1、node.js到底是什么?
简单的说 Node.js 就是运行在服务端的 JavaScript。
Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台。
Node.js是一个事件驱动I/O服务端JavaScript环境,基于Google的V8引擎,V8引擎执行Javascript的速度非常快,性能非常好。
node.js有非阻塞,事件驱动I/O等特性,从而让高并发(high concurrency)在的轮询(Polling)和comet构建的应用中成为可能。
解释:
传统的服务器(比如Apache),每次一个新用户连到网站上,服务器就得开一个连接。每个连接都需要占一个进程,这些进程大部分时间都是闲着的(比如等着你好友发新鲜事,等好友发完才给用户响应信息。或者等着数据库返回查询结果什么的)。虽然这些进程闲着,但是照样占用内存。这意味着,如果用户连接数的增长到一定规模,服务器没准就要耗光内存直接瘫了。
这种情况怎么解决?解决方法就是刚才上边说的:非阻塞和事件驱动。这些概念在我们谈的这个情景里面其实没那么难理解。你把非阻塞的服务器想象成一个loop循环,这个loop会一直跑下去。一个新请求来了,这个loop就接了这个请求,把这个请求传给其他的进程(比如传给一个搞数据库查询的进程),然后响应一个回调(callback)。完事了这loop就接着跑,接其他的请求。这样下来。服务器就不会像之前那样傻等着数据库返回结果了。
如果数据库把结果返回来了,loop就把结果传回用户的浏览器,接着继续跑。在这种方式下,你的服务器的进程就不会闲着等着。从而在理论上说,同一时刻的数据库查询数量,以及用户的请求数量就没有限制了。服务器只在用户那边有事件发生的时候才响应,这就是事件驱动。
2、node与javascript/php之间的区别
服务端I/O性能(用程序的输入/输出(I/O))之间的区别:
node.js:在需要做一些涉及I/O的操作的时候,你需要发出请求,并给出一个回调函数,Node会在处理完请求之后调用这个函数。
在请求中执行I/O操作的典型代码如下所示: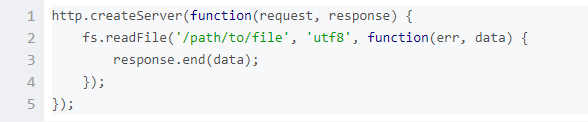
如上所示,这里有两个回调函数。当请求开始时,第一个函数会被调用,而第二个函数是在文件数据可用时被调用。
这样,Node就能更有效地处理这些回调函数的I/O。有一个更能说明问题的例子:在Node中调用数据库操作。首先,你的程序开始调用数据库操作,并给Node一个回调函数,Node会使用非阻塞调用来单独执行I/O操作,然后在请求的数据可用时调用你的回调函数。这种对I/O调用进行排队并让Node处理I/O调用然后得到一个回调的机制称为“事件循环”。这个机制非常不错。
但是,它的缺点在于,如果你在一个处理HTTP请求的函数中放入了CPU处理密集型代码的话,一不小心就会让每个连接都出现拥堵,举个例子,for循环在一个主线程中使用了CPU周期–这意味着如果你有10000个连接,那么这个循环就可能会占用整个应用程序的时间。每个请求都必须要在主线程中占用一小段时间。
PHP使用的模型非常简单。虽然不可能完全相同,但一般的PHP服务器原理是这样的:
用户浏览器发出一个HTTP请求,请求进入到Apache web服务器中。 Apache为每个请求创建一个单独的进程,并通过一些优化手段对这些进程进行重用,从而最大限度地减少原本需要执行的操作(创建进程相对而言是比较慢的)。
每个请求一个进程。 I/O调用是阻塞的。那么优点呢?简单而又有效。缺点呢?如果有20000个客户端并发,服务器将会瘫痪。这种方法扩展起来比较难,因为内核提供的用于处理大量I/O(epoll等)的工具并没有充分利用起来。更糟糕的是,为每个请求运行一个单独的进程往往会占用大量的系统资源,尤其是内存,这通常是第一个耗尽的。