Flink 流处理核心编程及算子操作
经过一段时间的学习,我对flink流处理的编程基础、核心API(转换算子)、开发流程等做出了如下整理。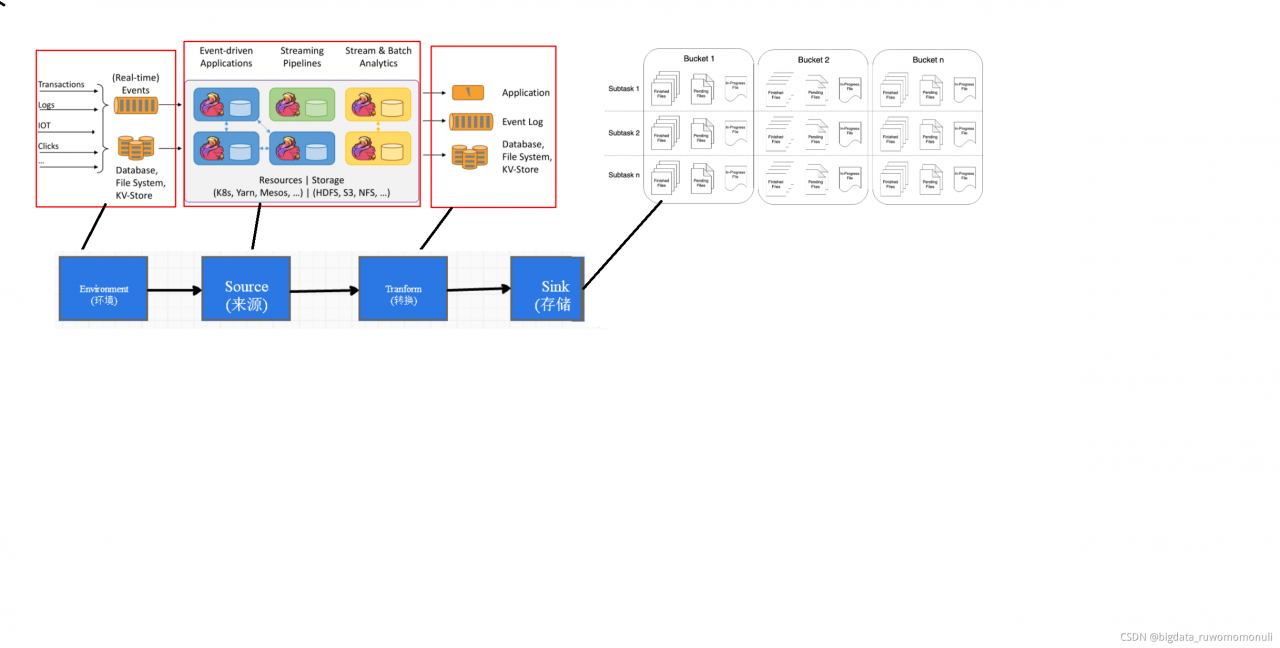
Environment运行环境
从flink1.12.0起,flink在真正的意义上实现了流批一体。
flink的运行环境包括批处理环境和流处理环境
在开发过程中获取比较简单,只需要如下操作
// 批处理环境
ExecutionEnvironment benv = ExecutionEnvironment.getExecutionEnvironment();
// 流式数据处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Source数据来源
Flink框架可以从不同的来源获取数据,将数据提交给框架进行处理, 我们将获取数据的来源称之为数据源(Source)。
比如集合、文件、网络端口、kafka、hdfs以及自定义等等。
这些比较简单
- 比如从文件中获取
readTextFile("input")
- 从网络端口获取
env.socketTextStream("localhost", 9999)
- 从kafka获取
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
- 数据从dhfs目录下读取
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
- 自定义Source
需要实现SourceFunction相关接口,
重写run()和canel()方法,需要指定并行度的话可以实现ParallelSourceFunction这个接口
public static class
AppMarketingDataSource extends
RichSourceFunction<MarketingUserBehavior>{}
Flink 转换算子
转换算子可以把一个或多个DataStream转成一个新的DataStream.程序可以把多个复杂的转换组合成复杂的数据流拓扑。
- map 算子
作用将数据流中的数据转换,形成新的流,元素消费一个产生一个(一对一)
MapFunction实现类,或者使用lambda表达式
1.匿名内部类对象方法
env
.fromElements(1, 2, 3, 4, 5)
.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return value * value;
}
})
2.Lambda表达式方法
env
.fromElements(1,2,3,4,5)
.map(ele -> ele * ele)
.print();
3.静态内部类
env
.fromElements(1, 2, 3, 4, 5)
.map(new MyMapFunction())
.print();
env.execute();
}
public static class MyMapFunction implements MapFunction<Integer, Integer> {
@Override
public Integer map(Integer value) throws Exception {
return value * value;
}
}
- flatMap算子
作用:消费一个元素并产生0个或者多个元素
FlatMapFunction实现类,或者使用lambda表达式
匿名内部类写法
env
.fromElements(1, 2, 3, 4, 5)
.flatMap(new FlatMapFunction<Integer, Integer>() {
@Override
public void flatMap(Integer value, Collector<Integer> out) throws Exception {
out.collect(value * value);
out.collect(value * value * value);
}
})
.print();
Lambda表达式写法
env
.fromElements(1,2,3,4,5)
.flatMap((Integer value, Collector<Integer> out) -> {
out.collect(value * value);
out.collect(value * value *value);
}).returns(Types.INT)
.print();
在使用Lambda表达式表达式的时候, 由于泛型擦除的存在, 在运行的时候无法获取泛型的具体类型, 全部当做Object来处理, 及其低效, 所以Flink要求当参数中有泛型的时候, 必须明确指定泛型的类型.
lamdba表达式本身不难,使用lamdba表达式,最重要的是需要弄清楚,表达式对应的输入输出类型。使用起来需要对整体需求理解深刻,也需要,注意泛型擦除问题的解决。
- filter算子
作用:根据指定的规则将满足条件(true)的数据保留,不满足条件(false)的数据丢弃
FilterFunction实现类、Lambda表达式
匿名内部类写法
env
.fromElements(10, 3, 5, 9, 20, 8)
.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value % 2 == 0;
}
})
.print();
Lambda表达式写法
env
.fromElements(10,3,5,9,20,8)
.filter(value -> value % 2 ==0)
.print();
- keyBy
把流中的数据分到不同的分区中.具有相同key的元素会分到同一个分区中.一个分区中可以有多重不同的key.
Key选择器函数: interface KeySelector<IN, KEY> 或者 lamdba表达式
// 奇数分一组, 偶数分一组
env
.fromElements(10, 3, 5, 9, 20, 8)
.keyBy(new KeySelector<Integer, String>() {
@Override
public String getKey(Integer value) throws Exception {
return value % 2 == 0 ? "偶数" : "奇数";
}
})
.print();
env.execute();
env
.fromElements(10, 3, 5, 9, 20, 8)
.keyBy(value -> value % 2 == 0 ? "偶数" : "奇数")
.print();
这里使用了三元运算符
a = b ? x : y ;
a=b 判断,如果为真,则输出x,否则输出y
keyBy也可以直接指定索引位置或者字段名
直接指定索引只能用于Tuple元组,指定字段名适用于POJO(java对象)
- shuffle算子
把流中的元素随机打乱.
这个没啥写的
env
.fromElements(10, 3, 5, 9, 20, 8)
.shuffle()
.print();
env.execute();
- connect算子和union算子
这两个连接算子都是对流的连接,具体写法超级简单如下
intStream.connect(stringStream);
stream1
.union(stream2)
.union(stream3)
主要讲讲区别,如下是我总结的
| 连接算子 | 操作流的个数 | 连接流的数据类型 |
|---|---|---|
| connect | 必须两个 | 可以不同 |
| union | 两个及以上 | 必须相同 |
- 常见的滚动聚合算子sum, min,max,minBy,maxBy
KeyedStream的每一个支流做聚合。执行完成后,会将聚合的结果合成一个流返回,所以结果都是DataStream
如果流中存储的是POJO(java对象)或者scala的样例类, 参数使用字段名
如果流中存储的是元组, 参数就是索引位置(基于0…)
返回
KeyedStream -> SingleOutputStreamOperator
kbStream.sum(0).print("sum");
kbStream.max(0).print("max");
kbStream.min(0).print("min");
- reduce
一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
ReduceFunction接口 或者 lamdba 方法
kbStream
.reduce((value1, value2) -> {
System.out.println("reducer function ...");
return new WaterSensor(value1.getId(), value1.getTs(), value1.getVc() + value2.getVc());
})
.print("reduce...");
经过测试可以得出一下两点
1、一个分组第一条数据来的时候,不会进入reduce方法。
2、输入和输出的数据类型,一定要一样。
process算子,flink比较低层的一个算子,可以在很多类型到的流上调用,可以从流中获取更多的信息(不仅仅数据本身)。比较强大。
写法直接匿名内部类,找出相应的function即可。重分区算子总结
为了方便大家记忆我特意将四大重分区算子的特点总结成了一张表格。
| 重分区算子 | 分区规则 | 特点 |
|---|---|---|
| KeyBy | 先分组再分区 | 根据key两次分区再计算().murmurHash和hashCode() |
| shuffle | 随机分区 | random.nextInt(numberOfChannels); |
| reblance | 轮巡平均分区 | 对流中的元素平均分布到每个分区 |
| rescale | 分组轮巡 | 也是平均分区,但是会先分组再轮巡 |
今天的分享就到这儿了哈!喜欢大数据的小伙伴可以关注我的账号,我会时常更新flink相关的知识点及项目实战的经验。有什么问题也可以私信我,我会在看到问题的第一时间,帮助解决问题。