spark中coalesce、repartition和partitionBy的区别
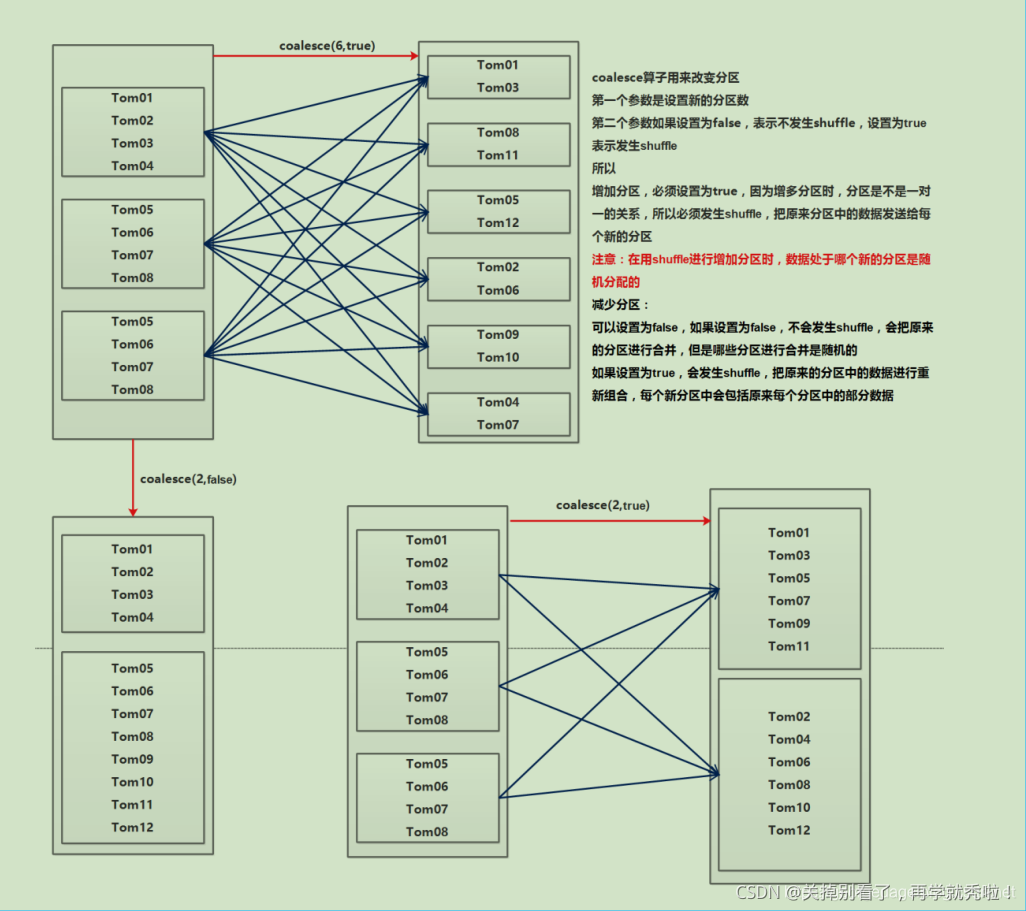
coalesce
- false:不产生 shuffle
- true:产生 shuffle
- 如果重分区的数量大于原来的分区数量,必须设置为 true,否则分区数不变
- 增加分区会把原来的分区中的数据随机分配给设置的分区个数
repartition
repartition实际上就是coalesce
repartition(int n) = coalesce(int n, true),也就是说,repartition默认就实现了shuffle操作,保证了分区时数据均匀。
在缩小分区的时候可以使用coalesce(int n, false) ,而不是repartition(int n)。这样就避免shuffle过程
partitionBy
partitionBy属于PairRDDFunctions 这里从rdd到PairRDDFunctions发生了隐式转换
- partitionBy针对的是 键值对类型
- partitionBy会根据指定的分区规则对数据进行重新分区
版权声明:本文为YYDS_emmm原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。