1.虚拟机准备
环境:ubuntu 16.04
准备两个虚拟机
一个作为 master节点 另一个作为node节点
我这两个 虚拟机的ip分别为
192.168.70.144 做master节点
192.168.70.146 做node节点
2.系统设置(master和node都要执行的)为了操作方便 建议都使用 root 用户
(1). 先禁用swap
swapoff -a
(这个一定要先关掉 如果不禁用 后面在kubeadm初始化或者加入node 的时候 Kubernetes的时候会报错
我在添加node 节点的时候 遇见过这个 问题 于是我就禁用它
当时我 执行 swapoff -a命令 但是 一直执行不成功![]()
后来才发现是因为我虚拟机内存 分的太小了,因为使用的交换文件的数量大于我的内存中所能容纳的数量。
之前分的 1g 后来改成2g 就没问题了
)
使用
free -m
命令查看一下
如果 Swap 都为0 则禁用成功
设置交换分区开机不启动
因为没有注释掉swap的自动挂载,机器重启后,swap还是会自动启用,从而导致kubelet无法启动
修改 /etc/fstab文件
vim /etc/fstab
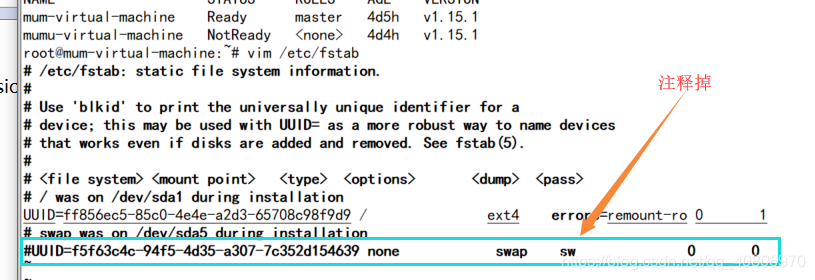
(2).关闭防火墙
ufw disable
如果不是 root用户 请加 sudo
sudo ufw disable
我参看的人家的博文上使用的是这两条命令
systemctl stop firewalld
systemctl disable firewalld
我自己在使用的时候 有问题![]()
用 sudo ufw disable 这个命令 关闭防火墙是可以的
开启防火墙
sudo ufw enable
为什么要关闭防火墙?
如果各个主机启用了防火墙,需要开放Kubernetes各个组件所需要的端
因为Kubernetes的Master和Node之间有大量的网络通信,安全的做法是在防火墙上配置各组件需要相互通信的端口,在安全的网络环境中较为简单的做法是禁用Firewalld防火墙。解决方法是运行systemctl status firewalld 查看Firewalld防火墙状态。如果防火墙没有禁用,就禁用它
(3).禁用Selinux
apt install selinux-utils
setenforce 0
不禁用Selinx 会导致Kubernetes 安装失败
什么是Selinx?
先简单说一下
安全增强型 Linux(Security-Enhanced Linux)简称 SELinux,它是一个 Linux 内核模块,也是 Linux 的一个安全子系统。
SELinux 主要由美国国家安全局开发。2.6 及以上版本的 Linux 内核都已经集成了 SELinux 模块。
SELinux 的结构及配置非常复杂,而且有大量概念性的东西,要学精难度较大。很多 Linux 系统管理员嫌麻烦都把 SELinux 关闭了。
SELinux 的作用
SELinux 主要作用就是最大限度地减小系统中服务进程可访问的资源(最小权限原则)。
详细说明请看:https://blog.csdn.net/yanjun821126/article/details/80828908
(4)在两个节点的 /etc/hosts配置中 分别 加入
192.168.70.144master
192.168.70.146 slave02
这两个是 ip地址 和 虚拟主机名
我在搭的时候 主机名忘了改
下面 mum-virtual-machine 是装的master 节点
mumu-virtual-machine 是装的node 节点
vim /etc/hosts
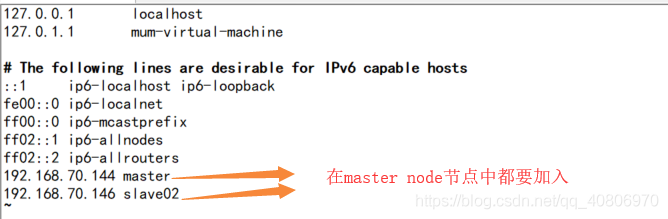 (
(
5) 两个节点中都要安装Docker
步骤:
先安装相关工具
apt-get update && apt-get install -y apt-transport-https curl
添加密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
安装Docker
apt-get install docker.io -y
查看Docker 版本 检验是否安装成功
docker version
(6)启动docker服务
systemctl enable docker
systemctl start docker
使用阿里云 镜像加速,否则拉取对象的时候 会有问题
vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://alzgoonw.mirror.aliyuncs.com"],
"live-restore": true
}
重启docker服务
systemctl daemon-reload
systemctl restart docker
3.安装kubectl,kubelet,kubeadm( master 和 node 节点都执行)
(1)添加密钥
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
国内网络无法访问谷歌,此时会报无法找到OpenPGP的错误。
(https://packages.cloud.google.com/apt/doc/apt-key.gpg)只要能访问谷歌都可以 可以在chrome装谷歌访问助手插件
我已经上传百度云了 有需要的可以通过 我的分享链接下载
链接: https://pan.baidu.com/s/1fE29UeatJkkbeG1iHcnmFg 提取码: 2cdu 复制这段内容后打开百度网盘手机App,操作更方便哦
把 apt-key.gpg文件上传到 ubuntu上之后
打开这个文件上传后所在的目录
使用 apt-key add apt-key.gpg 这个命令 添加密钥
(2)添加Kubernetes软件源
官方的源(如果无法科学上网,添加此源是没有办法安装kubectl、kubeadm、kubectl的):
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
国内的源(此源可以使用,本次搭建使用的是此源):
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main
EOF
安装:
apt-get update && apt-get install -y kubelet kubeadm kubectl
systemctl enable kubelet
注:安装成功后不要执行systemctl start kubelet,执行是会报错的,直接向下执行就可以了
4.配置Master(只用在Master下执行)
(1)在master节点 /etc/profile 下面增加如下环境变量
export KUBECONFIG=/etc/kubernetes/admin.conf
# 重起kubelet
systemctl daemon-reload
systemctl restart kubelet
2)在master节点上执行
这个是我参考的别人的那个博文 执行的
初始化命令
kubeadm init --kubernetes-version=v1.14.1 --pod-network-cidr 10.244.0.0/16
实际上在我执行这条命令的时候 出错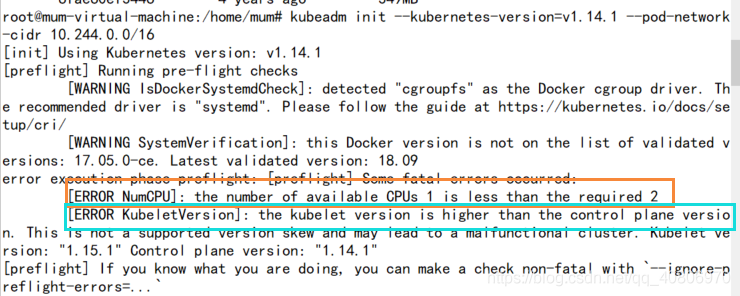 第一个ERROR解决
第一个ERROR解决
加入一个参数 --ignore-preflight-errors=NumCPU 忽略报错
第二个ERROR 解决
把 1.14.1 改成1.15.1
如果出现
可以 添加 ignore-preflight-errors=Swap 这个参数 忽略这个错误
最后执行的初始化命令为
kubeadm init --kubernetes-version=v1.15.1 --pod-network-cidr 10.244.0.0/16 --ignore-preflight-errors=NumCPU
–pod-network-cidr 指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 --pod-network-cidr 有自己的要求,这里设置为 10.244.0.0/16 是因为我们将使用 flannel 网络方案
–kubernetes-version 指定要安装的版本号是1.15.1
但是 执行 这条命令之后会报错 原因是 被k8s.gcr.io 被墙了 无法拉取镜像 拉取镜像失败
执行
kubeadm config images list
查看所需的镜像的版本
(我之前 忘了截图 只是用手机拍了一下 凑合着看吧)
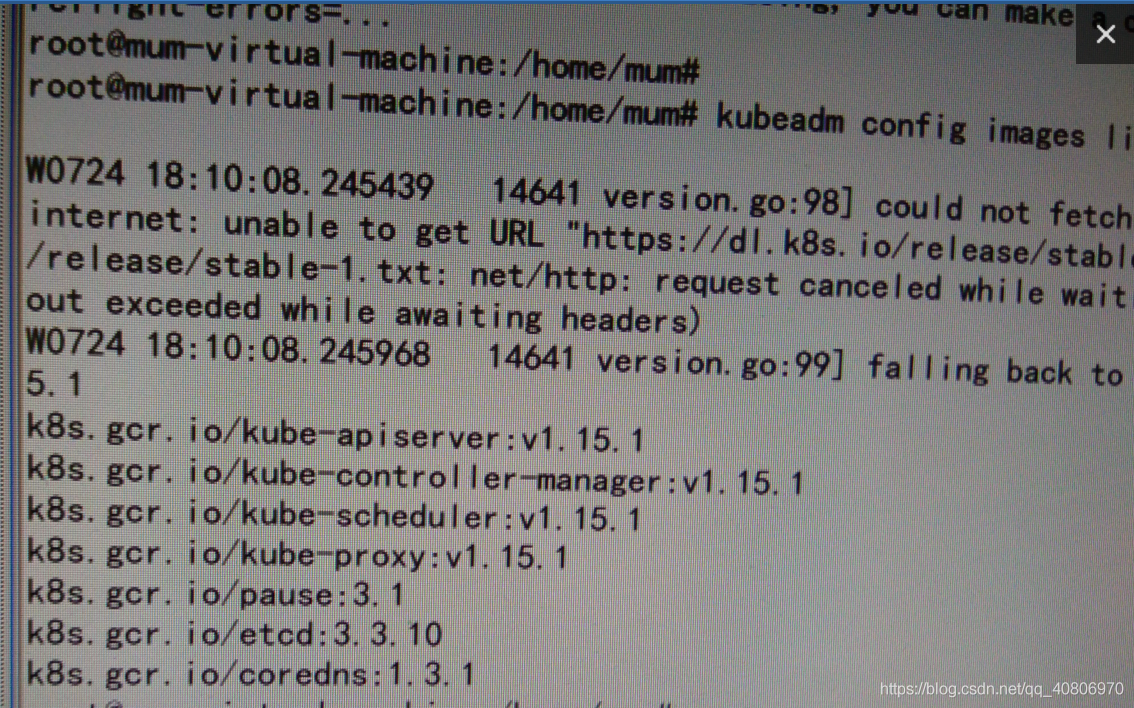 列出的就是 所缺的镜像
列出的就是 所缺的镜像
这里我们使用阿里云的镜像仓库 拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.15.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.15.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.15.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.15.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.3.1
拉取完成后
把这些镜像进行tag一下
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.15.1 k8s.gcr.io/kube-apiserver:v1.15.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.15.1 k8s.gcr.io/kube-controller-manager:v1.15.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.15.1 k8s.gcr.io/kube-scheduler:v1.15.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.15.1 k8s.gcr.io/kube-proxy:v1.15.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.10 k8s.gcr.io/etcd:3.3.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
接着重新执行
kubeadm init --kubernetes-version=v1.15.1 --pod-network-cidr 10.244.0.0/16 --ignore-preflight-errors=NumCPU
如果不加后面的–ignore-preflight-errors=NumCPU参数 还是会报错
输出结果为: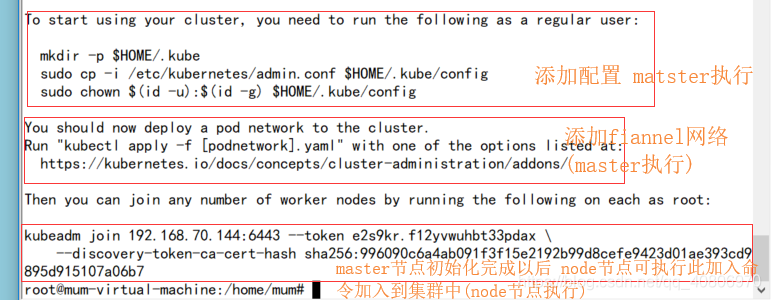 此时表示初始化成功
此时表示初始化成功
但此时集群还不可以使用,上图红框是需要执行的操作 执行完以后才能使用集群
(1)执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
(2)接下来配置网络插件
网络插件有很多
这里有两种配置网络插件的步骤 一种是配置flannel 另一种是 kube-router
两种网络插件 选其一
kube-router 这个网络插件 支持 网络策略。
1.配置 flannel 的方法
flannel网络插件,可以到 https://github.com/coreos/flannel 找到图中的这句话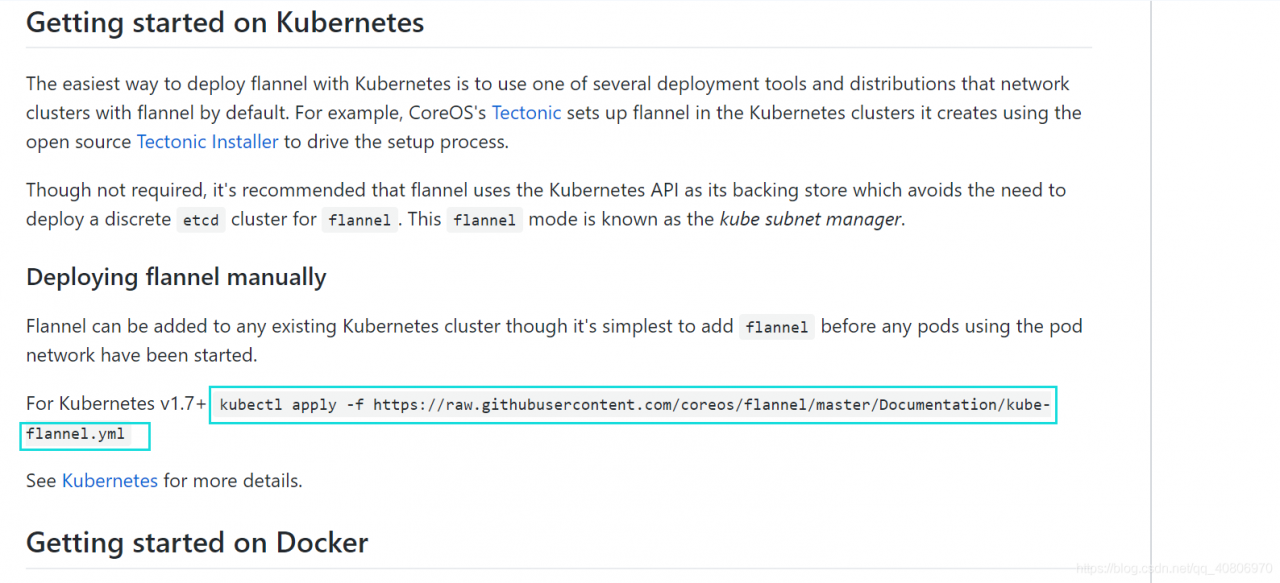 也可以直接执行这个 这条命令和图中框起来的一样
也可以直接执行这个 这条命令和图中框起来的一样
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
即可配置flannel网络
2.安装kube-router网络插件:
# 创建kube-router目录下载相关文件
mkdir kube-router && cd kube-router
wget https://raw.githubusercontent.com/cloudnativelabs/kube-router/master/daemonset/kubeadm-kuberouter.yaml
wget https://raw.githubusercontent.com/cloudnativelabs/kube-router/master/daemonset/kubeadm-kuberouter-all-features.yaml
# 以下两种部署方式任选其一
# 1. 只启用 pod网络通信,网络隔离策略 功能
kubectl apply -f kubeadm-kuberouter.yaml
# 2. 启用 pod网络通信,网络隔离策略,服务代理 所有功能
# 删除kube-proxy和其之前配置的服务代理
kubectl apply -f kubeadm-kuberouter-all-features.yaml
# 以上两种其一 根据需要
# 在每个节点上执行 master node 都执行
docker run --privileged --net=host registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.10.2 kube-proxy --cleanup
# 查看
kubectl get pods --namespace kube-system
kubectl get svc --namespace kube-system
第三个框中的是用在node节点中使用的 用来加入集群
(3)查看pod
kubectl get pods --all-namespaces
执行结果: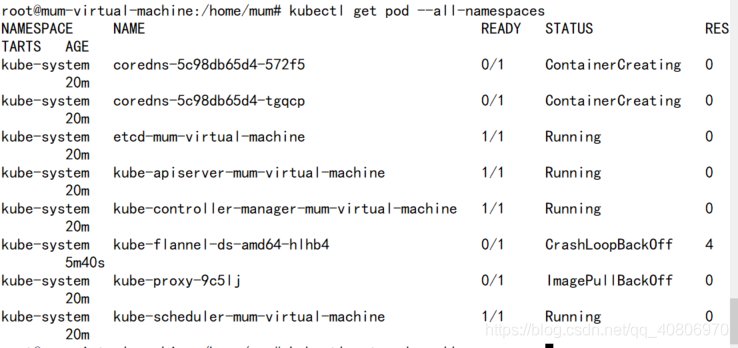 倒数第二个那个 那个镜像 没有拉下来的意思 其实可能是因为我忘了 tag这个吧
倒数第二个那个 那个镜像 没有拉下来的意思 其实可能是因为我忘了 tag这个吧
之后 我又在Master节点 重新拉了一下这个镜像 重新tag了一下
在 Master 使用命令
kubectl get nodes
执行结果
此时master节点 已经搭建成功!!
5.将node节点加入到集群中
(新的node节点 要执行完 第二大步的那些操作)
将 我们在初始化 Kubernetes 是 得到的那条命令在 node节点中执行
也可再重新生成
1.生成token(在master节点执行)
kubeadm token create
执行结果![]()
2.生成认证(在master节点执行)
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
执行结果
3.加入集群(node节点执行)
模板
模板: kubeadm join --token <token> <master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>
这我是 最终执行的
kubeadm join 192.168.70.144:6443 --token ua9yyk.mtcxk41yr6qlxbtq --discovery-token-ca-cert-hash sha256:996090c6a4ab091f3f15e2192b99d8cefe9423d01ae393cd9895d915107a06b7
执行完之后 我并没有成功
而是出了错误
可能是 我之前忘了node上 禁用swap了
但此时 我再使用 swapoff -a命令 但是 一直执行不成功![]()
后来才发现是因为我虚拟机内存 分的太小了,因为使用的交换文件的数量大于我的内存中所能容纳的数量。
之前分的 1g 后来我把内存改成2g 再执行 swapoff -a 就没问题了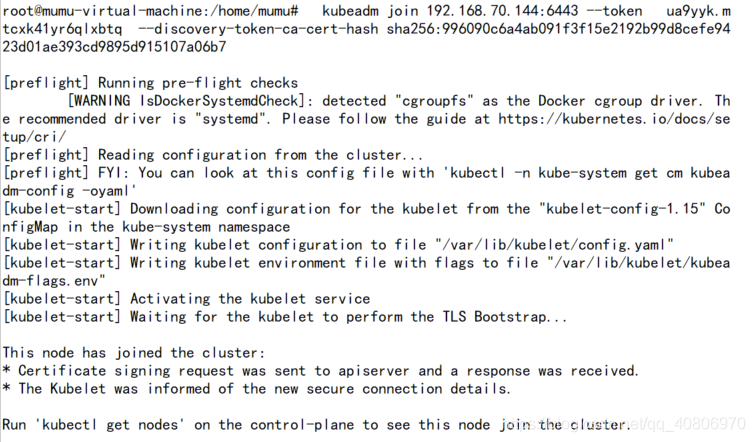 ***这样 node就加入成功了!!***
***这样 node就加入成功了!!***
你以为 这样就结束了吗?
并没有
4.在master节点上查看
此时节点的状态为 好吧还没结束 NotReady
在 master 查看pod 状态
kubectl get pods --all-namespaces
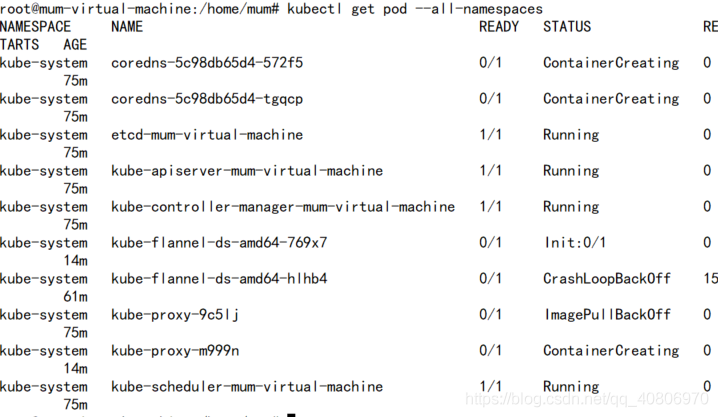 部分服务没有正常启动,原因是各个node也缺少镜像,需要手动下载,按照在master手动下载镜像的方式下载即可
部分服务没有正常启动,原因是各个node也缺少镜像,需要手动下载,按照在master手动下载镜像的方式下载即可
接着 我又在 node 把在master 拉取镜像 tag的步骤又 执行了一遍
在master 节点上执行 kubectl get nodes
还是 Not Ready
重新在 master 节点下 查看下 pod的状态
kubectl get pods --all-namespaces
这个已经没了![]()
但是 还是有点问题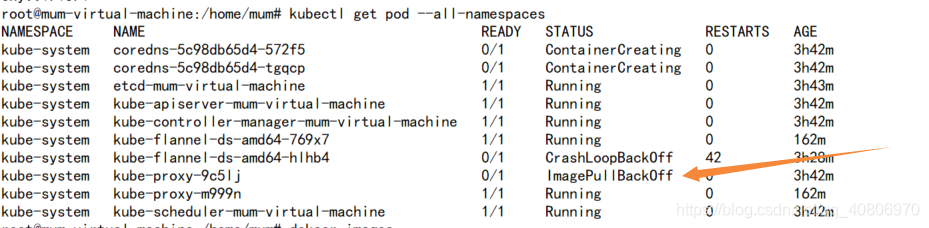
然后我执行了下
kubectl describe pods --namespace=kube-system kube-flannel-ds-amd64-hlh
查看 该pod的 详细信息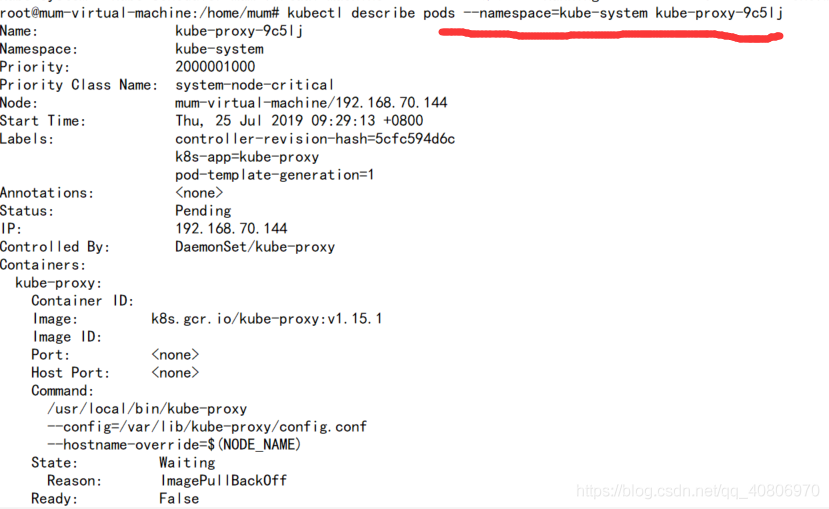

发现该镜像没有拉取下来
我在node中 对这个镜像 又执行了一遍 拉取 然后 tag
发现不行
然后我在master中 node中 对这个镜像 又执行了一遍 拉取 然后 tag
就可以了 其他那些 pod 不用管 不影响
其他那些 pod 不用管 不影响
之后执行 kubectl get nodes !
唔~~ 终于可以了!!!
可能遇见的问题
在node中 运行kubectl get nodes 时 报错
The connection to the server localhost:8080 was refused - did you specify the right host or port?![]()
出现这个问题的原因是kubectl命令需要使用kubernetes-admin来运行,解决方法如下,将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下,然后配置环境变量:
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
再次运行:
kubectl get nodes
OK了~~~
如果哪些地方有问题的话 欢迎指出
参考的文章:https://blog.csdn.net/wangchunfa122/article/details/86529406
https://blog.csdn.net/weixin_42551369/article/details/89208554