且Redis提供了多种缓存区同步硬盘策略
重写后的AOF文件为什么可以变小?- 进程内已经超时的数据不再写入文件
- 旧的AOF文件含有无效命令,重写使用进程内数据直接生成,新的AOF文件只保留最终数据的写入命令
- 多条写命令可以合并为一个,为了防止溢出,以64个元素为界拆分为多条