根据第一步得到如下数据集组成结构:
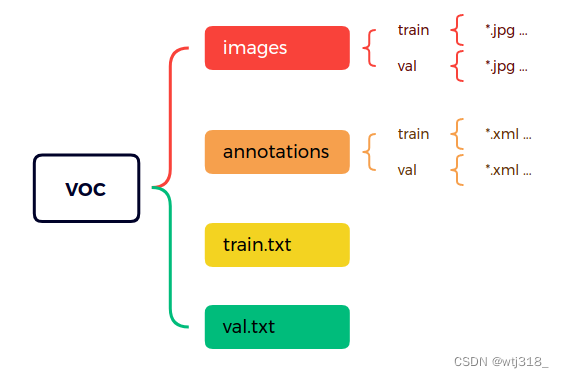
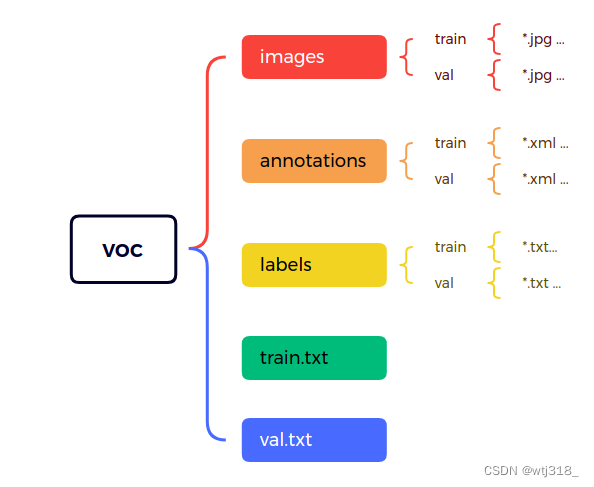
由下代码变成:
import xml.etree.ElementTree as ET
import os
sets = ['train', 'val'] # 需要转换训练集. 验证集
Root = '../datasets/voc-end/' # 数据集目录
classes = ["person", "chef_uniform", "voc_clothes"] # 修改为自己的label
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = round(x*dw, 6)
w = round(w*dw, 6)
y = round(y*dh, 6)
h = round(h*dh, 6)
return (x, y, w, h)
def convert_annotation(image_set, image_id):
in_file = open(Root + 'annotations/' + image_set + '/%s.xml' % (image_id))
out_file = open(Root + 'labels/' + image_set + '/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
for image_set in sets: # train / val
if not os.path.exists(Root + 'labels/'):
os.makedirs(Root + 'labels/')
if not os.path.exists(Root + 'labels/' + image_set + '/'):
os.makedirs(Root + 'labels/' + image_set + '/')
image_ids = open(Root + '%s.txt' % (image_set)).read().strip().split() # 按行读取
for image_id in image_ids:
print(image_id)
convert_annotation(image_set, image_id)
版权声明:本文为wtj318_原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。