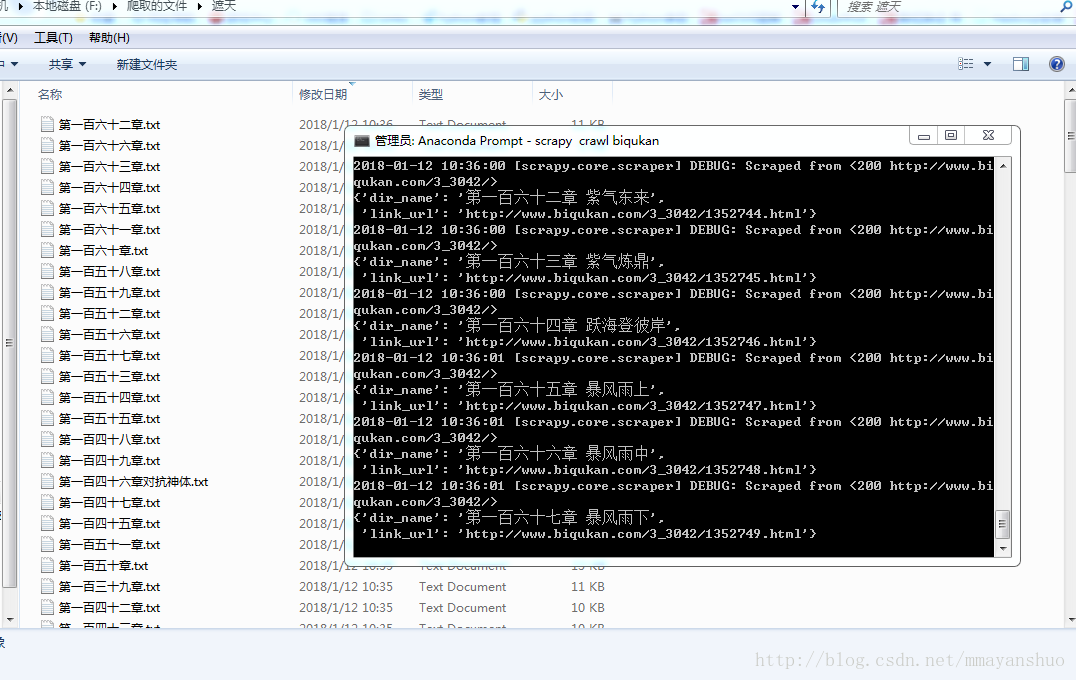
背景:
Python发行版本:Anaconda3(Python3)
IDE:PyCharm
运行平台:windows
前言:
Scrapy是一个流行的网络爬虫框架,它拥有很多简化网站抓取的高级函数。
现在Scrapy已经推出Python3版本,给做网络爬虫很大的助力。
(一)Scrapy简介
Scrapy流程图: 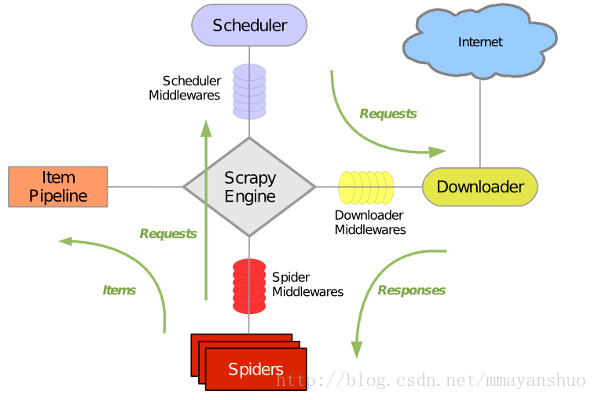
Scrapy主要包括了以下组成部分:
1、引擎(Scrapy Engine):
用来处理整个系统的数据流, 触发事务(框架核心)
2、调度器(Scheduler):
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(downloader):
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
4、爬虫(Spiders):
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
5、项目管道(Pipeline):
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6、下载器中间件(Spider Middlewares):
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7、爬虫中间件(Spider Middlewares):
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
8、调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程:
1、引擎从调度器中取出一个链接(URL)用于接下来的抓取
2、引擎把URL封装成一个请求(Request)传给下载器
3、下载器把资源下载下来,并封装成应答包(Response)
4、爬虫解析Response
5、解析出实体(Item),则交给实体管道进行进一步的处理
6、解析出的是链接(URL),则把URL交给调度器等待抓取
(二)Scrapy安装
打开Anaconda Prompt,键入命令:
pip install scrapy注意:这里希望朋友们安装Python的发行版本:Anaconda,发行版将python和许多常用的package打包。安装很多第三方库也很方便。比如装这个Scrapy,用Anaconda就需要一个命令,而裸奔的Python可能需要再安装很多Scrapy的依赖包。 
等待,安装好Scrapy后,我们检测是否安装成功。键入命令:
scrapy将会出现scrapy的版本信息。 
接下来通过一个实战项目来了解scrapy框架
项目:我们爬取一本我曾经非常喜欢的一部小说–遮天,爬取的网站还是我们曾经爬过的—笔趣阁
URL:http://www.biqukan.com/3_3042/
(三)Scrapy基础
1、创建项目:
我们打开Anaconda Prompt,进入打算存储项目的目录中,键入固定命令“scrapy startproject 项目名 ”,这里我创建了一个名为“zhetian”的项目,如:
scrapy startproject zhetian这时在目录中就会有这样几个文件:
zhetian/
zhetian/
spiders/
__init__.py
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
scrapy.cfg这部分文件的主要作用是:
(1)scrapy.cfg: 项目的配置文件;
(2)zhetian/: 该项目的python模块。之后将在此加入Spider代码;
(3)zhetian/items.py: 项目中的item文件;
(4)zhetian/middlewares .py:项目中的中间件;
(5)zhetian/pipelines.py: 项目中的pipelines文件;
(6)zhetian/settings.py: 项目的设置文件;
(7)zhetian/spiders/: 放置spider代码的目录。
2、创建程序:
首先,进入工程目录:
cd zhetian然后,创建爬虫程序:
scrapy genspider biqukan biqukan.combiqukan 是爬虫名,biqukan.com是你爬取页面所在的域名。
输入命令后,会在zhetian/spiders中自动生成biqukan.py文件,并自动生成模板代码。
创建程序后,我们就可以编程了,下面我将介绍Scrapy中几个重要的类,以及Scrpy爬虫的机制。
3、scrapy类:
打开自动生成的biqukan.py,我们会看到模板代码大致如下:
# -*- coding: utf-8 -*-
import scrapy
class BiqukanSpider(scrapy.Spider):
name = 'biqukan'
allowed_domains = ['biqukan.com']
start_urls = ['http://www.biqukan.com/3_3042/']
def parse(self, response):
pass我们可以看到创建的BiqukanSpider类继承了scrapy.Spider,用于构造Request对象给Scheduler。
3.1 scrapy类的属性:
(1)name:爬虫程序的名称,在运行工程的时候需要用到的标识;
(2)allowed_domains:允许爬虫访问的域名,防止爬虫跑飞。让爬虫只在指定域名下进行爬取,值得注意的一点是,这个域名需要放到列表里;
(3)start_urls:开始爬取的url,同样这个url链接也需要放在列表里;
3.2 scrapy类的方法:
(1)start_requests(self):启动爬虫的时候自动被调用,开始爬取start_urls的链接。如果重写了该方法,则不会自动爬取start_urls的链接。可以在这个方法里面定制一些自定义的url,如登录,从数据库读取url等,本方法返回Request对象。
(2)parse:response到达spider的时候默认调用,如果在Request对象配置了callback函数,则不会调用,parse方法可以迭代返回Item或Request对象,如果返回Request对象,则会进行增量爬取。
3.3 Request与Response
Request:
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback, flags])每个请求都是一个Request对象,Request对象定义了请求的相关信息(url, method, headers, body, cookie, priority)和回调的相关信息(meta, callback, dont_filter, errback),通常由spider迭代返回。
url:请求的链接地址;
callback:回调函数,此请求的响应一旦下载,这个参数将会第一时间响应。如果没有指定回调函数,那么这个Spider的parse()方法将会被调用。注意,如果在处理期间引发异常,则会调用errback。
method: 此请求的HTTP方法。默认为’GET’。
meta:官方说法:属性的初始值Request.meta。如果给定,在此参数中传递的dict将被浅复制。
我的理解是给回调函数传参数。在某些情况下,您可能有兴趣向这些回调函数传递参数,以便稍后在第二个回调中接收参数。您可以使用该Request.meta属性
body(str或unicode):请求体。如果一个 unicode(编码方案)被传递,那么它会使用被传递的编码方案编码成str(默认为utf-8)。如果 body没有给出,则存储一个空字符串。不管这个参数的什么类型,存储的最终值将是一个str(不会是unicode或None)。
headers(dict):这个请求的头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。如果 None作为值传递,则不会发送HTTP头。
cookie(dict或list) - 请求cookie。这些可以以两种形式发送
使用字典,和使用列表: 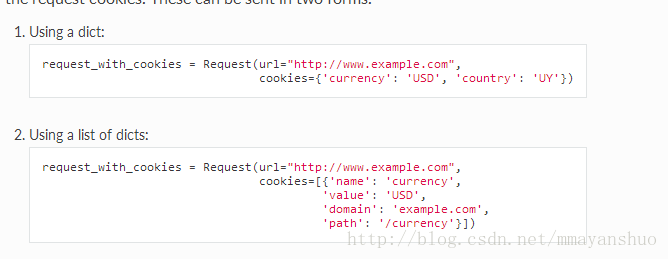
encoding(string) - 此请求的编码(默认为’utf-8’)。此编码将用于对URL进行百分比编码,并将正文转换为str(如果给定unicode)。
priority(int) - 此请求的优先级(默认为0)。调度器使用优先级来定义用于处理请求的顺序。具有较高优先级值的请求将较早执行。允许负值以指示相对低优先级。
dont_filter(boolean) - 表示此请求不应由调度程序过滤。当您想要多次执行相同的请求时忽略重复过滤器时使用。小心使用它,或者你会进入爬行循环。默认为False。
errback(callable) - 如果在处理请求时引发任何异常,将调用的函数。这包括失败的404 HTTP错误等页面。它接收一个Twisted Failure实例作为第一个参数。有关更多信息,请参阅使用errbacks在请求处理中捕获异常。
详细资料在:
https://doc.scrapy.org/en/latest/topics/request-response.html#request-objects
Response:
请求完成后,会通过Response对象发送给spider处理,常用属性有(url, status, headers, body, request, meta, )
详情看上面的英文文档。
4、 item类:
对于爬虫,我们需要明确我们需要爬取的结构化数据,我们定义一个item存储分类信息,scrapy的item继承自scrapy.Item。
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便。
Item提供了类字典的API,并且可以很方便的声明字段,很多Scrapy组件可以利用Item的其他信息。
简单来说:Item为抓取的数据提供了容器
编写后的items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhetianItem(scrapy.Item):
# define the fields for your item here like:
#每个章节的章节名
dir_name = scrapy.Field()
#每个章节的章节链接
link_url = scrapy.Field()
#每个章节下载之后的保存路径
dir_path = scrapy.Field()
因为这里我们要爬取小说,所有定义我们要爬取的结构话数据:
dir_name:小说每个章节的名字;
link_url:小说每个章节的链接;
dir_path:每个章节下载之后的保存路径;
5、Pipeline:
spider负责爬虫的配置,item负责声明结构化数据,而对于数据的处理,在scrapy中使用管道的方式进行处理,只要注册过的管道都可以处理item数据(处理,过滤,保存)
简单来说:Pipeline是处理item的地方。
以下是item pipeline的一些典型应用:
(1)验证爬取的数据(检查item包含某些字段,比如说name字段)
(2)查重(并丢弃)
(3)将爬取结果保存到文件或者数据库中
例如,爬取小说遮天这个例子,pipeline.py的任务是:根据item中每个章节的名字以及章节链接获取小说内容,并保存在本地。
6、settings:
Scrapy设置允许您自定义所有Scrapy组件的行为,包括核心,扩展,管道和爬虫本身。
设定为代码提供了提取以key-value映射的配置值的的全局命名空间(namespace)。
简单来说:settings.py可以设置全局变量,并对整个项目做一些配置。
这里把我们项目的setting.py贴上:
# -*- coding: utf-8 -*-
# Scrapy settings for zhetian project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'zhetian'
SPIDER_MODULES = ['zhetian.spiders']
NEWSPIDER_MODULE = 'zhetian.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'zhetian (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'zhetian.pipelines.ZhetianPipeline': 1,
}
TEXT_STORE='F:/爬取的文件/遮天'
#Cookie使能,这里禁止Cookie;
COOKIES_ENABLED = False
#下载延时,这里使用250ms延时。
DOWNLOAD_DELAY = 0.25 # 250 ms of delayBOT_NAME:自动生成的内容,根名字;
SPIDER_MODULES:自动生成的内容;
NEWSPIDER_MODULE:自动生成的内容;
ROBOTSTXT_OBEY:自动生成的内容,是否遵守robots.txt规则,这里选择不遵守;
ITEM_PIPELINES:定义item的pipeline;
TEXT_STORE:爬取的小说内容存储路径
COOKIES_ENABLED:Cookie使能,这里禁止Cookie;
DOWNLOAD_DELAY:下载延时,这里使用250ms延时。
7、xpath:
这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。
我会单开一篇介绍xpath的用法。占坑~~:)
介绍这么多,我们这个项目用到的知识点基本介绍完成了,接下来让我们接触整个项目。
(四)Scrapy实战:遮天
biqukan.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Selector
from zhetian.items import ZhetianItem
from bs4 import BeautifulSoup
class BiqukanSpider(scrapy.Spider):
name = 'biqukan'
allowed_domains = ['biqukan.com']
start_urls = ['http://www.biqukan.com/3_3042/']
def parse(self, response):
server_link="http://www.biqukan.com"
items = []
listmain=Selector(response)
#目录页面所有的章节链接
link_urls = listmain.xpath('//dd/a[1]/@href').extract()
#目录页面所有的章节名
dir_names = listmain.xpath('//dd/a[1]/text()').extract()
for index in range(len(link_urls)):
if index>11:
item = ZhetianItem()
item['link_url'] = server_link + link_urls[index]
item['dir_name'] = dir_names[index]
items.append(item)
for item in items:
yield item
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhetianItem(scrapy.Item):
# define the fields for your item here like:
#每个章节的章节名
dir_name = scrapy.Field()
#每个章节的章节链接
link_url = scrapy.Field()
#每个章节下载之后的保存路径
dir_path = scrapy.Field()
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for zhetian project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'zhetian'
SPIDER_MODULES = ['zhetian.spiders']
NEWSPIDER_MODULE = 'zhetian.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'zhetian (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'zhetian.pipelines.ZhetianPipeline': 1,
}
TEXT_STORE='F:/爬取的文件/遮天'
#Cookie使能,这里禁止Cookie;
COOKIES_ENABLED = False
#下载延时,这里使用250ms延时。
DOWNLOAD_DELAY = 0.25 # 250 ms of delaypipeline.py
# -*- coding: utf-8 -*-
from zhetian import settings
from bs4 import BeautifulSoup
import os
from urllib import request
class ZhetianPipeline(object):
def process_item(self, item, spider):
#如果获取了章节链接,进行如下操作
if "link_url" in item:
dir_path='%s/%s' % (settings.TEXT_STORE,item['dir_name'].split()[0])
#创建要保存的文件
file = open(dir_path+".txt", 'w', encoding='utf-8')
response = request.Request(url =item['link_url'])
download_response = request.urlopen(response)
download_html = download_response.read().decode('gbk', 'ignore')
soup_texts = BeautifulSoup(download_html, 'lxml')
texts = soup_texts.find_all(id='content', class_='showtxt')
soup_text = BeautifulSoup(str(texts), 'lxml')
write_flag = True
#在文件中写入章节名
file.write(item['dir_name'] + '\n\n')
# 将爬取内容写入文件
for each in soup_text.div.text.replace('\xa0', ''):
if each == 'h':
write_flag = False
if write_flag == True and each != ' ':
file.write(each)
if write_flag == True and each == '\r':
file.write('\n')
file.write('\n\n')
file.close()
return item
运行:
打开Anaconda Prompt,进入项目所在路径,键入命令:
scrapy crawl biqukan运行项目: