mongodb学习
参考文章:https://gitee.com/AoiX/studied/blob/master/documents/MongoDB.md
问题参考文章:https://www.cnblogs.com/angle6-liu/p/10791875.html
1. MongoDB 相关概念
1.1 业务场景
传统的关系型数据库 (比如 MySQL), 在数据操作的”三高”需求以及对应的 Web 2.0 网站需求面前, 会有”力不从心”的感觉
所谓的三高需求:
高并发, 高性能, 高可用, 简称三高
- High Performance: 对数据库的高并发读写的要求
- High Storage: 对海量数据的高效率存储和访问的需求
- High Scalability && High Available: 对数据的高扩展性和高可用性的需求
而 MongoDB 可以应对三高需求
具体的应用场景:
- 社交场景, 使用 MongoDB 存储存储用户信息, 以及用户发表的朋友圈信息, 通过地理位置索引实现附近的人, 地点等功能.
- 游戏场景, 使用 MongoDB 存储游戏用户信息, 用户的装备, 积分等直接以内嵌文档的形式存储, 方便查询, 高效率存储和访问.
- 物流场景, 使用 MongoDB 存储订单信息, 订单状态在运送过程中会不断更新, 以 MongoDB 内嵌数组的形式来存储, 一次查询就能将订单所有的变更读取出来.
- 物联网场景, 使用 MongoDB 存储所有接入的智能设备信息, 以及设备汇报的日志信息, 并对这些信息进行多维度的分析.
- 视频直播, 使用 MongoDB 存储用户信息, 点赞互动信息等.
这些应用场景中, 数据操作方面的共同点有:
- 数据量大
- 写入操作频繁
- 价值较低的数据, 对事务性要求不高
对于这样的数据, 更适合用 MongoDB 来实现数据存储
那么我们什么时候选择 MongoDB 呢?
除了架构选型上, 除了上述三个特点之外, 还要考虑下面这些问题:
- 应用不需要事务及复杂 JOIN 支持
- 新应用, 需求会变, 数据模型无法确定, 想快速迭代开发
- 应用需要 2000 - 3000 以上的读写QPS(更高也可以)
- 应用需要 TB 甚至 PB 级别数据存储
- 应用发展迅速, 需要能快速水平扩展
- 应用要求存储的数据不丢失
- 应用需要
99.999%高可用 - 应用需要大量的地理位置查询, 文本查询
如果上述有1个符合, 可以考虑 MongoDB, 2个及以上的符合, 选择 MongoDB 绝不会后悔.
如果用MySQL呢?
相对MySQL, 可以以更低的成本解决问题(包括学习, 开发, 运维等成本)
1.2 MongoDB 简介
MongoDB是一个开源, 高性能, 无模式的文档型数据库, 当初的设计就是用于简化开发和方便扩展, 是NoSQL数据库产品中的一种.是最 像关系型数据库(MySQL)的非关系型数据库. 它支持的数据结构非常松散, 是一种类似于 JSON 的 格式叫BSON, 所以它既可以存储比较复杂的数据类型, 又相当的灵活. MongoDB中的记录是一个文档, 它是一个由字段和值对(field:value)组成的数据结构.MongoDB文档类似于JSON对象, 即一个文档认 为就是一个对象.字段的数据类型是字符型, 它的值除了使用基本的一些类型外, 还可以包括其他文档, 普通数组和文档数组.
“最像关系型数据库的 NoSQL 数据库”. MongoDB 中的记录是一个文档, 是一个 key-value pair. 字段的数据类型是字符型, 值除了使用基本的一些类型以外, 还包括其它文档, 普通数组以及文档数组
MongoDB 数据模型是面向文档的, 所谓文档就是一种类似于 JSON 的结构, 简单理解 MongoDB 这个数据库中存在的是各种各样的 JSON(BSON)
- 数据库 (database)
- 数据库是一个仓库, 存储集合 (collection)
- 集合 (collection)
- 类似于数组, 在集合中存放文档
- 文档 (document)
- 文档型数据库的最小单位, 通常情况, 我们存储和操作的内容都是文档
在 MongoDB 中, 数据库和集合都不需要手动创建, 当我们创建文档时, 如果文档所在的集合或者数据库不存在, 则会自动创建数据库或者集合
1.3 MongoDB 的特点
1.3.1 高性能
MongoDB 提供高性能的数据持久化
- 嵌入式数据模型的支持减少了数据库系统上的 I/O 活动
- 索引支持更快的查询, 并且可以包含来自嵌入式文档和数组的键 (文本索引解决搜索的需求, TTL 索引解决历史数据自动过期的需求, 地理位置索引可以用于构件各种 O2O 应用)
- mmapv1, wiredtiger, mongorocks (rocksdb) in-memory 等多引擎支持满足各种场景需求
- Gridfs 解决文件存储需求
1.3.2 高可用
MongoDB 的复制工具称作副本集 (replica set) 可以提供自动故障转移和数据冗余
1.3.3 高扩展
水平扩展是其核心功能一部分
分片将数据分布在一组集群的机器上 (海量数据存储, 服务能力水平扩展)
MongoDB 支持基于片键创建数据区域, 在一个平衡的集群当中, MongoDB 将一个区域所覆盖的读写只定向到该区域的那些片
1.3.4 其他
MongoDB支持丰富的查询语言, 支持读和写操作(CRUD), 比如数据聚合, 文本搜索和地理空间查询等. 无模式(动态模式), 灵活的文档模型
2.MongoDB安装
windows:官网地址https://www.mongodb.com/try/download/community

推荐zip格式解压即用
MongoDB的版本命名规范如:x.y.z;
y为奇数时表示当前版本为开发版,如:1.5.2、4.1.13;
y为偶数时表示当前版本为稳定版,如:1.6.3、4.0.10;
z是修正版本号,数字越大越好
第二步:解压安装启动将压缩包解压到一个目录中。
在解压目录中,手动建立一个目录用于存放数据文件,如data/db
方式1:命令行参数方式启动服务在bin目录中打开命令行提示符,输入如下命令:
mongod --dbpath=..\data\db
我们在启动信息中可以看到,mongoDB的默认端口是27017,如果我们想改变默认的启动端口,可以通过–port来指定端口。
为了方便我们每次启动,可以将安装目录的bin目录设置到环境变量的path中,bin目录下是一些常用命令,比如mongod启动服务用的,mongo客户端连接服务用的
方式2:配置文件方式启动服务
在解压目录中新建config文件夹,该文件夹中新建配置文件mongod.conf,内如参考如下:
storage:
#The directory where the mongod instance stores its data.Default Value is "\data\db" onWindows.
dbPath: D:\MongoDB\mongodb-win32-x86_64-windows-4.4.6\data\db
后面的路径是之前创建db的那个路径
启动方式:
mongod -f ../conf/mongod.conf
或
mongod --config ../conf/mongod.conf
连接:
在命令提示符输入以下shell命令即可完成登陆
mongo
或
mongo --host=127.0.0.1 --port=27017
确定是否连接成功可以通过show dbs命令查看
图形化界面:
官网下载地址:https://www.mongodb.com/try/download/compass
3 基本常用命令
3.1 案例需求
存放文章评论的数据存放到MongoDB中,数据结构参考如下:
数据库:articledb
| 专栏文章评论 | comment | ||
|---|---|---|---|
| 字段名称 | 字段含义 | 字段类型 | 备注 |
| _id | ID | ObjectId或String | Mongo的主键的字段 |
| articleid | 文章ID | String | |
| content | 评论内容 | String | |
| userid | 评论人ID | String | |
| nickname | 评论人昵称 | String | |
| createdatetime | 评论的日期时间 | Date | |
| likenum | 点赞数 | Int32 | |
| replynum | 回复数 | Int32 | |
| state | 状态 | String | 0:不可见;1:可见; |
| parentid | 上级ID | String | 如果为0表示文章的顶级评论 |
3.2 数据库操作
3.2.1 选择和创建数据库
选择和创建数据库的语法格式:
use 数据库名称
如果数据库不存在则自动创建,例如,以下语句创建 spitdb 数据库:
use articledb
查看有权限查看的所有的数据库命令
show dbs
或
show databases
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
查看当前正在使用的数据库命令
db
MongoDB 中默认的数据库为 test,如果你没有选择数据库,集合将存放在 test 数据库中。
另外:
数据库名可以是满足以下条件的任意UTF-8字符串。
不能是空字符串("")。
不得含有’ '(空格)、.、$、/、\和\0 (空字符)。
应全部小写。
最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
admin:从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
3.2.2 数据库的删除
MongoDB 删除数据库的语法格式如下:
db.dropDatabase()
提示:主要用来删除已经持久化的数据库
3.3 集合操作
集合,类似关系型数据库中的表。
可以显示的创建,也可以隐式的创建。
3.3.1 集合的显式创建(了解)
基本语法格式:
db.createCollection(name)
参数说明:
name: 要创建的集合名称
例如:创建一个名为 mycollection 的普通集合。
db.createCollection("mycollection")
查看当前库中的表:show tables命令
show collections
或
show tables
集合的命名规范:
集合名不能是空字符串""。
集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
集合名不能以"system."开头,这是为系统集合保留的前缀。
用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
3.3.2 集合的隐式创建
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。
详见 文档的插入 章节。
提示:通常我们使用隐式创建文档即可。
3.3.3 集合的删除
db.collection.drop()
或
db.集合.drop()
集合删除语法格式如下:
返回值
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。
例如:要删除mycollection集合
db.mycollection.drop()
3.4 文档基本CRUD
文档(document)的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
3.4.1 文档的插入
(1)单个文档插入
使用insert() 或 save() 方法向集合中插入文档,语法如下:
db.collection.insert(
<document or array of documents>,
{
writeConcern: <document>,
ordered: <boolean>
}
)
参数:
| Parameter | Type | Description |
|---|---|---|
| document | document or array | 要插入到集合中的文档或文档数组。((json格式) |
| writeConcern | document | Optional. A document expressing the write concern. Omit to use the default write concern. See Write Concern.Do not explicitly set the write concern for the operation if run in a transaction. To use write concern with transactions, see Transactions and Write Concern. |
| ordered | boolean | 可选。如果为真,则按顺序插入数组中的文档,如果其中一个文档出现错误,MongoDB将返回而 不处理数组中的其余文档。如果为假,则执行无序插入,如果其中一个文档出现错误,则继续处理 数组中的主文档。在版本2.6+中默认为true |
【示例】
要向comment的集合(表)中插入一条测试数据:
db.comment.insert({"articleid":"100000","content":"今天天气真好,阳光明
媚","userid":"1001","nickname":"Rose","createdatetime":new Date(),"likenum":NumberInt(10),"state":null})
提示:
1)comment集合如果不存在,则会隐式创建
2)mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字),否则取出来就有问题了。
3)插入当前日期使用 new Date()
4)插入的数据没有指定 _id ,会自动生成主键值
5)如果某字段没值,可以赋值为null,或不写该字段。
执行后,如下,说明插入一个数据成功了。
WriteResult({ "nInserted" : 1 })
注意:
文档中的键/值对是有序的。
文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
MongoDB区分类型和大小写。
MongoDB的文档不能有重复的键。
文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
键不能含有\0 (空字符)。这个字符用来表示键的结尾。
.和$有特别的意义,只有在特定环境下才能使用。
以下划线"_"开头的键是保留的(不是严格要求的)。
(2)批量插入
语法:
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
参数:
| Parameter | Type | Description |
|---|---|---|
| document | document | 要插入到集合中的文档或文档数组。((json格式) |
| writeConcern | document | Optional. A document expressing the write concern. Omit to use the default write concern.Do not explicitly set the write concern for the operation if run in a transaction. To use write concern with transactions, see Transactions and Write Concern. |
| ordered | boolean | 可选。一个布尔值,指定Mongod实例应执行有序插入还是无序插入。默认为true。 |
【示例】
批量插入多条文章评论:
db.comment.insertMany([
{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我
他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-
05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},
{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔
悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},
{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船
长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},
{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯
撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},
{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫
嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-
06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}
])
提示:
插入时指定了 _id ,则主键就是该值。
如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。
因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理。如(了解):
try {
db.comment.insertMany([
{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我
他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-
05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},
{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔
悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},
{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船
长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},
{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯
撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},
{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫
嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-
06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}
])
catch (e) {
print (e);
}
3.4.2 文档的基本查询
查询数据的语法格式如下:
db.collection.find(<query>, [projection])
参数:
| Parameter | Type | Description |
|---|---|---|
| query | document | 可选。使用查询运算符指定选择筛选器。若要返回集合中的所有文档,请省略此参数或传递空文档 ( {} )。 |
| projection | document | 可选。指定要在与查询筛选器匹配的文档中返回的字段(投影)。若要返回匹配文档中的所有字段, 请省略此参数。 |
【示例】
(1)查询所有
如果我们要查询spit集合的所有文档,我们输入以下命令
db.comment.find()
或
db.comment.find({})
这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型。
如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型。
如果我想按一定条件来查询,比如我想查询userid为1003的记录,怎么办?很简单!只 要在find()中添加参数即可,参数也是json格式,如下:
db.comment.find({userid:'1003'})
如果你只需要返回符合条件的第一条数据,我们可以使用findOne命令来实现,语法和find一样。
如:查询用户编号是1003的记录,但只最多返回符合条件的第一条记录:
db.comment.findOne({userid:'1003'})
(2)投影查询(Projection Query):
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)。
如:查询结果只显示 _id、userid、nickname :
db.comment.find({userid:"1003"},{userid:1,nickname:1})
结果:
{ "_id" : "4", "userid" : "1003", "nickname" : "凯撒" }
{ "_id" : "5", "userid" : "1003", "nickname" : "凯撒" }
默认 _id 会显示。
如:查询结果只显示 、userid、nickname ,不显示 _id :
db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0})
结果:
{ "userid" : "1003", "nickname" : "凯撒" }
{ "userid" : "1003", "nickname" : "凯撒" }
再例如:查询所有数据,但只显示 _id、userid、nickname :
db.comment.find({},{userid:1,nickname:1})
3.4.3 文档的更新
更新文档的语法:
db.collection.update(query, update, options)
//或
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string> // Available starting in MongoDB 4.2
}
)
参数:
| Parameter | Type | Description |
|---|---|---|
| query document 更新的选择条件。可以使用与find()方法中相同的查询选择器,类似sql update查询内where后面的。。在3.0版中进行了更改:当使用upsert**?* rue执行update()时,如果查询使用点表示法在_id字段上指定条件,则MongoDB将拒绝插入新文档。 | ||
| update | document opripeline | 要应用的修改。该值可以是:包含更新运算符表达式的文档,或仅包含:对的替换文档,或在MongoDB 4.2中启动聚合管道。管道可以由以下阶段组成:其别名 set 其别名unset 其别名 replaceWith。换句话说:它是update的对象和一些更新的操作符(如 inc**.** )等,也可以理解为 |
| upsert boolean 可选。如果设置为true,则在没有与查询条件匹配的文档时创建新文档。默认值为false,如果找不到匹配项,则不会插入新文档。 | ||
| multi | boolean | 可选。如果设置为true,则更新符合查询条件的多个文档。如果设置为false,则更新一个文档。默认值为false。 |
| writeConcern document 可选。表示写问题的文档。抛出异常的级别。 | ||
| collation | document | 可选。 指校定对要规用则于允操许作用的户校为对字规符则串。比较指定特定于语言的规则,例如字母大小写和重音标记的规则。 校校对对规规则则选:项{ 具有以下语法: 区ca域se设Le置ve:l:,, c强as度eF:ir,st:, n替u代m:er,icordering:, 最向大后变:量:, }指定校对规则时,区域设置字段是必需的;所有其他校对规则字段都是可选的。有关字段的说明,请参阅校对规则文档。 如如果果未没指有定为校集对合规或则操,作但指集定合校具对有规默则认,校M对on规go则D(B将请使参用见以db前.c版re本at中eC使ol用ec的ti简on单(二)进)制,比则较该进操行作字将符使串用比为较集。合不指能定为的一校个对操规作则指。定多个校对规则。例如,不能为每个字段指定不同的校对规则,或者如果使用排序执行查找,则不能将一个校对规则用于查找,另一个校对规则用于排序。 3.4版新增。 |
| arrayFilters ar ay 可选(。一个筛选文档数组,用于确定要为数组字段上的更新操作修改哪些数组元素。在更新文档中,使用[ 筛选的 运算符来 义标识符,然后在 组过滤 档中 用。如果标识符未 在更 档中,则不 有标识符的 组筛选 档。注 , 必须 小 开头,并且只 [标识符])都必须指定一个对应的数组筛选器文档。也就是说,不能为同一标识符指定多个数组筛选器文档。3.6版+ | ||
| hint | Door csturminegnt | 可选。指定用于支持查询谓词的索引的文档或字符串。该选项可以采用索引规范文档或索引名称字符串。如果指定的索引不存在,则说明操作错误。例如,请参阅版本4中的“为更新操作指定提示。 |
提示:
主要关注前四个参数即可。
【示例】
(1)覆盖的修改
如果我们想修改_id为1的记录,点赞量为1001,输入以下语句:
db.comment.update({_id:"1"},{likenum:NumberInt(1001)})
执行后,我们会发现,这条文档除了likenum字段其它字段都不见了,
(2)局部修改
为了解决这个问题,我们需要使用修改器$set来实现,命令如下:
我们想修改_id为2的记录,浏览量为889,输入以下语句:
db.comment.update({_id:"2"},{$set:{likenum:NumberInt(889)}})
这样就OK啦。
(3)批量的修改
更新所有用户为 1003 的用户的昵称为 凯撒大帝 。
//默认只修改第一条数据
db.comment.update({userid:"1003"},{$set:{nickname:"凯撒2"}})
//修改所有符合条件的数据
db.comment.update({userid:"1003"},{$set:{nickname:"凯撒大帝"}},{multi:true})
提示:如果不加后面的参数,则只更新符合条件的第一条记录
(3)列值增长的修改
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 $inc 运算符来实现。
需求:对3号数据的点赞数,每次递增1
db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})
3.4.4 删除文档
删除文档的语法结构:
db.集合名称.remove(条件)
以下语句可以将数据全部删除,请慎用
db.comment.remove({})
如果删除_id=1的记录,输入以下语句
db.comment.remove({_id:"1"})
3.5 文档的分页查询
3.5.1 统计查询
统计查询使用count()方法,语法如下:
db.collection.count(query, options)
参数:
| Parameter | Type | Description |
|---|---|---|
| query | document | 查询选择条件。 |
| options | document | 可选。用于修改计数的额外选项。 |
提示:
可选项暂时不使用。
【示例】
(1)统计所有记录数:
统计comment集合的所有的记录数:
db.comment.count()
(2)按条件统计记录数:
例如:统计userid为1003的记录条数
db.comment.count({userid:"1003"})
提示:
默认情况下 count() 方法返回符合条件的全部记录条数。
3.5.2 分页列表查询
可以使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据。
基本语法如下所示:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
如果你想返回指定条数的记录,可以在find方法后调用limit来返回结果(TopN),默认值20,例如:
db.comment.find().limit(3)
skip方法同样接受一个数字参数作为跳过的记录条数。(前N个不要),默认值是0
db.comment.find().skip(3)
分页查询:需求:每页2个,第二页开始:跳过前两条数据,接着值显示3和4条数据
//第一页
db.comment.find().skip(0).limit(2)
//第二页
db.comment.find().skip(2).limit(2)
//第三页
db.comment.find().skip(4).limit(2)
3.5.3 排序查询
sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法如下所示:
db.COLLECTION_NAME.find().sort({KEY:1})
或
db.集合名称.find().sort(排序方式)
例如:
对userid降序排列,并对访问量进行升序排列
db.comment.find().sort({userid:-1,likenum:1})
提示:
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关。
3.6 文档的更多查询
3.6.1 正则的复杂条件查询
MongoDB的模糊查询是通过正则表达式的方式实现的。格式为:
db.collection.find({field:/正则表达式/})
或
db.集合.find({字段:/正则表达式/})
提示:正则表达式是js的语法,直接量的写法。
例如,我要查询评论内容包含“开水”的所有文档,代码如下:
db.comment.find({content:/开水/})
如果要查询评论的内容中以“专家”开头的,代码如下:
db.comment.find({content:/^专家/})
3.6.2 比较查询
<, <=, >, >= 这个操作符也是很常用的,格式如下:
db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value
db.集合名称.find({ "field" : { $lt: value }}) // 小于: field < value
db.集合名称.find({ "field" : { $gte: value }}) // 大于等于: field >= value
db.集合名称.find({ "field" : { $lte: value }}) // 小于等于: field <= value
db.集合名称.find({ "field" : { $ne: value }}) // 不等于: field != value
示例:查询评论点赞数量大于700的记录
db.comment.find({likenum:{$gt:NumberInt(700)}})
3.6.3 包含查询
包含使用$in操作符。示例:查询评论的集合中userid字段包含1003或1004的文档
db.comment.find({userid:{$in:["1003","1004"]}})
不包含使用$nin操作符。示例:查询评论集合中userid字段不包含1003和1004的文档
db.comment.find({userid:{$nin:["1003","1004"]}})
3.6.4 条件连接查询
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。(相 当于SQL的and)格式为:
$and:[ { },{ },{ } ]
示例:查询评论集合中likenum大于等于700 并且小于2000的文档:
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})
如果两个以上条件之间是或者的关系,我们使用 操作符进行关联,与前面 and的使用方式相同 格式为:
$or:[ { },{ },{ } ]
示例:查询评论集合中userid为1003,或者点赞数小于1000的文档记录
db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})
3.7 常用命令小结
选择切换数据库:use articledb
插入数据:db.comment.insert({bson数据})
查询所有数据:db.comment.find();
条件查询数据:db.comment.find({条件})
查询符合条件的第一条记录:db.comment.findOne({条件})
查询符合条件的前几条记录:db.comment.find({条件}).limit(条数)
查询符合条件的跳过的记录:db.comment.find({条件}).skip(条数)
修改数据:db.comment.update({条件},{修改后的数据}) 或db.comment.update({条件},{$set:{要修改部分的字段:数据})
修改数据并自增某字段值:db.comment.update({条件},{$inc:{自增的字段:步进值}})
删除数据:db.comment.remove({条件})
统计查询:db.comment.count({条件})
模糊查询:db.comment.find({字段名:/正则表达式/})
条件比较运算:db.comment.find({字段名:{$gt:值}})
包含查询:db.comment.find({字段名:{$in:[值1,值2]}})或db.comment.find({字段名:{$nin:[值1,值2]}})
条件连接查询:db.comment.find({$and:[{条件1},{条件2}]})或db.comment.find({$or:[{条件1},{条件2}]})
4 索引-Index
4.1 概述
索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
如果查询存在适当的索引,MongoDB可以使用该索引限制必须检查的文档数。
索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序结果。
官网文档:https://docs.mongodb.com/manual/indexes/
了解:
MongoDB索引使用B树数据结构(确切的说是B-Tree,MySQL是B+Tree)
4.2 索引的类型
4.2.1 单字段索引
MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,称为单字段索引(Single Field Index)。
对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以在任何方向上遍历索引。

4.2.2 复合索引
MongoDB还支持多个字段的用户定义索引,即复合索引(Compound Index)。
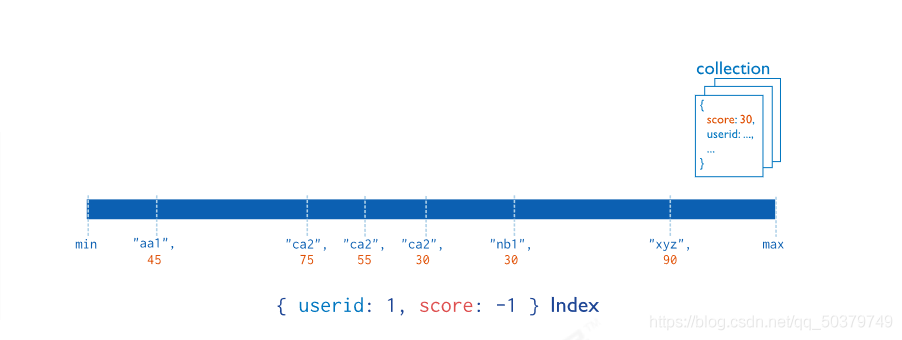
复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由 { userid: 1, score: -1 } 组成,则索引首先按userid正序排序,然后在每个userid的值内,再在按score倒序排序。
4.2.3 其他索引
地理空间索引(Geospatial Index)、文本索引(Text Indexes)、哈希索引(Hashed Indexes)。
地理空间索引(Geospatial Index)
为了支持对地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引:返回结果时使用平面几何的二维索引和返回结果时使用球面几何的二维球面索引。
文本索引(Text Indexes)
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停止词(例如“the”、“a”、“or”),而将集合中的词作为词干,只存储根词。
哈希索引(Hashed Indexes)
为了支持基于散列的分片,MongoDB提供了散列索引类型,它对字段值的散列进行索引。这些索引在其范围内的值分布更加随机,但只支持相等匹配,不支持基于范围的查询。
4.3 索引的管理操作
4.3.1 索引的查看
说明:
返回一个集合中的所有索引的数组。
语法:
db.collection.getIndexes()
提示:该语法命令运行要求是MongoDB 3.0+
【示例】
查看comment集合中所有的索引情况
db.comment.getIndexes()
结果:
db.comment.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "articledb.comment"
}
]
结果中显示的是默认 _id 索引。
默认_id索引:
MongoDB在创建集合的过程中,在 _id 字段上创建一个唯一的索引,默认名字为 id ,该索引可防止客户端插入两个具有相同值的文档,您不能在_id字段上删除此索引。
注意:该索引是唯一索引,因此值不能重复,即 _id 值不能重复的。在分片集群中,通常使用 _id 作为片键。
4.3.2 索引的创建
说明:
在集合上创建索引。
语法:
db.collection.createIndex(keys, options)
参数:
| Parameter | Type | Description |
|---|---|---|
| keys | document | 包含字段和值对的文档,其中字段是索引键,值描述该字段的索引类型。对于字段上的升序索引,请 指定值1;对于降序索引,请指定值-1。比如:{字段:1或-1} ,其中1 为指定按升序创建索引,如果你 想按降序来创建索引指定为 -1 即可。另外,MongoDB支持几种不同的索引类型,包括文本、地理空 间和哈希索引。 |
| options | document | 可选。包含一组控制索引创建的选项的文档。有关详细信息,请参见选项详情列表。 |
options(更多选项)列表:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。“background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名 称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索 引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
【示例】
(1)单字段索引示例:对 userid 字段建立索引:
db.comment.createIndex({userid:1})
结果:
db.comment.createIndex({userid:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
参数1:按升序创建索引
可以查看一下:
db.comment.getIndexes()
结果:
db.comment.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "articledb.comment"
},
{
"v" : 2,
"key" : {
"userid" : 1
},
"name" : "userid_1",
"ns" : "articledb.comment"
}
]
索引名字为`userid_1
compass查看:

(2)复合索引:对 userid 和 nickname 同时建立复合(Compound)索引:
db.comment.createIndex({userid:1,nickname:-1})
结果:
db.comment.createIndex({userid:1,nickname:-1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}
查看一下索引:
db.comment.getIndexes()

compass中:

4.3.3 索引的移除
说明:可以移除指定的索引,或移除所有索引
一、指定索引的移除
语法:
db.collection.dropIndex(index)
参数:
| Parameter | Type | Description |
|---|---|---|
| index | string or document | 指定要删除的索引。可以通过索引名称或索引规范文档指定索引。若要删除文本索引,请指定 索引名称。 |
【示例】
删除 comment 集合中 userid 字段上的升序索引:
db.comment.dropIndex({userid:1})
结果:
{ "nIndexesWas" : 3, "ok" : 1 }
查看已经删除了。
二、所有索引的移除
语法:
db.collection.dropIndexes()
【示例】
删除 spit 集合中所有索引。
db.comment.dropIndexes()
结果:
db.comment.dropIndexes()
{
"nIndexesWas" : 2,
"msg" : "non-_id indexes dropped for collection",
"ok" : 1
}
提示:_id 的字段的索引是无法删除的,只能删除非 _id 字段的索引。
4.4 索引的使用
4.4.1 执行计划
分析查询性能(Analyze Query Performance)通常使用执行计划(解释计划、Explain Plan)来查看查询的情况,如查询耗费的时间、是否基于索引查询等。
那么,通常,我们想知道,建立的索引是否有效,效果如何,都需要通过执行计划查看。
语法:
db.collection.find(query,options).explain(options)
【示例】
查看根据userid查询数据的情况:
db.comment.find({userid:"1013"}).explain()
结果:
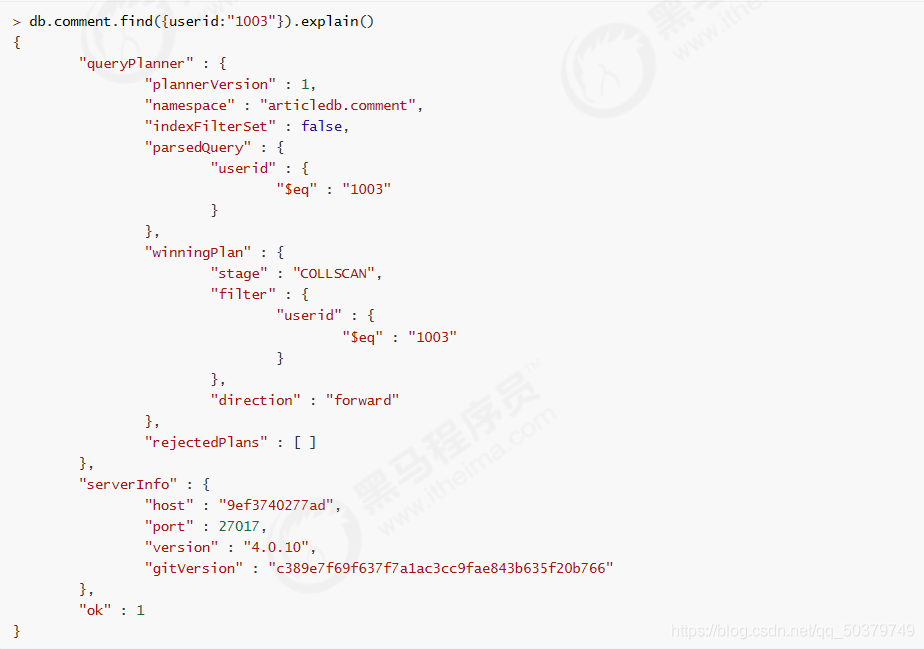
关键点看:“stage” : “COLLSCAN”, 表示全集合扫描
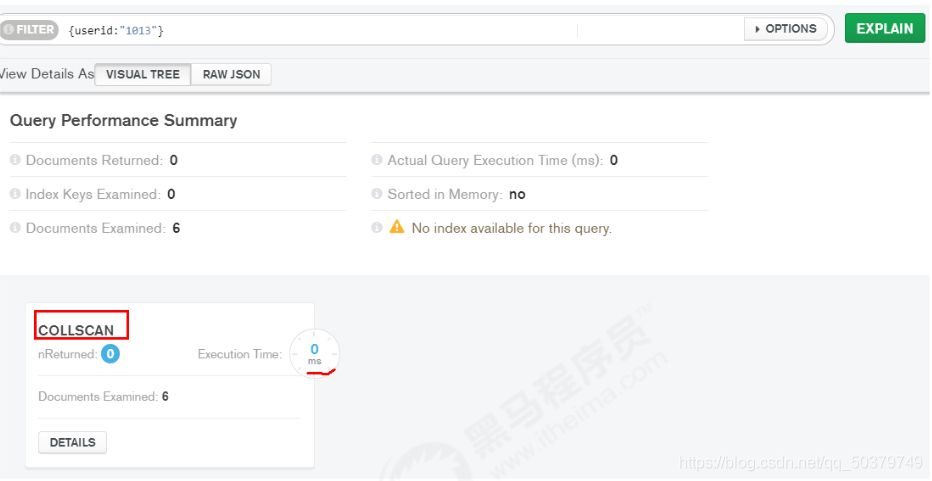
下面对userid建立索引
db.comment.createIndex({userid:1})
结果:
db.comment.createIndex({userid:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
再次查看执行计划:
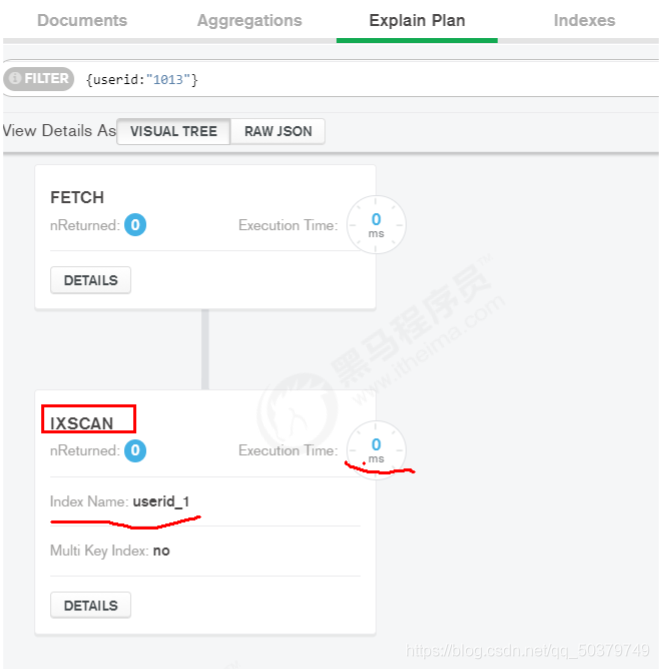
db.comment.find({userid:"1013"}).explain()

关键点看:“stage” : “IXSCAN” ,基于索引的扫描
compass查看:
4.4.2 涵盖的查询
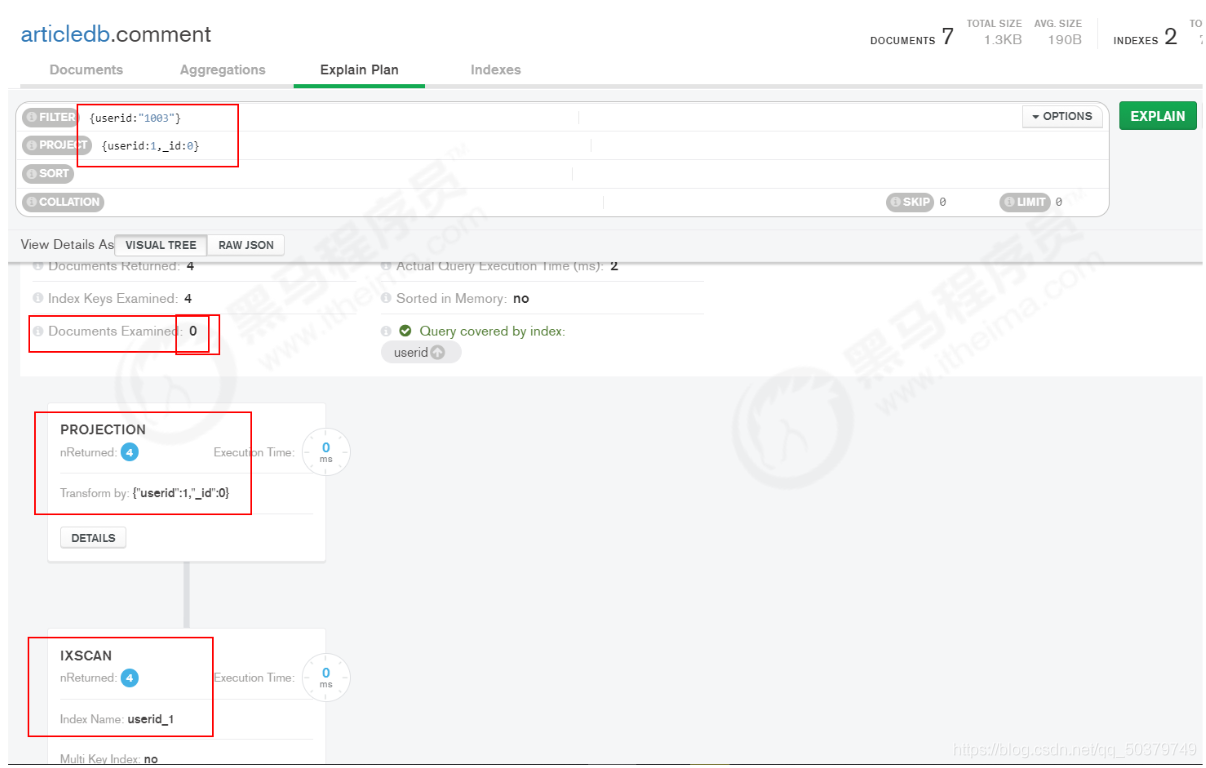
Covered Queries
当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存。这些覆盖的查询可以非常有效。

更多:https://docs.mongodb.com/manual/core/query-optimization/#read-operations-covered-query
【示例】
db.comment.find({userid:"1003"},{userid:1,_id:0})
{ "userid" : "1003" }
{ "userid" : "1003" }
db.comment.find({userid:"1003"},{userid:1,_id:0}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "articledb.comment",
"indexFilterSet" : false,
"parsedQuery" : {
"userid" : {
"$eq" : "1003"
}
},
"winningPlan" : {
"stage" : "PROJECTION",
"transformBy" : {
"userid" : 1,
"_id" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"userid" : 1
},
"indexName" : "userid_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"userid" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"userid" : [
"[\"1003\", \"1003\"]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "bobohost.localdomain",
"port" : 27017,
"version" : "4.0.10",
"gitVersion" : "c389e7f69f637f7a1ac3cc9fae843b635f20b766"},
"ok" : 1
}
Compass中:
5.集群
1.简介
MongoDB 中的副本集(Replica Set)是一组维护相同数据集的 mongod 服务。 副本集可提供冗余和高可用性,是所有生产部署的基础。
也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就是用多台机器进行同一数据的异步同步,从而使多台机器拥有同一数据的多个副本,并且当主库当掉时在不需要用户干预的情况下自动切换其他备份服务器做主库。而且还可以利用副本服务器做只读服务器,实现读写分离,提高负载。
冗余和数据可用性
复制提供冗余并提高数据可用性。 通过在不同数据库服务器上提供多个数据副本,复制可提供一定级别的容错功能,以防止丢失单个数据库服务器。
在某些情况下,复制可以提供增加的读取性能,因为客户端可以将读取操作发送到不同的服务上, 在不同数据中心维护数据副本可以增加分布式应用程序的数据位置和可用性。 还可以为专用目的维护其他副本,例如灾难恢复,报告或备份。
MongoDB 中的复制
副本集是一组维护相同数据集的 mongod 实例。 副本集包含多个数据承载节点和可选的一个仲裁节点。 在承载数据的节点中,一个且仅一个成员被视为主节点,而其他节点被视为次要(从)节点。
主节点接收所有写操作。 副本集只能有一个主要能够确认具有 {w:"most"} 写入关注的写入; 虽然在某些情况下,另一个 mongod 实例可能暂时认为自己也是主要的。主要记录其操作日志中的数据集的所有 更改,即 oplog。
辅助(副本)节点复制主节点的oplog并将操作应用于其数据集,以使辅助节点的数据集反映主节点的数据 集。 如果主要人员不在,则符合条件的中学将举行选举以选出新的主要人员。
主从复制和副本集区别
主从集群和副本集最大的区别就是副本集没有固定的”主节点”;整个集群会选出一个”主节点”,当其挂掉后,又在剩下的从节点中选中其他节点为主节点,副本集总有一个活跃点 (主、primary) 和一个或多个备份节点 (从、secondary)
2 副本集的三个角色
两种类型:
- 主节点(Primary)类型:数据操作的主要连接点,可读写
- 次要(辅助、从)节点(Secondary)类型:数据冗余备份节点,可以读或选举
三种角色:
- 主要成员(Primary):主要接收所有写操作。就是主节点
- 副本成员(Replicate):从主节点通过复制操作以维护相同的数据集,即备份数据,不可写操作,但可以读操作(但需要配置)。是默认的一种从节点类型
- 仲裁者(Arbiter):不保留任何数据的副本,只具有投票选举作用。当然也可以将仲裁服务器维护为副本集的一部分,即副本成员同时也可以是仲裁者。也是一种从节点类型。
关于仲裁者的额外说明:
您可以将额外的 mongod 实例添加到副本集作为仲裁者。 仲裁者不维护数据集。 仲裁者的目的是通过响应其他副本集成员的心跳和选举请求来维护副本集中的仲裁。 因为它们不存储数据集,所以仲裁器可以是提供副本集仲裁功能的好方法,其资源成本比具有数据集的全功能副本集成员更便宜。
如果您的副本集具有偶数个成员,请添加仲裁者以获得主要选举中的大多数投票。 仲裁者不需要专用 硬件。
仲裁者将永远是仲裁者,而主要人员可能会退出并成为次要人员,而次要人员可能成为选举期间的主要人员。
如果你的副本+主节点的个数是偶数,建议加一个仲裁者,形成奇数,容易满足大多数的投票。
如果你的副本+主节点的个数是奇数,可以不加仲裁者。
说人话就是 Paxos 协议算法, 建议阅读
搭建副本集
一主一从一仲裁
下载文件
将下载好的文件解压并改名
tar -zxvf mongodb-linux-x86_64-4.0.10.tgz -C /opt/module
mv mongodb-linux-x86_64-4.0.10 mongodb
主节点
建立存放数据和日志的目录
mkdir -p /opt/module/mongodb/data
mkdir -p /opt/module/mongodb/log
新建配置文件
vi /opt/module/mongodb/mongod.conf
配置文件内容如下:
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: "/opt/module/mongodb/log/mongod.log"
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。
logAppend: true
storage:
#mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。
dbPath: "/opt/module/mongodb/data"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式
fork: true
#指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID
pidFilePath: "/opt/module/mongodb/log/mongod.pid"
net:
#服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip
#bindIpAll:true
#服务实例绑定的IP
bindIp: 192.168.137.5
#bindIp
#绑定的端口
port: 27017
replication:
#副本集的名称
replSetName: mongodb-cluster
注:注意修改路径和ip,副本集名字要相同
从节点
参考主节点,注意修改路径和ip,副本集名字要相同
启动节点
/opt/module/mongodb/bin/mongod -f /opt/module/mongodb/mongod.conf
使用我们配置的配置文件启动
连接节点
选择一个服务连接启动
/opt/module/mongodb/bin/mongo --host=192.168.137.5 --port=27017
建议带上ip和端口
连入后初始化副本
rs.initiate() #可加参数configuration
初始化之后按一下回车变为secondary,再按一下回车变为primary
rs.conf()和rs.status()来查看相应的信息
添加副本从节点
在主节点添加从节点,将其他成员加入到副本集中
rs.add(host,arbiterOnly)
arbiterOnly是可选的。仅在值为字符串时适用。如果为true,则添加的主机是仲裁者。
通常情况下,添加副本从节点:
rs.add("192.168.137.6:27017")
添加仲裁节点
rs.add(host,arbiterOnly)
或
rs.addArb(host)
通常情况下,添加仲裁节点:
rs.addArb("192.168.137.6:27017")
副本读写操作:
登陆主节点27017,写入和读取数据:
/opt/module/mongodb/bin/mongo --host=192.168.137.5 --port=27017
创建数据库
use test
插入数据
db.comment.insert({"articleid":"100000","content":"今天天气真好,阳光明媚","userid":"1001","nickname":"Aoi","createdatetime":new Date()})
查看数据
db.comment.find()
登陆从节点:
/opt/module/mongodb/bin/mongo --host=192.168.137.6 --port=27017
此时如果进行操作,例如
show dbs
会报错
要先将当前节点变为从节点
rs.slaveOk()
或
rs.slaveOk(true)
如果要取消从节点
rs.slaveOk(false)
仲裁者节点
该节点不存放任何数据信息,只用于查看配置信息
主节点的选举原则
MongoDB在副本集中,会自动进行主节点的选举,主节点选举的触发条件:
- 主节点故障
- 主节点网络不可达(默认心跳信息为10秒)
- 人工干预(rs.stepDown(600))
一旦触发选举,就要根据一定的规则来选主节点
选举规则是根据票数来决定谁获胜:
- 票数最高,且获得了"大多数"成员的投票支持的节点获胜
"大多数"的定义为:假设复制集内投票成员数量为N,则大多数为N/2+1。例如:3个投票成员,则大多数的值是2.当复制集内存活的数量不足大多数时,整个复制集将无法选举出Primary,复制集将无法提供写服务,处于只读状态。
- 若票数相同,且都获得了"大多数"成员的投票支持的,数据新的节点获胜。
数据的新旧是通过操作日志oplog来对比的。
6.docker下部署mongodb
1.下载镜像
docker pull mongo
2.启动三个节点
没那么多服务器,只有一个虚拟机,用端口区分
docker run --name m0 -p 37017:27017 -d mongo --replSet "rs"
docker run --name m1 -p 47017:27017 -d mongo --replSet "rs"
docker run --name m2 -p 57017:27017 -d mongo --replSet "rs"
可用docker ps 查看
3.连接任意一个节点,进行副本集配置
进入其中一个容器
docker exec -it 你自己的容器id /bin/bash
连接三个节点中的任意一个,注意ip地址为宿主机ip,我当前的为192.168.137.4
mongo --host 192.168.137.4 --port 37017
此时已连接到m0节点,进行副本集配置
var config={
_id:"rs",
members:[
{_id:0,host:"192.168.137.4:37017"},
{_id:1,host:"192.168.137.4:47017"},
{_id:2,host:"192.168.137.4:57017"}
]};
rs.initiate(config)
响应应该类似下面,注意此时命令提示符已经发生变化,由原来的 > 变成了 rs:SECONDARY>
{
"ok" : 1,
"operationTime" : Timestamp(1522810920, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1522810920, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
然后可用rs.conf()命令查看配置信息,或者rs.status()查看状态。这种建立后是1主两副。为什么没有仲裁节点呢。因为我不会弄,连这一段都是借鉴https://www.cnblogs.com/cowboys/p/9264494.html这里的。
但是1主2副为奇数也勉强凑合
但是可以移除一个副本,再添加一个仲裁
7.SpringDataMongoDB连接副本集
语法:
mongodb://host1,host2,host3/?connect=replicaSet&slaveOk=true&replicaSet=副本集名字
其中:
- slaveOk=true:开启副本节点读的功能,可实现读写分离。
- connect=replicaSet:自动到副本集中选择读写的主机。如果slaveOk是打开的,则实现读写分离。
示例:
连接replica set三台服务器,直接连接第一个服务器,无论是replica set一部分或者主服务器或者从服务器,写入操作应用在主服务器并且分布查询到从服务器。
spring:
#数据源配置
data:
mongodb:
#主机地址
#host: 192.168.137.5
#数据库
#database: test
#默认端口号是27017
#port: 27017
#也可以使用url连接
#url:mongodb://localhost:27017/test
#也可以使用uri连接
uri:mongodb://192.168.137.5:27017,192.168.137.6:27017,192.168.137.7:27017/test?connect=replicaSet&slaveOk=true&replicaSet=mongodb-cluster
8.mongodb相关问题
1.什么是MongoDB
MongoDB是一个文档数据库,提供好的性能,领先的非关系型数据库。采用BSON存储文档数据。
BSON()是一种类json的一种二进制形式的存储格式,简称Binary JSON.
相对于json多了date类型和二进制数组。
2.MongoDB的优势有哪些
- 面向文档的存储:以 JSON 格式的文档保存数据。
- 任何属性都可以建立索引。
- 复制以及高可扩展性。
- 自动分片。
- 丰富的查询功能。
- 快速的即时更新。
3.什么是非关系型数据库
非关系型数据库的显著特点是不使用SQL作为查询语言,数据存储不需要特定的表格模式。
4.为什么用MOngoDB?
- 架构简单
- 没有复杂的连接
- 深度查询能力,MongoDB支持动态查询。
- 容易调试
- 容易扩展
- 不需要转化/映射应用对象到数据库对象
- 使用内部内存作为存储工作区,以便更快的存取数据。
5.在哪些场景使用MongoDB
- 大数据
- 内容管理系统
- 移动端Apps
- 数据管理
6. monogodb 中的分片什么意思
分片是将数据水平切分到不同的物理节点。当应用数据越来越大的时候,数据量也会越来越大。当数据量增长
时,单台机器有可能无法存储数据或可接受的读取写入吞吐量。利用分片技术可以添加更多的机器来应对数据量增加
以及读写操作的要求。
7. MongoDB支持哪些数据类型
- String
- Integer
- Double
- Boolean
- Object
- Object ID
- Arrays
- Min/Max Keys
- Datetime
- Code
- Regular Expression等
8.为什么要在MongoDB中用"Code"数据类型
"Code"类型用于在文档中存储 JavaScript 代码。
9. 为什么要在MongoDB中用"Regular Expression"数据类型
"Regular Expression"类型用于在文档中存储正则表达式
10.为什么在MongoDB中使用"Object ID"数据类型
"ObjectID"数据类型用于存储文档id
11."ObjectID"有哪些部分组成
一共有四部分组成:时间戳、客户端ID、客户进程ID、三个字节的增量计数器
12.用什么方法可以格式化输出结果
db.collectionName.find().pretty()
13.什么是聚合
聚合操作能够处理数据记录并返回计算结果。聚合操作能将多个文档中的值组合起来,对成组数据执行各种操作,返回单一的结果。它相当于 SQL 中的 count(*) 组合 group by。对于 MongoDB 中的聚合操作,应该使用aggregate()方法。
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
14.在MongoDB中什么是副本集(避免单点故障)
在MongoDB中副本集由一组MongoDB实例组成,包括一个主节点多个次节点,MongoDB客户端的所有数据都
写入主节点(Primary),副节点从主节点同步写入数据,以保持所有复制集内存储相同的数据,提高数据可用性。
15.什么是NoSQL数据库?NoSQL和RDBMS有什么区别?在哪些情况下使用和不使用NoSQL数据库?
NoSQL是非关系型数据库,NoSQL = Not Only SQL。
关系型数据库采用的结构化的数据,NoSQL采用的是键值对的方式存储数据。
在处理非结构化/半结构化的大数据时;在水平方向上进行扩展时;随时应对动态增加的数据项时可以优先考虑
使用NoSQL数据库。
在考虑数据库的成熟度;支持;分析和商业智能;管理及专业性等问题时,应优先考虑关系型数据库。
16.MongoDB支持存储过程吗?如果支持的话,怎么用?
MongoDB支持存储过程,它是javascript写的,保存在db.system.js表中。
17.如何理解MongoDB中的GridFS机制,MongoDB为何使用GridFS来存储文件?
GridFS是一种将大型文件存储在MongoDB中的文件规范。使用GridFS可以将大文件分隔成多个小文档存放,这样我们能够有效的保存大文档,而且解决了BSON对象有限制的问题。
18.为什么MongoDB的数据文件很大?
MongoDB采用的预分配空间的方式来防止文件碎片。
19.当更新一个正在被迁移的块(Chunk)上的文档时会发生什么?
更新操作会立即发生在旧的块(Chunk)上,然后更改才会在所有权转移前复制到新的分片上。
20.MongoDB在A:{B,C}上建立索引,查询A:{B,C}和A:{C,B}都会使用索引吗?
不会,只会在A:{B,C}上使用索引。
21. mongodb成为最好nosql数据库的原因是什么?
面向文件的 高性能 高可用性 易扩展性 丰富的查询语言
22. 如果用户移除对象的属性,该属性是否从存储层中删除?
是的,用户移除属性然后对象会重新保存(re-save()).
23.允许空值null吗?
对于对象成员而言,是的.然而用户不能够添加空值(null)到数据库丛集(collection)因为空值不是对象.然而用户能够添加空对象{}.
24. 更新操作立刻fsync到磁盘?
不会,磁盘写操作默认是延迟执行的.写操作可能在两三秒(默认在60秒内)后到达磁盘.例如,如果一秒内数据库收到一千个对一个对象递增的操作,仅刷新磁盘一次.
25.如何执行事务/加锁?
mongodb没有使用传统的锁或者复杂的带回滚的事务,因为它设计的宗旨是轻量,快速以及可预计的高性能.可以把它类比成mysql mylsam的自动提交模式.通过精简对事务的支持,性能得到了提升,特别是在一个可能会穿过多个服务器的系统里.
26.启用备份故障恢复需要多久?
从备份数据库声明主数据库宕机到选出一个备份数据库作为新的主数据库将花费10到30秒时间.这期间在主数据库上的操作将会失败–包括写入和强一致性读取(strong consistent read)操作.然而,你还能在第二数据库上执行最终一致性查询(eventually consistent query)(在slaveok模式下),即使在这段时间里.
27.数据在什么时候才会扩展到多个分片(shard)里?
mongodb 分片是基于区域(range)的.所以一个集合(collection)中的所有的对象都被存放到一个块(chunk)中.只有当存在多余一个块的时候,才会有多个分片获取数据的选项.现在,每个默认块的大小是 64mb,所以你需要至少 64 mb 空间才可以实施一个迁移.
28.数据在什么时候才会扩展到多个分片(shard)里?
mongodb 分片是基于区域(range)的.所以一个集合(collection)中的所有的对象都被存放到一个块(chunk)中.只有当存在多余一个块的时候,才会有多个分片获取数据的选项.现在,每个默认块的大小是 64mb,所以你需要至少 64 mb 空间才可以实施一个迁移.
29. 当我试图更新一个正在被迁移的块(chunk)上的文档时会发生什么?
更新操作会立即发生在旧的分片(shard)上,然后更改才会在所有权转移(ownership transfers)前复制到新的分片上.
30.mongodb是否支持事务
MongoDB 4.0的新特性——事务(Transactions):MongoDB 是不支持事务的,因此开发者在需要用到事务的时候,不得不借用其他工具,在业务代码层面去弥补数据库的不足。
事务和会话(Sessions)关联,一个会话同一时刻只能开启一个事务操作,当一个会话断开,这个会话中的事务也会结束。