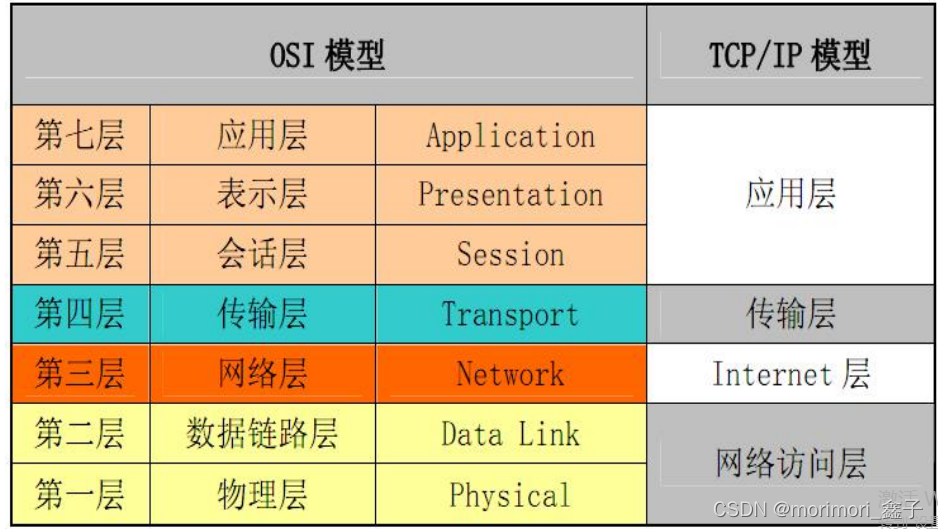
TCP/IP四层协议模型

HTTP协议

HTTP协议的特性
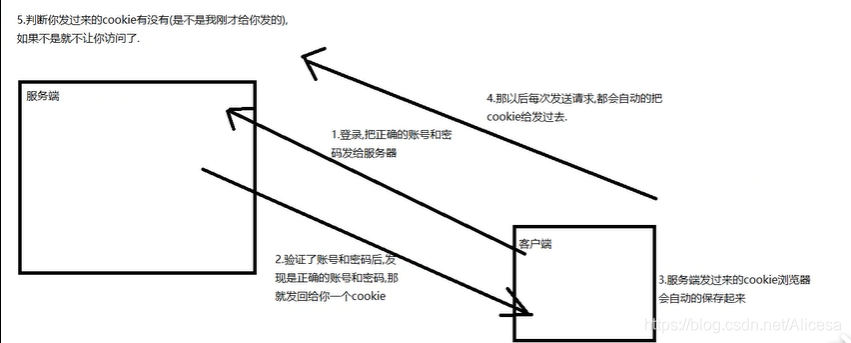
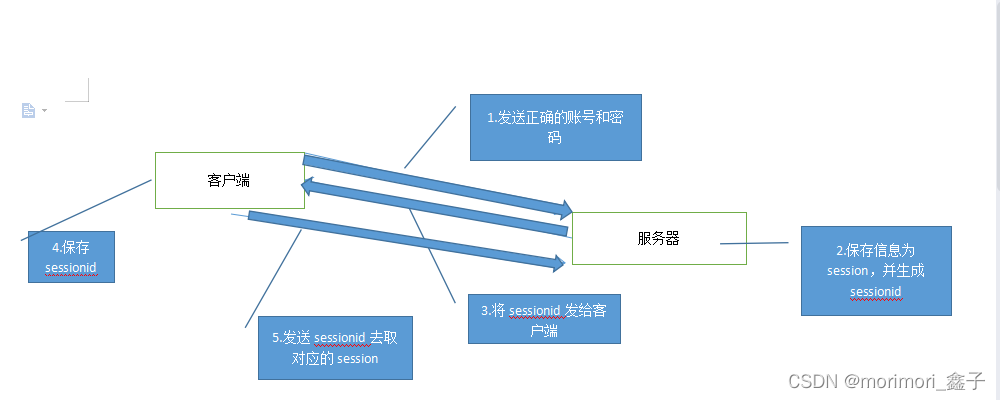

挥手:

HTTPS和HTTP的区别?
https就是http协议+ssl协议。https是安全的,http是不安全的。
http的默认端口号:80,https的默认端口号是443
请求头里面需要关注的点:
(1)URL地址:通过抓包直接看
(2)content-type:传递请求格式

响应码:301表示永久重定向,302暂时重定向。
如何去写接口测试用例?
从正向和反向以及业务逻辑上去考虑。
正向:填写正确的参数组合 p0
反向:功能异常(数据错误(非类型和长度错误),补充--已删除的用户名,登录失败);数据异常(传入参数为空,数据类型错误,数据长度错误);参数异常(多了参数,少了参数,没有参数)
业务逻辑:多个接口的组合的执行顺序,以及接口的依赖。
接口测试用例的编写包含的要素:
编号(ID),测试模块,用例名称(标题,预期结果(输入内容组合),如:登陆成功(用户名和密码正确)),前置条件(依赖接口),请求url,请求类型(post、get),请求头{字典格式},请求参数{字典格式},预期响应状态码,预期返回数据{响应体},优先级
接口测试代码撰写:
get请求传参方式:1.发送不带参数的get请求
# 发送不带参数的get请求
def func1():
resp = requests.get('http://www.fanyunedu.com/mms/login.html')
resp.encoding = 'utf8'
print(resp.text)def func2():
resp = requests.get('http://www.tencent.com:5000/general/search?kw=健力宝')
print(resp.text)
params1 = {
'kw': 'bmw'
}
resp = requests.get('http://www.tencent.com:5000/general/search', params=params1)
print(resp.text)
post请求传参,需要关注请求头里面的content-type这个字段:
都以字典的格式组装;但是在自动化中传参后,报文会自动变为&连接,如username=wang&password=123456,这种格式,而json格式传参后,依旧保持字典格式。
def func3():
data = { # 参数组装的字典
'username': 'admin',
'password': 'admin'
}
resp = requests.post('http://www.tencent.com/mms/Login/loginUser', data=data)
print(resp.text) data = {
'username': 'class94',
'password': '123456',
'age': 1,
'phone': '15888888888'
}
resp = requests.post('http://www.tencent.com:5000/general/register_json', json=data)
print(resp.text)3.multipart/form-data,通常是用来上传文件,下面有上传file的代码介绍。
def func4():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36'
}
resp = requests.get('http://www.tencent.com:5000/', headers=headers)
print(resp.text)def func5():
headers = {
'Cookie': 'JSESSIONID=DD86F5991F9C6EFE19664D78B9FF9E02'
}
resp = requests.get('http://www.tencent.com/mms/Login/GetLoginName',headers=headers)
print(resp.text)def func6():
sess = requests.Session() # 创建一个session,用于在代码中保持会话状态
data = {
'username': 'admin',
'password': 'admin123'
}
sess.post('http://www.tencent.com/mms/Login/loginUser', data=data)
resp = sess.get('http://www.tencent.com/mms/Login/GetLoginName')
print(resp.text)上传文件---只有文件参数(记得带open,rb---二进制)
def func7():
files = {
'file': open(r'demo.txt', 'rb')
}
resp = requests.post('http://www.tencent.com:5000/general/api/upload', files=files)
print(resp.text)上传文件--除了有文件参数外,还有其它参数(文件参数和其他参数都要传)。上传文件只能用post,下载文件只能用get。
def func8():
# 先构造普通参数
data = {
'batchname': 'GB20220322'
}
# 构造文件参数
files = {
'batchfile': open(r'demo.txt', 'rb')
}
resp = requests.post('http://taobao/goods/upload', data=data, files=files)
print(resp.text)
下载普通文件-- 和python中文件读写类似(只能用get),将响应的text写入新建的文件中
def func9():
resp = requests.get('http://www.taobao.com:5000/general/api/download?file=1647914731.txt')
# 下载普通的文本文件
with open('result.txt', 'w') as f:
f.write(resp.text)下载图片--响应体的内容格式是content,(通常的响应体的内容格式是text和html)
def func9():
resp = requests.get('http://taobao/lancome/image/logo.png')
with open('lancome.png', 'wb') as f:
f.write(resp.content) # 不能使用resp.textimport hashlib
def func10():
uid, name, password, salt = '4', 'admin', 'admin123', 'taue19BJIOz9n6W8'
m = hashlib.md5()
m.update(('{}-{}-{}-{}'.format(uid, name, password, salt)).encode('utf8'))
sign = m.hexdigest()
#完成加盐值加密,下面正常传请求参数就行
data = {
'uid': '4',
'sign': sign
}
resp = requests.post('http://www.tencent.com:5000/general/userinfo_sign', json=data)
print(resp.text)lxml库提取html页面源码的内容
import etree
def func12():
sess = requests.Session() # 创建一个session,用于在代码中保持会话状态
data = {
'username': 'admin',
'password': 'admin123'
}
sess.post('http://www.taobao.com/mms/Login/loginUser', data=data)
resp = sess.get('http://www.taobao.com/mms/mms/index.html')
resp.encoding = 'utf8'
html = etree.HTML(resp.text)
# result = html.xpath("//a[@href='javascript:logOff()']/text()")
result = html.xpath("//a[@href='javascript:logOff()']/@href")
print(result)
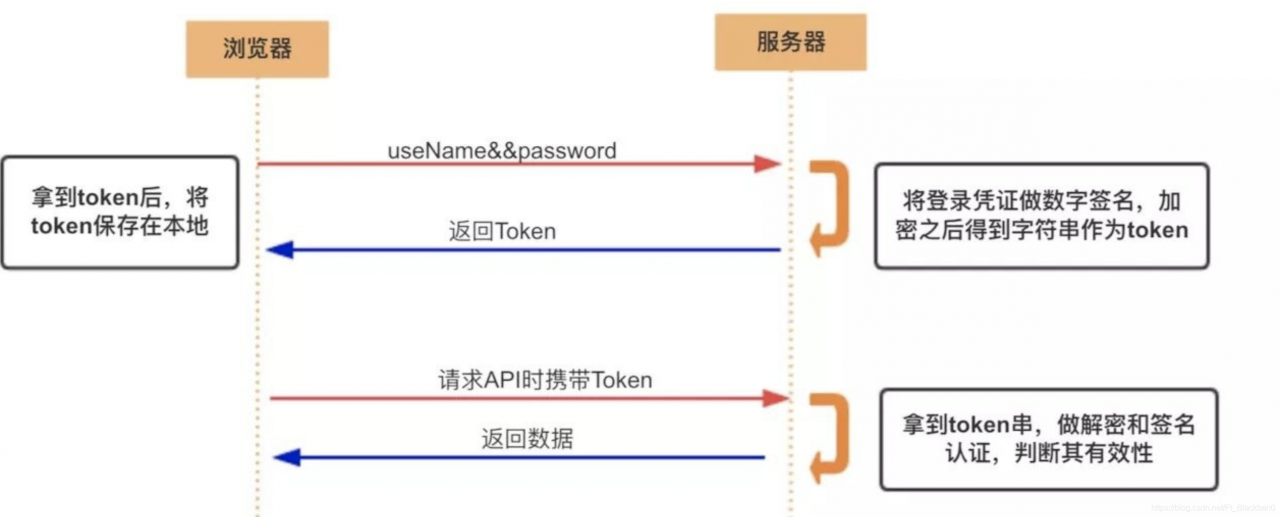
根据响应内容,来获取返回值,再根据返回值获得其他信息。
def func14():
data = {
'username': 'admin',
'password': 'admin123'
}
resp = requests.post('http://www.tencent.com:5000/general/login_token', data=data) #先得到响应结果
resp_json = resp.json() # 只适合于响应对象的值是json的情况,如果返回值不是json,则会报错 #再从响应结果中得到响应的json的内容
token = resp_json['data'] #再从json里获取token
headers = {
'auth-token': token
}
resp = requests.get('http://www.tencent.com:5000/general/userinfo_token', headers=headers) #带上token进入里面的网址,类似于cookie
resp_json = resp.json() #里面的网址的json值
print(resp_json['data']['联系方式']) #获取json里的data中的联系方式
func14()