过去几年,Kubernetes已经成为容器编排的标准,越来越多的公司开始在生产系统使用Kubernetes。通常我们使用Prometheus对K8S集群进行监控,但由于Prometheus自身单点的问题。不得不寻求一些联邦方案或者分布式高可用方案,社区热度比较高的项目有Thanos,Cortex,VictoriaMetrics。本文就介绍使用VictoriaMetrics作为数据存储后端对K8S集群进行监控,k8s部署不再具体描述。
环境版本
实验使用单节点k8s 网络组件使用cilium VictoriaMetrics存储使用localpv
[root@cilium-1 victoria-metrics-cluster]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@cilium-1 victoria-metrics-cluster]# uname -r
4.19.110-300.el7.x86_64
[root@cilium-1 pvs]# kubectl get node
NAME STATUS ROLES AGE VERSION
cilium-1.novalocal Ready master 28m v1.19.4
主要监控目标
- master,node节点负载状态
- k8s 组件状态
- etcd状态
- k8s集群资源状态 (deploy,sts,pod…)
- 用户自定义组件(主要通过pod定义prometheus.io/scrape自动上报target)
- …
监控需要部署的组件
- VictoriaMetrics(storage,insert,select,agent,vmalert)
- kube-state-metrics
- node-exporter
- promxy
- karma
- alertmanager
- grafana
- …
部署VictoriaMetrics
创建localpv为storage组件提供StorageClass 也可以使用其他网络存储
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: vm-disks
provisioner: kubernetes.io/no-provisioner
reclaimPolicy: Retain
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: vm-1
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: vm-disks
local:
path: /mnt/vmdata-1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- cilium-1.novalocal
---
...
[root@cilium-1 pvs]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
vm-disks kubernetes.io/no-provisioner Retain WaitForFirstConsumer false 6m5s
[root@cilium-1 pvs]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
vm-1 10Gi RWO Delete Available vm-disks 92s
vm-2 10Gi RWO Delete Available vm-disks 92s
vm-3 10Gi RWO Delete Available vm-disks 92s
使用helm 进行安装
添加helm repo 拉取chart包并解压
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update
helm fetch vm/victoria-metrics-cluster
tar -xf victoria-metrics-cluster-0.8.25.tgz
Chart.yaml README.md README.md.gotmpl templates values.yaml
根据自己的需求修改values.yaml
这里我主要修改vmstorage组件配置storageclass
# values.yaml
# Default values for victoria-metrics.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
# -- k8s cluster domain suffix, uses for building stroage pods' FQDN. Ref: [https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/](https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/)
clusterDomainSuffix: cluster.local
printNotes: true
rbac:
create: true
pspEnabled: true
namespaced: false
extraLabels: {}
# annotations: {}
serviceAccount:
create: true
# name:
extraLabels: {}
# annotations: {}
# mount API token to pod directly
automountToken: true
extraSecrets:
[]
# - name: secret-remote-storage-keys
# annotations: []
# labels: []
# data: |
# credentials: b64_encoded_str
vmselect:
# -- 为vmselect组件创建deployment. 如果有缓存数据的需要,也可以创建为
enabled: true
# -- Vmselect container name
name: vmselect
image:
# -- Image repository
repository: victoriametrics/vmselect
# -- Image tag
tag: v1.59.0-cluster
# -- Image pull policy
pullPolicy: IfNotPresent
# -- Name of Priority Class
priorityClassName: ""
# -- Overrides the full name of vmselect component
fullnameOverride: ""
# -- Suppress rendering `--storageNode` FQDNs based on `vmstorage.replicaCount` value. If true suppress rendering `--stroageNodes`, they can be re-defined in exrtaArgs
suppresStorageFQDNsRender: false
automountServiceAccountToken: true
# Extra command line arguments for vmselect component
extraArgs:
envflag.enable: "true"
envflag.prefix: VM_
loggerFormat: json
annotations: {}
extraLabels: {}
env: []
# Readiness & Liveness probes
probe:
readiness:
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
liveness:
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
# Additional hostPath mounts
extraHostPathMounts:
[]
# - name: certs-dir
# mountPath: /etc/kubernetes/certs
# subPath: ""
# hostPath: /etc/kubernetes/certs
# readOnly: true
# Extra Volumes for the pod
extraVolumes:
[]
# - name: example
# configMap:
# name: example
# Extra Volume Mounts for the container
extraVolumeMounts:
[]
# - name: example
# mountPath: /example
extraContainers:
[]
# - name: config-reloader
# image: reloader-image
initContainers:
[]
# - name: example
# image: example-image
podDisruptionBudget:
# -- See `kubectl explain poddisruptionbudget.spec` for more. Ref: https://kubernetes.io/docs/tasks/run-application/configure-pdb/
enabled: false
# minAvailable: 1
# maxUnavailable: 1
labels: {}
# -- Array of tolerations object. Ref: [https://kubernetes.io/docs/concepts/configuration/assign-pod-node/](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/)
tolerations: []
# - key: "key"
# operator: "Equal|Exists"
# value: "value"
# effect: "NoSchedule|PreferNoSchedule"
# -- Pod's node selector. Ref: [https://kubernetes.io/docs/user-guide/node-selection/](https://kubernetes.io/docs/user-guide/node-selection/)
nodeSelector: {}
# -- Pod affinity
affinity: {}
# -- Pod's annotations
podAnnotations: {}
# -- Count of vmselect pods
replicaCount: 2
# -- Resource object
resources: {}
# limits:
# cpu: 50m
# memory: 64Mi
# requests:
# cpu: 50m
# memory: 64Mi
# -- Pod's security context. Ref: [https://kubernetes.io/docs/tasks/configure-pod-container/security-context/](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
securityContext: {}
podSecurityContext: {}
# -- Cache root folder
cacheMountPath: /cache
service:
# -- Service annotations
annotations: {}
# -- Service labels
labels: {}
# -- Service ClusterIP
clusterIP: ""
# -- Service External IPs. Ref: [https://kubernetes.io/docs/user-guide/services/#external-ips](https://kubernetes.io/docs/user-guide/services/#external-ips)
externalIPs: []
# -- Service load balacner IP
loadBalancerIP: ""
# -- Load balancer source range
loadBalancerSourceRanges: []
# -- Service port
servicePort: 8481
# -- Service type
type: ClusterIP
ingress:
# -- Enable deployment of ingress for vmselect component
enabled: false
# -- Ingress annotations
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: 'true'
extraLabels: {}
# -- Array of host objects
hosts: []
# - name: vmselect.local
# path: /select
# port: http
# -- Array of TLS objects
tls: []
# - secretName: vmselect-ingress-tls
# hosts:
# - vmselect.local
statefulSet:
# -- Deploy StatefulSet instead of Deployment for vmselect. Useful if you want to keep cache data. Creates statefulset instead of deployment, useful when you want to keep the cache
enabled: false
# -- Deploy order policy for StatefulSet pods
podManagementPolicy: OrderedReady
## Headless service for statefulset
service:
# -- Headless service annotations
annotations: {}
# -- Headless service labels
labels: {}
# -- Headless service port
servicePort: 8481
persistentVolume:
# -- Create/use Persistent Volume Claim for vmselect component. Empty dir if false. If true, vmselect will create/use a Persistent Volume Claim
enabled: false
# -- Array of access mode. Must match those of existing PV or dynamic provisioner. Ref: [http://kubernetes.io/docs/user-guide/persistent-volumes/](http://kubernetes.io/docs/user-guide/persistent-volumes/)
accessModes:
- ReadWriteOnce
# -- Persistent volume annotations
annotations: {}
# -- Existing Claim name. Requires vmselect.persistentVolume.enabled: true. If defined, PVC must be created manually before volume will be bound
existingClaim: ""
## Vmselect data Persistent Volume mount root path
##
# -- Size of the volume. Better to set the same as resource limit memory property
size: 2Gi
# -- Mount subpath
subPath: ""
serviceMonitor:
# -- Enable deployment of Service Monitor for vmselect component. This is Prometheus operator object
enabled: false
# -- Target namespace of ServiceMonitor manifest
namespace: ""
# -- Service Monitor labels
extraLabels: {}
# -- Service Monitor annotations
annotations: {}
# Commented. Prometheus scare interval for vmselect component
# interval: 15s
# Commented. Prometheus pre-scrape timeout for vmselect component
# scrapeTimeout: 5s
vminsert:
# -- Enable deployment of vminsert component. Deployment is used
enabled: true
# -- vminsert container name
name: vminsert
image:
# -- Image repository
repository: victoriametrics/vminsert
# -- Image tag
tag: v1.59.0-cluster
# -- Image pull policy
pullPolicy: IfNotPresent
# -- Name of Priority Class
priorityClassName: ""
# -- Overrides the full name of vminsert component
fullnameOverride: ""
# Extra command line arguments for vminsert component
extraArgs:
envflag.enable: "true"
envflag.prefix: VM_
loggerFormat: json
annotations: {}
extraLabels: {}
env: []
# -- Suppress rendering `--storageNode` FQDNs based on `vmstorage.replicaCount` value. If true suppress rendering `--stroageNodes`, they can be re-defined in exrtaArgs
suppresStorageFQDNsRender: false
automountServiceAccountToken: true
# Readiness & Liveness probes
probe:
readiness:
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
liveness:
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
initContainers:
[]
# - name: example
# image: example-image
podDisruptionBudget:
# -- See `kubectl explain poddisruptionbudget.spec` for more. Ref: [https://kubernetes.io/docs/tasks/run-application/configure-pdb/](https://kubernetes.io/docs/tasks/run-application/configure-pdb/)
enabled: false
# minAvailable: 1
# maxUnavailable: 1
labels: {}
# -- Array of tolerations object. Ref: [https://kubernetes.io/docs/concepts/configuration/assign-pod-node/](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/)
tolerations: []
# - key: "key"
# operator: "Equal|Exists"
# value: "value"
# effect: "NoSchedule|PreferNoSchedule"
# -- Pod's node selector. Ref: [https://kubernetes.io/docs/user-guide/node-selection/](https://kubernetes.io/docs/user-guide/node-selection/)
nodeSelector: {}
# -- Pod affinity
affinity: {}
# -- Pod's annotations
podAnnotations: {}
# -- Count of vminsert pods
replicaCount: 2
# -- Resource object
resources: {}
# limits:
# cpu: 50m
# memory: 64Mi
# requests:
# cpu: 50m
# memory: 64Mi
# -- Pod's security context. Ref: [https://kubernetes.io/docs/tasks/configure-pod-container/security-context/](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/)
securityContext: {}
podSecurityContext: {}
service:
# -- Service annotations
annotations: {}
# -- Service labels
labels: {}
# -- Service ClusterIP
clusterIP: ""
# -- Service External IPs. Ref: [https://kubernetes.io/docs/user-guide/services/#external-ips]( https://kubernetes.io/docs/user-guide/services/#external-ips)
externalIPs: []
# -- Service load balancer IP
loadBalancerIP: ""
# -- Load balancer source range
loadBalancerSourceRanges: []
# -- Service port
servicePort: 8480
# -- Service type
type: ClusterIP
ingress:
# -- Enable deployment of ingress for vminsert component
enabled: false
# -- Ingress annotations
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: 'true'
extraLabels: {}
# -- Array of host objects
hosts: []
# - name: vminsert.local
# path: /insert
# port: http
# -- Array of TLS objects
tls: []
# - secretName: vminsert-ingress-tls
# hosts:
# - vminsert.local
serviceMonitor:
# -- Enable deployment of Service Monitor for vminsert component. This is Prometheus operator object
enabled: false
# -- Target namespace of ServiceMonitor manifest
namespace: ""
# -- Service Monitor labels
extraLabels: {}
# -- Service Monitor annotations
annotations: {}
# Commented. Prometheus scare interval for vminsert component
# interval: 15s
# Commented. Prometheus pre-scrape timeout for vminsert component
# scrapeTimeout: 5s
vmstorage:
# -- Enable deployment of vmstorage component. StatefulSet is used
enabled: true
# -- vmstorage container name
name: vmstorage
image:
# -- Image repository
repository: victoriametrics/vmstorage
# -- Image tag
tag: v1.59.0-cluster
# -- Image pull policy
pullPolicy: IfNotPresent
# -- Name of Priority Class
priorityClassName: ""
# -- Overrides the full name of vmstorage component
fullnameOverride:
automountServiceAccountToken: true
env: []
# -- Data retention period. Supported values 1w, 1d, number without measurement means month, e.g. 2 = 2month
retentionPeriod: 1
# Additional vmstorage container arguments. Extra command line arguments for vmstorage component
extraArgs:
envflag.enable: "true"
envflag.prefix: VM_
loggerFormat: json
# Additional hostPath mounts
extraHostPathMounts:
[]
# - name: certs-dir
# mountPath: /etc/kubernetes/certs
# subPath: ""
# hostPath: /etc/kubernetes/certs
# readOnly: true
# Extra Volumes for the pod
extraVolumes:
[]
# - name: example
# configMap:
# name: example
# Extra Volume Mounts for the container
extraVolumeMounts:
[]
# - name: example
# mountPath: /example
extraContainers:
[]
# - name: config-reloader
# image: reloader-image
initContainers:
[]
# - name: vmrestore
# image: victoriametrics/vmrestore:latest
# volumeMounts:
# - mountPath: /storage
# name: vmstorage-volume
# - mountPath: /etc/vm/creds
# name: secret-remote-storage-keys
# readOnly: true
# args:
# - -storageDataPath=/storage
# - -src=s3://your_bucket/folder/latest
# - -credsFilePath=/etc/vm/creds/credentials
# -- See `kubectl explain poddisruptionbudget.spec` for more. Ref: [https://kubernetes.io/docs/tasks/run-application/configure-pdb/](https://kubernetes.io/docs/tasks/run-application/configure-pdb/)
podDisruptionBudget:
enabled: false
# minAvailable: 1
# maxUnavailable: 1
labels: {}
# -- Array of tolerations object. Node tolerations for server scheduling to nodes with taints. Ref: [https://kubernetes.io/docs/concepts/configuration/assign-pod-node/](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/)
##
tolerations:
[]
# - key: "key"
# operator: "Equal|Exists"
# value: "value"
# effect: "NoSchedule|PreferNoSchedule"
# -- Pod's node selector. Ref: [https://kubernetes.io/docs/user-guide/node-selection/](https://kubernetes.io/docs/user-guide/node-selection/)
nodeSelector: {}
# -- Pod affinity
affinity: {}
## Use an alternate scheduler, e.g. "stork".
## ref: https://kubernetes.io/docs/tasks/administer-cluster/configure-multiple-schedulers/
##
# schedulerName:
persistentVolume:
# -- Create/use Persistent Volume Claim for vmstorage component. Empty dir if false. If true, vmstorage will create/use a Persistent Volume Claim
enabled: true
# -- Array of access modes. Must match those of existing PV or dynamic provisioner. Ref: [http://kubernetes.io/docs/user-guide/persistent-volumes/](http://kubernetes.io/docs/user-guide/persistent-volumes/)
accessModes:
- ReadWriteOnce
# -- Persistent volume annotations
annotations: {}
# -- Storage class name. Will be empty if not setted
storageClass: "vm-disks" 为vm-storage指定storageclass
# -- Existing Claim name. Requires vmstorage.persistentVolume.enabled: true. If defined, PVC must be created manually before volume will be bound
existingClaim: ""
# -- Data root path. Vmstorage data Persistent Volume mount root path
mountPath: /storage
# -- Size of the volume. Better to set the same as resource limit memory property
size: 8Gi
# -- Mount subpath
subPath: ""
# -- Pod's annotations
podAnnotations: {}
annotations: {}
extraLabels: {}
# -- Count of vmstorage pods
replicaCount: 3
# -- Deploy order policy for StatefulSet pods
podManagementPolicy: OrderedReady
# -- Resource object. Ref: [http://kubernetes.io/docs/user-guide/compute-resources/](http://kubernetes.io/docs/user-guide/compute-resources/)
resources: {}
# limits:
# cpu: 500m
# memory: 512Mi
# requests:
# cpu: 500m
# memory: 512Mi
# -- Pod's security context. Ref: [https://kubernetes.io/docs/tasks/configure-pod-container/security-context/](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/)
securityContext: {}
podSecurityContext: {}
service:
# -- Service annotations
annotations: {}
# -- Service labels
labels: {}
# -- Service port
servicePort: 8482
# -- Port for accepting connections from vminsert
vminsertPort: 8400
# -- Port for accepting connections from vmselect
vmselectPort: 8401
# -- Pod's termination grace period in seconds
terminationGracePeriodSeconds: 60
probe:
readiness:
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
liveness:
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
serviceMonitor:
# -- Enable deployment of Service Monitor for vmstorage component. This is Prometheus operator object
enabled: false
# -- Target namespace of ServiceMonitor manifest
namespace: ""
# -- Service Monitor labels
extraLabels: {}
# -- Service Monitor annotations
annotations: {}
# Commented. Prometheus scare interval for vmstorage component
# interval: 15s
# Commented. Prometheus pre-scrape timeout for vmstorage component
# scrapeTimeout: 5s
部署
kubectl create ns vm
helm install vm -n vm ./
如果需要输出渲染好的yaml文件可以添加参数--debug --dry-run
查看创建资源
[root@cilium-1 ~]# kubectl get po -n vm
NAME READY STATUS RESTARTS AGE
vm-victoria-metrics-cluster-vminsert-559db87988-cnb7g 1/1 Running 0 5m
vm-victoria-metrics-cluster-vminsert-559db87988-jm4cj 1/1 Running 0 5m
vm-victoria-metrics-cluster-vmselect-b77474bcf-6rrcz 1/1 Running 0 5m
vm-victoria-metrics-cluster-vmselect-b77474bcf-dsl4j 1/1 Running 0 5m
vm-victoria-metrics-cluster-vmstorage-0 1/1 Running 0 5m
vm-victoria-metrics-cluster-vmstorage-1 1/1 Running 0 5m
vm-victoria-metrics-cluster-vmstorage-2 1/1 Running 0 5m
部署kube-state-metrics
kube-state-metrics是一个简单的服务,它监听Kubernetes API服务器并生成关于对象状态的指标。
根据集群的k8s版本选择合适的kube-state-metrics版本
| kube-state-metrics | Kubernetes 1.16 | Kubernetes 1.17 | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 |
|---|---|---|---|---|---|
| v1.8.0 | - | - | - | - | - |
| v1.9.8 | ✓ | - | - | - | - |
| v2.0.0 | - | -/✓ | -/✓ | ✓ | ✓ |
| master | - | -/✓ | -/✓ | ✓ | ✓ |
✓Fully supported version range.-The Kubernetes cluster has features the client-go library can’t use (additional API objects, deprecated APIs, etc).
本文选用v2.0.0
git clone https://github.com/kubernetes/kube-state-metrics.git -b release-2.0
cd kube-state-metrics/examples/autosharding
# 主要文件
kube-state-metrics/examples/autosharding[root@cilium-bgp-1 autosharding]# ls
cluster-role-binding.yaml cluster-role.yaml role-binding.yaml role.yaml service-account.yaml service.yaml statefulset.yaml
kubectl apply -f ./
由于网络问题可能会遇到kube-state-metrics镜像无法拉取的情况,可以修改statefulset.yaml 使用 bitnami/kube-state-metrics:2.0.0
部署node_exporter
node-exporter用于采集服务器层面的运行指标,包括机器的loadavg、filesystem、meminfo等基础监控,类似于传统主机监控维度的zabbix-agent。
采用daemonset的方式部署在K8S集群,并通过scrape注释。让vmagent自动添加targets。
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: node-exporter
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
k8s-app: node-exporter
template:
metadata:
labels:
k8s-app: node-exporter
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9100"
prometheus.io/path: "/metrics"
spec:
containers:
- name: node-exporter
image: quay.io/prometheus/node-exporter:v1.1.2
ports:
- name: metrics
containerPort: 9100
args:
- "--path.procfs=/host/proc"
- "--path.sysfs=/host/sys"
- "--path.rootfs=/host"
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /host
volumes:
- name: dev
hostPath:
path: /dev
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
hostPID: true
hostNetwork: true
tolerations:
- operator: "Exists"
部署vmagent
由于连接etcd需要配置证书,由于我们的集群是使用kubeadm部署的,所以先在主节点创建etcd secret。
kubectl -n vm create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt
如果独立部署的etcd 集群,同样将证书保存到集群中的一个 secret 对象中去即可。
若监控kube-controller-manager 和 kube-scheduler 需要修改/etc/kubernetes/manifests 下面kube-controller-manager.yaml kube-scheduler.yaml 将- --bind-address=127.0.0.1改为0.0.0.0
#vmagent.yaml
#创建vmagent service 用于访问vmagent接口可以查看监控/targets
---
apiVersion: v1
kind: Service
metadata:
labels:
app: vmagent-k8s
name: vmagent-k8s
namespace: vm
spec:
ports:
- port: 8429
protocol: TCP
targetPort: http
name: http
selector:
app: vmagent-k8s
type: NodePort
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: vmagent-k8s
namespace: vm
labels:
app: vmagent-k8s
spec:
serviceName: "vmagent-k8s"
replicas: 1
selector:
matchLabels:
app: vmagent-k8s
template:
metadata:
labels:
app: vmagent-k8s
spec:
serviceAccountName: vmagent-k8s
containers:
- name: vmagent-k8s
image: victoriametrics/vmagent:v1.59.0
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
args:
- -promscrape.config=/etc/prometheus/prometheus.yaml
- -remoteWrite.tmpDataPath=/vmtmp
- -remoteWrite.url=http://vmetric-victoria-metrics-cluster-vminsert.vm.svc.cluster.local:8480/insert/0/prometheus/ #配置vmagent remotewrite接口
ports:
- name: http
containerPort: 8429
volumeMounts:
- name: time
mountPath: /etc/localtime
readOnly: true
- name: config
mountPath: /etc/prometheus/
- mountPath: "/etc/kubernetes/pki/etcd/" 挂载etcd secret 用于连接etcd接口
name: etcd-certs
- mountPath: "/vmtmp"
name: tmp
volumes:
- name: "tmp"
emptyDir: {}
- name: time
hostPath:
path: /etc/localtime
- name: config
configMap:
name: vmagent-k8s
- name: etcd-certs
secret:
secretName: etcd-certs
updateStrategy:
type: RollingUpdate
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: vmagent-k8s
namespace: vm
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: vmagent-k8s
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: vmagent-k8s
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: vmagent-k8s
subjects:
- kind: ServiceAccount
name: vmagent-k8s
namespace: vm
---
#使用configmap为vmagent挂载配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: vmagent-k8s
namespace: vm
data:
prometheus.yaml: |-
global:
scrape_interval: 60s
scrape_timeout: 60s
external_labels:
cluster: test # 根据需求添加自定义标签
datacenter: test
scrape_configs:
- job_name: etcd
scheme: https
tls_config:
insecure_skip_verify: true
ca_file: /etc/kubernetes/pki/etcd/ca.crt
cert_file: /etc/kubernetes/pki/etcd/healthcheck-client.crt
key_file: /etc/kubernetes/pki/etcd/healthcheck-client.key
static_configs:
- targets:
- 192.168.0.1:2379 #根据集群实际情况添加etcd endpoints
- job_name: kube-scheduler
scheme: http
static_configs:
- targets:
- 192.168.0.1:10259 #根据集群实际情况添加scheduler endpoints
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kube-controller-manager
scheme: http
static_configs:
- targets:
- 192.168.0.1:10257 #根据集群实际情况添加controller-manager endpoints
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kube-apiserver #配置apiserver连接
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes # 配置kubelet代理
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-cadvisor #配置cadvisor代理 获取容器负载数据
scrape_interval: 15s
scrape_timeout: 15s
kubernetes_sd_configs:
- role: node
relabel_configs:
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-service-endpoints # 配置获取服务后端endpoints 需要采集的targets
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-pods # 配置获取容器内服务自定义指标targets
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
kubectl apply -f vmagent.yaml
可以通过浏览器访问agent nodeport /targets 接口查看监控对象
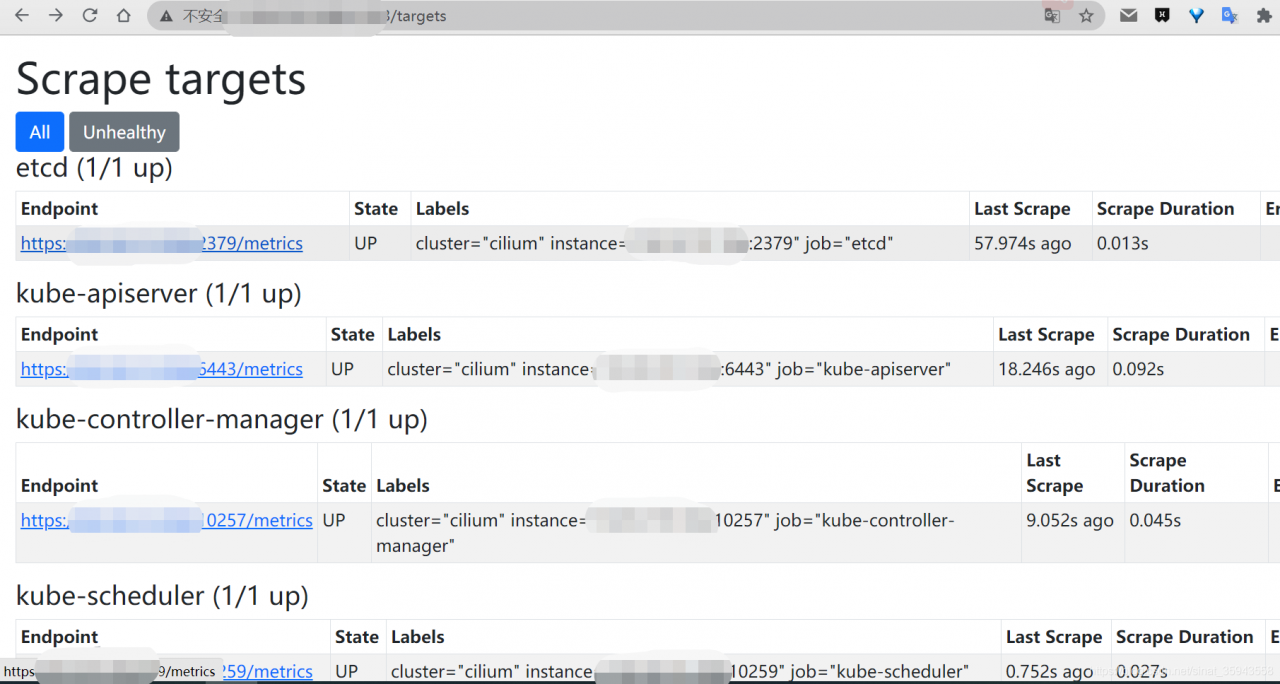
部署promxy
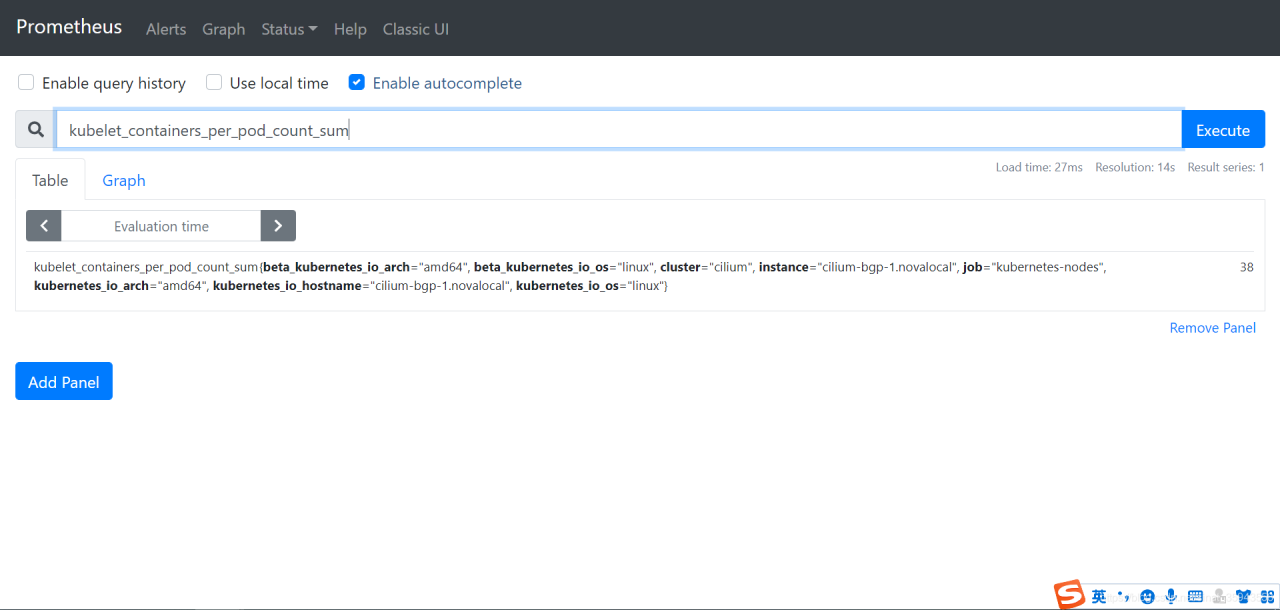
由于VictoriaMetrics没有查询UI,并且不提供Remote_read的功能。所以可以借助第三方工具Promxy实现类似于Prometheus界面填充promql查询数据的功能。
promxy 是一个聚合proxy 可以用来实现prometheus 的ha 详细的相关介绍可以参考github 文档,是一个值得尝试的工具,同时VictoriaMetrics对于自己的一些短板
也推荐了此工具。
[root@cilium-1 promxy]# cat promxy.yaml
apiVersion: v1
data:
config.yaml: |
### Promxy configuration 仅需要配置victoriametrics select组件地址及接口
promxy:
server_groups:
- static_configs:
- targets:
- vm-victoria-metrics-cluster-vmselect.vm.svc.cluster.local:8481
path_prefix: /select/0/prometheus
kind: ConfigMap
metadata:
name: promxy-config
namespace: vm
---
apiVersion: v1
kind: Service
metadata:
labels:
app: promxy
name: promxy
namespace: vm
spec:
ports:
- name: promxy
port: 8082
protocol: TCP
targetPort: 8082
type: NodePort
selector:
app: promxy
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: promxy
name: promxy
namespace: vm
spec:
replicas: 1
selector:
matchLabels:
app: promxy
template:
metadata:
labels:
app: promxy
spec:
containers:
- args:
- "--config=/etc/promxy/config.yaml"
- "--web.enable-lifecycle"
command:
- "/bin/promxy"
image: quay.io/jacksontj/promxy:latest
imagePullPolicy: Always
livenessProbe:
httpGet:
path: "/-/healthy"
port: 8082
initialDelaySeconds: 3
name: promxy
ports:
- containerPort: 8082
readinessProbe:
httpGet:
path: "/-/ready"
port: 8082
initialDelaySeconds: 3
volumeMounts:
- mountPath: "/etc/promxy/"
name: promxy-config
readOnly: true
# container to reload configs on configmap change
- args:
- "--volume-dir=/etc/promxy"
- "--webhook-url=http://localhost:8082/-/reload"
image: jimmidyson/configmap-reload:v0.1
name: promxy-server-configmap-reload
volumeMounts:
- mountPath: "/etc/promxy/"
name: promxy-config
readOnly: true
volumes:
- configMap:
name: promxy-config
name: promxy-config
部署PrometheusAlert
Prometheus Alert是开源的运维告警中心消息转发系统,支持主流的监控系统Prometheus,Zabbix,日志系统Graylog和数据可视化系统Grafana发出的预警消息,支持钉钉,微信,华为云短信,腾讯云短信,腾讯云电话,阿里云短信,阿里云电话等。
本次实验使用PrometheusAlert作为Webhook接收Alertmanager转发的告警信息。
配置文件有缩减 仅留下钉钉配置样例 完整配置请查阅官方文档
apiVersion: v1
data:
app.conf: |
#---------------------↓全局配置-----------------------
appname = PrometheusAlert
#登录用户名
login_user=prometheusalert
#登录密码
login_password=prometheusalert
#监听地址
httpaddr = "0.0.0.0"
#监听端口
httpport = 8080
runmode = dev
#设置代理
#proxy =
#开启JSON请求
copyrequestbody = true
#告警消息标题
title=PrometheusAlert
#链接到告警平台地址
#GraylogAlerturl=http://graylog.org
#钉钉告警 告警logo图标地址
logourl=https://raw.githubusercontent.com/feiyu563/PrometheusAlert/master/doc/alert-center.png
#钉钉告警 恢复logo图标地址
rlogourl=https://raw.githubusercontent.com/feiyu563/PrometheusAlert/master/doc/alert-center.png
#故障恢复是否启用电话通知0为关闭,1为开启
phonecallresolved=0
#自动告警抑制(自动告警抑制是默认同一个告警源的告警信息只发送告警级别最高的第一条告警信息,其他消息默认屏蔽,这么做的目的是为了减少相同告警来源的消息数量,防止告警炸弹,0为关闭,1为开启)
silent=0
#是否前台输出file or console
logtype=file
#日志文件路径
logpath=logs/prometheusalertcenter.log
#转换Prometheus,graylog告警消息的时区为CST时区(如默认已经是CST时区,请勿开启)
prometheus_cst_time=0
#数据库驱动,支持sqlite3,mysql,postgres如使用mysql或postgres,请开启db_host,db_port,db_user,db_password,db_name的注释
db_driver=sqlite3
#---------------------↓webhook-----------------------
#是否开启钉钉告警通道,可同时开始多个通道0为关闭,1为开启
open-dingding=1
#默认钉钉机器人地址
ddurl=https://oapi.dingtalk.com/robot/send?access_token=xxxxx
#是否开启 @所有人(0为关闭,1为开启)
dd_isatall=1
kind: ConfigMap
metadata:
name: prometheus-alert-center-conf
namespace: vm
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: prometheus-alert-center
alertname: prometheus-alert-center
name: prometheus-alert-center
namespace: vm
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-alert-center
alertname: prometheus-alert-center
template:
metadata:
labels:
app: prometheus-alert-center
alertname: prometheus-alert-center
spec:
containers:
- image: feiyu563/prometheus-alert
name: prometheus-alert-center
env:
- name: TZ
value: "Asia/Shanghai"
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: prometheus-alert-center-conf-map
mountPath: /app/conf/app.conf
subPath: app.conf
- name: prometheus-alert-center-conf-map
mountPath: /app/user.csv
subPath: user.csv
volumes:
- name: prometheus-alert-center-conf-map
configMap:
name: prometheus-alert-center-conf
items:
- key: app.conf
path: app.conf
- key: user.csv
path: user.csv
---
apiVersion: v1
kind: Service
metadata:
labels:
alertname: prometheus-alert-center
name: prometheus-alert-center
namespace: vm
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
spec:
ports:
- name: http
port: 8080
targetPort: http
type: NodePort
selector:
app: prometheus-alert-center
部署Alertmanager 和 Karma
警报一直是整个监控系统中的重要组成部分,Prometheus监控系统中,采集与警报是分离的。警报规则在 Prometheus 定义,警报规则触发以后,才会将信息转发到给独立的组件Alertmanager ,经过 Alertmanager r对警报的信息处理后,最终通过接收器发送给指定用户。
Alertmanager支持配置以创建高可用性集群。 可以使用–cluster- *标志进行配置。 重要的是不要在Prometheus及其Alertmanagers之间平衡流量,而是将Prometheus指向所有Alertmanagers的列表。可以查看官方文档详细说明。
Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
为了能够让Alertmanager节点之间进行通讯,需要在Alertmanager启动时设置相应的参数。其中主要的参数包括:
–cluster.listen-address string: 当前实例集群服务监听地址
–cluster.peer value: 初始化时关联的其它实例的集群服务地址
本次实验使用K8S statefulset资源部署Alertmanager 通过headless service 为副本之间提供域名寻址功能,配置PrometheusAlert作为报警转发后端。
Karma是一个比较炫丽的告警展示工具,还提供多种筛选功能。查看告警更加直观。
k8s部署Alertmanager
测试环境没有配置持久化存储,实际部署尽量使用持久化存储
# config-map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: vm
data:
alertmanager.yaml: |-
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 5m
group_interval: 10s
repeat_interval: 10m
receiver: 'web.hook.prometheusalert'
receivers:
- name: web.hook.prometheusalert
webhook_configs:
- url: http://prometheus-alert-center:8080/prometheus/alert
# alertmanager-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: alertmanager
namespace: vm
spec:
serviceName: alertmanager
podManagementPolicy: Parallel
replicas: 3
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
containers:
- name: alertmanager
image: quay.io/prometheus/alertmanager:v0.21.0
args:
- --config.file=/etc/alertmanager/config/alertmanager.yaml
- --cluster.listen-address=[$(POD_IP)]:9094
- --storage.path=/alertmanager
- --data.retention=120h
- --web.listen-address=:9093
- --web.route-prefix=/
- --cluster.peer=alertmanager-0.alertmanager.$(POD_NAMESPACE).svc:9094
- --cluster.peer=alertmanager-1.alertmanager.$(POD_NAMESPACE).svc:9094
- --cluster.peer=alertmanager-2.alertmanager.$(POD_NAMESPACE).svc:9094
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
ports:
- containerPort: 9093
name: web
protocol: TCP
- containerPort: 9094
name: mesh-tcp
protocol: TCP
- containerPort: 9094
name: mesh-udp
protocol: UDP
livenessProbe:
failureThreshold: 10
httpGet:
path: /-/healthy
port: web
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
readinessProbe:
failureThreshold: 10
httpGet:
path: /-/ready
port: web
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
volumeMounts:
- mountPath: etc/alertmanager/config
name: alertmanager-config
- mountPath: alertmanager
name: alertmanager-storage
volumes:
- name: alertmanager-config
configMap:
defaultMode: 420
name: alertmanager-config
- name: alertmanager-storage
emptyDir: {}
# alertmanager-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: vm
labels:
app: alertmanager
spec:
type: NodePort
selector:
app: alertmanager
ports:
- name: web
protocol: TCP
port: 9093
targetPort: web
k8s部署Karma
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: karma
name: karma
namespace: vm
spec:
replicas: 1
selector:
matchLabels:
app: karma
template:
metadata:
labels:
app: karma
spec:
containers:
- image: ghcr.io/prymitive/karma:v0.85
name: karma
ports:
- containerPort: 8080
name: http
resources:
limits:
cpu: 400m
memory: 400Mi
requests:
cpu: 200m
memory: 200Mi
env:
- name: ALERTMANAGER_URI
value: "http://alertmanager.vm.svc.cluster.local:9093"
---
apiVersion: v1
kind: Service
metadata:
labels:
app: karma
name: karma
namespace: vm
spec:
ports:
- name: http
port: 8080
targetPort: http
selector:
app: karma
type: NodePort
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jqGLHheD-1621590463668)(https://github.com/prymitive/karma/raw/main/docs/img/screenshot.png)]
部署grafana
测试环境没有配置持久化存储,实际部署尽量使用持久化存储。否则容器重启会导致配置的模板丢失。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: grafana
namespace: vm
labels:
app: grafana
spec:
replicas: 1
selector:
matchLabels:
app: grafana
serviceName: grafana
template:
metadata:
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: "3000"
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana:7.5.4
ports:
- name: http
containerPort: 3000
resources:
limits:
cpu: 1000m
memory: 1000Mi
requests:
cpu: 600m
memory: 600Mi
volumeMounts:
- name: grafana-storage
mountPath: /var/lib/grafana
- mountPath: /etc/grafana/provisioning/datasources
readOnly: false
name: grafana-datasources
env:
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: "Admin"
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: grafana
volumes:
- name: grafana-datasources
configMap:
name: grafana-datasources
updateStrategy:
type: RollingUpdate
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: grafana
namespace: vm
---
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitor
spec:
ports:
- name: http
port: 3000
targetPort: http
selector:
statefulset.kubernetes.io/pod-name: grafana-0
type: NodePort
---
apiVersion: v1
data:
prometheus.yaml: |-
{
"apiVersion": 1,
"datasources": [
{
"access": "proxy",
"editable": false,
"name": "Prometheus",
"orgId": 1,
"type": "prometheus",
"url": "http://vm-victoria-metrics-cluster-vmselect.vm.svc.cluster.local:8481:/select/0/prometheus",
"version": 1
},
]
}
kind: ConfigMap
metadata:
name: grafana-datasources
namespace: vm
推荐常用的模板
可自行导入,并根据实际需求修改。
部署vmalert
主要参数
- -datasource.url 配置数据查询地址
- -notifier.url 配置alertmanager地址
# rule.yaml 示例rule规则配置文件
apiVersion: v1
data:
k8s.yaml: |-
groups:
- name: k8s
rules:
- alert: KubernetesNodeReady
expr: kube_node_status_condition{condition="Ready",status="true"} == 0
for: 5m
labels:
alert_level: high
alert_type: state
alert_source_type: k8s
annotations:
summary: "Kubernetes Node ready (instance {{ $labels.instance }})"
description: "Node {{ $labels.node }} has been unready for a long time\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: KubernetesMemoryPressure
expr: kube_node_status_condition{condition="MemoryPressure",status="true"} == 1
for: 5m
labels:
alert_level: middle
alert_type: mem
alert_source_type: k8s
annotations:
summary: "Kubernetes memory pressure (instance {{ $labels.instance }})"
description: "{{ $labels.node }} has MemoryPressure condition\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: KubernetesPodCrashLooping
expr: rate(kube_pod_container_status_restarts_total[15m]) * 60 * 5 > 5
for: 5m
labels:
alert_level: middle
alert_type: state
alert_source_type: k8s
annotations:
summary: "Kubernetes pod crash looping (instance {{ $labels.instance }})"
description: "Pod {{ $labels.pod }} is crash looping\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
pod.yaml: |-
groups:
- name: pod
rules:
- alert: ContainerMemoryUsage
expr: (sum(container_memory_working_set_bytes) BY (instance, name) / sum(container_spec_memory_limit_bytes > 0) BY (instance, name) * 100) > 80
for: 5m
labels:
alert_level: middle
alert_type: mem
alert_source_type: pod
annotations:
summary: "Container Memory usage (instance {{ $labels.instance }})"
description: "Container Memory usage is above 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
kvm_node_exporter.yaml: |-
groups:
- name: kvm
rules:
- alert: VirtualMachineDown
expr: up{machinetype="virtualmachine"} == 0
for: 2m
labels:
alert_level: high
alert_type: state
alert_source_type: kvm
annotations:
summary: "Prometheus VirtualmachineMachine target missing (instance {{ $labels.instance }})"
description: "A Prometheus VirtualMahine target has disappeared. An exporter might be crashed.\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostUnusualDiskWriteLatency
expr: rate(node_disk_write_time_seconds_total{machinetype="virtualmachine"}[1m]) / rate(node_disk_writes_completed_total{machinetype="virtualmachine"}[1m]) > 100
for: 5m
labels:
alert_level: middle
alert_type: disk
alert_source_type: kvm
annotations:
summary: "Host unusual disk write latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (write operations > 100ms)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostHighCpuLoad
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle",machinetype="virtualmachine"}[5m])) * 100) > 80
for: 5m
labels:
alert_level: middle
alert_type: cpu
alert_source_type: kvm
annotations:
summary: "Host high CPU load (instance {{ $labels.instance }})"
description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostSwapIsFillingUp
expr: (1 - (node_memory_SwapFree_bytes{machinetype="virtualmachine"} / node_memory_SwapTotal_bytes{machinetype="virtualmachine"})) * 100 > 80
for: 5m
labels:
alert_level: middle
alert_type: mem
alert_source_type: kvm
annotations:
summary: "Host swap is filling up (instance {{ $labels.instance }})"
description: "Swap is filling up (>80%)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostUnusualNetworkThroughputIn
expr: sum by (instance) (irate(node_network_receive_bytes_total{machinetype="virtualmachine"}[2m])) / 1024 / 1024 > 100
for: 5m
labels:
alert_level: middle
alert_type: network
alert_source_type: kvm
annotations:
summary: "Host unusual network throughput in (instance {{ $labels.instance }})"
description: "Host network interfaces are probably receiving too much data (> 100 MB/s)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes{machinetype="virtualmachine"} / node_memory_MemTotal_bytes{machinetype="virtualmachine"} * 100 < 10
for: 5m
labels:
alert_level: middle
alert_type: mem
alert_source_type: kvm
annotations:
summary: "Host out of memory (instance {{ $labels.instance }})"
description: "Node memory is filling up (< 10% left)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
description: "The node is under heavy memory pressure. High rate of major page faults\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
node_exporter.yaml: |-
groups:
- name: machine
rules:
- alert: MachineDown
expr: up{machinetype="physicalmachine"} == 0
for: 2m
labels:
alert_level: high
alert_type: state
alert_source_type: machine
annotations:
summary: "Prometheus Machine target missing (instance {{ $labels.instance }})"
description: "A Prometheus Mahine target has disappeared. An exporter might be crashed.\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostUnusualDiskWriteLatency
expr: rate(node_disk_write_time_seconds_total{machinetype="physicalmachine"}[1m]) / rate(node_disk_writes_completed_total{machinetype="physicalmachine"}[1m]) > 100
for: 5m
labels:
alert_level: middle
alert_type: disk
alert_source_type: machine
annotations:
summary: "Host unusual disk write latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (write operations > 100ms)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostHighCpuLoad
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle",machinetype="physicalmachine"}[5m])) * 100) > 80
for: 5m
labels:
alert_level: middle
alert_type: cpu
alert_source_type: machine
annotations:
summary: "Host high CPU load (instance {{ $labels.instance }})"
description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostSwapIsFillingUp
expr: (1 - (node_memory_SwapFree_bytes{machinetype="physicalmachine"} / node_memory_SwapTotal_bytes{machinetype="physicalmachine"})) * 100 > 80
for: 5m
labels:
alert_level: middle
alert_type: state
alert_source_type: machine
annotations:
summary: "Host swap is filling up (instance {{ $labels.instance }})"
description: "Swap is filling up (>80%)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostUnusualNetworkThroughputIn
expr: sum by (instance) (irate(node_network_receive_bytes_total{machinetype="physicalmachine"}[2m])) / 1024 / 1024 > 100
for: 5m
labels:
alert_level: middle
alert_type: network
alert_source_type: machine
annotations:
summary: "Host unusual network throughput in (instance {{ $labels.instance }})"
description: "Host network interfaces are probably receiving too much data (> 100 MB/s)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes{machinetype="physicalmachine"} / node_memory_MemTotal_bytes{machinetype="physicalmachine"} * 100 < 10
for: 5m
labels:
alert_level: middle
alert_type: mem
alert_source_type: machine
annotations:
summary: "Host out of memory (instance {{ $labels.instance }})"
description: "Node memory is filling up (< 10% left)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
description: "The node is under heavy memory pressure. High rate of major page faults\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostOutOfDiskSpace
expr: (node_filesystem_avail_bytes{machinetype="physicalmachine"} * 100) / node_filesystem_size_bytesi{machinetype="physicalmachine"} < 10
for: 5m
labels:
alert_level: middle
alert_type: disk
alert_source_type: machine
annotations:
summary: "Host out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostDiskWillFillIn4Hours
expr: predict_linear(node_filesystem_free_bytes{fstype!~"tmpfs",machinetype="physicalmachine"}[1h], 4 * 3600) < 0
for: 5m
labels:
alert_level: middle
alert_type: disk
alert_source_type: machine
annotations:
summary: "Host disk will fill in 4 hours (instance {{ $labels.instance }})"
description: "Disk will fill in 4 hours at current write rate\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostOutOfInodes
expr: node_filesystem_files_free{mountpoint ="/rootfs",machinetype="physicalmachine"} / node_filesystem_files{mountpoint ="/rootfs",machinetype="physicalmachine"} * 100 < 10
for: 5m
labels:
alert_level: middle
alert_type: disk
alert_source_type: machine
annotations:
summary: "Host out of inodes (instance {{ $labels.instance }})"
description: "Disk is almost running out of available inodes (< 10% left)\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostOomKillDetected
expr: increase(node_vmstat_oom_kill{machinetype="physicalmachine"}[5m]) > 0
for: 5m
labels:
alert_level: middle
alert_type: state
alert_source_type: machine
annotations:
summary: "Host OOM kill detected (instance {{ $labels.instance }})"
description: "OOM kill detected\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: HostNetworkTransmitErrors
expr: increase(node_network_transmit_errs_total{machinetype="physicalmachine"}[5m]) > 0
for: 5m
labels:
alert_level: middle
alert_type: network
alert_source_type: machine
annotations:
summary: "Host Network Transmit Errors (instance {{ $labels.instance }})"
description: '{{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf "%.0f" $value }} transmit errors in the last five minutes.\n VALUE = {{ $value }}\n LABELS: {{ $labels }}'
kind: ConfigMap
metadata:
name: vmalert-ruler
namespace: vm
常用ruler配置请点击awesome-prometheus-alerts
apiVersion: v1
kind: Service
metadata:
labels:
app: vmalert
name: vmalert
namespace: vm
spec:
ports:
- name: vmalert
port: 8080
protocol: TCP
targetPort: 8080
type: NodePort
selector:
app: vmalert
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: vmalert
name: vmalert
namespace: vm
spec:
replicas: 1
selector:
matchLabels:
app: vmalert
template:
metadata:
labels:
app: vmalert
spec:
containers:
- args:
- "-rule=/etc/ruler/*.yaml"
- "-datasource.url=http://vm-victoria-metrics-cluster-vmselect.vm.svc.cluster.local:8481/select/0/prometheus"
- "-notifier.url=http://alertmanager.monitor.svc.cluster.local"
- "-evaluationInterval=60s"
- "-httpListenAddr=0.0.0.0:8080"
command:
- "/vmalert-prod"
image: victoriametrics/vmalert:v1.59.0
name: vmalert
imagePullPolicy: Always
volumeMounts:
- mountPath: "/etc/ruler/"
name: ruler
readOnly: true
volumes:
- configMap:
name: vmalert-ruler
name: ruler