此文为翻译+自己的理解,github地址:https://github.com/paulvangentcom/heartrate_analysis_python
第1部分:打开数据,检测第一个峰并计算BPM(每分钟的心跳量);
为了开发峰值检测算法,对于ECG和PPG两种信号,我们都需要标记每个复合物中的最高峰。
首先让我们下载数据集并绘制信号图,以便对数据有所了解并开始寻找有意义地分析数据的方法。我将pandas用于大多数数据任务,并将matplotlib用于大多数绘图需求。
import pandas as pd
import matplotlib.pyplot as plt
dataset = pd.read_csv("data.csv") #读数据
plt.title("Heart Rate Signal") #标题
plt.plot(dataset.hart) #画图
plt.show() #显示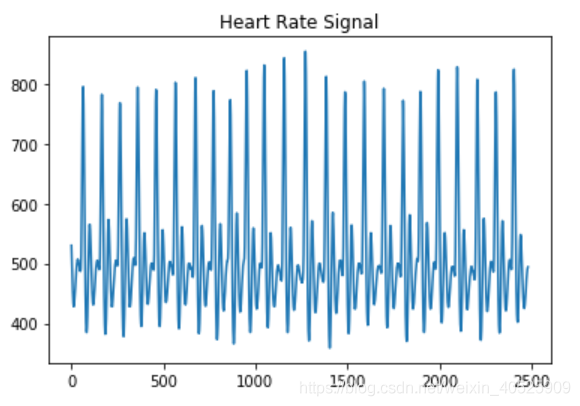
信号看起来很干净!第3部分中的更多内容涉及如何处理噪声和自动确定信号质量。
检测第一个峰
第一步是找到所有R峰的位置。为此,我们需要确定感兴趣区域(ROI),即信号中的每个R峰。得到这些之后,我们需要确定它们的最大值。有几种方法可以做到这一点:
- 在ROI数据点上拟合曲线,求解最大值的x位置;(计算度复杂)
- 确定ROI中每组点之间的斜率,找到斜率反转的位置;
- 在ROI内标记数据点,找到最高点的位置。
- 后两种方法在计算上便宜得多,但精度会降低。这些方法的高精度比曲线拟合方法更加依赖于高采样率。
现在我们把ROI的最高点作为心拍的位置。
现在开始工作:首先将不同的峰彼此分离。为此,我们绘制一个移动平均线,标记心率信号位于移动平均线上方的ROI,并最终在每个ROI中找到最高点,如下所示
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import math
dataset = pd.read_csv("data.csv")
#在当前点的左右0.75s段上做滑动平均, then append do dataset
hrw = 0.75 #单边窗口大小,与采样频率的比例
fs = 100 #示例数据集的采样频率
mov_avg = dataset['hart'].rolling(int(hrw*fs)).mean() #计算滑动平均
#在左右0.75s内返回NaN时, 用信号的平均值代替
avg_hr = (np.mean(dataset.hart))
mov_avg = [avg_hr if math.isnan(x) else x for x in mov_avg]
mov_avg = [x*1.2 for x in mov_avg] #将平均值提高20%,以防止继发性心脏收缩产生干扰,在第2部分中,我们将动态地进行此操作
dataset['hart_rollingmean'] = mov_avg #向表格中增加一列,名为‘hart_rollingmean’,存储滑动平均值
#标注感兴趣的区域
window = []
peaklist = []
listpos = 0 #使用listpos这个变量在不同的列上移动
for datapoint in dataset.hart:
rollingmean = dataset.hart_rollingmean[listpos] #得到局部均值
if (datapoint < rollingmean) and (len(window) < 1): #这时若检测不到 R -> 什么都不用做
listpos += 1
elif (datapoint > rollingmean): #如果信号高于平均值, 标注为 ROI
window.append(datapoint)
listpos += 1
else: #如果信号低于局部均值->确定最高点
maximum = max(window)
beatposition = listpos - len(window) + (window.index(max(window))) #标注这个点的位置
peaklist.append(beatposition) #检测到峰值
window = [] #清空标注的ROI
listpos += 1
ybeat = [dataset.hart[x] for x in peaklist] #得到所有峰值的y值(画图用)
plt.title("Detected peaks in signal")
plt.xlim(0,2500)
plt.plot(dataset.hart, alpha=0.5, color='blue') #Plot semi-transparent HR
plt.plot(mov_avg, color ='green') #画出滑动平均线
plt.scatter(peaklist, ybeat, color='red') #画出检测的峰值
plt.show() 我们已经在信号中标记了信号的最高点,还不错!但是,这是一个理想的信号。在本系列的第3部分中,我们将了解如何处理噪声、测量误差、检测误差以及如何防止我们的模块在质量差的信号部分抛出误差。
有人可能会问:为什么要移动平均线,为什么不仅仅使用700左右的水平线作为阈值?这是一个很好的问题,可以很好地处理此信号。为什么我们使用移动平均线与理想化程度较低的信号有关。R峰值的幅度会随时间变化,尤其是当传感器稍微移动时。较小的次要峰的振幅也可以独立于R峰的振幅而变化,有时具有同R波几乎相同的振幅。减少第3部分中讨论的错误检测到的峰的一种方法是通过拟合不同高度处的移动平均值并确定哪种拟合效果最佳。稍后再详细介绍。
计算心率
我们知道每个峰值在时间上的位置,因此计算此信号的平均“每分钟心跳数”(BPM)度量很简单。只需计算峰之间的距离,取平均值并转换为每分钟的值,如下所示
RR_list = []
cnt = 0
while (cnt < (len(peaklist)-1)):
RR_interval = (peaklist[cnt+1] - peaklist[cnt]) #计算相邻峰值的RR间隔
ms_dist = ((RR_interval / fs) * 1000.0) #将RR间隔转化为时间单位(ms)
RR_list.append(ms_dist) #Append to list
cnt += 1
bpm = 60000 / np.mean(RR_list) #60000 ms (1 分钟) / 信号的平均RR间隔
print("Average Heart Beat is: %.01f" %bpm)#四舍五入到小数点后一位并打印 最后,我们整理一下代码并将其放入可调用函数中。这将使我们的生活在下一部分变得更加轻松,并且我们的代码将更加有条理和可重用。请注意,可能要做的是整洁的事情,使函数成为类的一部分,但为了使本教程也可供那些不太熟悉Python(并且可能对类不熟悉或不熟悉)的人访问,我选择从此处省略本教程系列中的所有代码。
让我们将BPM值和我们计算出的列表放在一个可以调用的字典中,并可以附加我们将在第2部分中计算出的度量。我们编写一个包装函数process(),以便我们可以使用尽可能少的代码来调用分析:
可以这样使用:
import heartbeat as hb #假如我们的文件名为 'heartbeat.py'
dataset = hb.get_data("data.csv")
hb.process(dataset, 0.75, 100)
#我们导入Python 模块,称为 'hb'
#This object contains the dictionary 'measures' with all values in it
#Now we can also retrieve the BPM value (and later other values) like this:
bpm = hb.measures['bpm']
#To view all objects in the dictionary, use "keys()" like so:
print hb.measures.keys()请注意,我们将get_data()函数与包装器分开。这样,我们的模块还可以接受已经存储在内存中的数据帧对象,例如在由另一个程序生成这些数据帧对象时很有用。这使我们的模块保持灵活。
#更新一下绘图方式,加上图例,显示BPM:
plt.title("Detected peaks in signal")
plt.xlim(0,2500)
plt.plot(dataset.hart, alpha=0.5, color='blue', label="raw signal") #Plot semi-transparent HR
plt.plot(mov_avg, color ='green', label="moving average") #Plot moving average
plt.scatter(peaklist, ybeat, color='red', label="average: %.1f BPM" %bpm) #Plot detected peaks
plt.legend(loc=4, framealpha=0.6)
plt.show()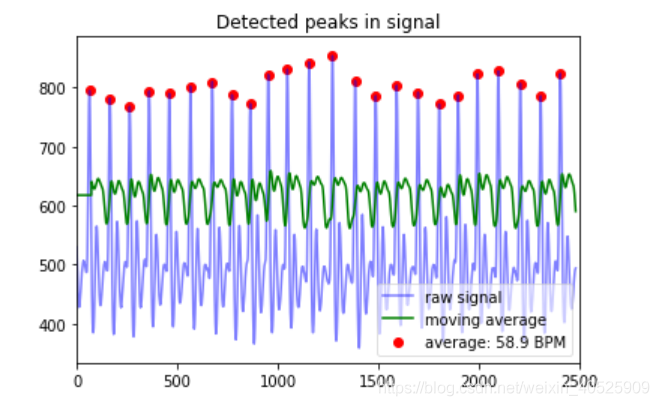
将代码封装一下
最后,我们整理一下代码并将其放入可调用函数中。这将使我们的生活在下一部分变得更加轻松,并且我们的代码将更加有条理和可重用。
我们将BPM值和我们计算出的列表放在一个可以调用的字典中,并可以附加我们将在第2部分中计算出的度量。编写了一个封装函数process(),方便我们可以使用尽可能少的代码来调用分析:
import heartbeat as hb #假设我们将其命名为 'heartbeat.py'
dataset = hb.get_data("data.csv")
hb.process(dataset, 0.75, 100)
#我们导入了称为 'hb'的模块
#设置了一个字典 'measures' 用于储存所有值
#现在,我们可以这样得到BPM值(以及还会有其他值):
bpm = hb.measures['bpm']
#如果要查看字典中的所有对象,请使用“ keys()”,如下所示:
print hb.measures.keys()