Redis 本身是一个 Map,其中所有的数据都是采用 key:value 的形式存储
这里的数据类型主要是指存储的,也即是 value 的数据类型,key 的数据类型永远都是 String
redis 中 value 使用的数据结构有:
String:字符串类型List:列表类型Hash:哈希表类型Set:无序集合类型sorted set:有序集合类型
下面我们来一个一个分别来了解一下:
一、String:字符串类型
redis 是使用 C 语言开发,但 C 中并没有 String 类型,只能使用指针或字符数组的形式表示一个字符串,所以 redis 设计了一种简单动态字符串(SDS[Simple Dynamic String])作为底层实现。
这个 SDS 的内部结构更像是一个 ArrayList,内部维护着一个字节数组,并且在其内部预分配了一定的空间,以减少内存的频繁分配。
Redis 的内存分配机制是这样:
当字符串的长度小于 1MB 时,每次扩容都是加倍现有的空间。
如果字符串长度超过 1MB 时,每次扩容时只会扩展 1MB 的空间。
这样既保证了内存空间够用,还不至于造成内存的浪费,字符串最大长度为 512MB。
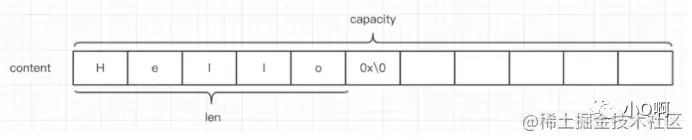
上图就是字符串的基本结构,其中 content 里面保存的是字符串内容,0x\0 作为结束字符不会被计算 len 中。
SDS 的数据结构:

capacity 和 len 两个属性都是泛型,为什么不直接用 int 类型?因为 Redis 内部有很多优化方案,为更合理的使用内存,不同长度的字符串采用不同的数据类型表示,且在创建字符串的时候 len 会和 capacity 一样大,不产生冗余的空间,所以 String 值可以是字符串、数字(整数、浮点数) 或者二进制。
redis 中 SDS 和 C 语言字符串对比:
1)C 语言中的字符串,遇到'\0'则结尾,用长度 N+1 的数组维护长度为 N 的字符串。
Redis 的 SDS 是:
len 表示字符串的长度;
free 表示空闲的,未分配的空间;
buffer 数组是真正的字符串,并且以'\0'结尾。
2)C 字符串并不记录自身的长度信息,获取一个 C 字符串的长度,必须遍历整个字符串,对遇到的字符进行计数,直到遇到代表字符串结尾的空字符为止,复杂度为 O(n)
SDS 在 len 属性中记录了 SDS 的本身长度,复杂度为 O(1)
3)C 字符串不记录自身长度容易造成缓冲区溢出
SDS 的空间分配策略完全杜绝了发生缓冲区的可能性:当 SDS API 需要对 SDS 进行修改时,API 会先检查 SDS 的空间是否满足修改所需的要求,如果不满足的话,API 会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出问题
4)减少修改字符串时带来的内存重分配次数
C 字符串的长度和底层数组的长度之间存在这种关联性,所以每次增长或者缩短一个 C 字符串,总要对保存 C 字符串的数组进行一次内存重分配操作
在 SDS 中,buf 数组的长度不一定就是字符数量加一,数组里面可以包含为使用的字节,而这些字节的数量就由 SDS 的 free 属性记录。通过未使用空间,SDS 实现了空间预分配和惰性空间释放两种优化策略
5)二级制安全
C 字符串必须符合某种编码,并且除了字符串的末尾之外,字符串里面不能包含空字符
SDS 的 API 都是二进制安全的,所有 SDS API 都会以处理二进制的方式来处理 SDS 存放在 buf 数组里的数据
6)C 兼容所有字符串函数
SDS 兼容部分 C 字符串函数

String 类型的应用
1、可以存储 base64 的图片数据
2、作为缓存功能,降低 mysql 数据库的请求
3、做一些短时间的错误限制控制
二、List:列表类型
Redis 中的 list 本质是链表结构
list 的实现在 3.2 版本之前有两种方式:
压缩列表 ziplist
双向链表 linkedlist
在 3.2 版本之后引入了:
快速列表 quicklist
因为双向链表 linkedlist 占用的内存比压缩列表 ziplist 要多, 所以当创建新的列表键时,列表会优先考虑使用压缩列表 ziplist, 并且在有需要的时候, 才从压缩列表 ziplist 实现转换到双向链表 linkedlist 实现。
而后续引入的 quicklist 可以看作是 linkedlist 和 ziplist 的结合体。
这三种列表内部使用哪一种类型是通过编码来区分的:
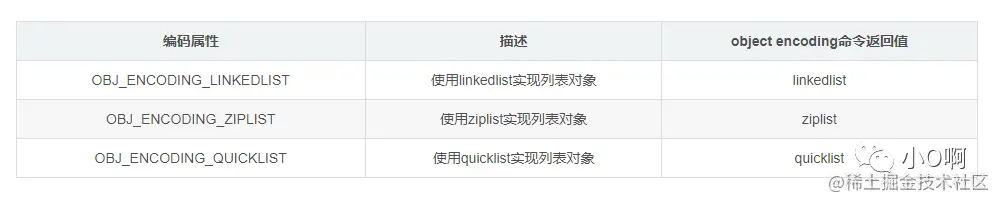
linkedlist
linkedlist 是一个双向列表,每个节点都会存储指向上一个节点和指向下一个节点的指针。linkedlist 因为每个节点的空间是不连续的,所以可能会造成过多的空间碎片。
linkedlist 的存储结构,链表中每一个节点都是一个 listNode 对象(源码 adlist.h 内),不过需要注意的是,列表中的 value 其实也是一个字符串对象。

然后会将其再进行封装成为一个 list 对象(源码 adlist.h 内):

Redis 中对 linkedlist 的访问是以 NULL 值为终点的,因为 head 节点的 prev 节点为 NULL,tail 节点的 next 节点为 NULL。
所以,在 Redis3.2 之前我们可以得到如下简图:
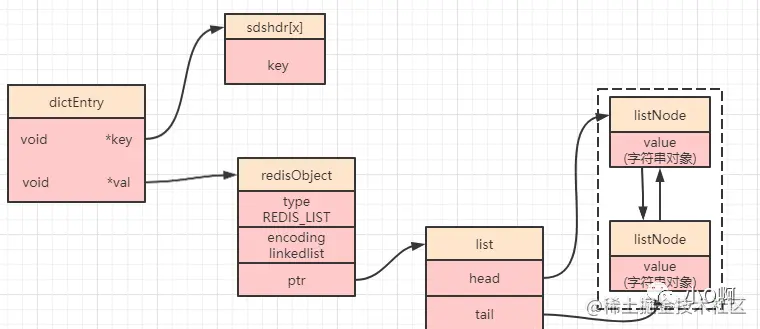
ziplist
ziplist 是为了节省内存而开发的一种压缩列表数据结构,哈希数据类型底层也用到了 ziplist。
ziplist 是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个 ziplist 可以包含任意多个 entry,而每一个 entry 又可以保存一个字节数组或者一个整数值。
ziplist 和 linkedlist 最大的区别是 ziplist 不存储指向上一个节点和下一个节点的指针,存储的是上一个节点的长度和当前节点的长度,牺牲了部分读写性能来换取高效的内存利用率,是一种时间换空间的思想。
ziplist 适用于字段个数少和字段值少的场景。
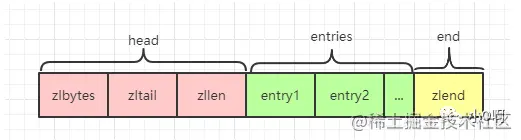
ziplist 的组成结构:
![]()
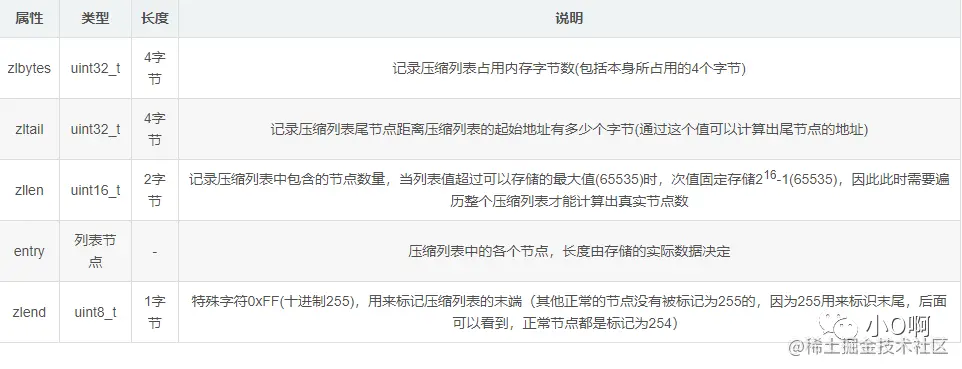
关于列表选择使用 ziplist 编码进行存储,必须满足下面两个条件:
1)列表对象保存的所有字符串元素的长度都小于 64 字节。
2)列表对象保存的元素数量小于 512 个。
一旦不满足这两个条件中的任意一个,则会使用 linkedlist 编码来进行存储
这两个条件可以通过参数 list-max-ziplist-value 和 list-max-ziplist-entries 进行修改重新设定
quicklist
在 Redis3.2 之后,统一用 quicklist 来存储列表对象,quicklist 存储了一个双向列表,每个列表的节点是一个 ziplist,所以实际上 quicklist 就是 linkedlist 和 ziplist 的结合。
quicklist 内部存储结构,quicklist 中每一个节点都是一个 quicklistNode 对象,其数据结构定义为:
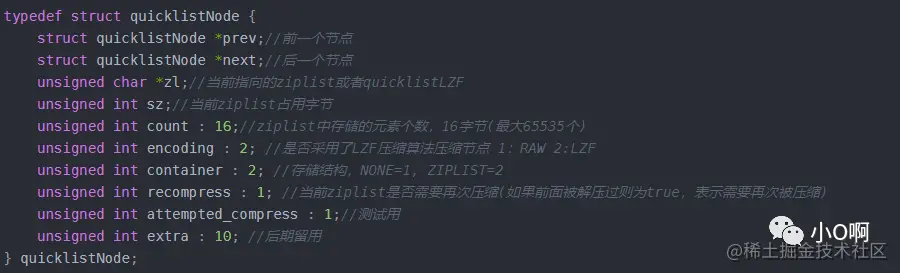
然后各个 quicklistNode 就构成了一个列表,quicklist:

根据上面两个结构图,可以得到 Redis3.2 之后列表的简图:
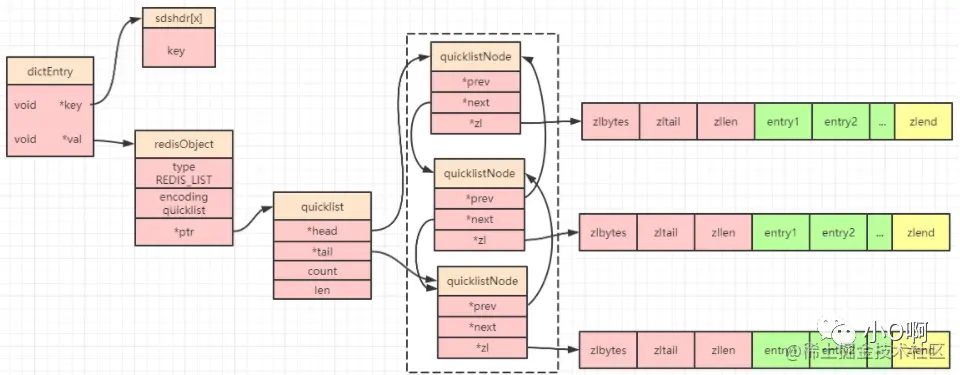
quicklist 和原始两种列表的对比
quicklist 同样采用了 linkedlist 的双端列表特性,然后 quicklist 中的每个节点又是一个 ziplist,所以 quicklist 就是综合平衡考虑了空间碎片和读写性能两个维度。
使用 quicklist 需要注意以下 2 点:
1、如果 ziplist 中的 entry 个数过少,极端情况就是只有 1 个 entry,此时就相当于退化成了一个普通的 linkedlist。
2、如果 ziplist 中的 entry 过多,那么也会导致一次性需要申请的内存空间过大,而且因为 ziplist 本身的就是以时间换空间,所以会过多 entry 也会影响到列表对象的读写性能。
ziplist 中的 entry 个数可以通过参数 list-max-ziplist-size 来控制:
list-max-ziplist-size 1
这个参数可以配置正数也可以配置负数。正数表示限制每个节点中的 entry 数量,如果是负数则只能为-1~-5
-1:每个 ziplist 最多只能为 4KB
-2:每个 ziplist 最多只能为 8KB
-3:每个 ziplist 最多只能为 16KB
-4:每个 ziplist 最多只能为 32KB
-5:每个 ziplist 最多只能为 64KB
Redis Lrange 返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。其中 0 表示列表的第一个元素,1 表示列表的第二个元素,以此类推。也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
List 数据类型应用:
timeline:例如微博的时间轴,有人发布微博,用 lpush 加入时间轴,展示新的列表信息。
三、Hash:哈希表类型
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 2^32 - 1 键值对(40 多亿)
Redis 的哈希对象的底层存储可以使用 ziplist(压缩列表)和 hashtable。
当 hash 对象可以同时满足以下两个条件时,哈希对象使用 ziplist 编码
1.哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节
2.哈希对象保存的键值对数量小于 512 个
常见操作命令:
所有 hash 的命令都是 h 开头的 hget、hset、hdel 等
Hash 数据类型应用:
1、缓存:能直观,相比 string 更节省空间的维护缓存信息,如:用户信息,视频信息等。
四、Set:无序集合类型
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,将一个重复的元素添加到 set 中将会被忽略。
集合对象的编码可以是 intset 或者 hashtable。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储 40 多亿个成员)
集合类型也是用来保存多个字符串的元素,但和列表不同的是,集合中:
不允许有重复的元素
集合中的元素是无序的,不能通过索引下标获取元素
支持集合间的操作,可以取多个集合取交集、并集、差集
Set 数据类型应用:
1、标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人
2、点赞,或点踩,收藏等,可以放到 set 中实现
五、Sorted Set
Redis 的 sorted_set 是有序集合,在 set 的基础上增加 score 属性用来排序
在 redis 中,数据类型对应的命令一般以数据类型的首字母开头,但是单词 s 已经被 string 类型使用了,所以 sorted_set 类型的相关命令只能使用 26 个英文字母中的最后一个字母 z 来开头,所以 sorted_set 也被称为 zset。
有序集合和集合有着必然的联系,保留了集合不能有重复成员的特性,区别是,有序集合中的元素是可以排序的,它给每个元素设置一个分数,作为排序的依据。
(有序集合中的元素不可以重复,但是 score 分数可以重复,就和一个班里的同学学号不能重复,但考试成绩可以相同)。
Sortedset 底层存储结构:
Sortedset 同时会由两种数据结构支持,ziplist 和 skiplist
只有同时满足如下条件时,使用的是 ziplist,其他时候则是使用 skiplist
1)有序集合保存的元素数量小于 128 个
2)有序集合保存的所有元素的长度小于 64 字节
当 ziplist 作为存储结构时候,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个元素保存元素的分值.
当使用 skiplist 作为存储结构时,使用 skiplist 按序保存元素分值,使用 dict 来保存元素和分值的对应关系
关于 skiplist
skiplist 本质上是一个 list, 它其实是由有序链表发展而来
我们先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头节点):

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为 O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

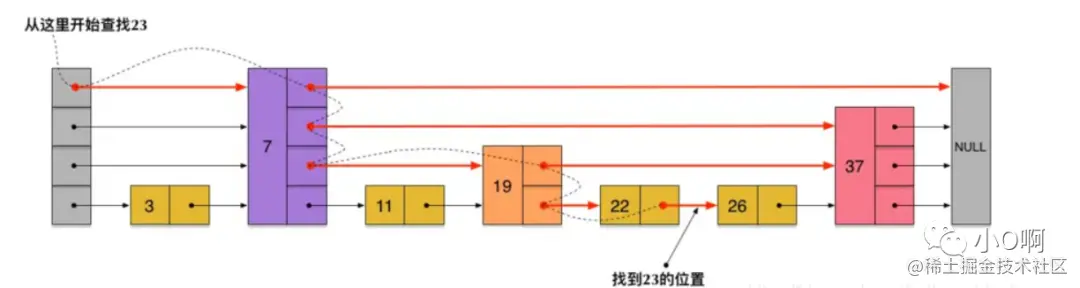
这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是 7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找 23,查找的路径是沿着下图中标红的指针所指向的方向进行的:

1)23 首先和 7 比较,再和 19 比较,比它们都大,继续向后比较,当 23 和 26 比较的时候,比 26 要小,因此回到下面的链表(原链表),与 22 比较
2)23 比 22 要大,沿下面的指针继续向后和 26 比较
3)23 比 26 小,说明待查数据 23 在原链表中不存在,而且它的插入位置应该在 22 和 26 之间
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找 23,那么沿着最上层链表首先要比较的是 19,发现 23 比 19 大,接下来我们就知道只需要到 19 的后面去继续查找,从而一下子跳过了 19 前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度
skiplist 正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到 O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的 2:1 的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新退化成 O(n),删除数据也有同样的问题。
skiplist 为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是 3,那么就把它链入到第 1 层到第 3 层这三层链表中。为了表达清楚,下图展示了如何通过一步步地插入操作从而形成一个 skiplist 的过程:
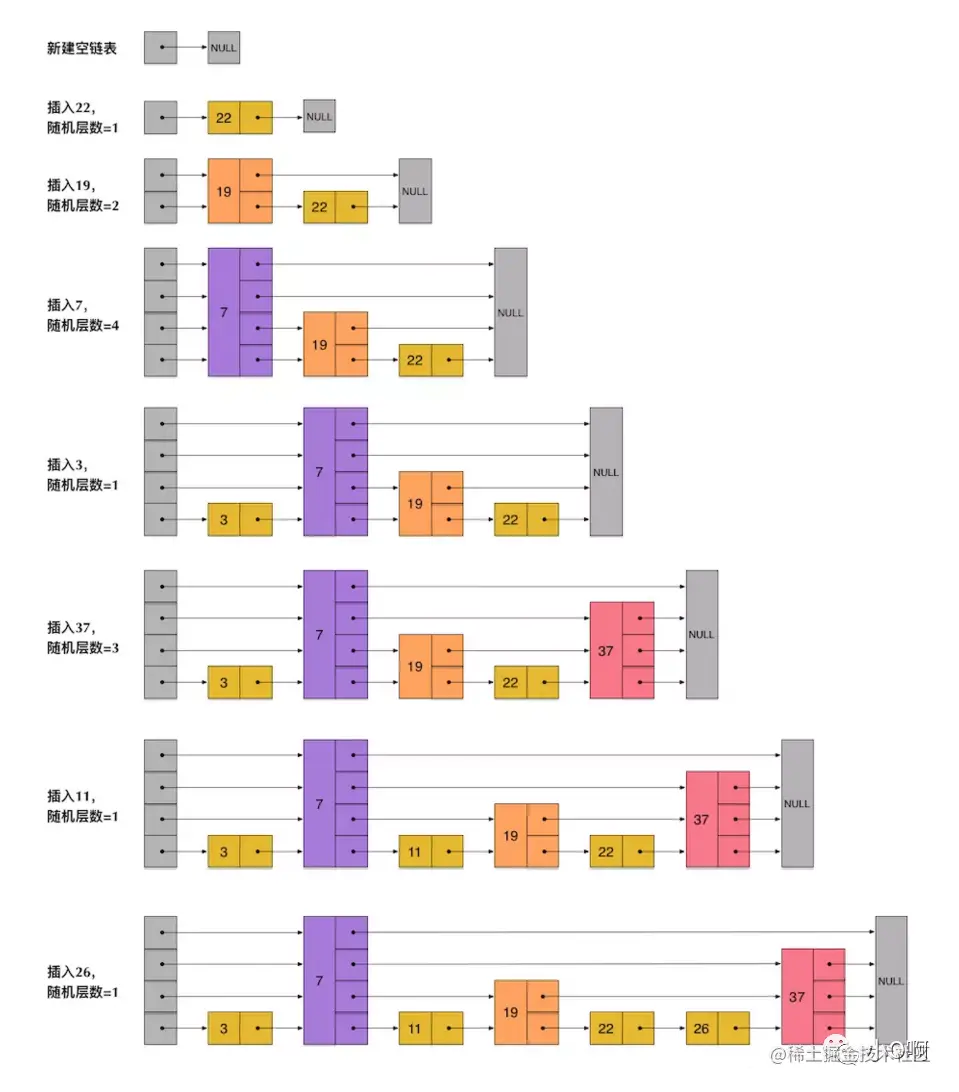
从上面 skiplist 的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是 skiplist 的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。
根据上图中的 skiplist 结构,我们很容易理解这种数据结构的名字的由来。skiplist,翻译成中文,可以翻译成“跳表”或“跳跃表”,指的就是除了最下面第 1 层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第 1 层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
刚刚创建的这个 skiplist 总共包含 4 层链表,现在假设我们在它里面依然查找 23,下图给出了查找路径:
需要注意的是,前面演示的各个节点的插入过程,实际上在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
至此,skiplist 的查找和插入操作,我们已经很清楚了。而删除操作与插入操作类似,我们也很容易想象出来。这些操作我们也应该能很容易地用代码实现出来。
当然,实际应用中的 skiplist 每个节点应该包含 key 和 value 两部分。前面的描述中我们没有具体区分 key 和 value,但实际上列表中是按照 key 进行排序的,查找过程也是根据 key 在比较。
zset 数据类型应用:
1、排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行
小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。

原文出处:xie.infoq.cn/article/95d49f0bf9ef2b9839bba58ab