
box-free的实力分割通常依赖于局部的像素级信息,缺少全局信息,因此常出现过分割或欠分割的问题。因此作者提出了一种新的anchor-based的实例分割方法。主要方法就是像Mask-RCNN一样先产生RoI,然后在每一个RoI上进行分割。但是作者与之有两点主要不同:① multi-level 的特征融合,不仅仅关注global还关注local;② 在分割阶段加入instance normalization来恢复目标物体的分布,同时抑制其他物体的分布。
1 The Proposed Method
1.1 Framework
分为两个Branch:
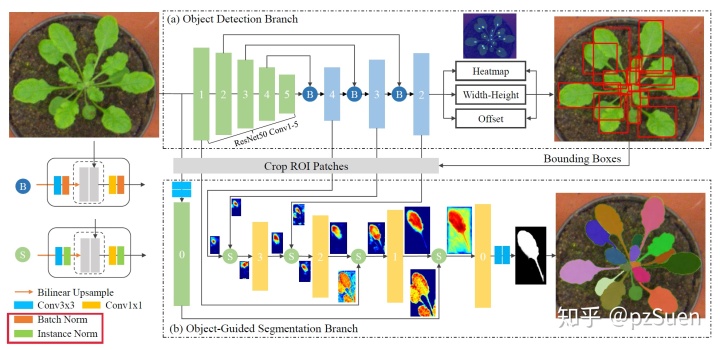
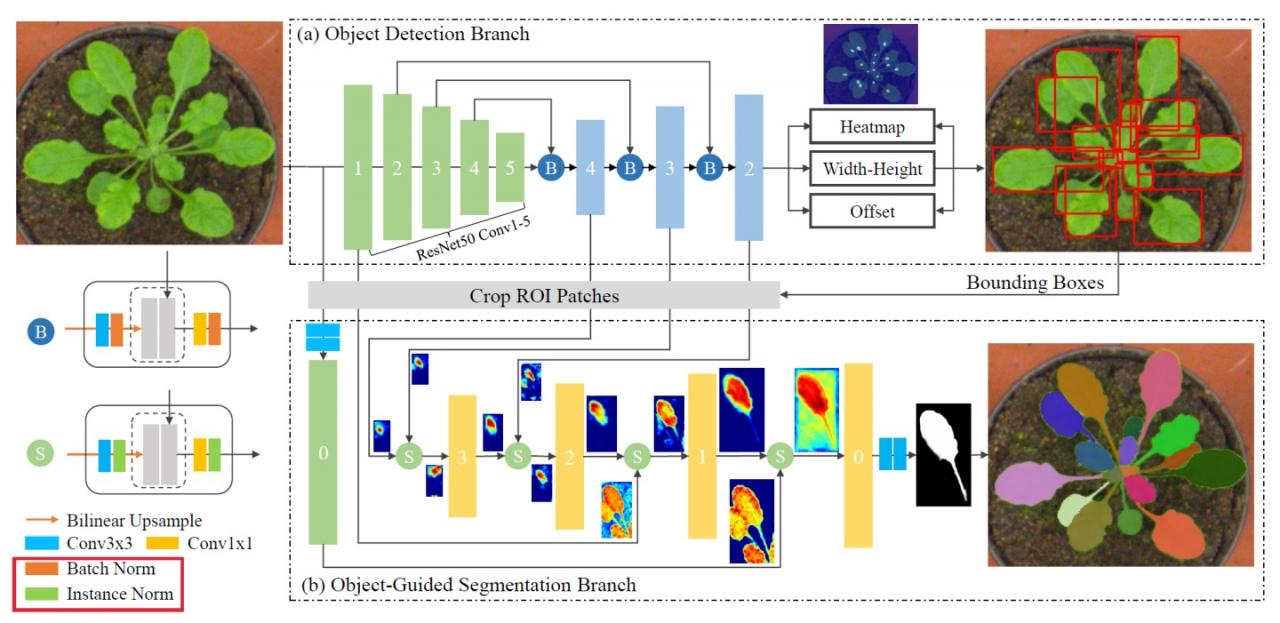
- Object Detection Branch:首先输入图片到ResNet50提取特征,然后将低层语义信息与高层语义信息进行结合(应该是concatenate),每次会进行三次双线性上采样,最后的detection head输出center heatmap,width-height map和center offset map。
- Object-Guided Segmentation Branch:多层特征融合(低层有更多的形态方面的细节,深层特征更关注 target object),结合 instance normalization(remove style statistics of instances)。总的来说就是保留了target的细节信息,抑制了非target的statistics.
1.2 Loss Function
① center heatmap:variant focal loss。其中i表示预测的第i个heatmap,N是center points总数,y是ground truth。论文中使用的α=2,β=4。预测的heatmap会通过NMS进行refine。

② center offset map:L1 loss。由于中心点的预测是不依赖形态信息的,因此,预测中心点时通常是在缩小的heatmap上进行预测的,n是缩小因子,(x,y)表示位置,i表示第i个中心点,则offset可以表示为:
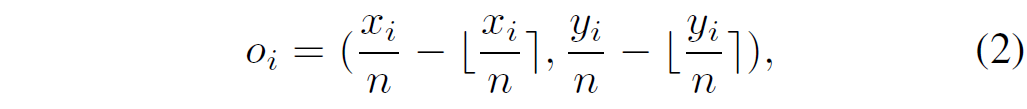
③ width-height map:L1 loss。
④ segmentation:binary cross-entropy loss
2 Experiments
2.1 Datasets
① DSB 2018:细胞核分割数据库,670张图片(clustering,细胞成块)
② Plant Phenotyping:分割植物的叶子,自上而下的视角,473张(occlusion,遮挡严重)
③ Neural Cell:神经元细胞,644张(adhesion,轴突粘连,细节要求高)
2.2 Implementation Details
- 数据扩增:random cropping,random horizontal/vertical flipping
- 输入大小:512 x 512
- 迭代次数:100 epoch,如果val loss不下降就提前停止
- 初始化:backbone用ImageNet预训练,其他部分使用标准高斯分布初始化
- 优化函数:Adam,初始学习率为1.25e-4
2.3 Evaluation Metrics
① Average Precision(AP)
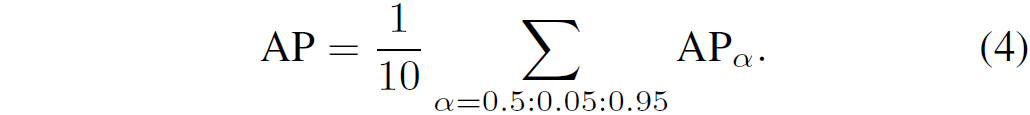
② Average Mask IoU(AIoU),阈值是0.5和0.75
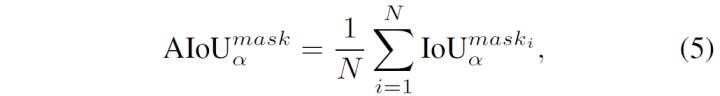
3 Experimental Results
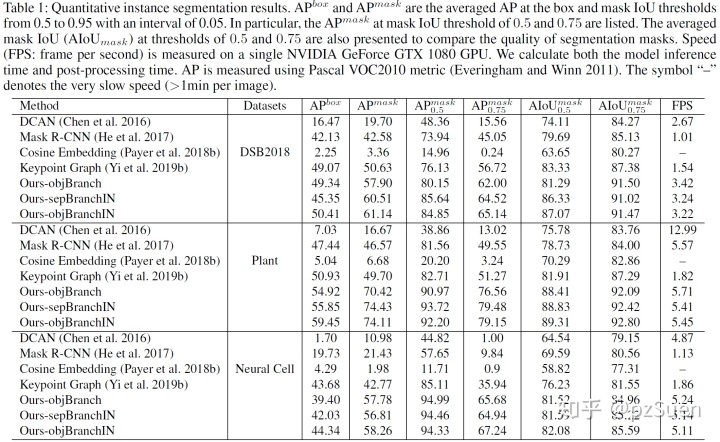
定量分析,见表1,
定性分析,如图3所示:① 细节信息完整,轴突能完整分割出来;② 产生的mask比较完整,同时不会被分到临近的object。

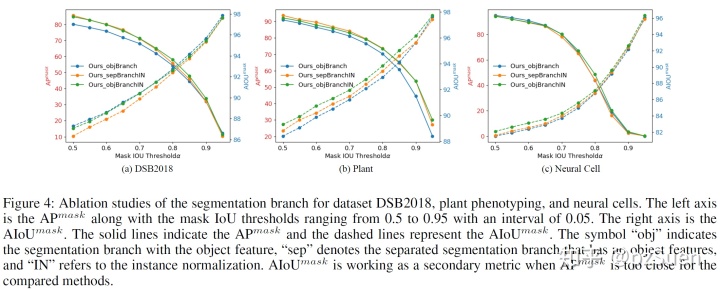
下面图2和图4是Ablation Studies,结论就是box-based有助于区别实例,instance normalization有助于保留target instance的信息并且抑制其他instance。

4 Conclusion
4.1 Discussion for Multi-Modal Distribution
Within an RoI patch, the multi-modal appearance distribution is generally mapped to multi-channels of the feature map.
我的理解就是不同的instance在不同channel上的表示是不同的,在某些channel上,target的权重更大,而该模型就是能学习这些东西。因此最后对聚集数据的分割以及对细节的保留效果都不错。值得注意的是,预测的bounding box应该是紧密的,这也是基于box的原因。但是对于一个过大的包含多个相同大小object的bounding box,该模型将失效。但是如果一个over-sized的bounding box内只有一个object,模型仍然鲁棒。
4.2 Main Contribution
① 对biological images进行object-guided的实力分割(先检测bbox再在其基础上分割)
② 在object-guided segmentation branch,采用instance normalization,集中于target分布,同时抑制其他object。
③ 速度、准确的都较好。
4.3 Weakness or Doubt
① 源码未公开
② 缺少模型的细节信息(channels等)
③ 各层Croped RoI Patch的大小是不同的,怎么处理?
4.4 Memorandum
① Instance Segmentation分为box-based和box-free。前者先从全局信息定位bbox,然后在每个RoI精调进行实力分割,但是可能出现丢失细节、数据不平衡、无法识别小物体等情况;后者仅仅根据实例的形态信息(轮廓、纹理、形状),容易出现欠分割或者过分割的情况。
② instance normalization对于模型恢复实例的完整细节至关重要(但是IN不是remove style statistics of instances吗?)
③ 同一张图,在不同尺度上背景和前景的imbalance程度是不同的,越大的图越imbalance