前言(日常废话)
本篇文章记录了本人所知道的用原生JS来获取到DOM元素节点的几种办法,做个记录,加深记忆,方便以后复习。
正文
本文所做演示基于下面的HTML结构: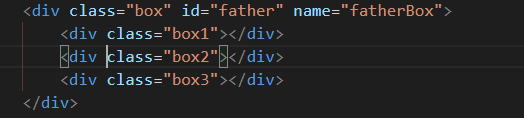
本文内容通过个人理解的分类进行归纳总结,大致的目录骨架如下:
目录
一、通过document顶层方法获取
我们要获取DOM最先想到的代码段就是document系列,通过控制台打印console.log(document),可以看到document代表的是整个页面文档。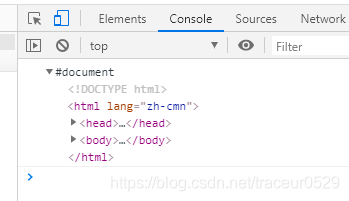
然后我们就可以通过各种类型的方法去获取document下面的各个节点了,接下来进行逐一说明:
1、document获取html,body标签
本节前言:要获取html,head,body标签不是只能用下面的办法,只是下面的三种方法是专门用来获取它们的,所以单独分类在这里介绍,你也可以用后文介绍到的那些方法(通过选择器获取之类的)来获取到这三个标签。担心大家被我这小节的标题误导了,所以啰嗦一下,废话不多说,开始本小节:
1.1、获取html标签
获取html标签有一个专门的方法,那就是document.documentElement,打印到控制台,如下图所示: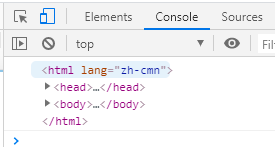
1.2、获取head标签
获取head标签也有一个专用方法:document.head,打印到控制台,如下图所示: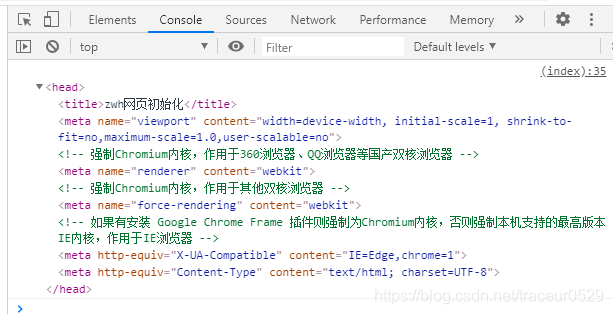
1.3、获取body标签
获取body标签同样有一个专门的方法:document.body,打印到控制台,如下图所示: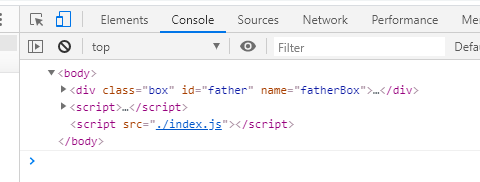
2、getElementBy系列获取
在写HTML页面时,我们为了语义化,会用到各种各样的标签,有时也会给标签设置上id、class、name等属性,这些行为都为我们在js代码中获取这个DOM元素提供了便利,我们就可以通过document提供的getElementBy系列来进行元素节点的获取:
2.1、通过ID获取
通过ID获取元素的方法是document.getElementById('在想要获取到的元素标签上设置的id名')
通过打印document.getElementById('father')可以看到因为ID具有的唯一性,所以通过这个方法返回来的是单独一个元素: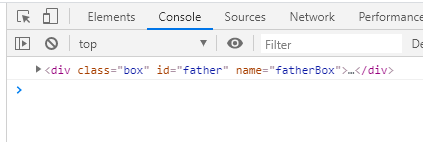
如果你不小心给两个标签添加了一样的id,那他在获取到第一个id匹配的标签时便会停止搜索,如下图所示,我在原有的结构前面加了一个同样是father ID的div
这个时候通过这个getElementById(“father”)打印出来的元素就是这个新加的,而不是我们刚刚打印的那个。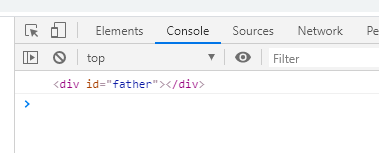
2.2、通过类名获取
通过类名获取元素的方法是getElementsByClassName('在想要获取到的元素标签上设置的class类名')
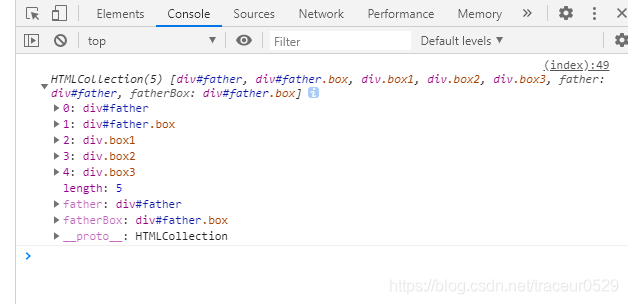
通过打印document.getElementsByClassName('box')我们就可以在控制台看见在我们的页面中设置的class为box的元素标签了: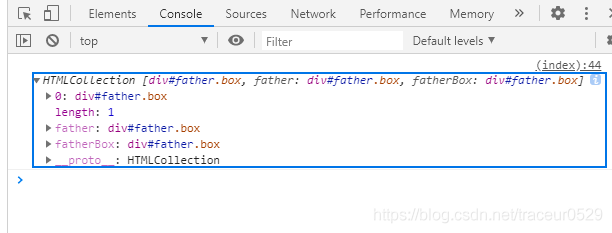
我们可以发现上面打印出来的和我们通过id打印出来的不太一样,打印出来的是HTMLCollection(关于HTMLCollection这个概念,看官大老爷们可以自行百度,因为我对它的理解也不够深)一个数组,数组里面存放的就是我们要获取的标签了,为什么是数组呢,因为我们知道在HTML中css的样式class属性是可以多个标签共用的,所以我们获取到的就是一个数组了(个人理解它设置成这样是因为这个原因,如果有错请指正,小白马上修改,尽量不误人子弟)。
知道了返回来的是一个数组,那我们在取元素的时候就用数组取值的方法即可比如document.getElementsByClassName('box')[0]来获取到class为box的标签组里的第一个标签元素。
2.3、name属性获取
通过name属性获取元素的方法是getElementsByName('在想要获取到的元素标签上设置的name属性值')
通过在控制台打印console.log(document.getElementsByName('fatherBox'))就可以在控制台看见返回的是一个NodeList(NodeList这个概念和前面通过class类名获取里面提到的HTMLCollection概念相似但是又有不同,因为本小白也说不明白,所以具体的还请看官大佬们自行百度)数组,
2.4、通过标签名获取
通过标签名获取元素的方法是getElementsByTagName('想要获取到的元素标签名')
如果既没有给元素设置id,name这样的标识符,也没有添加class类,那要怎么获取到标签元素呢,getElementsByTagName满足你的要求。在控制台打印document.getElementsByTagName('div')可以看到返回了一个HTMLCollection数组,数组里面包含了我们HTML中的所有div
3、query系列获取
当我们只有父元素有设置id、class、name值,然后HTML内容又偏多时,这个时候用上面的那四种选择器都不太方便,所有在HTML5中添加了query选择器来帮助我们更方便的获取到元素。
3.1、通过query选择器获取一个元素
通过query选择器获取一个元素的方法是querySelector('根据css选择器的规则选择想要获取到的元素'),注意要根据css选择器的匹配规则去获取。当选择器选择的内容为多个时,会只选择匹配到的第一个元素返回,但是这里的第一个和前面ById选择器的选择第一个返回不太一样,比如你还是不小心给两个元素写了一样的Id,都是father,然后第一个father里面没有div,第二个father里面有多个div,这个时候querySelector会先匹配到第一个father然后往里面匹配,发现没有可以匹配到的div来返回,他就会进入到第二个father里面进行匹配,将匹配到的第一个div进行返回处理;但是,如果第一个father里面有了可以返回的div,那么它就不会匹配第二个father。可能说的不够直观,我们直接上图:
(1)两个father,第一个father里面没有div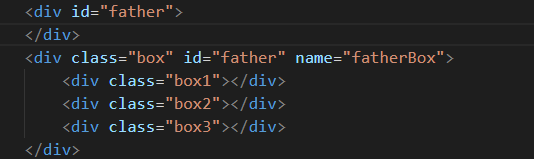
在控制台打印document.querySelector('#father>div')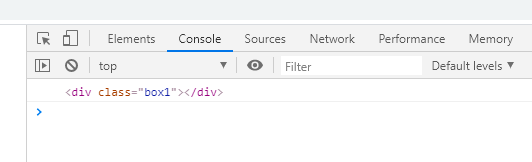
(2)两个father,第一个father里面有div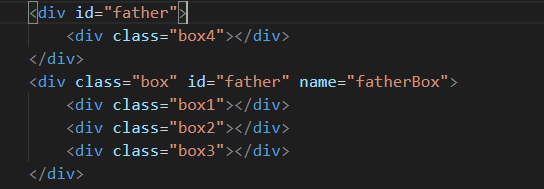
在控制台打印document.querySelector('#father>div')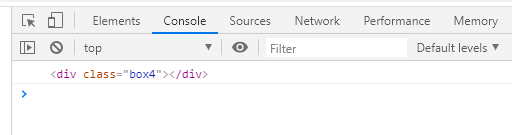
3.2、通过query选择器获取一组元素
通过query选择器获取一组元素的方法是querySelectorAll('根据css选择器的规则选择想要获取到的元素'),注意要根据css选择器的匹配规则去获取。
在控制台打印document.querySelectorAll('#father>div')可以看到返回了一个NodeList数组,里面包含着我们通过匹配规则匹配到的所有div元素。

可能有看官大佬就好奇了,这时候要是多写了个重复id的元素会出现啥情况呀,别急,我给您打印出来了,还是上面那个两个father,第一个father里面有一个div,第二个father里面有三个div的结构,再打印一遍document.querySelectorAll('#father>div'):

我们可以看到他把两个重复id的父级元素里面的子div全都获取进数组了。
4、小结
到这里通过document顶层方法获取元素标签的方法就结束了,下面是通过节点的一些属性来获取元素的内容。其实到这里我们已经可以获取到任何在HTML中的DOM元素并对其进行一些需求的操作了,后面的内容可以当做一个补充进行相关的了解,也许有用到的时候也说不准嘛…
二、通过节点的属性获取
每个DOM元素其实都可以看作是一个对象,在这个DOM元素对象里面有着用于获取各类节点的属性,我们可在通过第一节介绍的方法获取到一个节点,然后通过操作这个节点上的属性获取到想要的元素节点。
1、获取父节点
1.1、parentNode获取父节点
我们可以通过parentNode属性获取到元素的父节点,比如在控制台打印document.getElementsByClassName('box2')[0].parentNode就可以获取到类名为box2的元素数组中第一个元素的父节点了,打印结果为: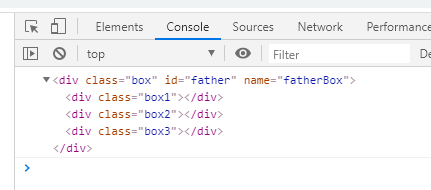
2、获取子节点
2.1、childNodes获取所有子节点
我们可以通过childNodes属性获取到元素的父节点,比如在控制台打印document.getElementById('father').childNodes就可以获取到ID为father的元素底下的所有子节点了,通过观察控制台我们可以看见返回了一个NodeList数组: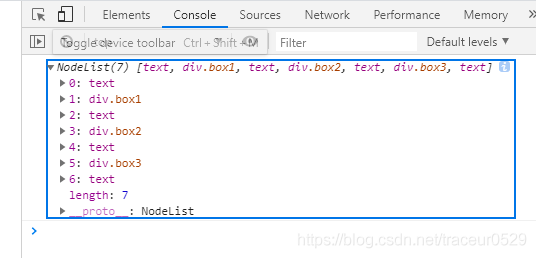
我们可以看到数组里面出现了一些奇怪的东西–text,这个其实是我们在编辑器里面打代码时为了代码结构清晰一些,打的空格。每一个子元素的头尾但凡有空格的地方都会解析成text并加入到数组里面。我们要操作这样的数组就很难受了,所以不推荐使用这个办法。
2.2、children获取所有子节点
我们还可以通过children来获取所有的子节点,这个属性和childNodes一样都会返回一个数组,只不过返回的是一个HTMLCollection数组。在控制台打印document.getElementById('father').children结果如下:
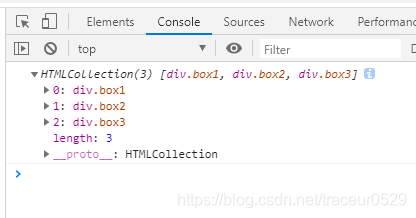
可以看到,我们获取到的数组和用childNodes获取到的子节点数组不太一样,它没有奇奇怪怪的东西–text,这种情况下,我们可以更好的进行需求操作,所以如果你要用节点的属性来获取全部子节点时,推荐使用children而不是childNodes。
2.3、firstChild获取首个子节点
当我们要获取一个元素的首个子节点时,我们就可以使用firstChild属性啦。同样的在控制台打印一下看看返回结果console.log(document.getElementById('father').firstChild):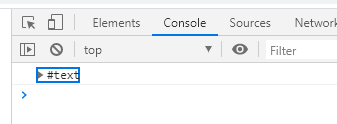
我们发现打印出来了一个似曾相识的东西,前面childNodes返回的数组里面出现过的text,那这应该也是空格的问题吧,将第一个子节点前面的空格给删了再看看
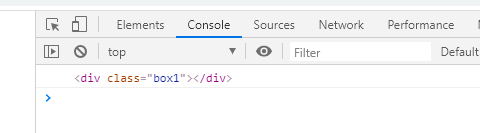
可以看到他完美的返回了我们想要的东西。
因为他不会过滤换行空格之类的所以可以将它变相的认为是childNodes[0]。
2.4、lastChild获取最后一个子节点
当我们要获取一个元素的最后一个子节点时,我们就可以使用lastChild属性啦。同样的在控制台打印一下看看返回结果console.log(document.getElementById('father').lastChild):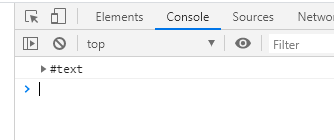
可以发现依旧是换行、空格的问题,和firstChild解决方法略有不同的是,firstChild去除的是第一个子节点前面的间隙,而lastChild要去除的是最后一个子节点后面的间隙:
这个时候再打印就会得到我们需要的最后一个子节点元素了: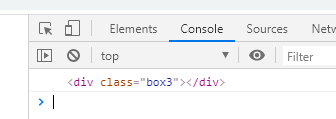
3、获取兄弟节点
使用sibling系列属性来获取兄弟元素
3.1、previousSibling获取前一个兄弟元素
使用previousSibling获取前一个兄弟元素,通过控制台打印document.getElementsByClassName('box2')[0].previousSibling来获取box2前面的兄弟元素: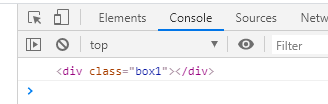
3.2、nextSibling获取后一个兄弟元素
使用nextSibling获取后一个兄弟元素,通过控制台打印document.getElementsByClassName('box2')[0].nextSibling来获取box2后面的兄弟元素: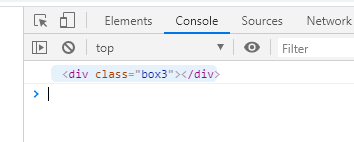
3.3、本节小结
注意获取兄弟元素同样会有换行、空格解析成text的问题,所以在使用时要把兄弟元素与本元素之间的间隙都删除掉,换句话说就是删除掉已经获取到的节点前后的间隙:
4、小结
会打印出text的几个方法(childNodes获取所有子节点、firstChild获取首个子节点、firstChild获取首个子节点、lastChild获取最后一个子节点、previousSibling获取前一个兄弟元素、nextSibling获取后一个兄弟元素),个人不建议使用,现在编辑器都是格式化美化代码,一不留神就换行了,那真的就是到处都是text了。
写给看贴的你
不知道还有什么没提到的获取方式,希望看官大老爷们将上述未及的方法评论在下面,带小白一把,共同进步,万分感谢~
本人见识短浅,如有错误以及缺漏的地方请指正批评;如有涉及侵权,请手下留情,联系本人,看见即删(手动狗头保命)。
祝各位看官大佬们身体健康、诸事顺心、仙运荣昌、少写bug多加薪…