sql:命名管道管道程序
A naming convention is a set of unwritten rules you should use if you want to increase the readability of the whole data model. Today, I’ll try to explain how you should formulate your naming convention and, maybe even more important, why should you do it and what is the overall benefit from using it.
命名约定是一组不成文的规则,如果要提高整个数据模型的可读性,应使用这些规则。 今天,我将尝试解释您应该如何制定命名约定,甚至可能更重要的是,为什么要这么做以及使用它的总体好处是什么?
数据模型及简介 (Data Model & the brief introduction)
We’ll use the same data model we’re using in this series.
我们将使用与本系列相同的数据模型。
{kind=link}

This time we won’t talk about the data itself, but rather about the database objects and the way they were named.
这次我们不讨论数据本身,而是讨论数据库对象及其命名方式。
I’ve already stated it in the intro, but more generally, a naming convention is a set of rules you decide to go with before you start modeling your database. You’ll apply these rules while naming anything inside the database – tables, columns, primary and foreign keys, stored procedures, functions, views, etc. Of course, you could decide to only set naming convention rules for tables and column names. That part is completely up to you.
我已经在介绍中进行了说明,但更笼统地说,命名约定是在开始对数据库进行建模之前决定要遵循的一组规则。 在命名数据库内部的任何内容(表,列, 主 键和外键 , 存储过程 , 函数 , 视图等)时,将应用这些规则。当然,您可以决定只为表和列名设置命名约定规则。 那部分完全取决于您。
Also, using the naming convention is not the rule, but it’s desired. While most rules are pretty logical, you could go with some you’ve invited (e.g., you could call a primary key attribute “id”, or “ID”), and that is completely up to you. In this article, I’ll try to use these rules you’ll meet in most cases.
另外,使用命名约定不是规则,但它是所希望的。 尽管大多数规则是合乎逻辑的,但是您可以选择一些已邀请的规则(例如,可以将主键属性称为“ id”或“ ID”),而这完全取决于您。 在本文中,我将尝试使用大多数情况下会遇到的这些规则。
为什么要使用命名约定? (Why should you use the naming convention?)
Maybe the most important reason to use it is to simplify life to yourself. Databases rarely have a small number of tables. Usually, you’ll have hundreds of tables, and if you don’t want to have a complete mess, you should follow some organizational rules. One of these rules would be to apply a naming convention. It will increase the overall model readability, and you’ll spend less time finding what you need. Also, it will be much easier to query the INFORMATION_SCHEMA database in search of specific patterns – e.g., checking if all tables have the primary key attribute named “id”; do we have a stored procedure that performs an insert for each table, etc.
也许使用它的最重要原因是简化自己的生活。 数据库很少有少量的表。 通常,您将有数百个表,如果您不希望一团糟,则应遵循一些组织规则。 这些规则之一就是应用命名约定。 它将提高整体模型的可读性,并且您将花费更少的时间查找所需的内容。 同样,查询INFORMATION_SCHEMA数据库以查找特定模式将容易得多,例如,检查所有表是否具有名为“ id”的主键属性; 我们是否有一个存储过程为每个表等执行插入操作?
If that wasn’t enough, there is also one good reason. The database shall live for a long time. Changes at the database level are usually avoided and done only when necessary. The main reason is that if you change the name of the database object that could affect many places in your code. On the other hand, the code can change during time. Maybe you’ll even change the language used to write the code. Therefore, you can expect that the database will stay, more or less, very similar to its’ initial production version. If you apply best practices from the start and continue using them when you add new objects, you’ll keep your database structure well organized and easily readable.
如果那还不够,还有一个很好的理由。 该数据库应存在很长时间。 通常避免在数据库级别进行更改,并且仅在必要时进行更改。 主要原因是,如果您更改数据库对象的名称,这可能会影响代码中的许多位置。 另一方面,代码可以随时间变化。 也许您甚至会更改用于编写代码的语言。 因此,您可以预期数据库将或多或少地保持与其初始生产版本非常相似。 如果您从一开始就应用最佳实践,并在添加新对象时继续使用它们,则可以使数据库结构井井有条,易于阅读。
One more reason to use it is that you probably won’t be the only one working with the database. If it’s readable, anybody who jumps into the project should be aware of what is where and how the data is related. That shall be especially the case if you’re using the most common naming convention rules. In case you have something specific for your database, you can list all such exceptions in one short document.
使用它的另一个原因是您可能不是唯一使用该数据库的人。 如果可读性强,那么跳入项目的任何人都应该知道数据在什么地方以及如何关联。 如果您使用的是最常见的命名约定规则,则尤其如此。 如果您有特定于数据库的内容,则可以在一个简短的文档中列出所有此类异常。
如何命名表格? (How to name tables?)
Hint: Use lower letters when naming database objects. For separating words in the database object name, use underscore
提示 :命名数据库对象时,请使用小写字母。 要在数据库对象名称中分隔单词,请使用下划线
When naming tables, you have two options – to use the singular for the table name or to use a plural. My suggestion would be to always go with names in the singular.
命名表时,有两种选择–使用单数表示表名或使用复数。 我的建议是始终使用单数形式的名称。
If you’re naming entities that represent real-world facts, you should use nouns. These are tables like employee, customer, city, and country. If possible, use a single word that exactly describes what is in the table. On the example of our 4 tables, it’s more than clear what data can be found in these tables.
如果要命名代表现实世界事实的实体,则应使用名词。 这些表包括员工 , 客户 , 城市和国家 。 如果可能,请使用一个单词来准确描述表中的内容。 在我们的4个表的示例中,不仅仅可以在这些表中找到什么数据。
Hint: Use singular for table names (user, role), and not plural (users, roles). The plural could lead to some weird table names later (instead of user_has_role, you would have users_have_roles, etc.)
提示 :表名(用户,角色)使用单数,而不是表名(用户,角色)。 复数形式可能会在以后导致一些怪异的表名(而不是user_has_role,而您将拥有users_have_roles等)。
If there is a need to use more than 1 word to describe what is in the table – do it so. In our database, one such example would be the call_outcome table. We can’t use only “call”, because we already have the table call in the database. On the other hand, using the word outcome wouldn’t clearly describe what is in the table, so using the call_outcome as the table name seems like a good choice.
如果需要使用多个单词来描述表中的内容,请执行此操作。 在我们的数据库中, call_outcome表就是这样的示例。 我们不能只使用“调用”,因为我们已经在数据库中进行了表调用 。 另一方面,使用结果一词并不能清楚地描述表中的内容,因此使用call_outcome作为表名似乎是一个不错的选择。
For relations between two tables, it’s good to use these two tables’ names and maybe add a verb between these names to describe what that action is.
对于两个表之间的关系,最好使用这两个表的名称,并可能在这些名称之间添加一个动词来描述该动作是什么。
Imagine that we have tables user and role. We want to add a many-to-many relation telling us that a user had a certain role. We could use names user_has_role, or if we want to be shorter – user_role.
想象我们有表user和role 。 我们想要添加一个多对多关系来告诉我们用户具有特定角色。 我们可以使用名称user_has_role ,也可以使用更短的名称– user_role 。
We could always make exceptions if they are logical. If we have tables product and invoice, and we want to specify which products were on which invoice, we could name that table invoice_product or invoice_contains_product. Still, using the name invoice_item is much closer to the real world. Still, that decision is completely up to you.
如果异常是合乎逻辑的,我们总是可以做出例外。 如果我们有表product和invoice ,并且想要指定哪个产品在哪个发票上,则可以将该表命名为invoice_product或invoice_contains_product 。 尽管如此,使用名称invoice_item更接近现实世界。 不过,该决定完全取决于您。
如何命名列? (How to name columns?)
I would separate the naming convention for columns in a few categories:
我将列的命名约定分为几类:
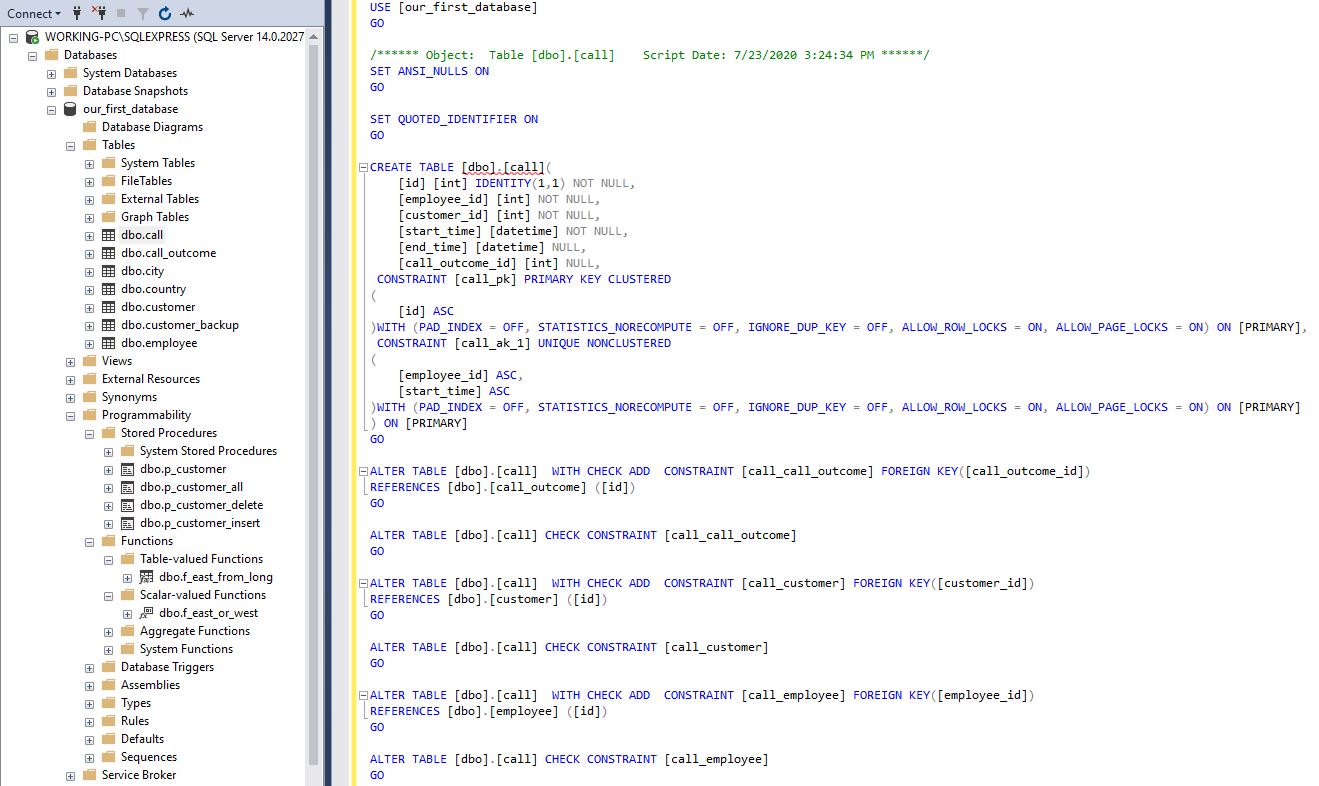
- A primary key column.You should usually have only 1 column serving as a primary key. It would be the best to simply name this column “id”. You should also name your PK constraint in a meaningful way. E.g., in our database, the PK of the 主键列。 通常,您只应有1列用作主键。 最好仅将此列命名为“ id”。 您还应该以有意义的方式命名PK约束。 例如,在我们的数据库中, call table is named 调用表的PK名为call_pk call_pk
CONSTRAINT [call_pk] PRIMARY KEY CLUSTERED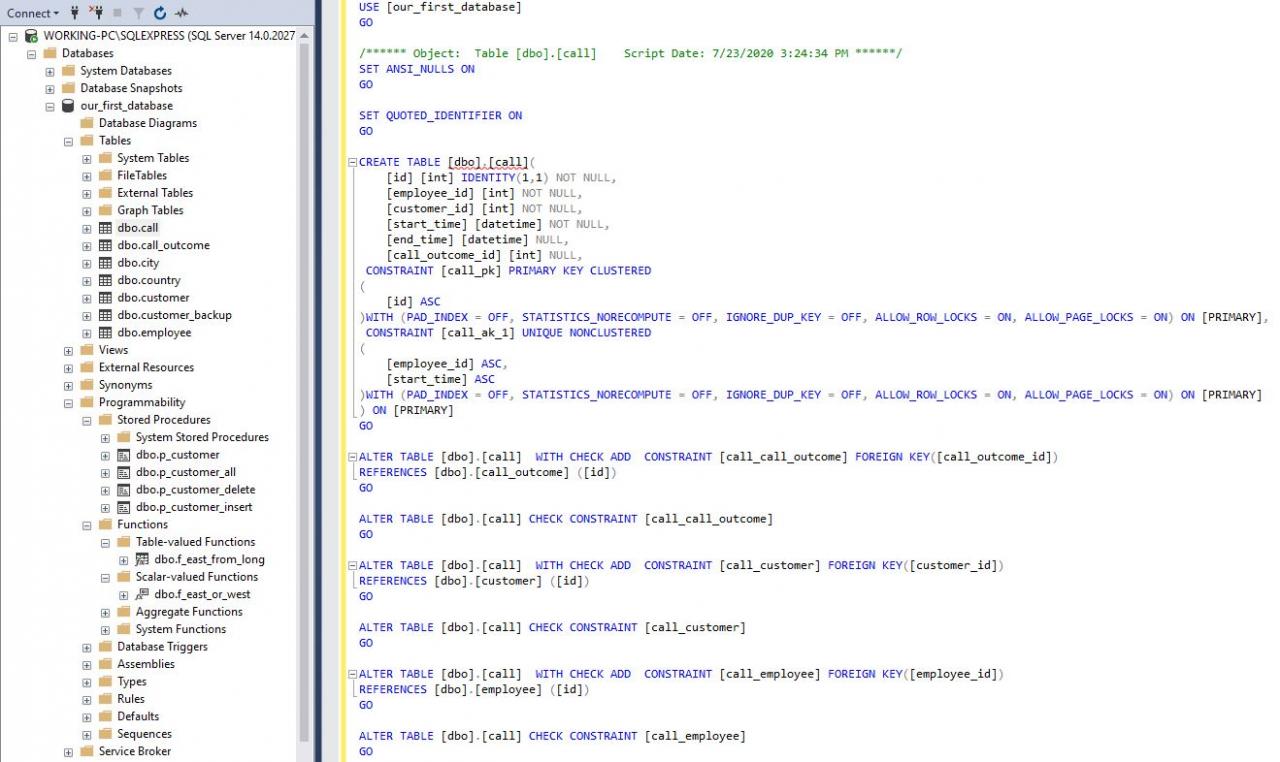
- Foreign key columns.Since they store values from the range of primary key of the referenced table, you should use that table name and “id”, e.g. 外键列。 由于它们存储的值来自所引用表的主键范围,因此应使用该表名和“ id”,例如customer_id or customer_id或id_customer, id_customer , employee_id or employee_id或employee_id. This will tell us that this is a foreign key column and also point to the referenced table. In our database, we go with the first option – e.g., employee_id 。 这将告诉我们这是一个外键列,也指向引用的表。 在我们的数据库中,我们采用第一个选项–例如, customer_id customer_id
- Data columns. These are attributes that store real-world data. The same rules could be applied as the ones used when naming tables. You should use the least possible words to describe what is stored in that column, e.g., 数据列。 这些是存储实际数据的属性。 可以使用与命名表时使用的规则相同的规则。 您应该使用最少的单词来描述该列中存储的内容,例如country_name, country_name , country_code, country_code , customer_name. If you expect that 2 tables will have the column with the same name, you could add something to keep the name unique. In our model in the customer table, I’ve used the customer_name 。 如果您期望2个表中的列具有相同的名称,则可以添加一些内容以保持名称唯一。 在我们的客户表模型中,我使用customer_name as a column name. I’ve also done the same in the table city with the column customer_name作为列名。 在表city中,我也使用列city_name. Generally, you can expect that using the word name alone won’t be enough to keep that column name unique city_name进行了相同的操作。 通常,您可以期望仅使用单词名称不足以使该列名称保持唯一
{kind=link}
Hint: It’s not a problem if two columns, in different tables in the database, have the same name. Still, having unique names for each column is OK because we reduce the chance to later mix these two columns while writing queries
提示 :如果数据库中不同表中的两列具有相同的名称,这不是问题。 不过,每列都具有唯一的名称是可以的,因为我们减少了稍后在编写查询时将这两列混合的机会
- Dates. For dates, it’s good to describe what the date represents. Names like 日期。 对于日期,最好描述日期代表什么。 诸如start_date and start_date和end_date are pretty descriptive. If you want, you can describe them even more precise, using names like end_date之类的名称具有很好的描述性。 如果需要,您可以使用call_start_date and call_start_date和call_end_date call_end_date之类的名称更精确地描述它们
- Flags. We could have flags marking if some action took place or not. We could use names like 标志。 我们可以有标记来标记是否采取了某些措施。 我们可以使用is_active, is_active , is_deleted is_deleted之类的名称
外键,过程,功能和视图的命名约定 (Naming Conventions for Foreign Keys, Procedures, Functions, and Views)
I won’t go into details here, but rather give a brief explanation of the naming convention I use when I do name these objects.
我在这里不做详细介绍,而是简要说明我为这些对象命名时使用的命名约定。
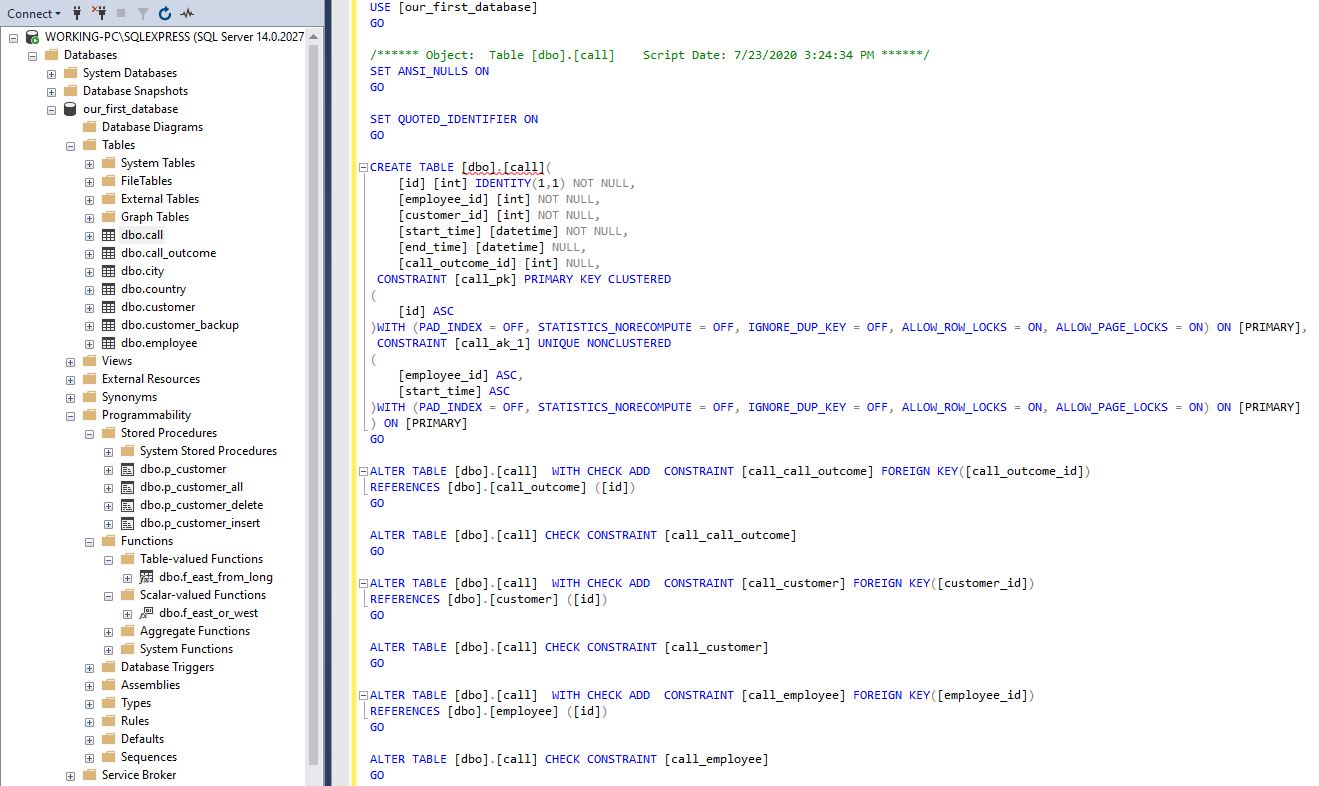
Foreign keys. You should name them in such a manner that they uniquely and clearly describe what they are – which tables they relate. In our database, the foreign key that relates tables call and call_outcome is called call_call_outcome.
外键。 您应该以独特的方式命名它们,并清楚地描述它们是什么-它们相关的表。 在我们的数据库中,与表call和call_outcome相关的外键称为call_call_outcome 。
ALTER TABLE [dbo].[call] WITH CHECK ADD CONSTRAINT [call_call_outcome] FOREIGN KEY([call_outcome_id])
REFERENCES [dbo].[call_outcome] ([id])
{kind=link}
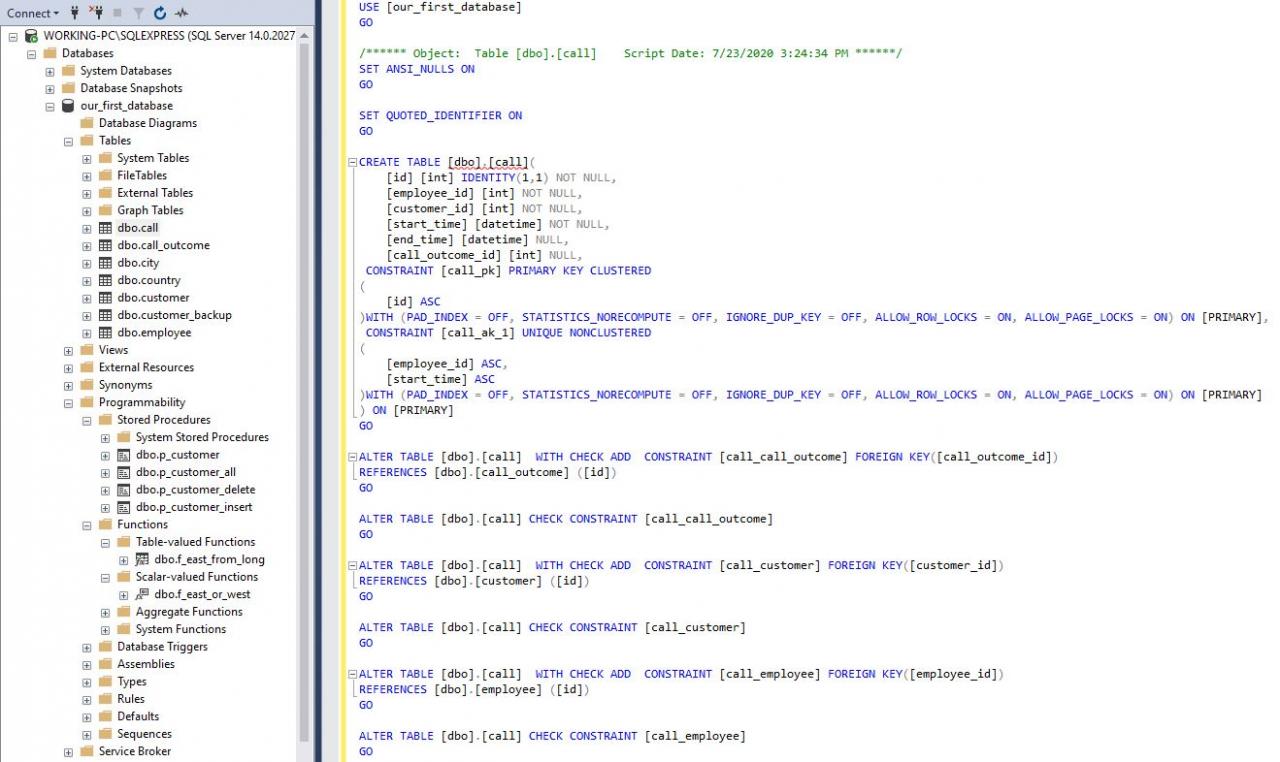
Stored procedures. Stored procedures usually run a set of actions and return a dataset. My rule is to have two approaches to their naming.
存储过程。 存储过程通常运行一组动作并返回数据集。 我的规则是采用两种命名方法。
- p_<table_name>_<action_name>. E.g., p_ <table_name> _ <action_name> 。 例如, p_customer_insert inserts a new row in the table customer; p_customer_insert在表customer中插入新行; p_customer_delete deletes a row, p_customer_delete删除一行, p_customer_all returns all customers from the table, while p_customer_all返回表中的所有客户,而p_customer returns only 1 customer p_customer仅返回1个客户
- If the procedure uses more than 1 table, I would use a descriptive name for the procedure. E.g., if we want all customers with 5 or more calls, I would call this procedure similar to this – p_customer_with_5_or_more_calls
- 如果该过程使用多个表,则将为该过程使用一个描述性名称。 例如,如果我们希望所有客户都拨打5个或更多电话,我将调用与此类似的过程– p_customer_with_5_or_more_calls
Functions. Functions usually perform simple calculations and return values. Therefore, the best way to name them would be to describe what the function does. I also love to put f_ at the start of the name. In our database, one example is – f_east_from_long.
功能。 函数通常执行简单的计算并返回值。 因此,命名它们的最佳方法是描述函数的作用。 我也喜欢将f_放在名字的开头。 在我们的数据库中,一个示例是– f_east_from_long 。
Views. Most of the rules that are applied to naming stored procedures should be applied to views. I usually don’t use views, but when I do, I place v_ at the start of their name.
意见。 适用于命名存储过程的大多数规则都应应用于视图。 我通常不使用视图,但是当我使用视图时,我将v_放在其名称的开头。
结论 (Conclusion)
The naming convention is not a must, but (very) nice to have. Applying the rules you’ve set for the database design will help not only you but also others who will work with the database. Therefore, I would suggest that you use it and keep the database as organized as it could be.
命名约定不是必须的,但是(非常)不错。 应用您为数据库设计设置的规则不仅对您有帮助,而且对使用数据库的其他人也有帮助。 因此,我建议您使用它并保持数据库尽可能的井井有条。
目录 (Table of contents)
sql:命名管道管道程序